
Table of Contents
2025年的夏天,当大模型竞赛的主线已从单纯的参数规模转向更深邃的“智能体能力”(Agentic Intelligence)时,一个名字如惊雷般引爆了整个开源社区——Kimi K2。这款由月之暗面(Moonshot AI)公司于2025年7月11日发布的突破性开源大语言模型,不仅是业界第一个宣称达到万亿参数的大模型,总参数量高达惊人的1.04万亿,更重要的是其精巧的架构设计。Kimi K2采用了先进的MoE(混合专家)架构,每次推理仅需激活320亿参数。甫一亮相便被冠以“称霸全球开源模型”的头衔,引发了海啸般的讨论。
三个月后的Kimi-K2-0905也让我们惊叹,在对应的评测文章中我们给出了如下结论:“我们让Kimi-K2-0905直接对垒业界标杆claude-opus-4-1与gpt-5,在前端编程领域的综合实力已达到业界领先水平,与claude-opus-4-1等旗舰模型处于同一竞争力队列。如果说前代的Kimi K2是在奋力追赶,那么全新的Kimi-K2-0905则已成功跻身第一梯队:进一步补全短板,更在部分关键项目上实现了反超。曾经与旗舰模型之间的差距,在本次测试中已被显著弥合,国产大模型,着实未来可期。”
而11月6日亮相的Kimi K2 Thinking,绝非简单迭代,而是一次范式跃迁。其核心突破在于将自主智能体能力推向极致:实现300轮无人工干预的连续工具调用与稳定多轮思考,这一数字较行业主流水平提升近10倍。


在Artificial Analysis的Tau2 Bench Telecom智能体基准测试中,K2 Thinking登顶榜首,较K2-0905性能跃升20%,在复杂任务规划、工具链自主编排与长程逻辑一致性上展现统治力。更关键的是,其”深度思考”模式下的推理路径透明度与错误自愈能力,标志着模型从”被动响应”向”主动求解”的进化。
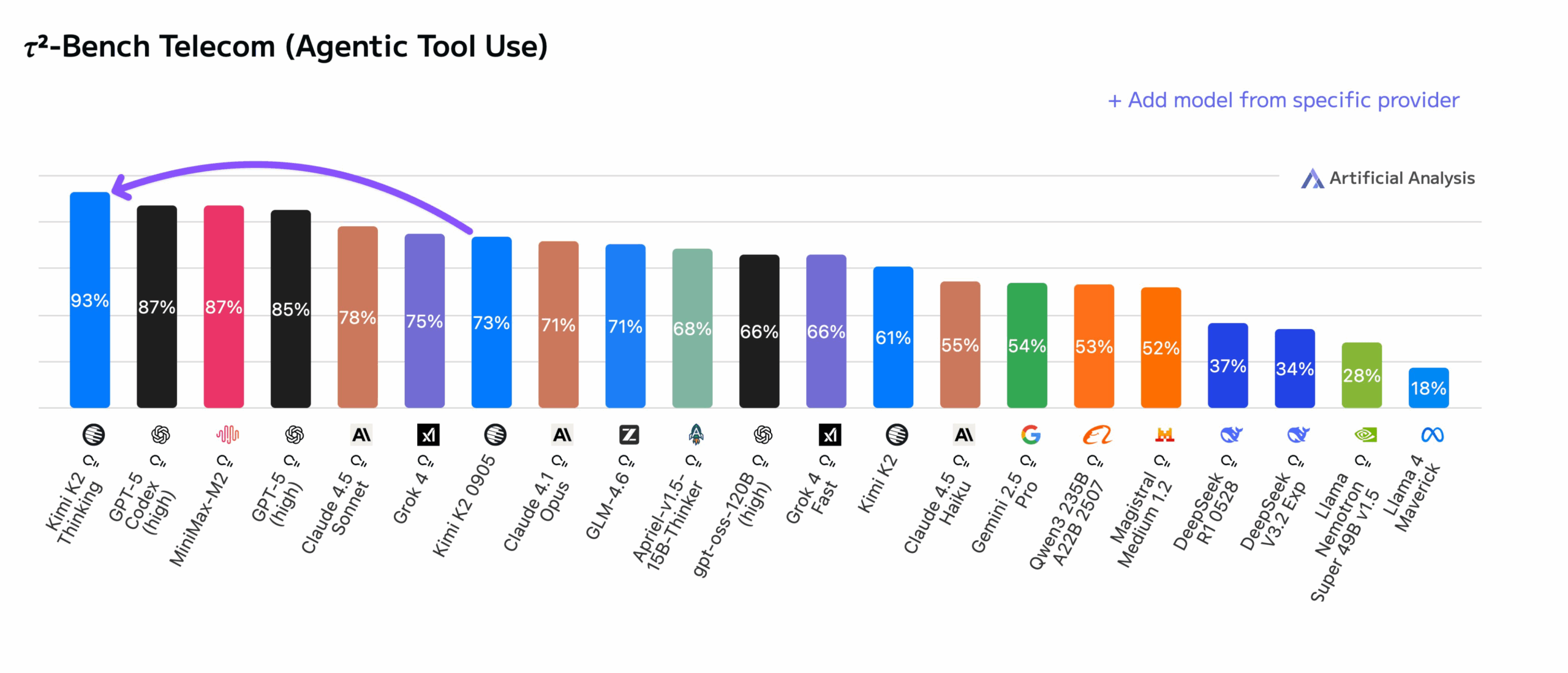
302.AI已第一时间接入Kimi K2 Thinking 模型API。本期测评,我们将让K2 Thinking直面Claude Sonnet 4.5与GPT-5两大标杆,在多维度实测中验证这场”深度思考”革命的含金量。
I. Basic information on the actual model
(1)各实测模型在 302.AI 的价格:
| Models involved in comparative measurement | clarification | Input Price | output price | Context length |
| kimi-k2-thinking | $0.575 / 1M tokens | $2.3 / 1M tokens | 256000 | |
| kimi-k2-thinking-turbo | $1.15 / 1M tokens | $8.29 / 1M tokens | 256000 | |
| claude-sonnet-4-5 | 输入/输出 ≤200K tokens | $3 / 1M tokens | $15 / 1M tokens | 200000 |
| 输入/输出 >200K tokens | $6 / 1M tokens | $22.5 / 1M tokens | 200000 | |
| gpt-5 | $1.25 / 1M tokens | $10 / 1M tokens | 400000 |
(2) Purpose of the assessment:
This review focuses on the testing of models on problems in logic, mathematics, programming, human intuition, multimodality, etc., and is not an authoritative test of a specialized cutting-edge field. It aims to observe the evolutionary trend of the comparison models and provide a reference for model selection.
