
刚进入12月,DeepSeek 又一次无预告地发布了备受期待的 V3.2 系列模型—— DeepSeek-V3.2 与 DeepSeek-V3.2-Speciale,距离上次9月末发布Deepseek-V3.2-Exp仅过去2个月。本次更新不仅是技术迭代的成果,更像是一次针对大模型能力天花板的主动探索。两款模型师出同门,却有着清晰的分工:一个追求高效实用的日常智慧,另一个则专攻极限场景下的深度推理。
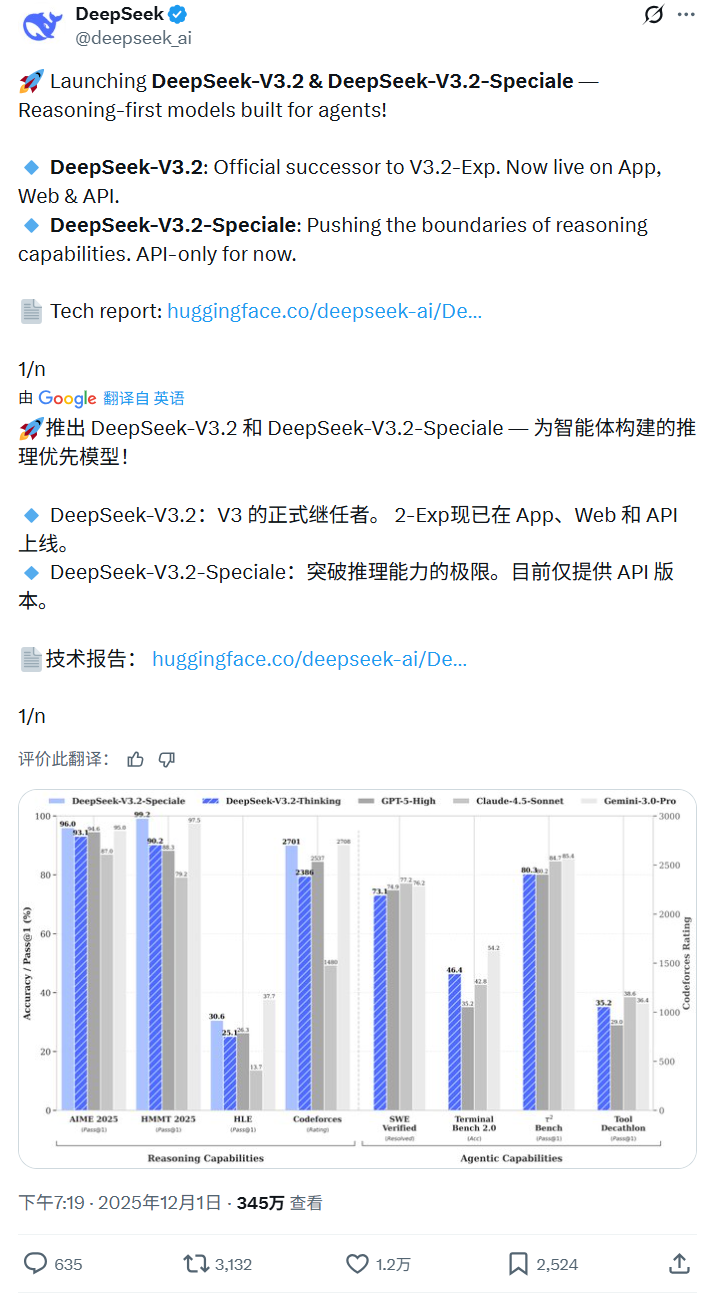

- DeepSeek-V3.2:作为主打日常应用的版本,其核心优化方向在于提升综合效率。它在多项公开推理测试中表现已达到与 GPT-5 相当的水平,同时通过创新的稀疏注意力机制(DSA),显著降低了长文本处理的计算开销与响应延迟。更具突破性的是,V3.2首次实现了“思考”与“工具调用”的深度融合,使其在处理需要多步骤规划、外部信息查询或代码执行的复杂任务时,展现出更接近人类决策的链式推理能力。
- DeepSeek-V3.2-Speciale:作为 V3.2 的长思考增强版,融合了 DeepSeek-Math-V2 的定理证明能力,模型在数学、算法及逻辑推理等高难度领域表现卓越。根据官方报告,其不仅在多项学术基准测试中媲美 Gemini-3.0-Pro,更在 IMO、ICPC 等顶级国际竞赛的模拟评估中达到金牌水准,直观印证了其在解决复杂、深层次问题上的强大潜力。
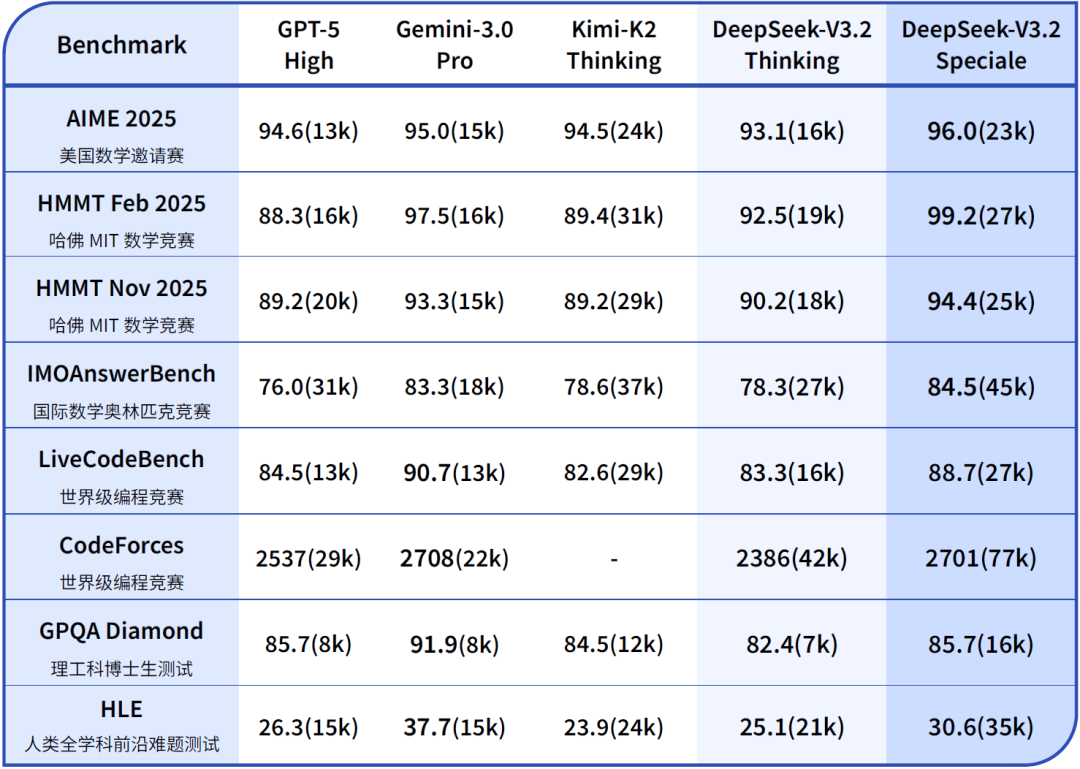
此次升级的技术基石在于两大创新:其一是 DSA 稀疏注意力机制,它有效缓解了传统 Transformer 在超长上下文处理中的计算瓶颈;其二是通过大规模、多样化的 Agent 训练数据合成方法,构建了涵盖 1800 余种环境与超过 8.5 万条复杂指令的强化学习框架,从而大幅提升了模型在真实场景中的泛化性与任务遵循能力。
302.AI 已第一时间接入了 DeepSeek V3.2 系列模型,本期测评将针对模型升级方向,多维度对比实测 deepseek-v3.2,deepseek-v3.2-thinking 与 deepseek-v3.2-speciale 模型,直观对比起表现差异与性能边界。
I. Basic information on the actual model
(1)各对比模型在 302.AI 的价格:
| Models involved in comparative measurement | Input Price | output price | Context length |
| deepseek-v3.2 | $0.29/ 1M tokens | $0.43/ 1M tokens | 128000 |
| deepseek-v3.2-thinking | $0.29/ 1M tokens | $0.43/ 1M tokens | 128000 |
| deepseek-v3.2-speciale | $0.29/ 1M tokens | $0.43 / 1M tokens | 128000 |
(2) Purpose of the assessment:
This review focuses on the testing of models on problems in logic, mathematics, programming, human intuition, multimodality, etc., and is not an authoritative test of a specialized cutting-edge field. It aims to observe the evolutionary trend of the comparison models and provide a reference for model selection.
(3) Measurement methods:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共8题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
题库地址:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡Scoring Rules:
Points are scored out of 10, with corresponding deductions set, and the final average of each round's score is taken.
