
Table of Contents
The AI programming track in the second half of this year can be described as a group of fierce competition. There are Kimi-K2-0905 Strongly in the first tier, followed by Smart Spectrum GLM-4.5 To the ringmaster. Claude Sonnet 4.5 Launching a challenge, MiniMax also launches its latest creationMiniMax-M2The first of these models to be released in a row is a new model that will be released in the next few years. It is not difficult to find that these models, which emerged one after another like casting stones into a lake, invariably emphasized their significant improvement in programming power when they were released.
This trend clearly shows that large modelsCompetition is increasingly focused on AI programming。
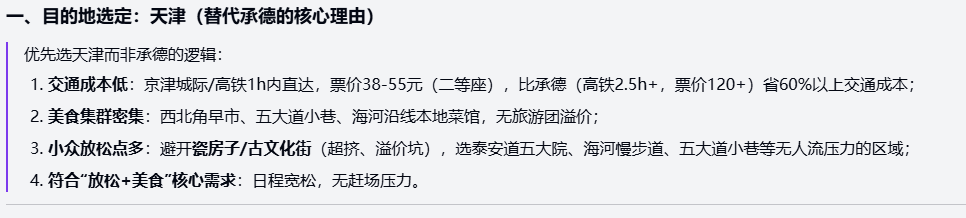
And in recent days, Byte Jump's Volcano Engine also added another fire to this - on the occasion of Double 11, the first programming model was officially introduced in the beanbag family bucket:Doubao-Seed-Code
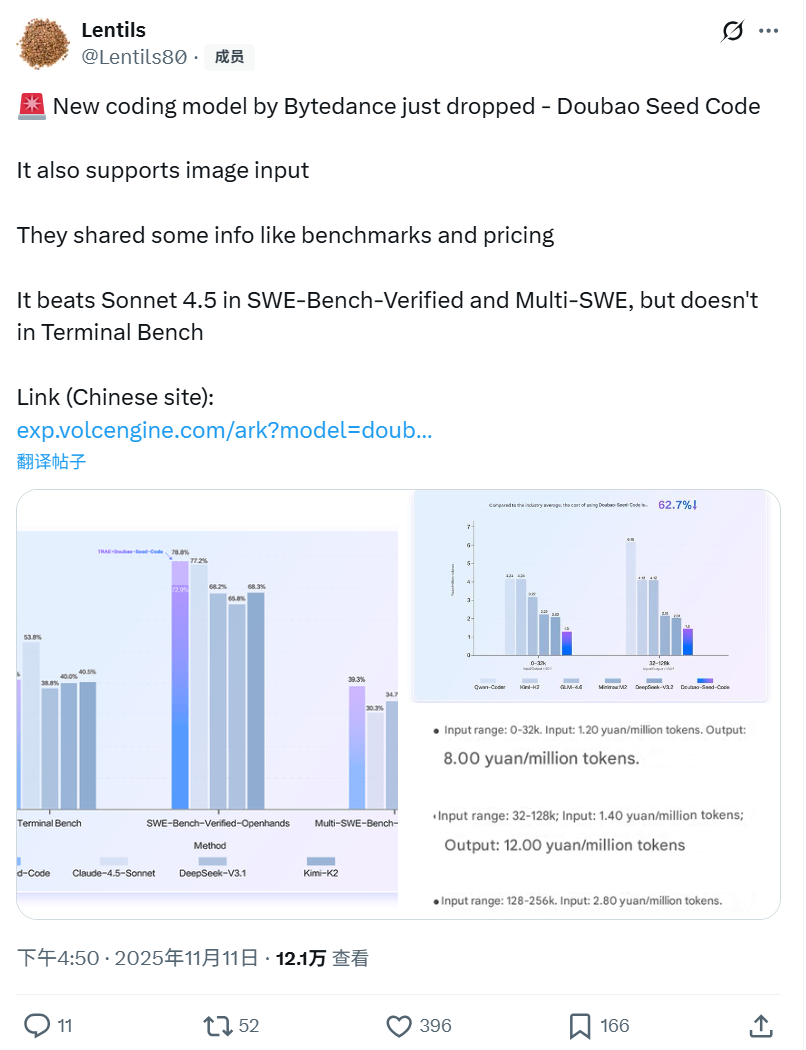

Doubao-Seed-Code As a code generation model optimized for Agentic programming tasks, Volcano Engine has achieved excellent performance in many authoritative programming benchmarks. Especially in the SWE-Bench-Verified list, it achieved a SOTA of 78.80% with the TRAE development environment, which is one of the top models in China in terms of comprehensive performance, and its overall performance is only second to that of the Claude Sonnet 4.5It supports 256K long contexts natively. Its native support for 256K long context , can easily handle complex code base and multi-module dependencies , and in the front-end development , full-stack programming and other scenarios to show excellent end-to-end coding capabilities .
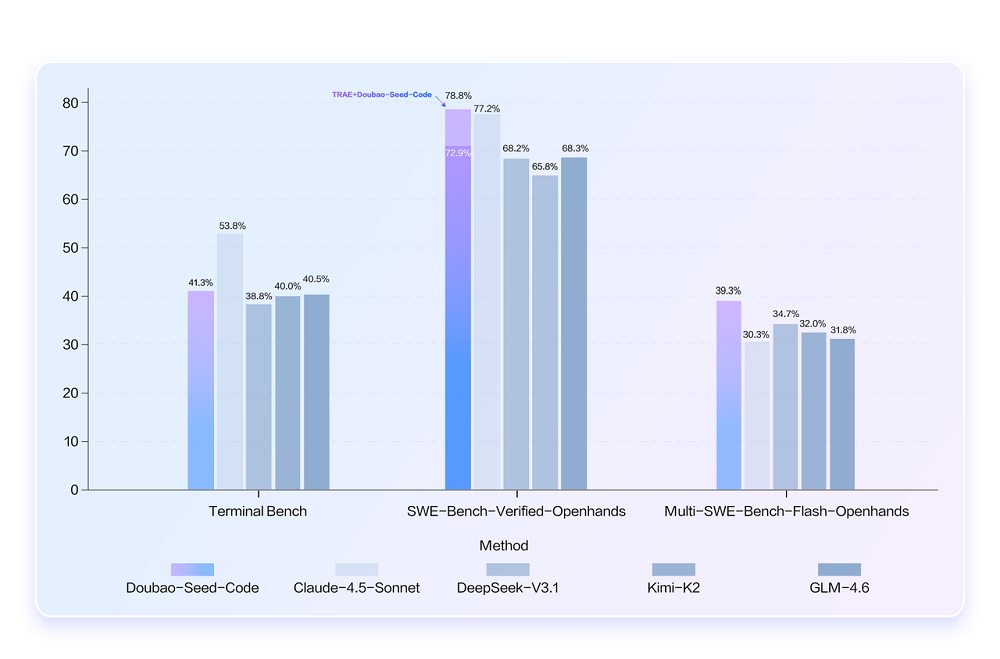
As the first programming model with visual understanding capability, Doubao-Seed-Code can generate code directly from UI design, interface screenshots and even hand-drawn sketches, and supports visual comparison and style repair, which significantly improves the efficiency of front-end development. The model is also deeply adapted to Anthropic API, TRAE and other mainstream development environments, which makes it easy for developers to smoothly migrate from Claude Code at a very low cost and enjoy more cost-effective coding services.