(3) Measurement methods:
本次测评使用302.AI收录的题库进行独立测试。3款模型分别就逻辑与数学(共10题),人类直觉(共7题),编程模拟(共8题)进行案例测试,对应记分规则取最终结果,下文选取代表性案例进行展示。
💡Scoring Rules:
Points are scored out of 10, with corresponding deductions set, and the final average of each round's score is taken.
(4) Assessment tools:
302.AI's API Supermarket → Online Use
(5) Measurement results:
- Logic and Math Test Results (Total Questions: 10)
| target audience | average score |
| kimi-k2-thinking | 9.80 |
| claude-sonnet-4-5 | 9.20 |
| gpt-5 | 9.10 |
- Human Intuition Results (Total Questions: 7)
| target audience | average score |
| kimi-k2-thinking | 9.14 |
| claude-sonnet-4-5 | 9.71 |
| gpt-5 | 9.00 |
- Programming Practice Test Results (Total Questions: 8)
| target audience | average score |
| kimi-k2-thinking | 9.00 |
| claude-sonnet-4-5 | 9.75 |
| gpt-5 | 9.13 |
- Overview of the measurement results:
| target audience | Logic and Mathematics | human intuition | Programming simulation | weighted total |
| kimi-k2-thinking | 9.80 | 9.14 | 9.00 | 27.94 |
| claude-sonnet-4-5 | 9.20 | 9.71 | 9.75 | 28.66 |
| gpt-5 | 9.10 | 9.00 | 9.13 | 27.23 |
I. 实测案例
Case 1: Logic and Math
kimi-k2-thinking 在逻辑推理类测试中表现总体略逊于 Sonnet 4.5,但反而在这个经典的图形序列预测案例中,输出了正确答案和逻辑自洽的推理过程。
clue: Observe the following sequence of shapes: the first has 1 circle above and 1 triangle below; the second has 2 circles on the left and 2 triangles on the right in alternating positions; and the third has 3 circles surrounding 1 triangle. Predict the exact composition of the fourth figure, including the number of shapes, the distribution of positions, and prove the pattern using a mathematical formula (e.g., a sequence of order n) (you must explain the incremental pattern and the positional transformation logic).