(4) Assessment tools:
302.AI's API Supermarket → Online Use
II. 测试结果总览
302.AI 题库测试结果:
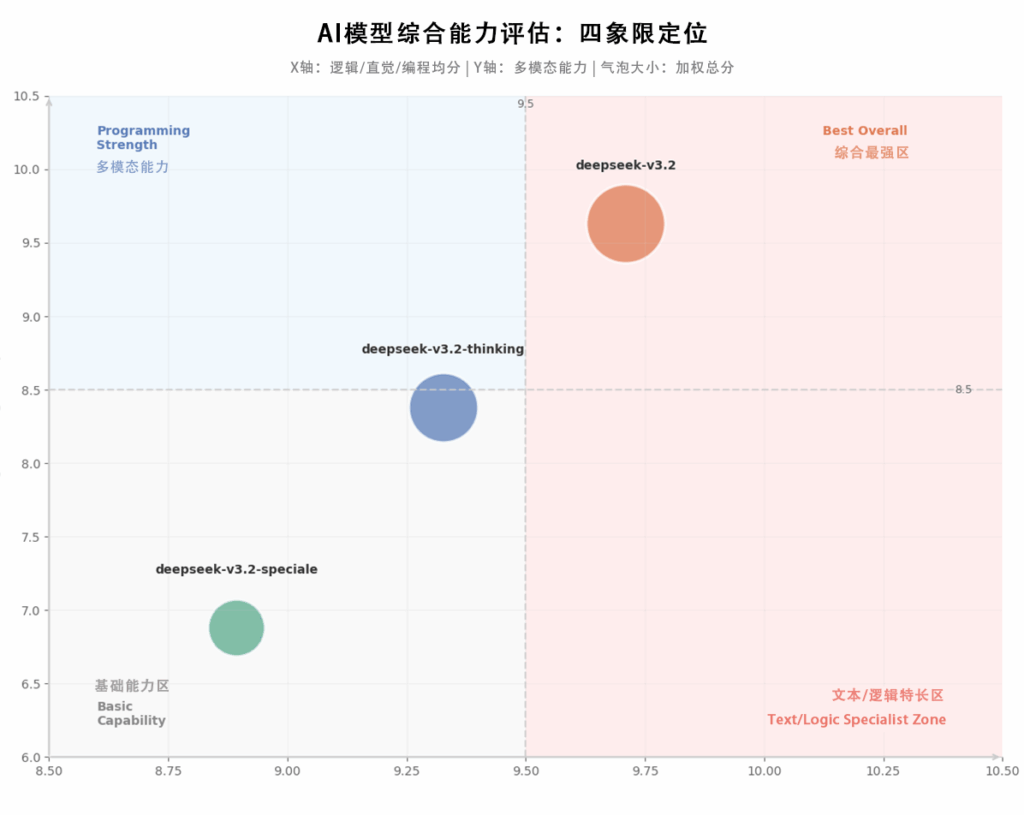
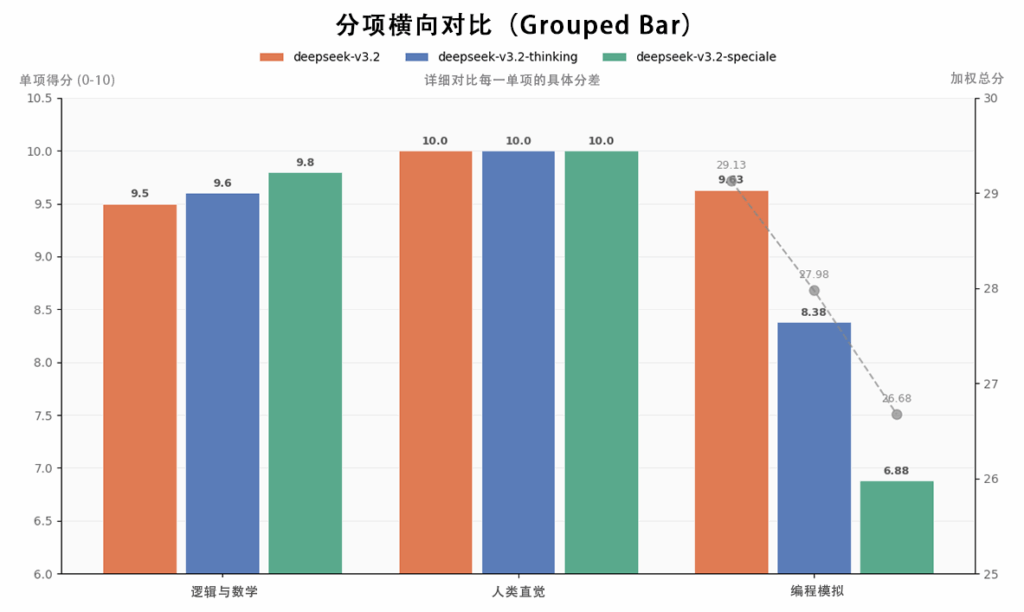
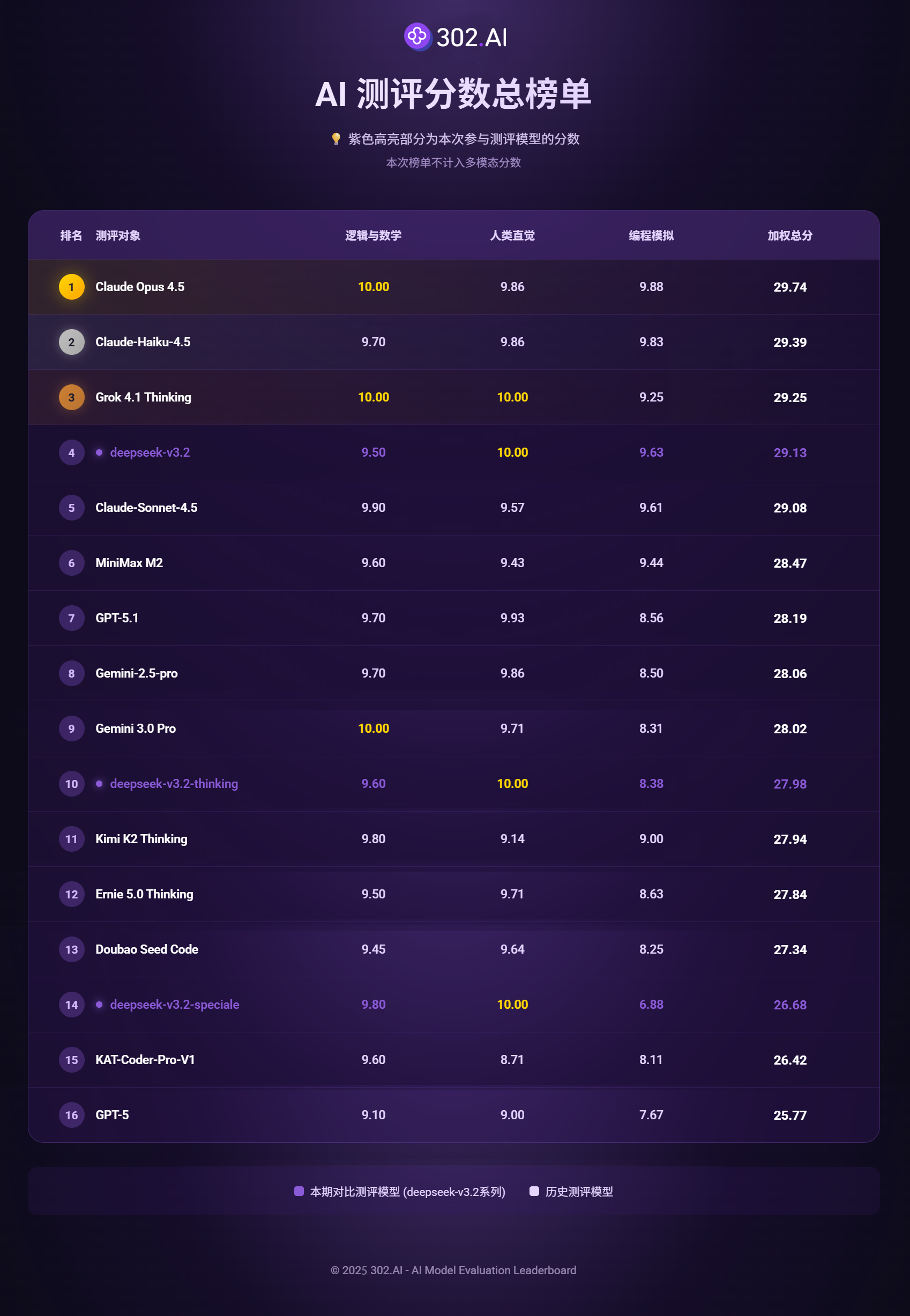
附302.AI测评分数总榜单:(本榜单去除多模态测试项)
III. 实测案例展示
案例 1:逻辑推理-图形序列预测
deepseek-v3.2-speciale 在逻辑推理测试中表现出较高且高且直击核心的逻辑严谨性,尤其明确规律的问题(如图形序列、否定等价证明)中快速抓取核心规则,并用最简形式表达,回答效率高。但也由于其过度简化输出,在评分标准中的多角度分析上扣分较多。
clue: 图形序列规律预测:观察以下图形序列:第一个图形有1个圆形在上方和1个三角形在下方;第二个有2个圆形在左侧和2个三角形在右侧,位置交替;第三个有3个圆形环绕1个三角形。请预测第四个图形的精确组成,包括形状数量、位置分布,并用数学公式(如n阶序列)证明规律(必须解释递增模式和位置变换逻辑)。