At the cost level, Doubao-Seed-Code utilizes tiered pricing with full transparent caching.Comprehensive utilization cost is 62.7% lower than the industry average, the lowest in China.It helps development teams move into a new phase of AI-native development at a much smaller cost.
From a macro point of view, whether it is open source or closed source, domestic or overseas, the programming ability of the model has indeed been strengthened in the continuous iteration and market competition, but there are also many cases that show that part of the model performs omnipotently in the runtime, and the actual test lacks a lot of loopholes.302.AI The Doubao-Seed-Code model API is now available, and in this evaluation, we will focus on its programming ability to test it with Kimi K2 Thinking and Claude Sonnet 4.5 are compared for validation.
I. Basic information on the actual model
(1) The price of each real model at 302.AI:
| Models involved in comparative measurement | clarification | Input Price | output price | Context length |
| doubao-seed-code-preview | [0,32] k tokens | $0.1715/ 1M tokens | $1.1429/ 1M tokens | 256000 |
| [32,128] k tokens | $0.2/ 1M tokens | $1.7143/ 1M tokens | ||
| [128, 256] k tokens | $0.4/ 1M tokens | $2.2858/ 1M tokens | ||
| kimi-k2-thinking | $0.575 / 1M tokens | $2.3 / 1M tokens | 256000 | |
| claude-sonnet-4-5 | ≤200K tokens | $3 / 1M tokens | $15 / 1M tokens | 200000 |
| >200K tokens | $6 / 1M tokens | $22.5 / 1M tokens | 200000 |
(2) Purpose of the assessment:
This review focuses on the testing of models on problems in logic, mathematics, programming, human intuition, multimodality, etc., and is not an authoritative test of a specialized cutting-edge field. It aims to observe the evolutionary trend of the comparison models and provide a reference for model selection.
(3) Measurement methods:
The evaluation was conducted independently using the question bank included in 302.AI. 3 models were tested on logic and mathematics (10 questions), human intuition (7 questions), programming simulation (8 questions), and multimodal reasoning (20 questions), and the final results were obtained according to the scoring rules, which are shown in the following representative cases.
Question bank address:https://docs.google.com/spreadsheets/d/1sBxs60yWsxc9I5Va8Rjc1_le1Omg2hOXbwqOzpImZio/edit?gid=0#gid=0
💡Scoring Rules:
Points are scored out of 10, with corresponding deductions set, and the final average of each round's score is taken.
(4) Assessment tools:
302.AI's API Supermarket → Online Use
302.AI's Application Supermarket - Chatbot Applications
(5) Measurement results:
- Logic and Math Test Results (Total Questions: 10)
| target audience | average score |
| doubao-seed-code-preview | 9.45 |
| kimi-k2-thinking | 9.90 |
| claude-sonnet-4-5 | 9.90 |
- Human Intuition Results (Total Questions: 7)
| target audience | average score |
| doubao-seed-code-preview | 9.64 |
| kimi-k2-thinking | 8.86 |
| claude-sonnet-4-5 | 9.43 |
- Programming Practice Test Results (Total Questions: 8)
| target audience | average score |
| doubao-seed-code-preview | 8.25 |
| kimi-k2-thinking | 9.06 |
| claude-sonnet-4-5 | 9.69 |
- Multimodal Ability Test Results (Total Questions: 20) (kimi-k2-thinking does not have multimodal ability and did not participate in this test)
| target audience | Number of correct answers | correctness rate |
| doubao-seed-code-preview | 15 | 75% |
| claude-sonnet-4-5 | 16 | 80% |
💡 with references to previous multimodal model test results:
| target audience | Number of correct answers | correctness rate |
| gemini-2.5-pro | 17 | 85% |
| gpt-5 | 15 | 75% |
| claude-haiku-4-5 | 14 | 70% |
- Overview of the measurement results:
| target audience | Logic and Mathematics | human intuition | Programming simulation | weighted total |
| doubao-seed-code-preview | 9.45 | 9.64 | 8.25 | 27.34 |
| kimi-k2-thinking | 9.90 | 8.86 | 9.06 | 27.82 |
| claude-sonnet-4-5 | 9.90 | 9.43 | 9.69 | 29.02 |
II. Actual test cases
Case 1: Logic and Math
Doubao-Seed-Code exhibits a de-redundant, concise and straightforward structure in the output of the Logical Reasoning empirical test, but to a certain extent it also makes the reasoning process appear thin and lacking in case examples.
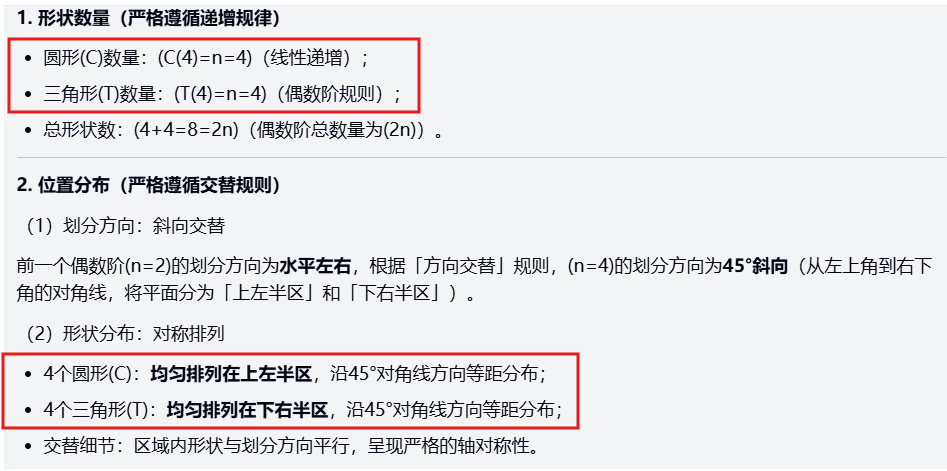
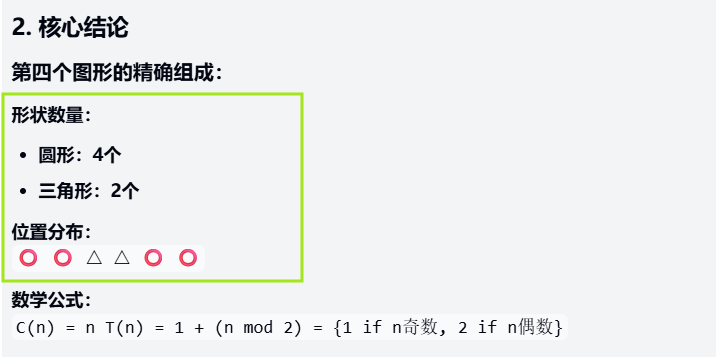
clue: Observe the following sequence of shapes: the first has 1 circle above and 1 triangle below; the second has 2 circles on the left and 2 triangles on the right in alternating positions; and the third has 3 circles surrounding 1 triangle. Predict the exact composition of the fourth figure, including the number of shapes, the distribution of positions, and prove the pattern using a mathematical formula (e.g., a sequence of order n) (you must explain the incremental pattern and the positional transformation logic).