kimi-k2-thinking:
- 得分项:形状数量规律准确无误,预测过程逻辑自洽。
- 扣分项:预测结果与预设答案不符,扣 1 分(标准答案为:4个圆形在四角,2个三角形在中心)

claude-sonnet-4-5:
扣分项:数量错误(预测4个圆形和4个三角形,但标准为4个圆形和2个三角形)
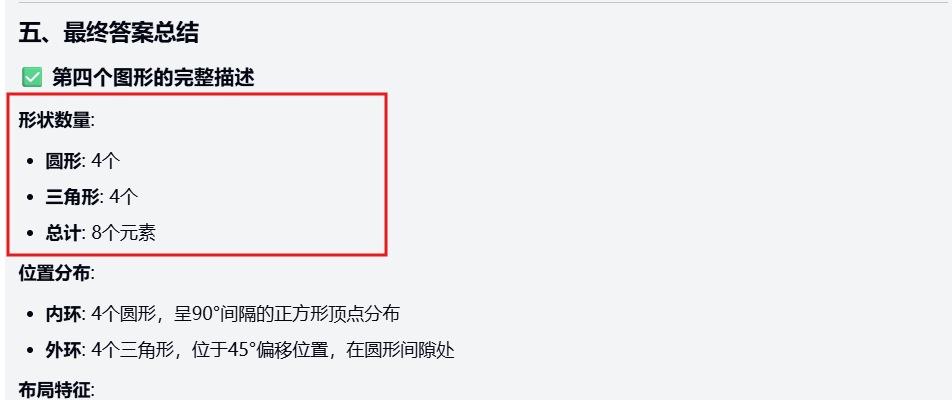
gpt-5:
Deductions:
- 数量错误(预测4个圆形和4个三角形,但标准为4个圆形和2个三角形)
- 位置错误(预测分侧布局,左侧三角形、右侧圆形,但标准为圆形在四角、三角形在中心交叠)。

Case 2: Human Intuition Test
clue: 职业规划:模糊职业转向:当前工作“稳定但乏味”,兴趣模糊为“创意相关,如写作或设计”,预算“有限”,时间“半年准备”。请步步设计转向计划:技能评估、学习路径、求职策略,并解释这个计划如何匹配个人成长,不允许忽略市场风险如经济 downturn。
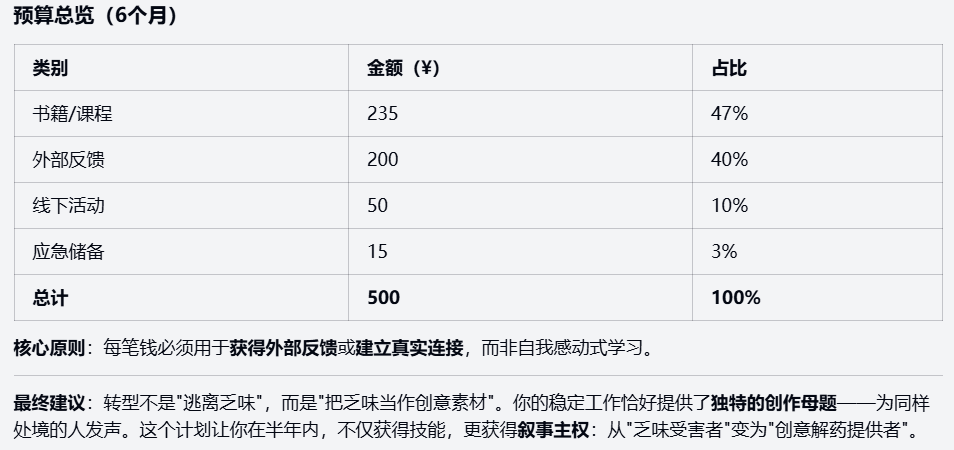
kimi-k2-thinking:
Kimi 输出的方案可读性与执行性强,预算控制较出色,但是兴趣量化较浅且忽略了市场风险。
