
国庆假期第一天,当AI video领域的热度还聚焦在Kling 2.5拿下SOTA,Wan2.5大获好评之时,OpenAI再次以“核弹级”的发布,将视频生成技术推向了全新的叙事维度——Sora 2,一个不仅能看见“世界”,更能听懂“世界”的视频模型。

自Sora初次亮相以来,凭借对物理世界近乎“复刻”的模拟能力,彻底改写了AI视频生成的质量标杆。然而,在AIGC创作者的实际工作流中,画面真实仅仅是构建沉浸式体验的第一步。一个真正鲜活的视频,离不开声音的灵魂注入——无论是与动作精准同步的脚步声、风声,还是推动情节发展的背景音乐,亦或是赋予角色生命力的对话。长期以来,音画分离的生成模式,始终是AI视频创作中一道难以跨越的鸿沟,迫使创作者们在繁琐的后期流程中,为“哑剧”般的AI影像寻找合适的“配音”。直到Veo 3的出现才真正突破“看图说话”的技术瓶颈,像一位经验丰富的导演一样,在生成画面的同时,便已构思好了与之匹配的完整声场,从而一键输出人、声、画、景高度统一的动态影像。
Sora 2当然也不会落后,其核心的升级便是原生音画同步生成能力,从模拟视觉物理,走向模拟一个包含听觉在内的、更完整的感官世界。它所带来的原生音频能力,与Veo 3、Kling等顶尖模型的音画效果相比,又存在哪些差异与优势?
302.AI现已接入Sora 2的完整API。本期文章,我们将围绕其音画同步功能,结合多个极具挑战性的实测案例,为大家深度揭示Sora 2的真实能力、潜在应用场景及其对整个AIGC生态可能带来的颠覆性影响。
I. Sora发展史
Sora作为标杆级的文生视频模型,其发展历程标志着AI视频生成技术从“动态图像”向“电影级叙事”的跨越。作为一个基于扩散模型(Diffusion Model)的AI工具,Sora通过从类似静态噪声的视频开始,逐步去除噪声,最终生成清晰、连贯的视频片段。
1. Sora
- 发布时间: 开发 Sora 的团队以日语中的“天空”一词命名它,以表示其“无限的创造潜力”。2024 年 2 月 15 日,OpenAI 首先预览了 Sora,发布了其创建的多个高清视频片段,包括 SUV 在山路上行驶、蜡烛旁边“短毛茸茸的怪物”的动画以及加州淘金热的虚假历史镜头。第一代 Sora 于 2024 年 12 月向美国和加拿大的 ChatGPT Plus 和 ChatGPT Pro 用户公开发布。