Still the same graphical sequence reasoning problem that almost no model has been able to play with a perfect score so far in this run. All three sets of models had errors in their first outputs, and after a rerun, Kimi K2 Thinking and Sonnet 4.5 output the correct conclusions, while Doubao's conclusions still had obvious holes.
Doubao-Seed-Code:
Deductions: incorrect reasoning about the number of triangles → incorrect direct conclusions (standard answer: 4 circles in the corners, 2 triangles in the center)
Kimi k2 Thinking:
Output correct derivation after rerun

Claude Sonnet 4.5:
Output correct derivation after rerun
Case 2: Human Intuition Test
Doubao-Seed-Code's human intuition test scored the highest of the three models, captured key cues accurately, and demonstrated an “insightful intuition” and “goal-oriented” style of practical decision-making assistance.
clueTravel Planning: Fuzzy Budget Weekend Trip: You are planning a weekend trip (2 days and 1 night) to a nearby city, with a vague budget of “about 500-800RMB”, a preference for “relaxation+food”, and a dislike of crowded attractions. Assuming you are traveling from Beijing, you can choose destinations such as Tianjin or Chengde. Plan your trip step-by-step: include transportation, scheduling, lodging and dining suggestions, address budgetary uncertainties (e.g., prioritize low-cost options), and explain why this plan balances relaxation with affordability and doesn't allow you to ignore potential risks such as weather changes.
Doubao-Seed-Code:
Accurately speculate the user's intention, identify the core contradiction of “relaxation + food + not crowded + low budget”, and give the quantitative reasons for abandoning Chengde; the budget allocation and risk control analysis is reasonable, reflecting strong decision-making assistance ability.

Kimi k2 Thinking:
The plan fails to fully circumvent congestion and the risk assessment is more general.

Claude Sonnet 4.5:
Ignores the need for “don't like crowding” in the prompt and lacks a risk assessment section.
Case 3: Multimodal Visual Reasoning
Doubao-Seed-Code performed reasonably well on the multimodal visual reasoning test, and this more typical fine-grained recognition question was recognized correctly.
clueWhat is the referee doing in the image? Options: A: Blowing the whistle B: Talking to the players C: Watching the match from the sideline D: Scoring the goal Answer: C

Doubao-Seed-Code:
(The referee is the person pictured standing on the sidelines in the referee's uniform, holding the penalty card.)

Case 4: Programming Simulation - Webpage Replication
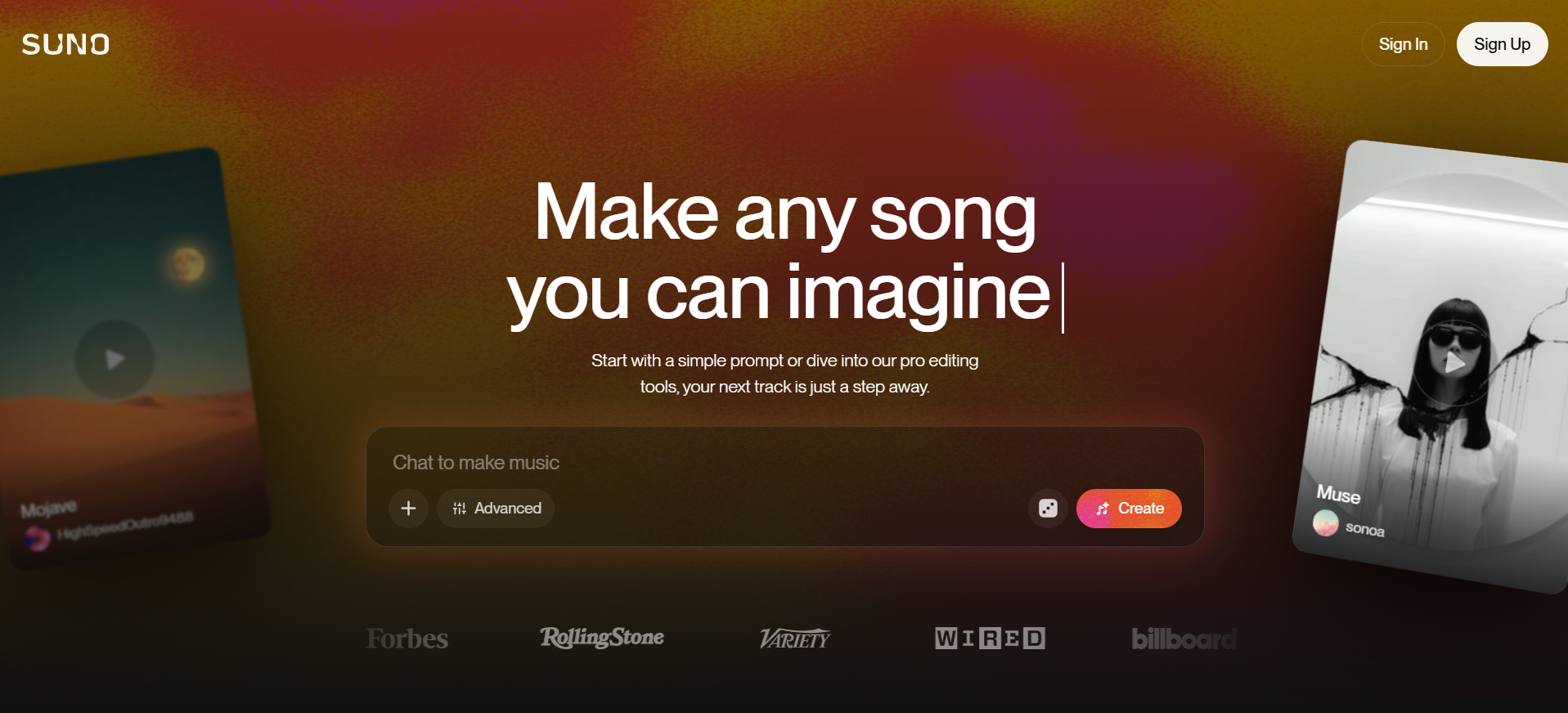
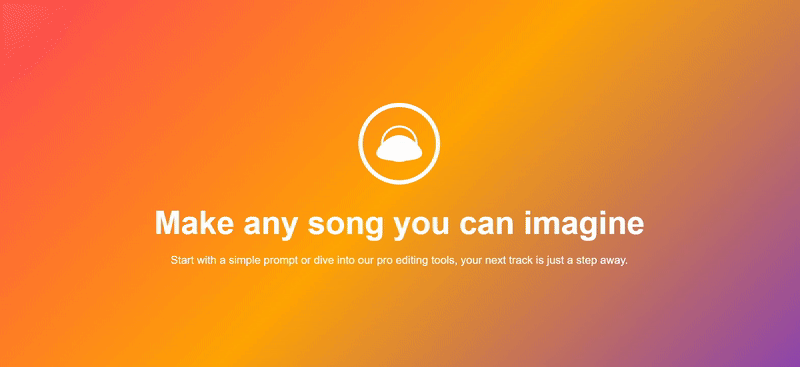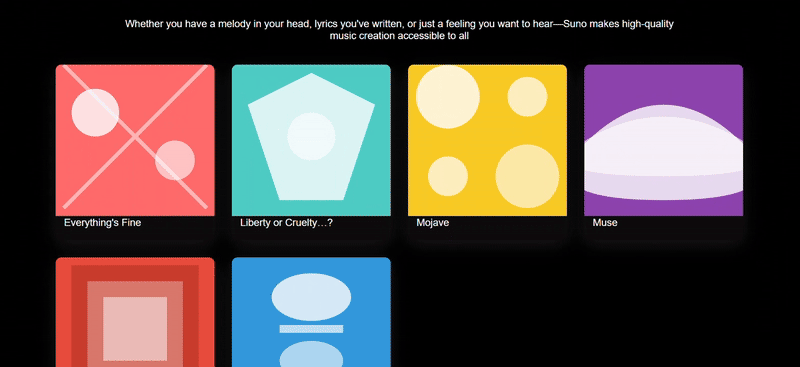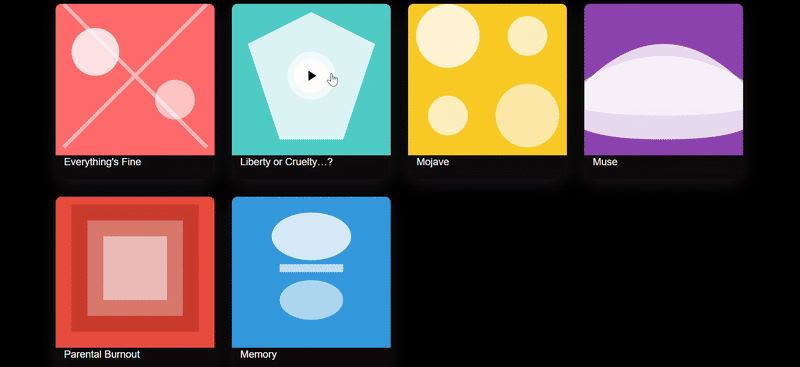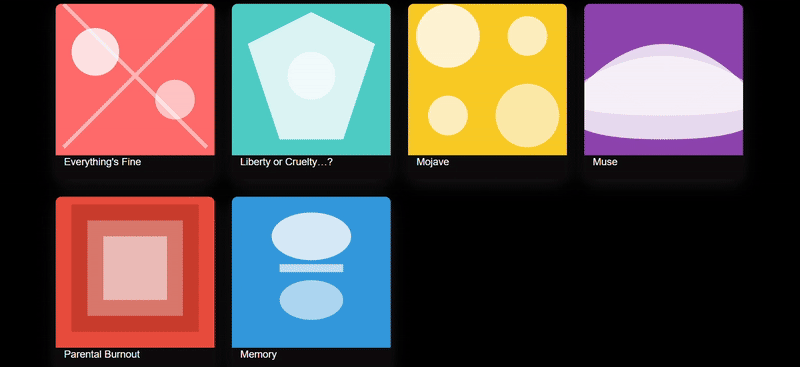
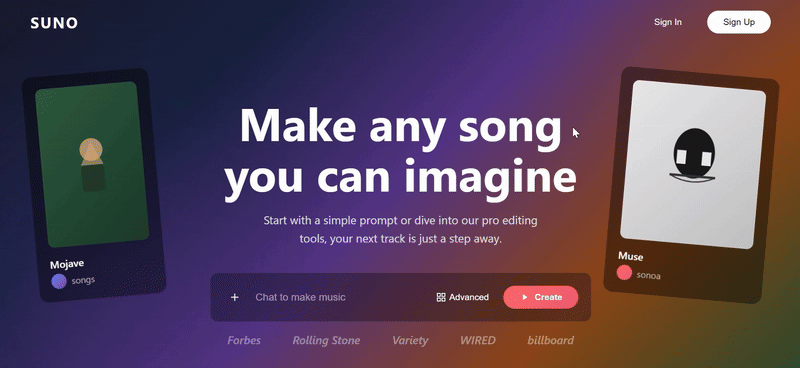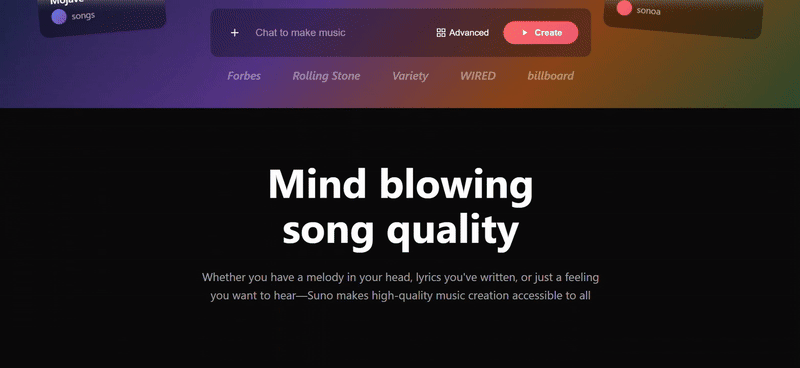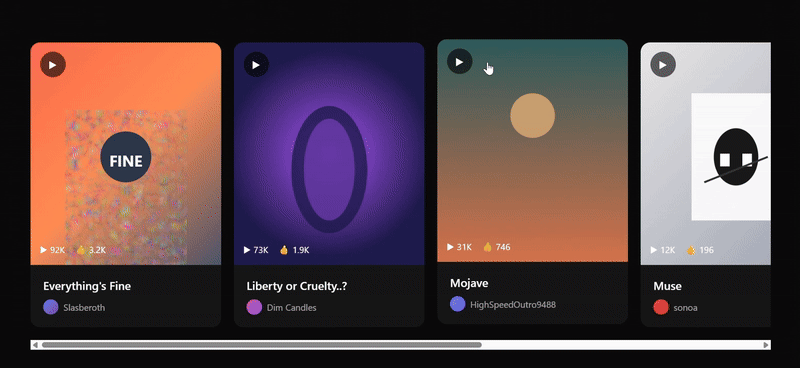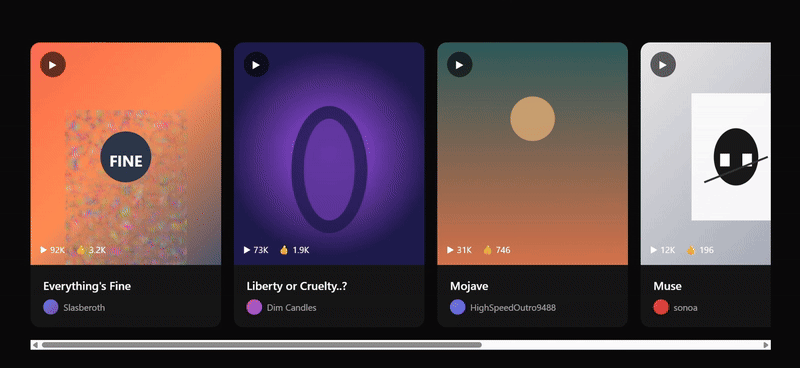
We threw in a couple of screenshots from the Suno website for three models to try to replicate, and only Sonnet 4.5 replicated the 90%. The biggest problem with Doubao's webpage replica was the complete lack of function group keys, and the results were still mediocre even after a second try with a different cue word.