还是这个经典的图形序列预测问题,三组模型中只有 deepseek-v3.2-speciale 输出了正确答案。
其输出表现最为鲜明的特征就是效率与简洁,相比以往参与过此题测试的模型,其输出篇幅明显短小且直击核心问题,善用高度结构化与数学化表达,体现了精确的工程化思维。

案例 2:编程模拟-3D卡片画廊
用前端编程任务来对比三组模型的不同输出效果:
在编程任务表现中,则是 deepseek-v3.2 普遍发挥优于另外两组模型,具有更高的稳定性以及技术实现完整性。
clue: 创建一个3D卡片画廊:
- 使用CSS 3D变换实现立体卡片
- 添加鼠标跟踪的光照效果
- 实现平滑的视差滚动
- 支持卡片翻转展示详情
deepseek-v3.2 完整实现了提示词的技术要求,但其对“卡片翻转”的理解则与之前测试的模型表现出不同,使用 CSS 3D变换,鼠标跟踪光效和视差滚动比较平滑。

deepseek-v3.2-thinking 在视觉整体性和 SVG 精细化上处理较佳,但是未实现“卡片翻转”这个核心要求。

deepseek-v3.2-speciale 的技术实现过于简洁,除“卡片翻转”交互丝滑之外,视觉效果比较单调,CSS缺少模块化,大量硬编码