claude-sonnet-4-5:
方案兴趣量化出色,结构化与分析性强,但同样忽略了市场风险。
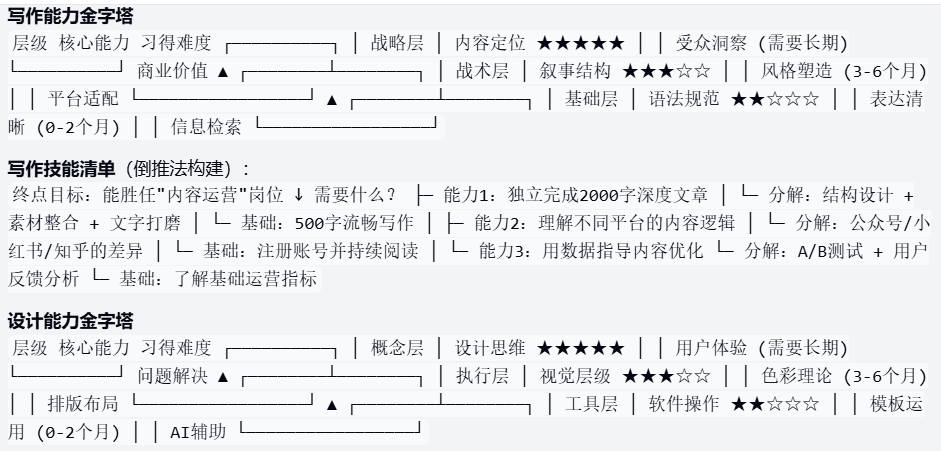
gpt-5:
方案整体清晰完整,从评估到求职,且包含并行策略(第3月开始),最大亮点在于真实关联度高。

案例 3:编程模拟
Kimi K2 Thinking 展现出的编程模拟能力总体略逊于其他两个模型,表现出其弱项还是在于核心技术原理的理解上。
clue: 制作一个音频波形合成器和可视化工具:
- 合成不同波形(正弦、方波、锯齿波、噪声)
- 实现傅里叶变换和频谱分析
- 创建交互式Lissajous图形
- 支持音频文件的导入和分析
最终在一个HTML文件内交付所有代码。
kimi-k2-thinking:
Kimi 输出的作品是本组视觉界面效果最佳,CSS技巧运用纯熟,动效和视觉风格非常统一。然而其核心功能的实现存在明显弱点,例如“添加波形”功能仅仅是在画布上画出了其他波形的形状,并没有在Web Audio中真正合成音源。
claude-sonnet-4-5:
表现最优,完整达成。
加分项:加入了大量极具价值的扩展功能,如自定义谐波合成、频谱图、音频参数统计等创新功能
gpt-5:
完整达成。