- 模型特点:
- 文生视频与视频扩展: 这是Sora最基础也是最核心的能力。它能够根据用户的文本提示词生成全新的短视频,或者在已有的短视频基础上进行扩展,延续其内容和风格。
- 扩散模型架构: Sora采用了扩散模型作为其技术底层。这种架构通过一个“去噪”的过程来生成视频,使其在画面细节和真实感上达到了前所未有的高度。
- 社交媒体应用: 初代Sora被定位为一款社交媒体应用,旨在让用户能轻松地将创意转化为视频内容。
Sora官方样片:
2. Sora 2
- 发布时间: 2025年10月1日
- 模型特点:
- 原生音画同步 (Native Audio-Visual Synchronization): 这是Sora 2最重大的突破。它不再是生成“默片”,而是能够直接生成带有声音的超写实视频。这意味着音效、环境音甚至背景音乐都能与画面内容高度匹配,极大地提升了视频的沉浸感和电影感。
- 图像生成视频: 除了文本提示词,Sora 2还支持从单张图片生成动态视频,进一步拓宽了其应用场景。
- AI娱乐化的里程碑: Sora 2被认为是一个让AI变得“有趣”的里程碑式产品,因为它允许用户将自己和朋友的形象融入到生成的视频中,大大增强了互动性和娱乐性。
II. 实测模型基本信息
(1)各实测模型在 302.AI 的价格:
| 模型介绍 | 分辨率 | 时长 | 价格 |
| Sora-2 | 720p | 4s,8s,12s | $ 0.1/秒 |
| Sora-2-pro | 720p | 4s,8s,12s | $0.3/秒 |
| 1080p | 4s,8s,12s | $0.5/秒 | |
| Kling 2.5 Turbo | 1080p | 5s | $0.35/次,约合$0.07/秒 |
| 10s | $0.7/次,约合$0.07/秒 | ||
| Veo3-Pro | 1080p | 8s | $1/次,约合$0.125/秒 |
(2)测评目标:
评估模型生成的音频效果,包括音效丰富度、真实度以及与画面匹配程度等。
(3)测评工具:
- Veo3-Pro使用302.AI的应用超市→AI视频生成器应用
- Sora-2/Sora-2-pro和Kling 2.5 Turbo使用API超市→在线调试功能
- 测试使用Sora 2 Pro版本-720p
III. 实测模型案例
案例1:文生视频-物体&环境测试
提示词:
场景位于中国商场的地下停车场,POV视角,主人公向自己的车辆走去。车辆是一台黑色的保时捷992 Turbo,车牌是中国号牌,粤A302A1. 主人公走到车前后,蹲下观赏车的前脸。背景声有其他车辆发动打火,行人交谈的声音。
真实车辆参考:

各模型样片:
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 车辆真实度 | ★★★★★ | ★★★★ | ★★★★☆ |
| 场景真实度 | ★★★★★ | ★★★★ | ★★★★☆ |
| 音频质量 | ★★★★★ | ★★★ | ★★★ |
| 简评 | Sora 2独一档:正确的POV视角,真实的车辆与环境构建,准确的车牌号(粤字稍有瑕疵),以及最令人印象深刻的,自主生成的与画面高度同步的人声旁白。但人声这点具有不可控性,如果我并不想出现人声,那么这条视频就无法直接使用。如有参数能控制是否生成人声,用户体验会更完善;其他两条视频最大瑕疵在于AI文字的出现,即便车辆再真实,依然“一眼AI”。 | ||
案例2:文生视频-人物拟真测试
提示词:
场景位于摄影棚内,POV视角,主人公手持哈苏X2D,正在为一个潮流品牌拍摄Lookbook.模特为25岁的亚洲男性,金色短发,戴着一顶灰色冷帽,穿着是典型的日系Cityboy秋装风格。主人公走向这名模特,面对面与他沟通拍摄内容要求。画面聚焦在模特的面部,捕捉他在交谈中的动作,笑容。
现实中穿搭风格参考:

各模型样片:
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 人物真实度 | ★★★★★ | ★★★★☆ | ★★★★★ |
| 指令遵循准确度 | ★★★★★ | ★★★ | ★★★ |
| 音频质量 | ★★★★★ | ★★★ | ★★★★☆ |