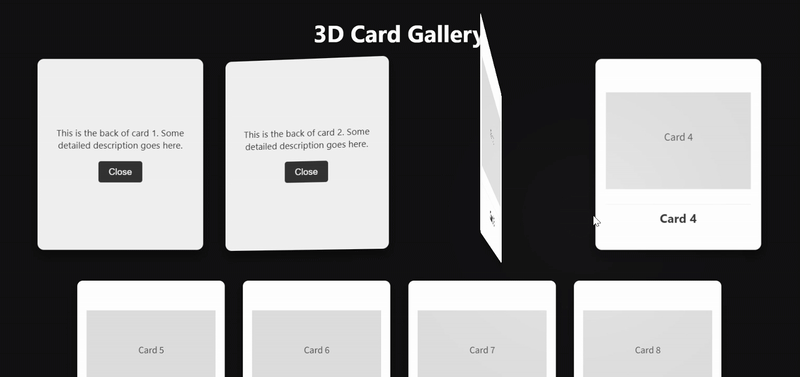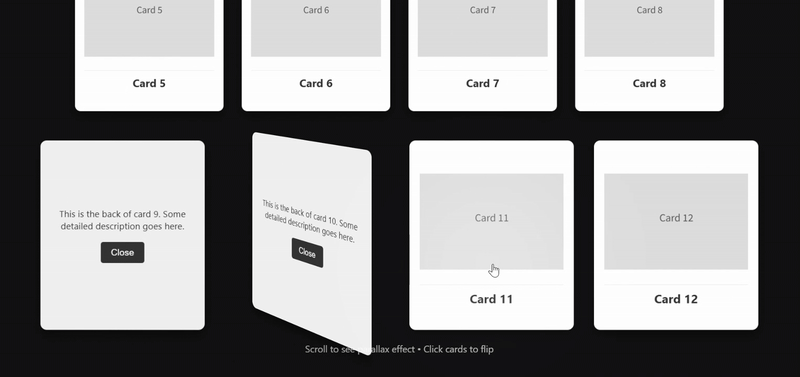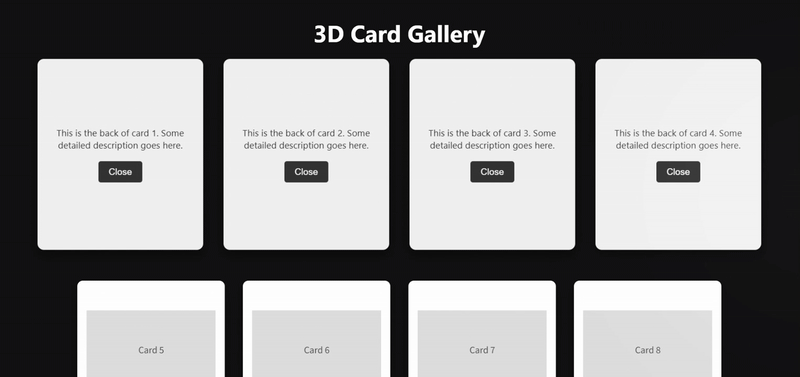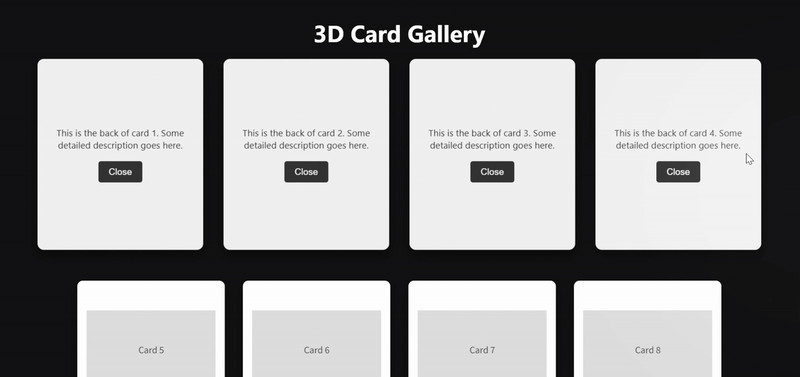
加入 Gemini 3 Pro作为对照组来说,deepseek-v3.2 在这一编程任务的发挥确实更胜一筹。

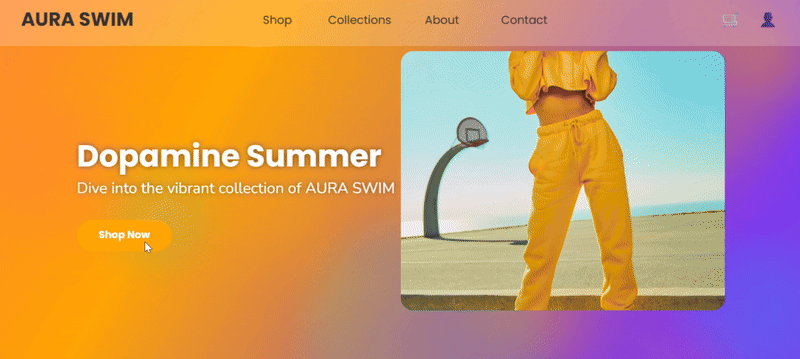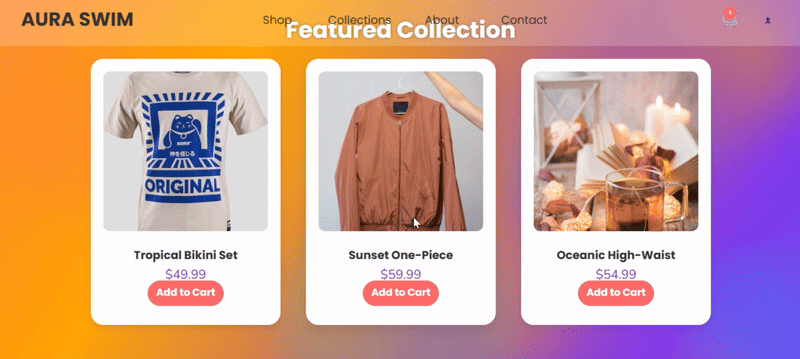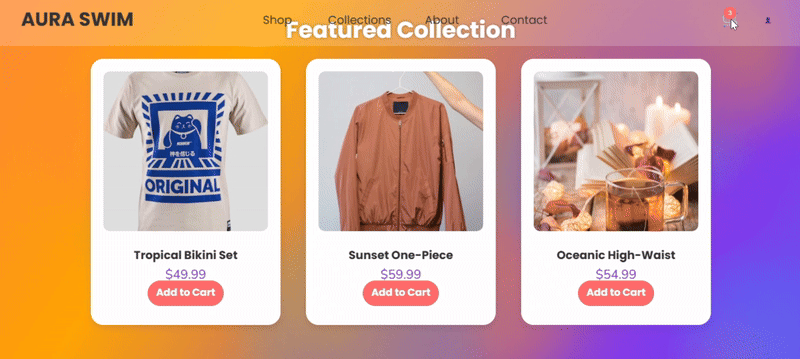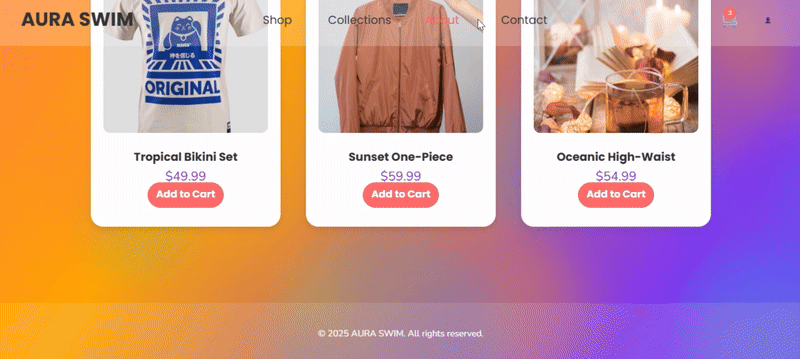
案例 3:编程模拟-电商网页
尝试用更加细化的提示词描述,让三组模型输出一个电商网页
clue:
为一个名为 “AURA SWIM” 的虚构女性泳装品牌,创建一个精美、逼真且完全交互的电商网站首页的完整代码(HTML、CSS 和 JavaScript)。整个页面的所有视觉元素都必须在一个单独的 <canvas> 元素内进行渲染。
- 目标用户与品牌美学:
品牌 AURA SWIM 的目标用户是Z世代消费者(年龄在16-25岁之间)。网站的整体美学必须充满活力、能量充沛,并具有数字原生感,以反映核心的Z世代设计趋势。