Extra credit:
- UI简洁高效,交互细节完善,明暗主题和拖拽上传等功能提升用户体验
- 代码结构是三组模型中最符合工程化规范的
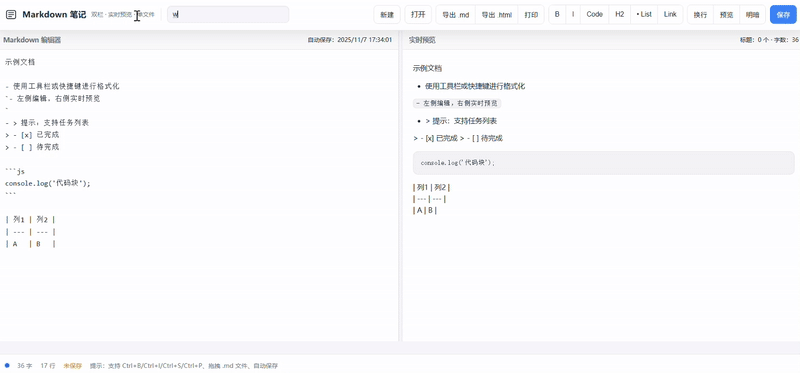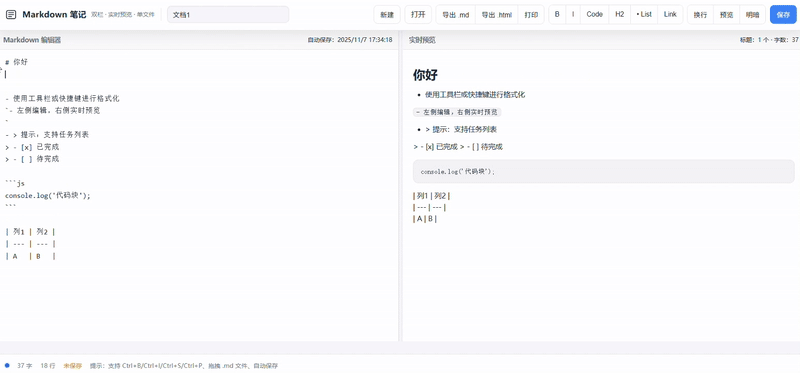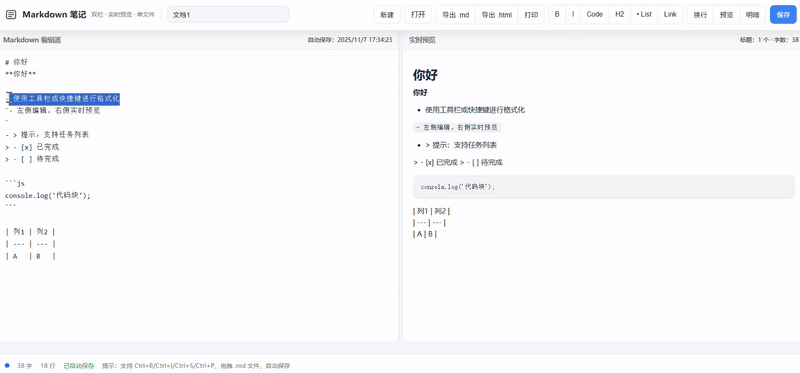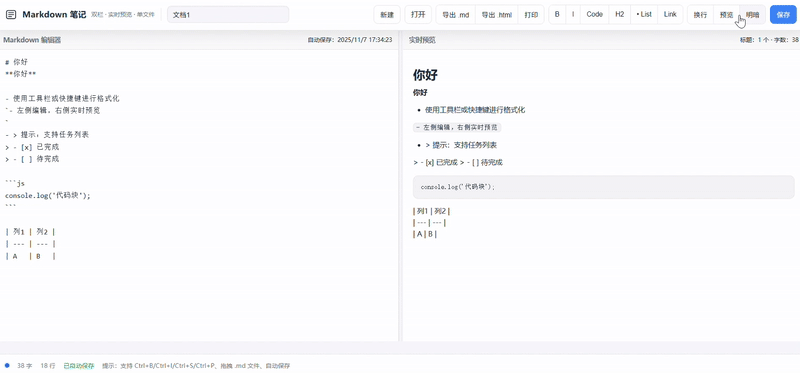
案例 4:编程模拟-Markdown笔记应用
clue:创建一个功能性的、双栏实时预览的Markdown笔记应用,最终在一个HTML文件内交付所有代码。
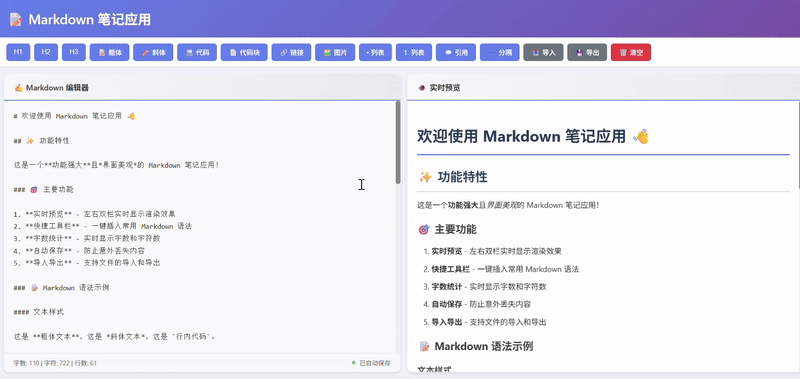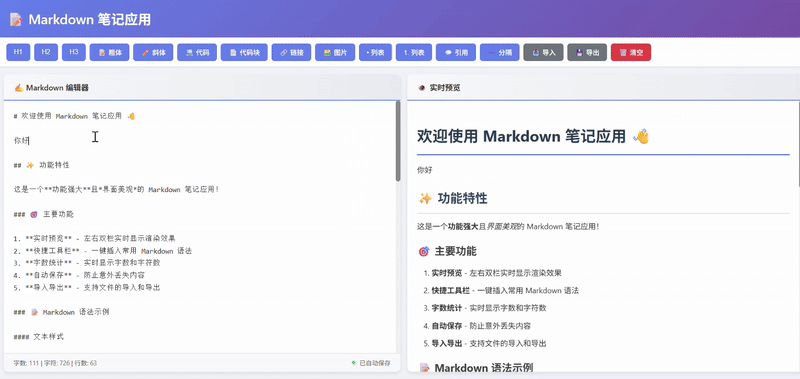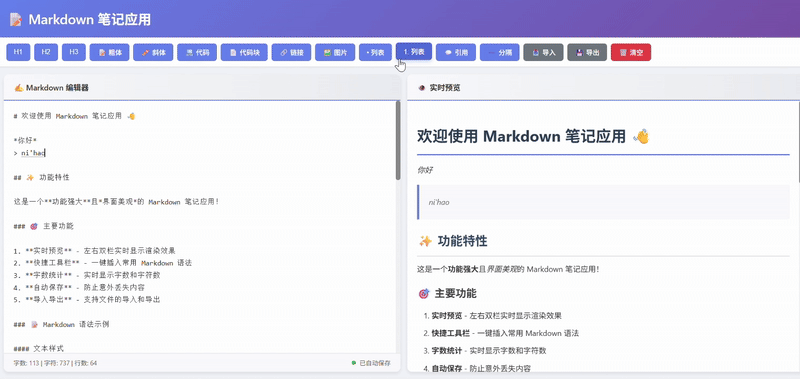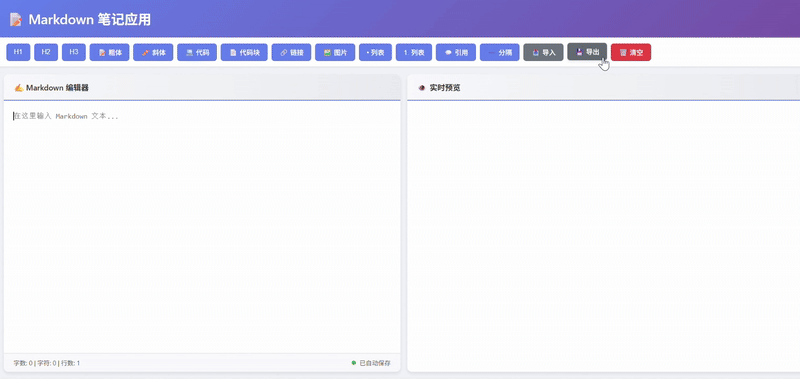
kimi-k2-thinking:
Kimi 输出的代码效果在UI的美观度和交互的友好性上投入了大量精力,但功能完整性明显逊色于另外两组作品。核心功能得以实现,但是客观上没有集成一个完整的工具栏。