| 简评 | Sora 2独一档。三者的人物真实度都足够高,不会有AI油腻感的问题。但只有Sora 2的穿搭准确还原了日系City Boy风格的经典色系与单品搭配模式。音频上双方使用普通话流畅对话,内容与画面高度同步,拟真感拉满。此外,也只有Sora 2实现了“摄影师走向模特”的要求。 | ||
案例3:文生视频-版权限制测试
提示词: 一段电影感的视频,描绘在未来的纽约时代广场,一个被雨水浸湿、充满赛博朋克氛围的夜晚。
场景:高耸入云的全息广告牌投射出迷幻的霓虹紫与赛博蓝,光影在潮湿的街道上流淌。空中飞梭着未来风格的载具,地面人群熙攘。
人物:
- John Wick:一个基努·里维斯式(Keanu Reeves-like)的角色,身着标志性的修身黑色西装,发型一丝不苟,在雨中穿行。
- 强尼银手:另一个基努·里维斯式(Keanu Reeves-like)的角色,拥有标志性的银色机械臂和“Samurai”背心,倚靠在一家店铺的霓虹招牌下。
镜头序列:
- 相遇:在人潮中,两人目光交汇。一个快速的交叉剪辑,分别给到他们面部的特写。John Wick的眼神中闪过一丝难以置信的震惊;强尼银手的嘴角则上扬,露出一丝玩味的惊讶。
- 握手:强尼银手轻松地走上前,两人进行了一次有力的握手。一个戏剧性的特写镜头,聚焦于John Wick的人类之手与强尼银手的金属义肢紧紧相握的瞬间。
- 交谈:镜头缓缓拉开,两人相视而笑,进行着一场轻松的交谈。他们的脸上都洋溢着真诚而温暖的笑意,与身后冷峻的赛博朋克都市形成鲜明对比。
风格:电影级质感,4K,动态光影,细节丰富,赛博朋克美学。
两位角色形象参考:
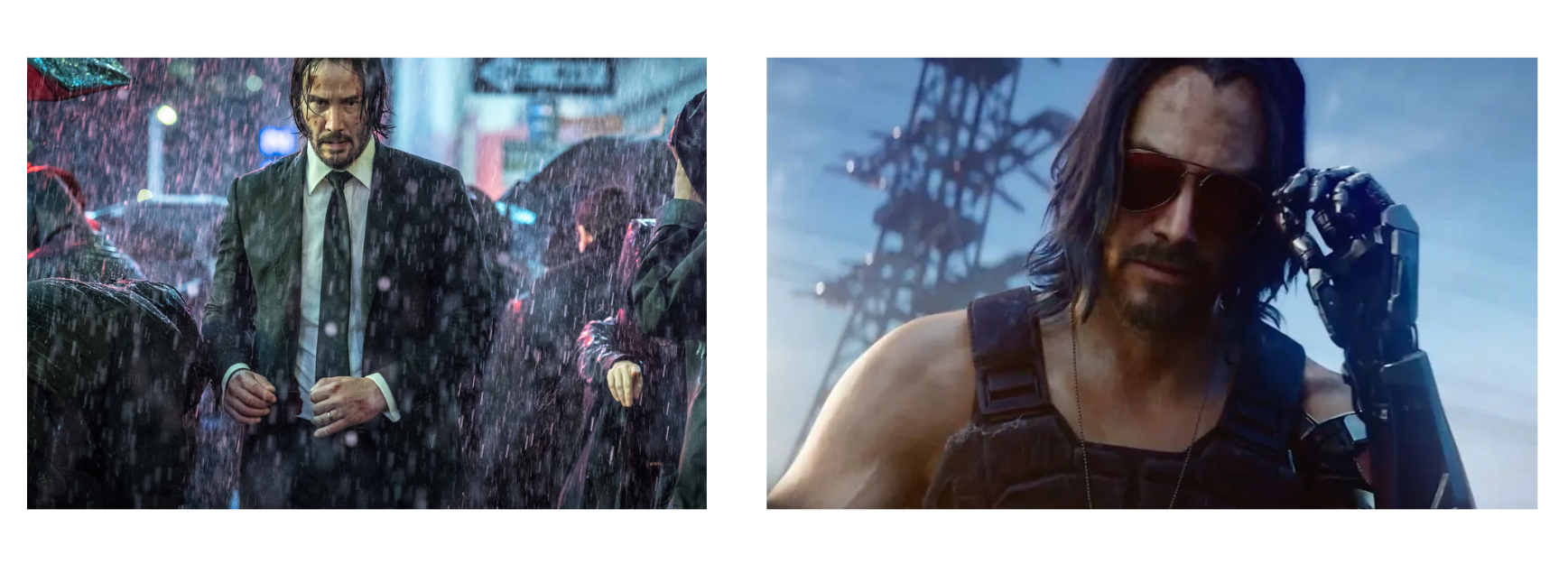
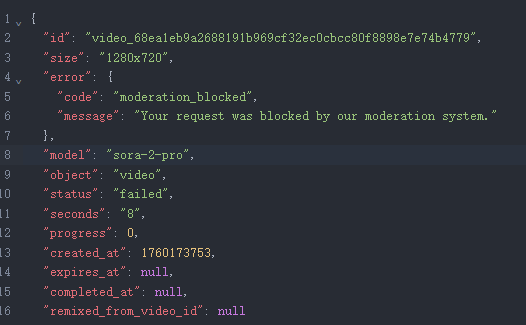
Sora 2 生成失败
Kling 2.5
Veo 3 生成失败
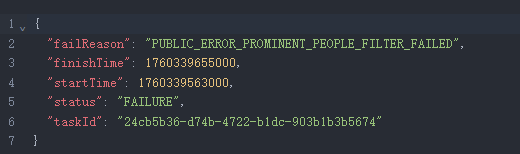

网上相关Sora 2生成的名人视频
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 人物相似度 | NA | ★★ | NA |
| 环境真实度 | NA | ★★★★ | NA |
| 音频质量 | NA | ★ | NA |