- 核心氛围: “多巴胺夏日”。风格需大胆、自信、有趣。
- 色彩搭配: 运用动态、流动的渐变色。想象日落与海洋交汇的景象:鲜艳的粉色 (#FF6B6B)、橙色 (#FFA500)、深紫色 (#8338EC) 和电光蓝 (#00C6FF)。
- 字体设计: 标题使用加粗的、圆润的无衬线字体(例如 ‘Poppins’, ‘Nunito’, 或类似的 Google Font)。正文文本应保持清晰易读。
- 布局与形状: 拥抱柔和的圆角(“soft-UI”风格)和非对称布局。避免使用尖锐、死板的矩形。对背景元素使用模糊效果以创造深度感。
- 技术要求与页面结构(需在Canvas上渲染):
你必须以编程方式将每一个元素绘制到Canvas上。除了<canvas>本身,<body>标签内不应包含任何用于构建界面的标准HTML元素。
deepseek-v3.2 完整实现了提示词的技术要求,外观设计感在线,产品卡片交互流畅,功能完整度高于其他两组,唯一缺陷在于元素布局和适配性存在改进空间。

deepseek-v3.2-thinking 的产品卡片轮播效果独具新意,视觉元素齐全,但组件布局有明显缺陷。

deepseek-v3.2-speciale 的输出则未能完整实现提示词要求,Canvas 渲染不完整,功能基础,缺乏深度,整个布局和设计相对传统