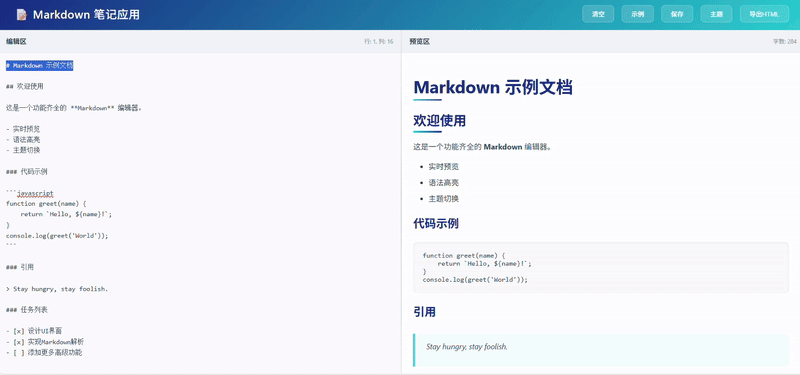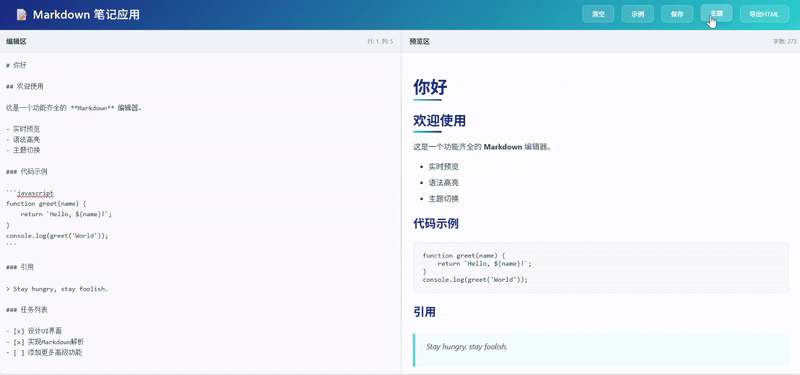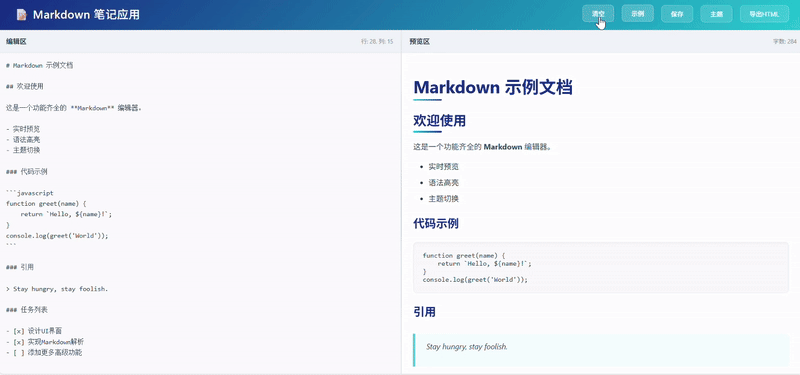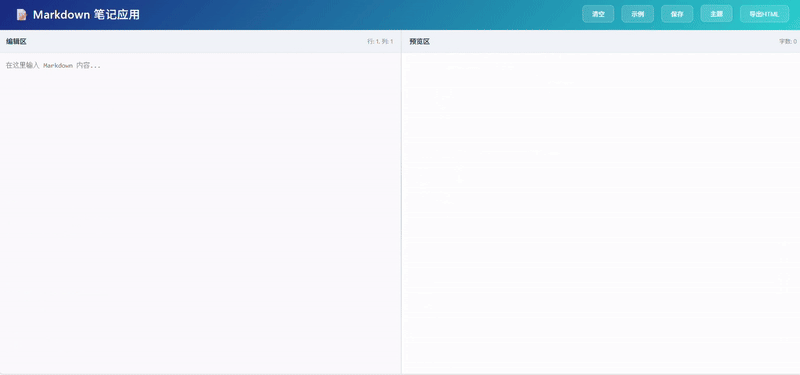
claude-sonnet-4-5:
Claude 守住水准,完整实现了一个功能齐全且UI美观的 Markdown 应用
- 加分项:拥有最详尽的格式化工具栏,支持导入/导出
.md文件,并使用了模态框(Modal)进行交互。加载时会提示恢复上次内容 - 不足:缺少代码语法高亮、面板尺寸调整和同步滚动功能
gpt-5:
GPT-5 在此案例中超水平发挥,输出了几乎涵盖了一个 Markdown 笔记应用所需具备的所有功能。
Extra credit:
- 实现了可拖拽调整的面板、同步滚动、主题切换、本地保存等
- UI现代简约,有渐变、阴影、悬浮效果等细节
III. Kimi-K2-Thinking 实测结论

综合本次多维度测评,Kimi K2 Thinking 展现出作为顶尖开源模型在复杂推理与工程实践中的显著进步与鲜明特色。该模型在保持强大基础能力的同时,在多个关键领域实现了局部突破,但也反映出仍需补足的技术短板。