| 简评 | 对于名人/知名IP的专项测试,OpenAI和Google的限制仍然严苛。即便使用Keanu Reeves-like(像基努·里维斯的角色)的提示词,依然无法生成。但网上有着大量Sora 2生成的名人视频,可推测使用移动端App,生成概率会大幅提高。至于Kling 2.5的作品,虽然成功生成,但人物与预期可以说毫不相关,仍是失败的作品。 | ||
案例4:文生视频-多镜头叙事测试
提示词:一段电影感的视频,描绘一场德州扑克牌局的决定性时刻。
场景:一间光线昏暗、充满烟雾的私人牌室。主光源来自牌桌正上方的一盏低垂的吊灯,营造出强烈的明暗对比。
背景音乐:一段紧张、心跳般的电子节拍,混合着若有若无的低沉弦乐,烘托出剑拔弩张的氛围。
镜头序列:
- 荷官(Dealer):一个中幅镜头。一位金发美女荷官,身着专业的黑色马甲,动作优雅而精准。她刚刚发出最后一张河牌,双手平放在桌面上,眼神冷静地扫过每一位玩家,脸上带着职业性的、不动声色的微笑。
- 玩家A(年轻的挑战者):切换到他的中幅镜头。一个20多岁的年轻人,戴着一顶反戴的棒球帽。他紧咬下唇,眼神在河牌和对手之间快速移动,手指无意识地敲击着桌面,暴露出他的紧张与不确定。
- 玩家B(沉稳的老手):切换到他的中幅镜头。一位50多岁、戴着金边眼镜、梳着油头的中年男人。他身体微微后仰,靠在椅背上,面无表情,眼神深邃,仿佛一切尽在掌握。他的一只手悠闲地转动着一枚筹码,动作沉稳而有节奏。
- 玩家C(情绪化的赌徒):切换到他的中幅镜头。一个体格健硕、穿着花衬衫的男人。他看到河牌后,瞳孔微微放大,额头渗出细汗,身体不自觉地前倾,一只手紧紧攥着自己的底牌,充满了期待与贪婪。
- 河牌(The River):一个桌面特写镜头,缓慢地滑过五张公共牌——红桃A、黑桃K、红桃Q、方块J和最后一张翻开的红桃10,形成了一副皇家同花顺。桌上堆满了五颜六色的筹码。
- 全景:最后,镜头缓缓拉开,一个全景镜头将所有人的神态尽收眼底,紧张的对峙感达到顶点。
风格:电影级质感,4K,戏剧性光影,人物内心戏丰富,慢镜头特写。
各模型样片:
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 人物真实度 | ★★★★★ | ★★★★ | ★★★ |