clue: Please try to reproduce this page on the image, the background can be demoed with gradient color/diffuse wind, the image part can be implemented with SVG, and finally all the code will be delivered in one HTML file.
Doubao-Seed-Code:The reduction is low and the code structure is very basic and straightforward.
Deductions:
- Missing details, lack of navigation bar, footer and other components that real web pages should have, low page integrity
- Textbook visuals with raw gradient colors
- Apart from Flexbox and Grid, there is no use of more modern CSS techniques that can enhance visual effects (e.g. animations, filters, complex shadows, etc.)
Kimi k2 Thinking:Visually the restoration is average, but the code is better structured.
Extra credit:
- The SVG waveform animation has been added on its own, and the diffusion effect, button hover animation and shadows are all more modern.
- CSS is well organized, HTML is well structured with navigation bar, branded display area, etc., the page is more like a business website
Deductions:
- The core functionality of the web page (i.e., generating music through text boxes) is underrepresented.
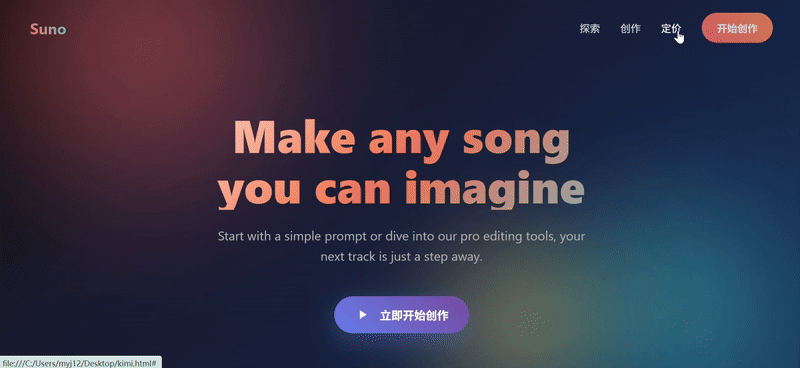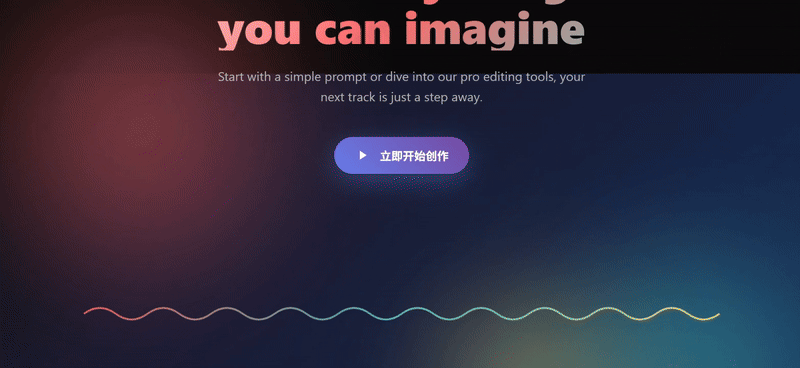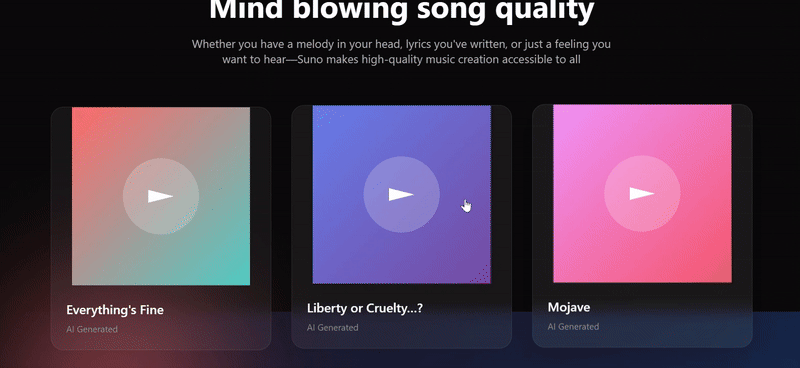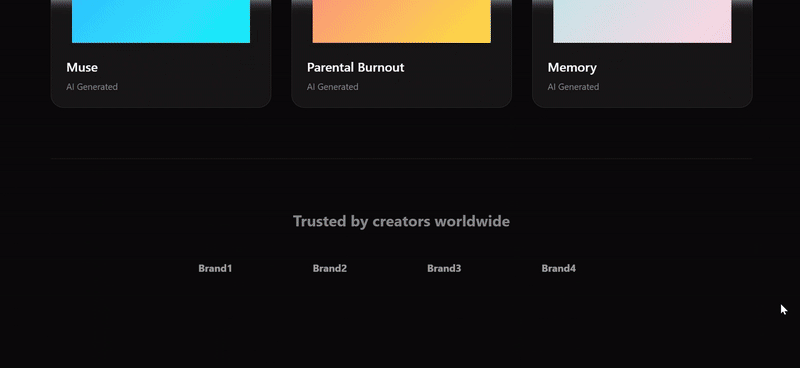
Claude Sonnet 4.5:Best performance. Appearance is the most reproducible and the most central point of superiority over the other two groups is actually theBetter understanding of the prompt “web replica” task。
Extra credit:
- Accurately replicates the core element of the site - the music generation input box
- The angled cards on either side of the Hero area, the wall of media logos at the bottom, and the horizontally scrolling gallery of songs in the second section are very close to Suno's actual layout and design language.
- Details abound, with song cards containing play counts and likes, and artist information with avatars to enhance page realism.
Defects:
- No JavaScript is provided in the code, so interactions are static, which is not as good as Kimi K2's
Modify the cue word and let doubao freehand an AI music generation webpage to try out the effect
clue: Create an AI music generation platform web page that contains:
1. Top branding area and user login
2. Music Composition Workbench: text input box, style selection, generate button
3. Work display area: music cards in a grid layout
4. Playback control bar: progress bar, volume, play/pause Visual style: dark theme, neon blue-violet gradient, techno glass mimicry effect. Eventually deliver all the code within a single HTML file.