IV. DeepSeek-V3.2 实测结论

通过以上多维度的对比实测,DeepSeek-V3.2 系列模型的理论升级方向,在实际应用中得到了清晰的印证。总体看来,V3.2 与 V3.2-Speciale 展现出了高度差异化的“模型性格”与擅长领域。
DeepSeek-V3.2 在综合任务中表现最为稳健,无愧于其高效实用的定位,在编程实现、前端构建等需要综合理解与稳定输出的任务中表现最为稳健可靠,其代码的完整度、功能实现与设计美感均达到了优秀水准,可作为日常开发与复杂任务执行的主力。而 V3.2-Speciale 虽加权总分不高,但其部分表现令人瞩目。在严密的逻辑推理、数学问题求解上展现出极高水准,表现出思维链条的简洁、精准与高度结构化,完美契合一位“推理大师”的定位。然而,这种为深度推理而优化的特性,也使其在需要丰富创意或冗长代码生成的场景中显得过于专注而略显简朴。
二者的表现差异恰巧对应了 DeepSeek 本次升级的两个核心:效率与深度。通过 DSA 机制与强化学习框架实现能力进化,这一机制也保障了模型在处理复杂逻辑问题的时的效率,使得 Speciale 能够迅速精准地抓取问题核心;而大规模 Agent 训练则极大提升了标准版 DeepSeek-V3.2 在理解复杂指令、工具性任务上的泛化能力与完成度。