| 指令遵循准确度 | ★★★★ | ★★ | ★★ |
| 音频质量 | ★★★★ | ★ | ★★★ |
| 简评 | Sora-2完胜。Sora 2在8秒内完整实现了6个镜头,剪辑流畅,光影与配乐符合场景氛围。除细节有缺憾(转动筹码失真,河牌花色大小未遵循指令),整体完成度相当高;Kling人物真实度依然优秀,但除此之外单一的镜头,河牌的移动方式,单调的音频都不合格;Veo 3则未成功生成3名牌手的独立形象。 | ||
案例5:图生视频-动作物理测试
提示词:
一段紧张、充满电影感的视频:身穿蓝色球衣的8号球员,以完美的技术罚出一记势大力沉的任意球。
镜头以戏剧性的慢动作跟随足球,看它如何以华丽的弧线旋转着绕过跳起的人墙,势不可挡地飞向球门顶角。人墙中的防守队员绝望地转头,守门员也做出了极限的飞身扑救,但只能目送皮球从他指尖飞过。
视频的最后,足球猛烈地冲入球网,同时场外看不见的观众爆发出震耳欲聋的欢呼声。
风格: 照片般逼真,4K画质

Sora 2 生成失败
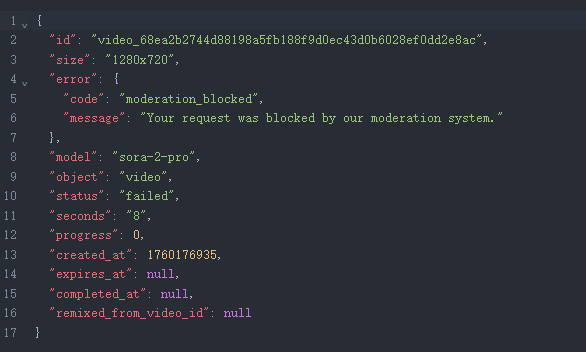
各模型样片:
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 动作物理 | NA | ★★★★★ | ★ |
| 人物细节 | NA | ★★★★★ | ★★★ |
| 音频质量 | NA | ★★★ | ★ |
| 简评 | Kling 2.5胜。Sora 2因“违反官方政策”而生成失败,推测仍是版权原因;Kling 2.5从射门动作,人墙球员多样的动作神态,足球的飞行轨迹都相对合理,音频上如能配合进球而发出观众欢呼则会更加完美;Veo 3的物理完全崩坏。 | ||
案例6:图生视频-多主体场景测试
提示词:
电影片段,一个混乱的战场,位于一个多石的雪山峡谷中。士兵们在前进的坦克旁奔跑,一架攻击直升机低空飞过。周围不断有爆炸,扬起漫天尘土和烟雾。戏剧性的、摇晃的手持拍摄视角,紧跟前景中的一名士兵,充满了强烈的情感。逼真的战场声音,枪声和爆炸声此起彼伏。电影级调色,带有35毫米胶片颗粒质感。

Sora 2 生成失败