Doubao-Seed-Code:
It looks a lot more complete this time around, with all four core sections called for in the cue word accurately created: the top branding area, the creation workbench, the artwork display area, and the bottom playback control bar, and the visual style is largely in line with the requirements.
However, the overall performance is not outstanding, so here are the results of Kimi K2 Thinking with the same cue word as a reference for comparison:
Case 5: Programming Simulation - Applet
clue: Develop a WeChat applet taxi interface:
- Map display (mockable)
- Location and address search
- Choice of models (economy/comfort/luxury)
- Estimated price and waiting time
- One-touch hailing function
- Simple and modern UI design
Requirements: runnable code, smooth interactions
In this task, Kimi K2 Thinking outperformed the other two models with its excellent cue word comprehension and complete functional interaction, and the implementation of the features was more realistic. Doubao's technical implementation is still conservative and its UI design is a bit basic.
Doubao-Seed-Code:Basic realization.
Extra credit:
- Accurate understanding of requirements and implementation of core functionality points (map, address, model selection, estimate information and call button)
- Code logic is clear and easy to understand
Deductions:
- UI design is too basic, the overall layout is simple and flat, not modern enough
- 交互体验缺失,地理搜索功能仅限于静态,缺少实时状态更新
- 技术实现保守,实现了基本功能需求,未体现提升用户体验的高级技巧
Kimi k2 Thinking:超额实现。
Extra credit:
- 功能实现完整,在基础功能上添加了地址转换、加载状态、匹配成功、司机信息等
- 专业 UI 布局,状态栏、实时时间等细节处理到位
- 自主添加了联系司机和取消订单选项,实现了完整的订单流程模拟
Claude Sonnet 4.5:完整实现。
Extra credit:
- 在完整功能的基础上添加了自动定位、地址搜索建议、加载状态、匹配成功、司机信息等
- UI / UX 设计精良,体验流程,叫车成功界面设计较为专业
Defects:
- 地址交换功能缺失,部分交互逻辑略显鸡肋
III. Doubao-Seed-Code findings

Doubao-Seed-Code 展现出一种颇具矛盾感的特质。它并非一个在所有维度上均衡发展的“六边形战士”,而更像一个在特定领域表现突出、同时在核心定位上尚有成长空间的“特长生”。其在人类直觉和实用逻辑推理上的惊艳表现,与其在复杂编程模拟任务中的保守和基础化形成了鲜明对比,这使得对它的评价不能一概而论。
首先,在作为一款 Code 模型的核心赛道——编程能力上,Doubao-Seed-Code 的实测表现与官方宣称的顶级跑分还有一定差距。在网页复刻和小程序开发这类考验综合设计、交互实现与代码美学的前端任务中,它的表现是略显保守和教科书式的。其产出的代码结构清晰、基础功能完备,但往往止步于需求的最低可行性实现,缺乏对UI/UX细节的打磨和提升用户体验的现代技术应用。与 Sonnet 4.5 对设计语言的精准复刻、或 Kimi K2 在交互动画上的主动创造相比,Doubao-Seed-Code 在前端创意和工程完整性上仍有明显的追赶空间。这反映出模型在将视觉或复杂需求转化为精良、现代化的前端代码方面,能力尚待加强。