实测的结果也验证了这种分工策略是成功的——用户在实际选择时,无需再为一个“通才”模型的所有能力付费,而是可以根据任务特性,在“深度思考专家”与“高效执行助手”之间做出更具性价比的选择。
整体而言,DeepSeek-V3.2 系列的升级,让我们看到开源模型在保持实用性和经济性的同时,已经能在特定领域与顶尖闭源模型一较高下。而对于大多数开发者和用户来说,这也意味着我们拥有了一组更加开放、能够按需取用的优质工具。
V. 如何在 302.AI 上使用
1. Use in chatbots
步骤指引 :应用超市→机器人→聊天机器人→立即体验
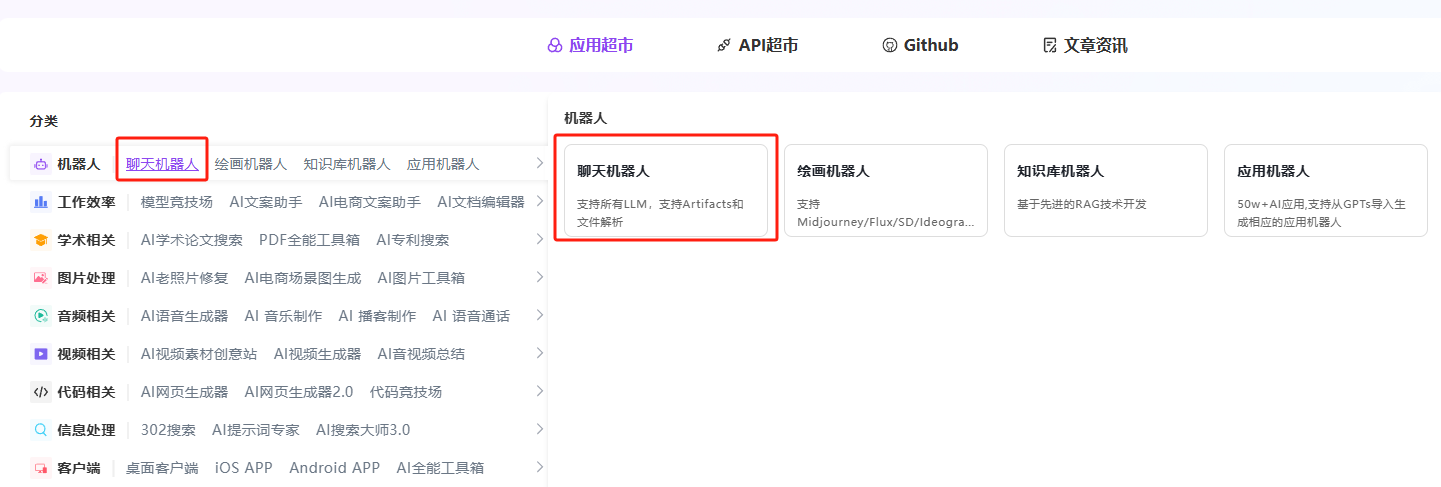
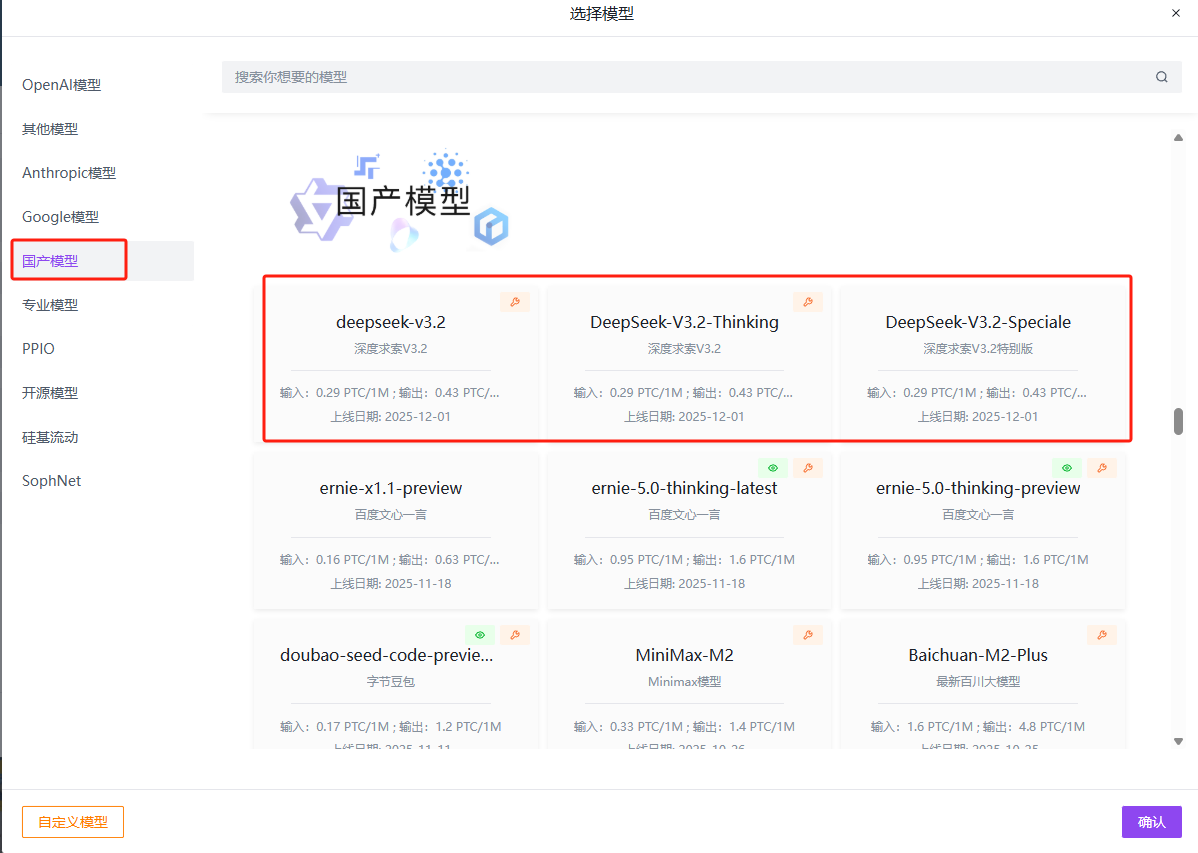
选择模型:国产模型→Deepseek→选择版本→创建
2. Using the Model API
步骤指引:API超市→语言大模型→Deepseek→v3.2系列模型
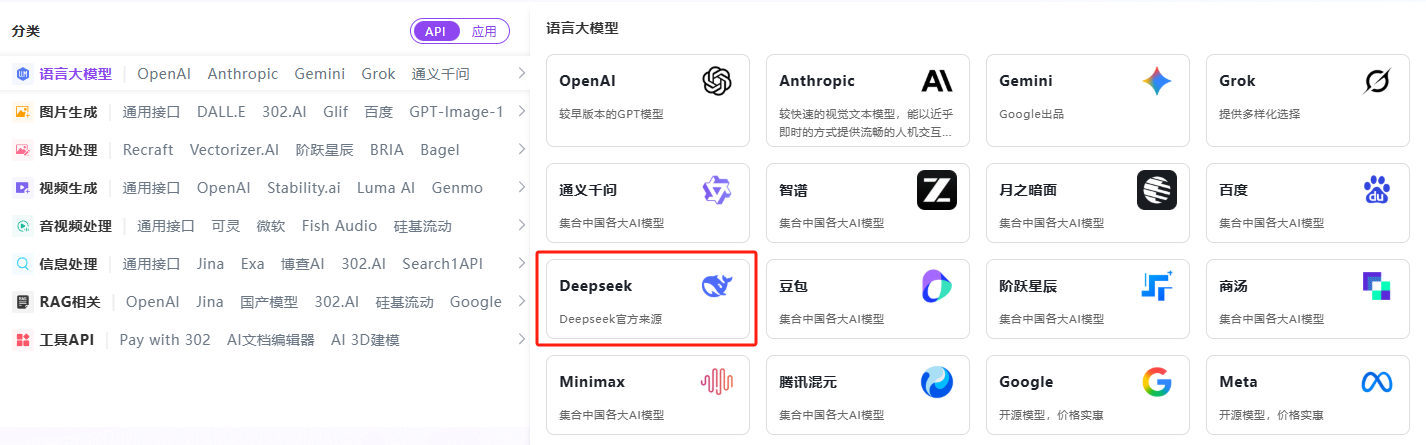
点击【Playground】在线调用 API
想即刻体验 DeepSeek-V3.2 系列模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