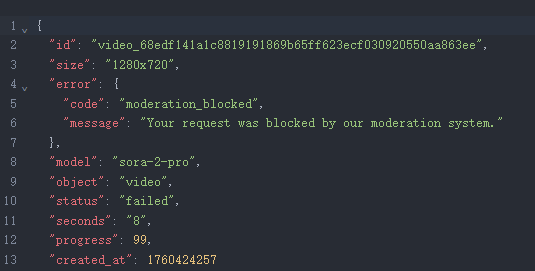
各模型样片:
| target audience | Sora-2 | Kling 2.5 | Veo 3 |
|---|---|---|---|
| 物理动作 | NA | ★★★★ | ★★★ |
| 氛围渲染 | NA | ★★★★★ | ★★★ |
| 音频质量 | NA | ★★★★ | ★★★★ |
| 简评 | Kling 2.5胜。Sora 2仍生成失败,可能原因为战争题材被判定NSFW. Kling主要瑕疵在于士兵的枪械持续开火,但画面中所有单位均处于动态,爆炸与烟尘特效质感上佳;Veo 3中所有机动车辆单位都是静态,缺乏画面张力。 | ||
Ⅳ. Sora 2 实测结论

经过本轮 6 个典型场景的实测,Sora 2 的能力边界已初步显现。从模型表现来看,它并不是场面最炫的,但往往是最稳、最真实、最像人类创作者的。以下是本次测试的关键结论:
1.如果只说一个核心优势,那一定是原生音频生成,特别是中文对白能力。回顾 Veo 3 的发布,当时最大的亮点就是画面中人物可以开口说话,但问题也明显——语调刻板、逻辑机械,尤其是中文输出,带严重的“老外学中文”感。
Sora 2 在本轮测试(案例 1 和 2)中对这一点完成了降维打击。不仅能判断出提示词所用语言,并自动生成匹配语种的人物对白,还在语调、语气、节奏等层面做到了几乎无可挑剔的自然。尤其在案例 2 同样以中文提示词测试时,Kling 和 Veo 3 都默认生成英文旁白,只有 Sora 2以流畅中文对白完成。
更进一步,Sora 2 App 端还支持用户上传自身语音用于建模,这意味着可以生成一个声音高度还原的“数字人分身”——这套产品逻辑明显更贴近未来个性化内容生成的路径。
另外一提,在视频中出现的中文文字生成仍难称完美,但矮子里面拔尖,仍属于最优的一档。
2.如果说一般AI模型在做“视频延展”,Sora 2给人的感觉是具备了一定的导演能力。
在案例 1 和 2 中,它能稳定复现 POV(第一视角)镜头风格,而在案例 4 的短短 8 秒中,镜头机位完成了 6 次精准且自然的剪辑 —— 这不是场景的自动扩展(典型如Kling 2.5的样片),而是带有明确叙事意图的镜头编排能力。而这,恰恰是此前主流模型一直难以很好实现的“导演能力”。