然而出乎意料的是,Doubao-Seed-Code 在人类直觉测试中的表现拔得头筹,展现了卓越的“顾问级”AI 特质。在旅游规划案例中,它能精准洞察用户潜在需求以及模糊偏好背后的核心意图,并以前瞻性的决策逻辑和共情式的风险管理,输出了超出预期的实用方案。这种表现证明了其强大的自然语言理解、逻辑推理和目标导向的决策辅助能力。它并非简单地检索信息,而是在进行真正的“权衡”与“规划”,这种能力在处理非编程类的复杂逻辑问题时具有一定价值。并且,作为其一大亮点,其多模态视觉推理能力达到可用水平。在干扰性较强的典型视觉识别任务中,它能正确完成细粒度识别与逻辑判断,证明了其跨模态理解的基本功,这对于一款以编程为核心的模型而言是显著的加分项。
综合来看,Doubao-Seed-Code 的现状呈现出一种能力分化。它在需要创意、美感和复杂交互的前端编程领域表现平平,但在处理结构化逻辑、进行成本效益分析和提供实用决策支持方面却异常强大。这或许意味着其当前的优化方向更偏向于后端逻辑、算法实现、脚本自动化或作为低成本的通用逻辑推理引擎。其国内最低的定价策略也印证了这一点:它为广大开发者和企业提供了一个极具性价比的选择,尤其适合那些对成本敏感、需求偏向于逻辑处理而非创意生成的应用场景。
总体而言,Doubao-Seed-Code 是一款特点鲜明、性价比突出的模型。它在需要直觉判断与跨模态理解的任务中具备优势,且定价策略极具竞争力。然而,若将其直接应用于对代码创造性、界面精致度或复杂逻辑推理要求极高的生产环境,还是欠缺火候,目前仍需谨慎。
IV. How to use on 302.AI
1. Use in chatbots
步骤指引 :应用超市→机器人→聊天机器人→立即体验
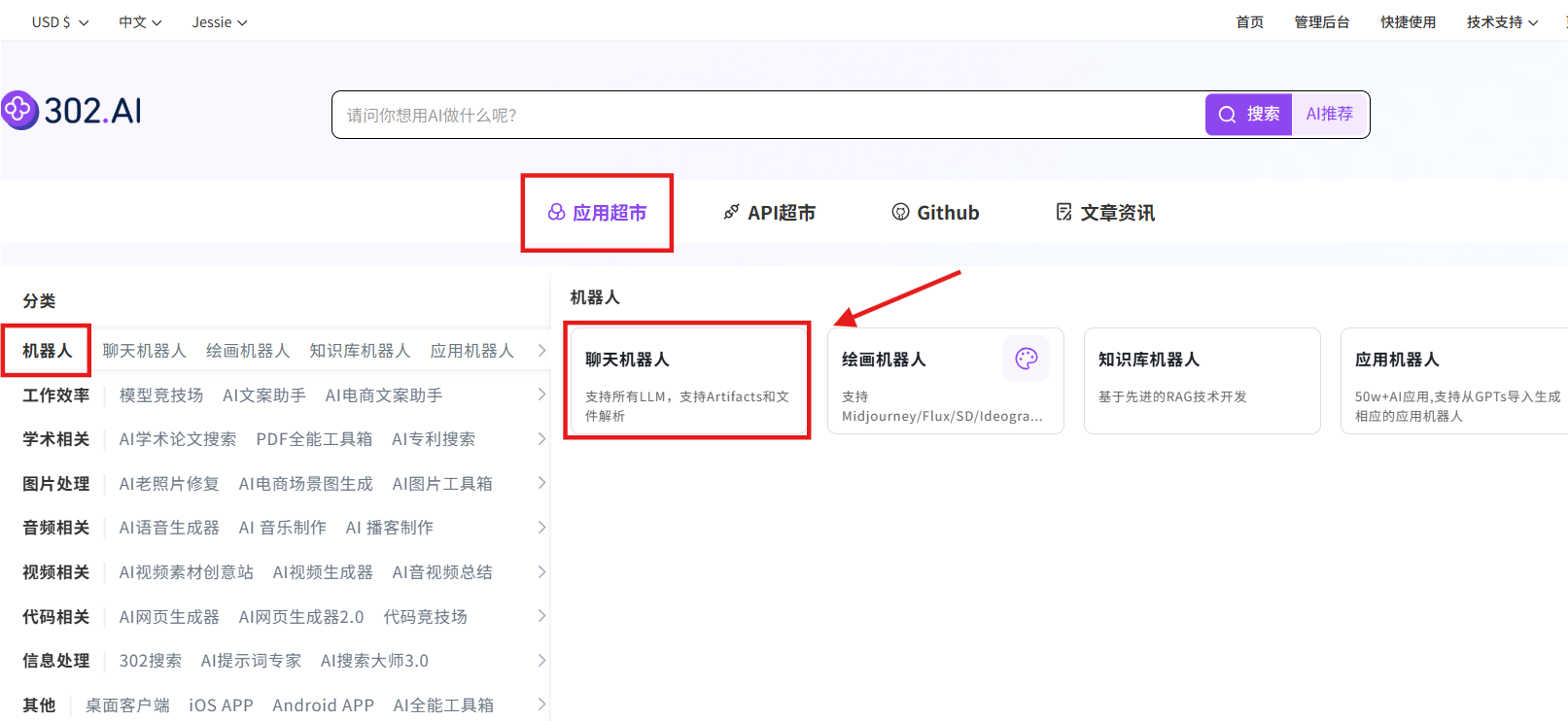
选择模型:国产模型→doubao-seed-code-preview→确认→创建
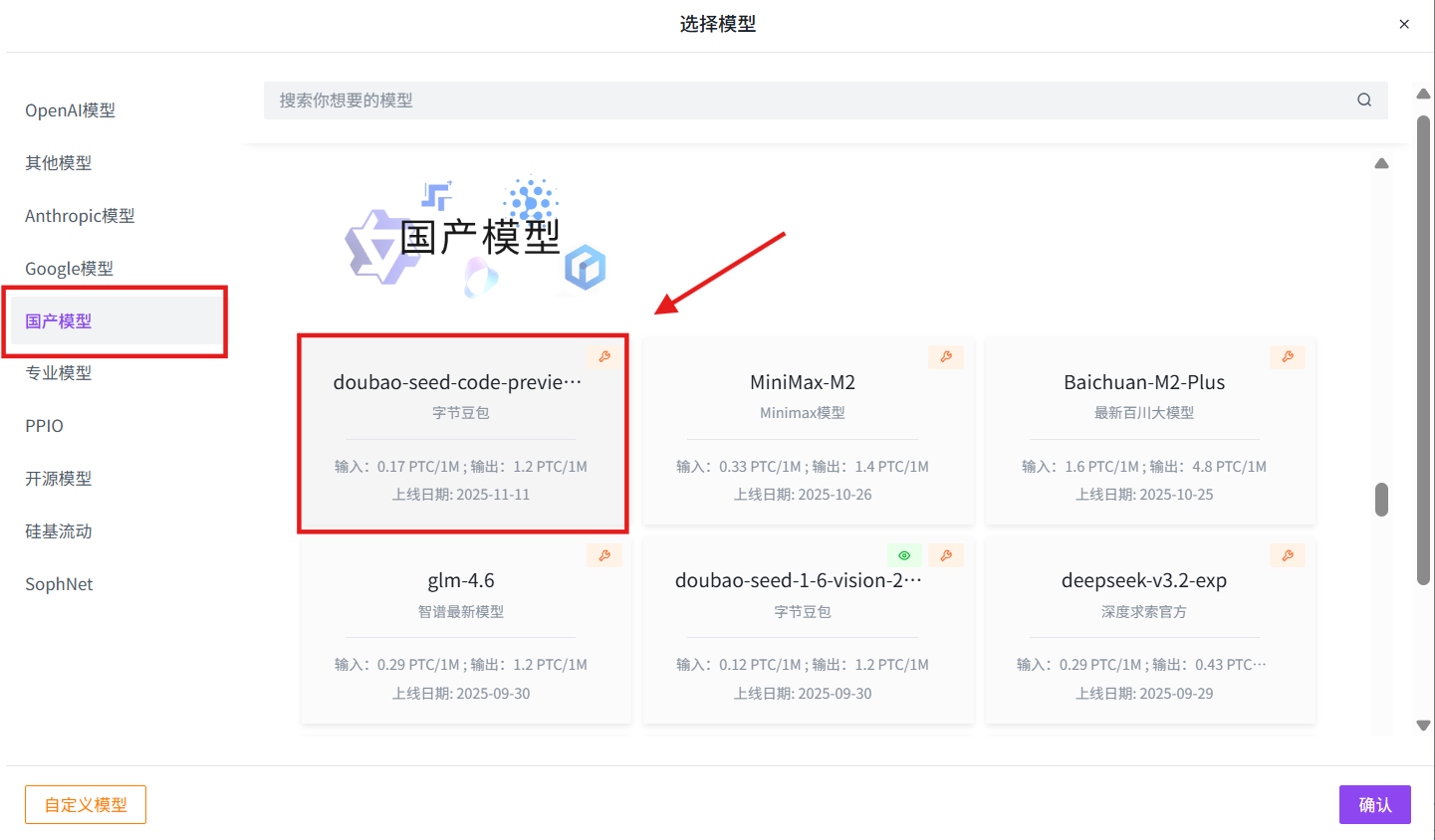
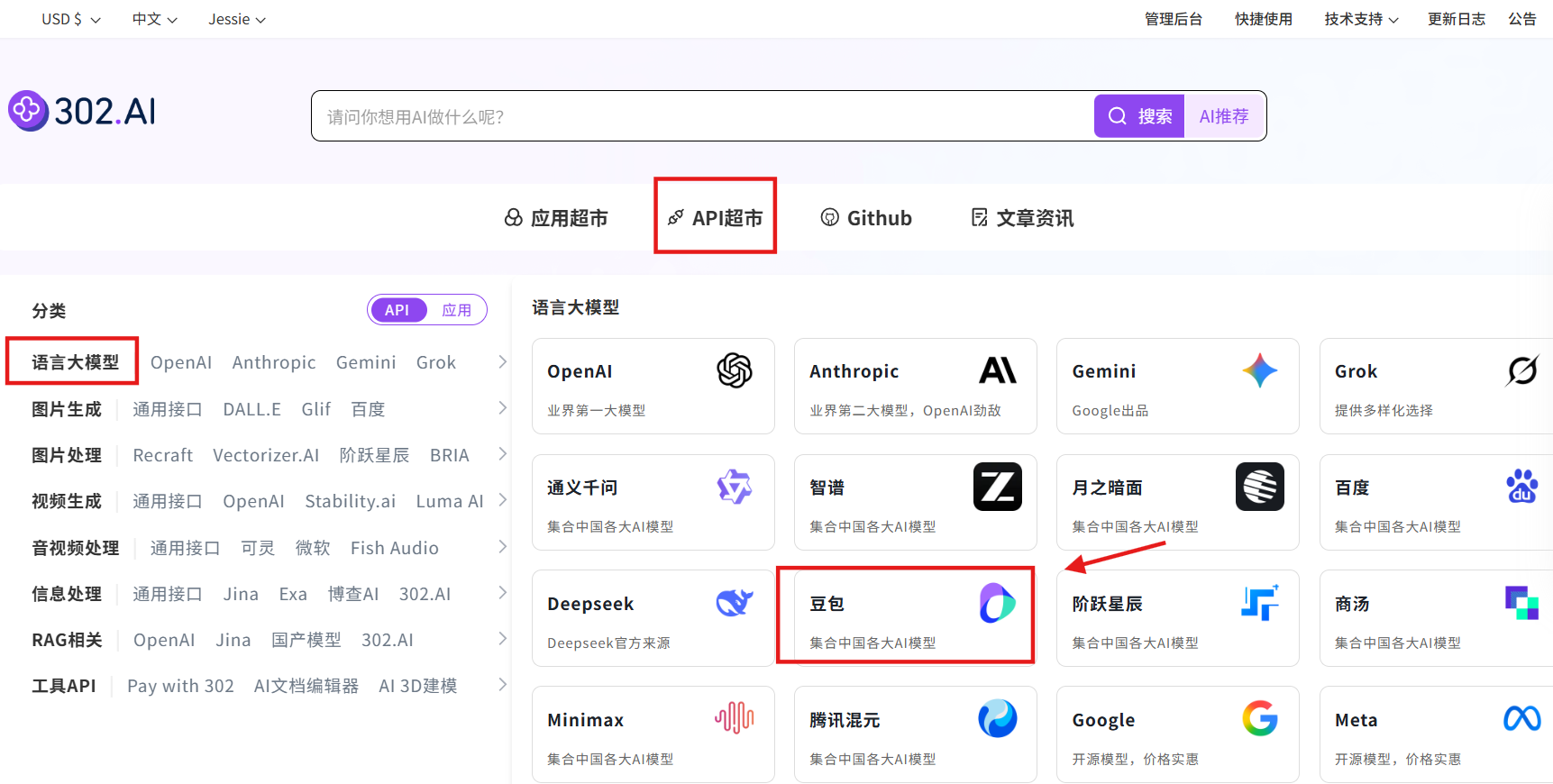
2. Using the Model API
步骤指引:API超市→语言大模型→豆包→doubao-seed-code-preview
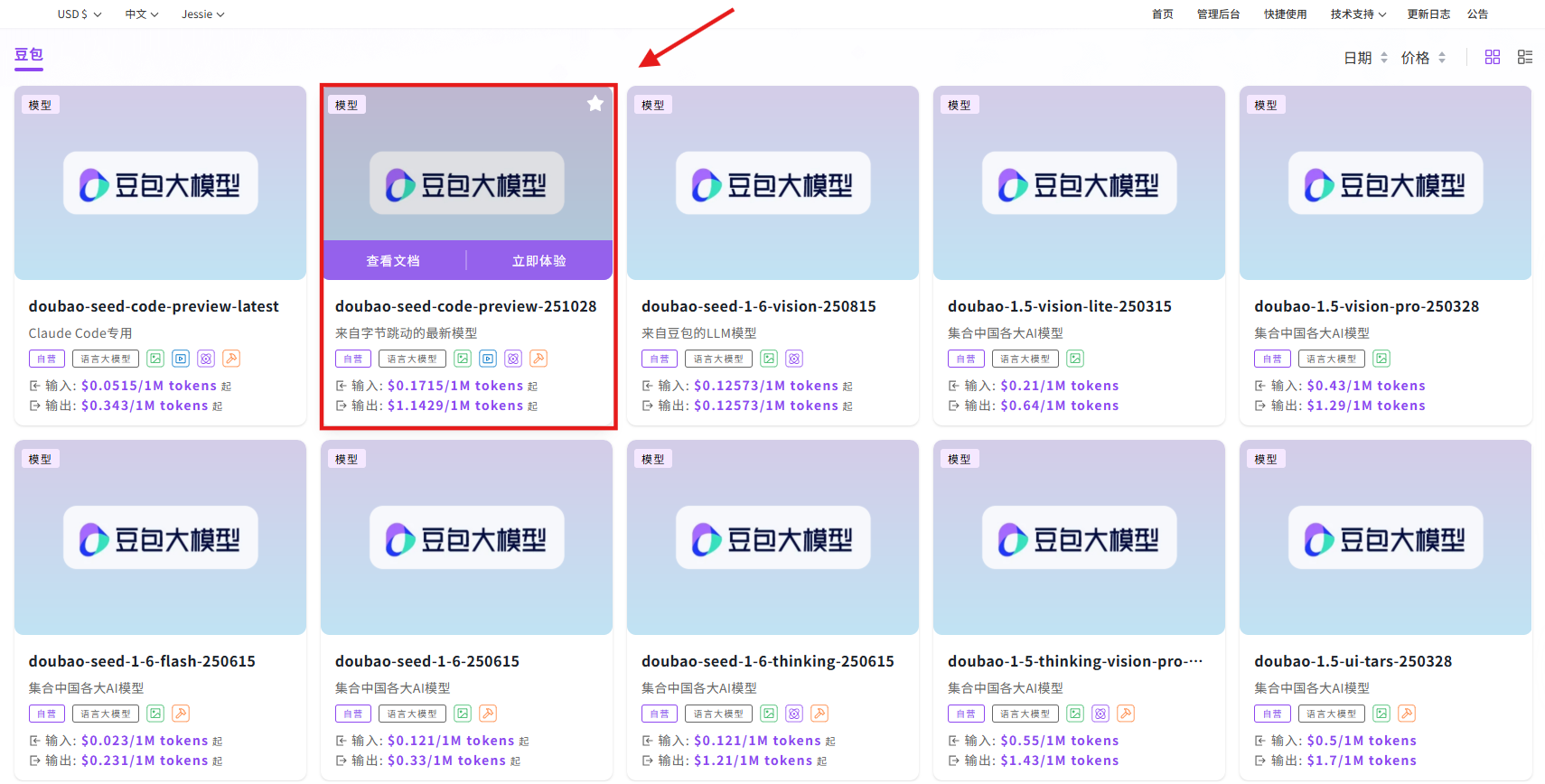
点击【立即体验】在线调用 API
想即刻体验 Doubao-Seed-Code 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