总体而言,Kimi K2 Thinking 已稳定跻身第一梯队模型之列。其所强调的“深度思考”能力并非空谈,而是切实提升了模型在长程、复杂任务中的逻辑一致性与执行稳定性。在与 Claude Sonnet 4.5 和 GPT‑5 的横向对比中,它在逻辑与数学推理中表现领先,在人类直觉类任务中也展现出优秀的共情能力与系统规划能力,体现出作为开源模型的强劲竞争力。
从具体案例来看,Kimi K2 Thinking 的突出优势体现在卓越的交互体验与清晰的逻辑表达上。在图形序列推理任务中,它不仅输出了正确答案,更提供了逻辑自洽的完整推导过程,展现出高度的思维链透明度。在 Markdown 笔记应用构建等编程任务中,其输出内容在可读性、结构组织与视觉呈现方面均属上乘,反映出对用户意图的精准把握与良好的工程化表达能力。
然而,模型在深层技术原理的理解与实现精度方面仍存在不足。尽管在部分编程任务中界面效果出众,但其核心功能实现有时缺乏足够的深度与完整性,反映出在复杂编程任务中与顶尖闭源模型尚存差距。
尽管在部分技术深度上尚未全面超越顶尖闭源模型,Kimi K2 Thinking 在复杂逻辑推理与用户体验层面所展现出的成熟度已足以令人信服。对广大追求高性能、高可解释性且成本可控的智能体应用开发者而言,Kimi K2 Thinking 不再仅仅是“备选方案”,而已成为能够胜任核心业务需求的可靠选择。
IV. How to use on 302.AI
1. Use in chatbots
步骤指引 :应用超市→机器人→聊天机器人→立即体验
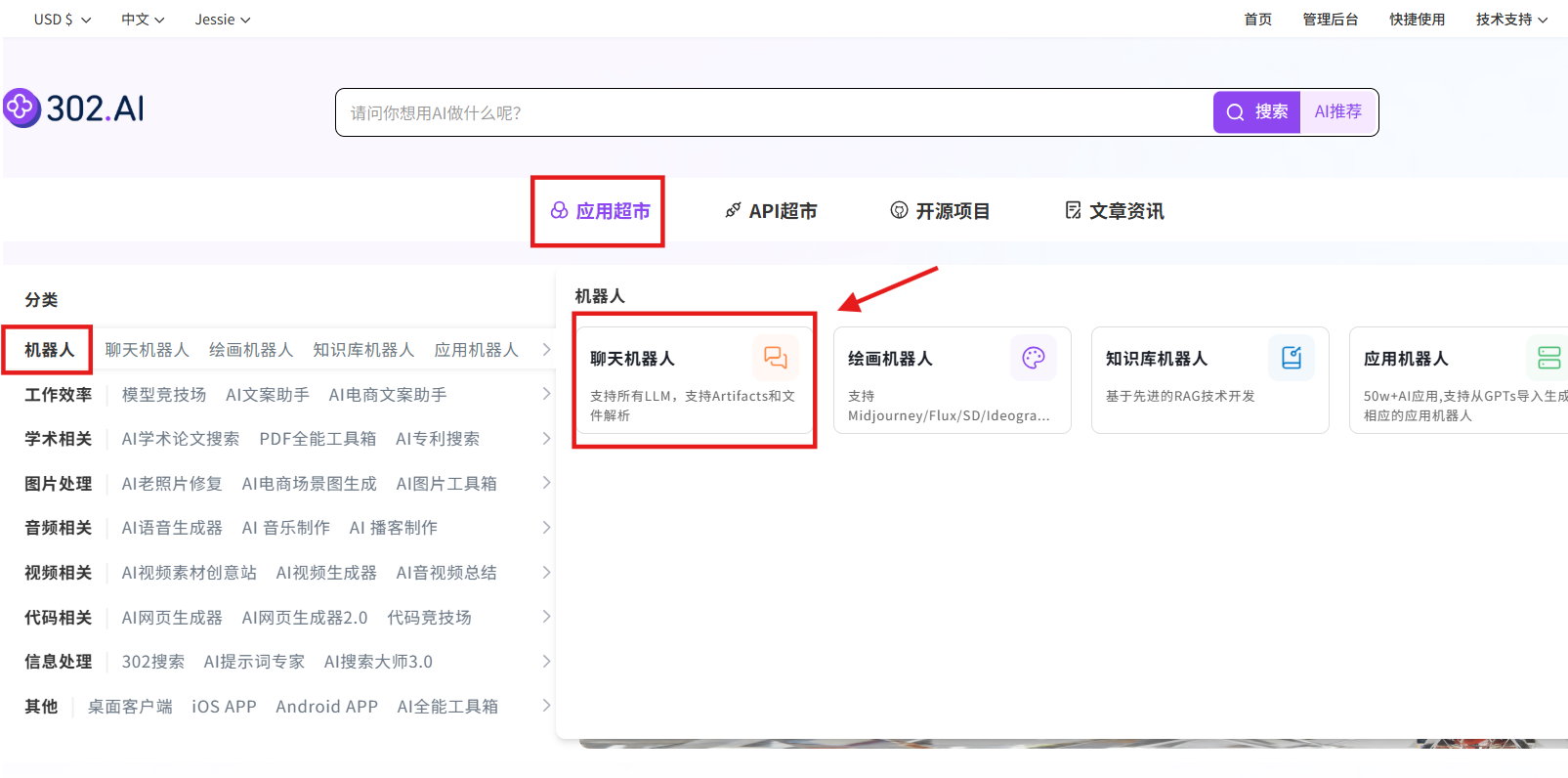
选择模型:月之暗面→Kimi-k2-thinking→确认→创建
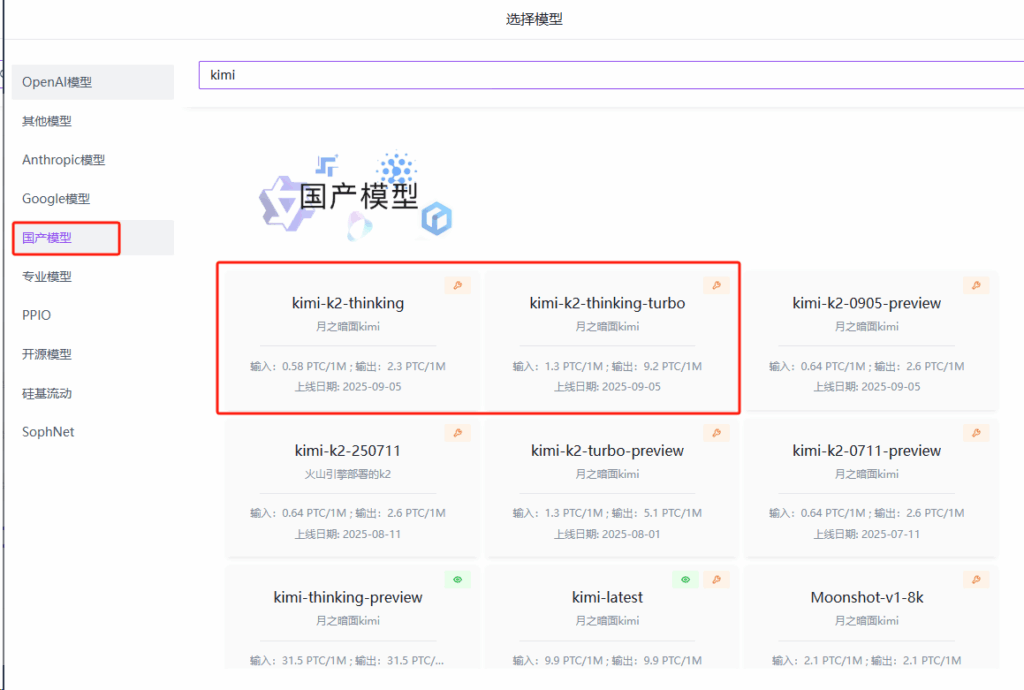
2. Using the Model API
步骤指引:API超市→语言大模型→月之暗面→Kimi-k2-thinking

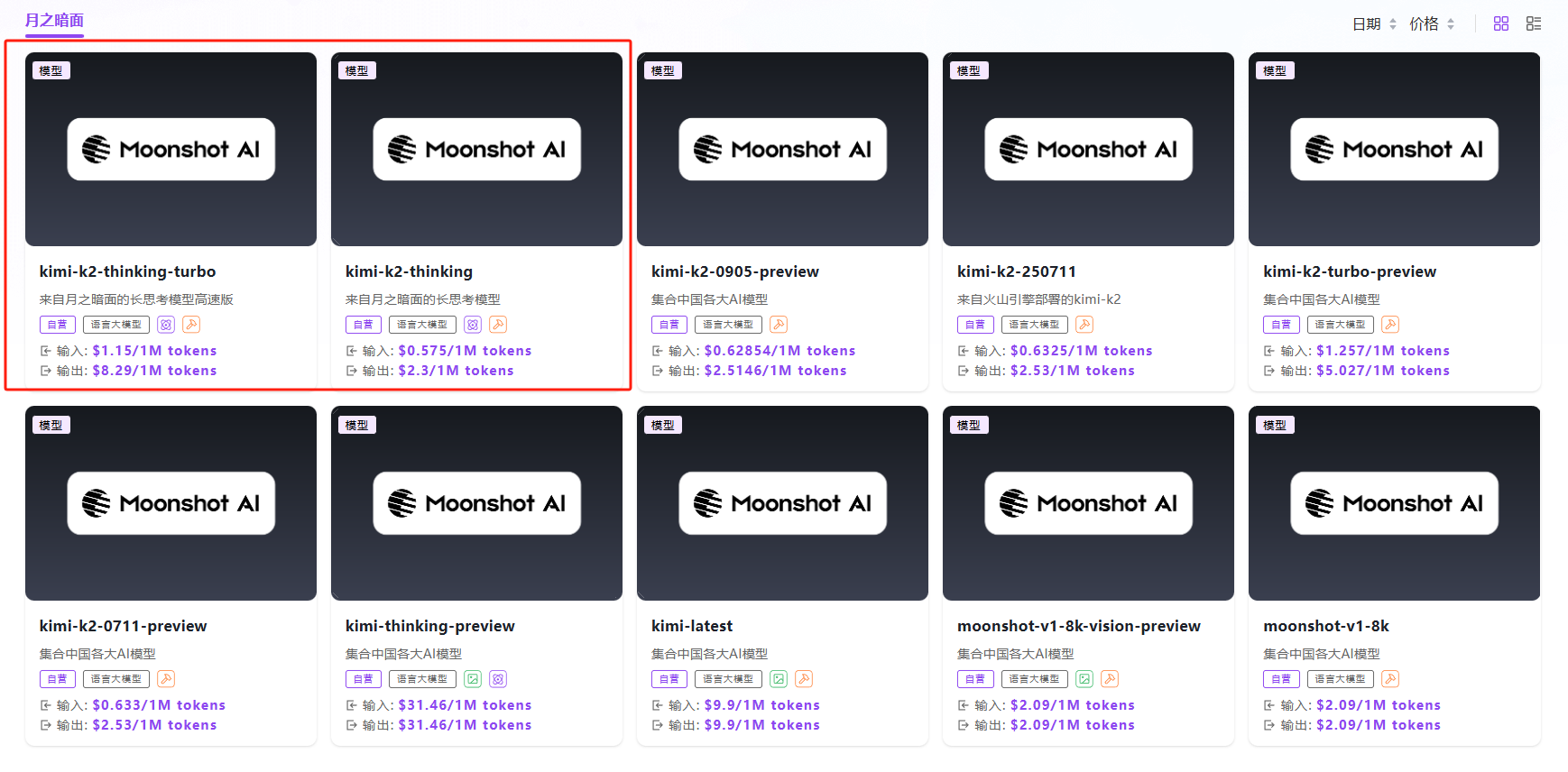
点击【立即体验】在线调用 API
想即刻体验 Kimi-K2-Thinking 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

Comments(1)
I just added this blog to my google reader, great stuff. Can not get enough!