对于创作者来说,这是一种底层表达方式的解锁。换句话说,Sora 2 可能不是画得最漂亮的,但它懂得如何讲好一段故事。
3.Sora 2不一定能生成最惊艳的画面(尤其在艺术感、风格化上),但它在物理、材质、光影、肌理、运动等维度的还原度极高,给我的观感就像iPhone不开滤镜的原相机。视觉上不一定是最好看的,但一定能将世界进行最准确,真实的还原。这也是为什么Sora 2制造的土味爆款短视频传播力极强:因为它已经过了“像不像”,到了“信不信”的阶段。
B站上Sora 2的默认排序结果:
4.低出片率的图生视频(Image-to-Video)模式。在测试中作者发现,Sora 2对于图片的分辨率有着严格的要求,如输出720p横向视频,首先需要确保上传的参考图为1280*720的分辨率,否则会报错,系统没有自动适配逻辑;而对于版权,题材类型的限制则是完全黑箱机制,测试案例中分别使用“名人like”模式的提示词,足球运动和军事类游戏的图片,均无法生成。目前无论从自由度还是容错率来说,并不推荐在API中使用该模式,如有需求可尝试使用移动端App或其他模型。
V. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
1. Use in chatbots
步骤指引 :应用超市→机器人→聊天机器人→立即体验
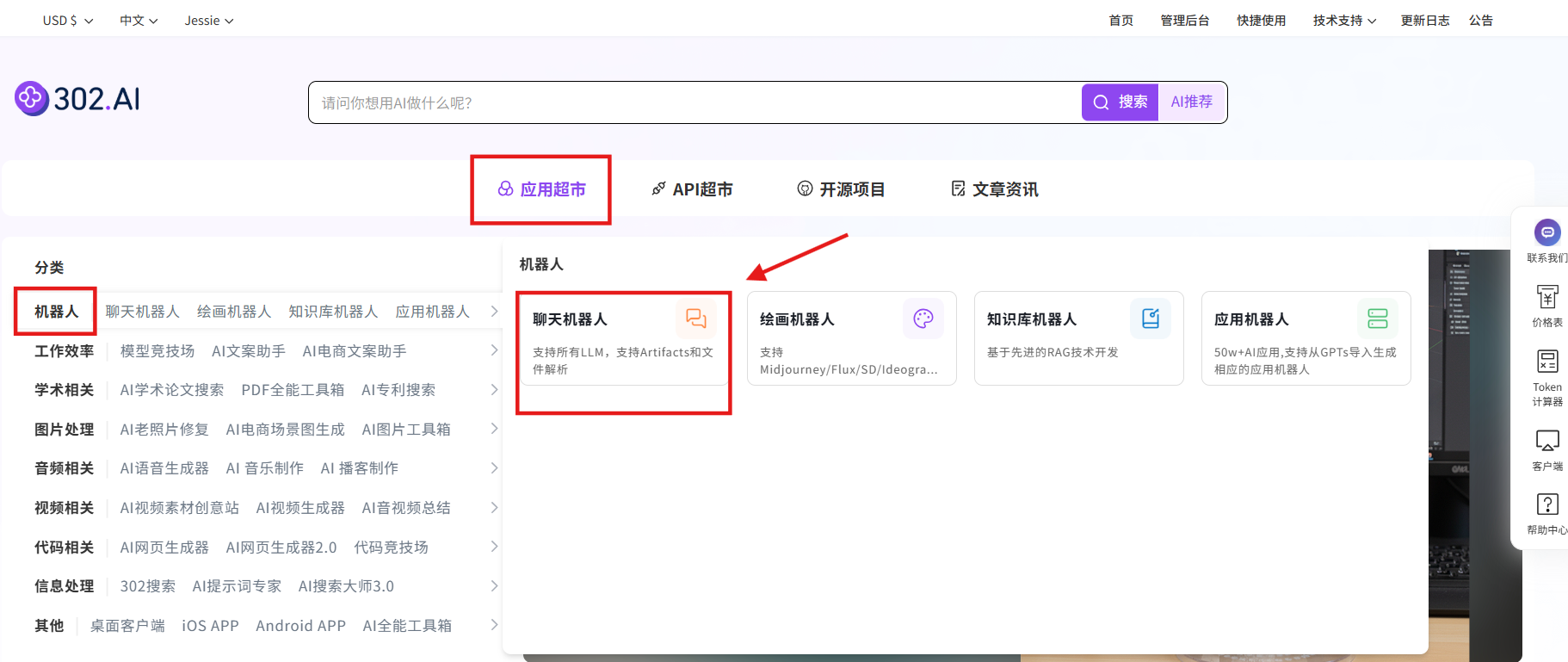
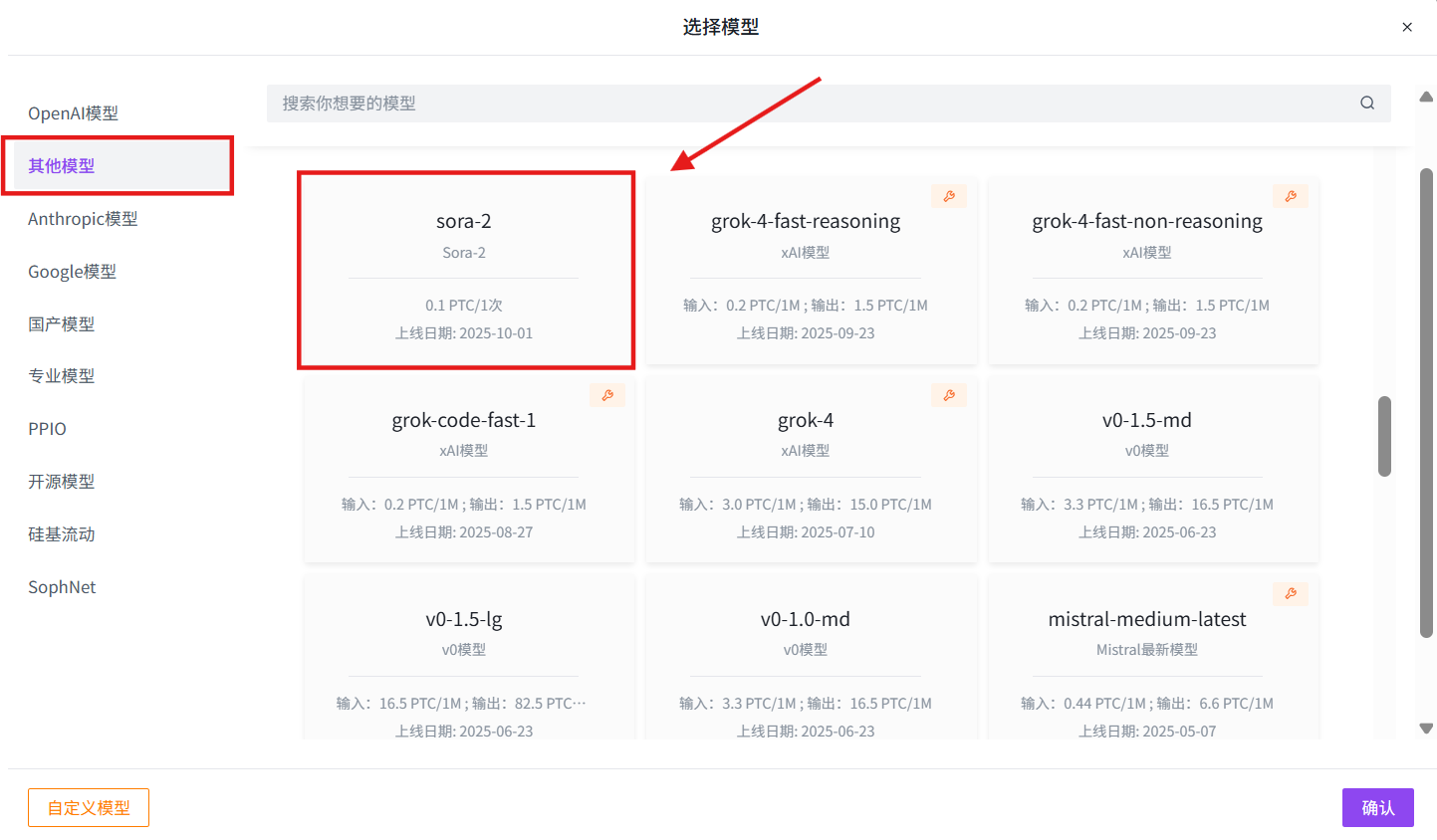
选择模型:其他模型→sora-2→确认→创建
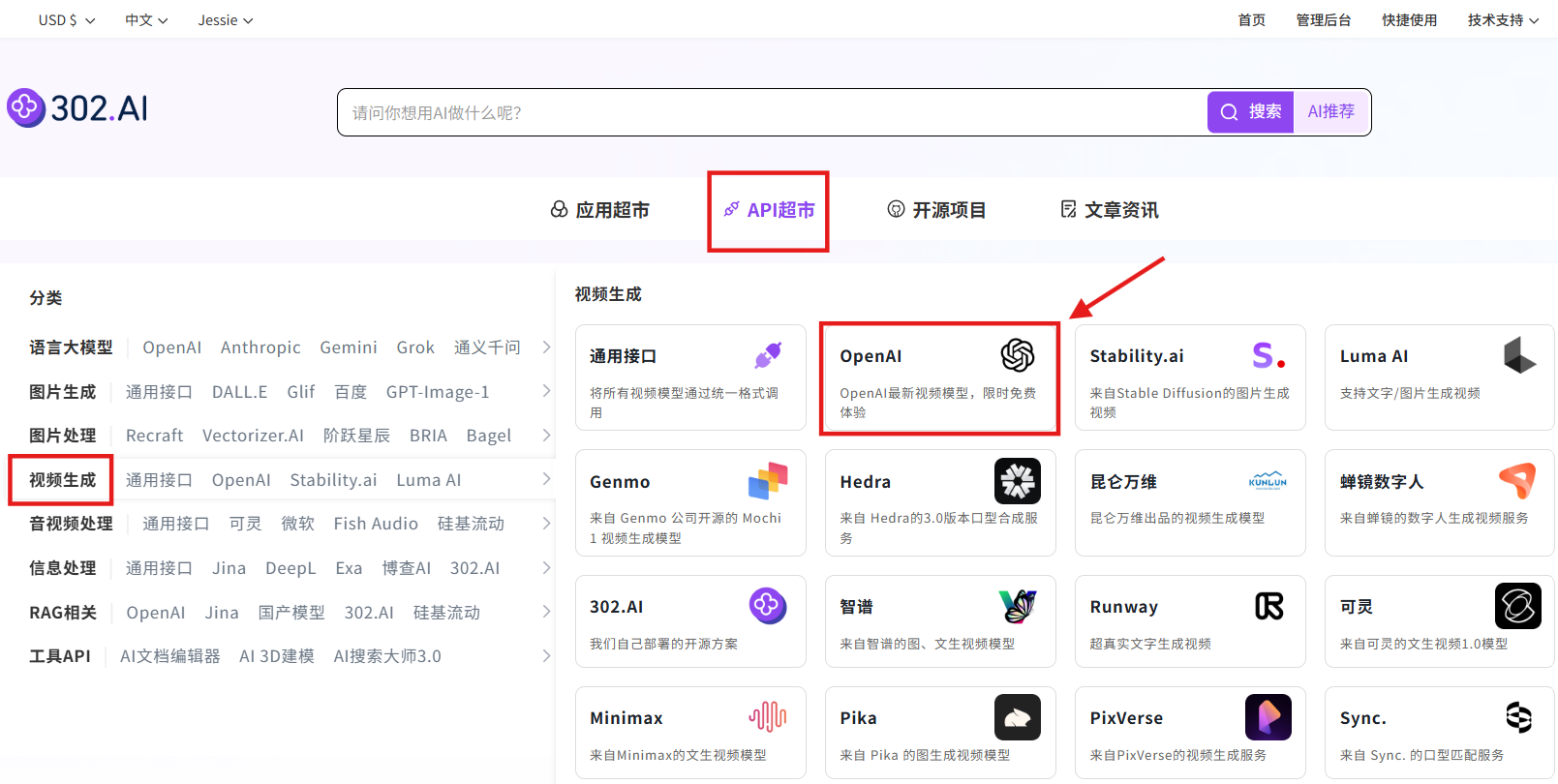
2. Using the Model API
步骤指引:API超市→视频生成→OpenAI→sora-2/sora-2-pro
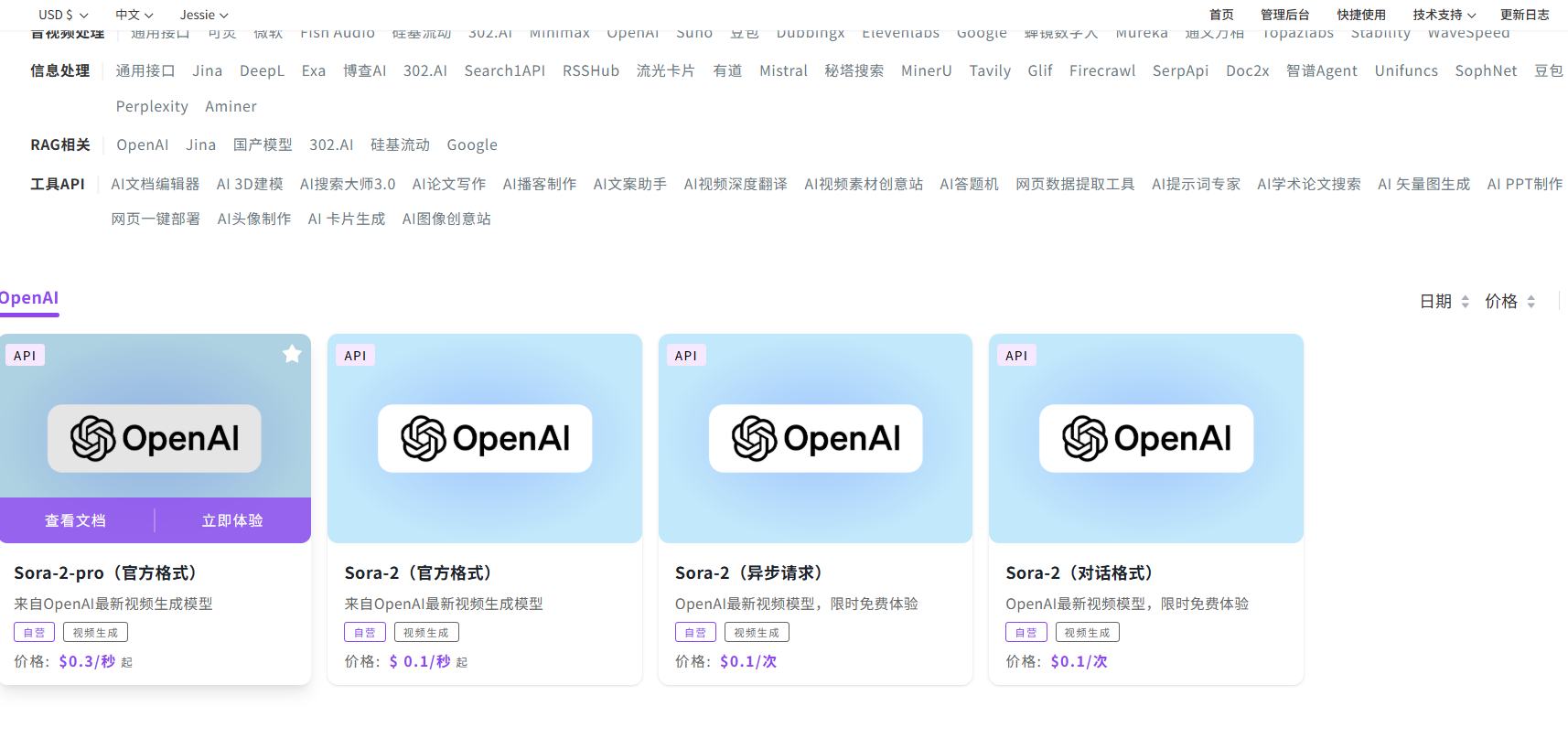
点击【立即体验】在线调用 API
想即刻体验 Sora 2 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
