
随着 AI 视频生成技术从基础的提示词理解迈向电影级画面创作,模型的进化方向已不再局限于画质本身,而是延伸至具备导演思维的运镜逻辑与对用户深层意图的感知能力。“电影级”,正成为新一代 AI 视频模型的核心标签。
在九月末密集发布的 AI 视频模型中,Wan2.5 与 Sora 2 凭借音画同步能力的突破,将 AI 视频的叙事质感推向一个新高度。紧随其后,生数科技推出的 Vidu Q2 则打出了“不止生成视频,更有生动演技”的独家 slogan——在这场围绕“电影级创作”的竞争中,Vidu 交出的答卷是:为 AI 赋予演技。

无论在图像还是视频生成领域,“拟真度”始终是衡量模型能力的最关键指标。Vidu Q2 将核心突破点聚焦于角色微表情、微动态的生成,力求让每一个神态、每一丝情绪都自然流动。此外,模型支持单图生成视频与自定义首尾帧模式,配合显著提升的运镜能力,带来了更丰盈的镜头表现力。该版本还可随心自定义视频时长,灵活适配多元创作场景。
回看我们上一期的测评《别再只谈电影级画质,Sora 2 评测:当 AI 开始真正讲中文、做导演,真实感什么水平?》,如果说 Sora 2 是一位统筹人、声、画、景的“全能导演”,那么 Vidu Q2 则更酷似一位专注于打磨表演细节的“资深演技指导”。
为验证 Vidu Q2 在实际生成任务中的表现,本期评测将联合 Wan2.5 与 Midjourney Video,从多场景、多维度展开对比实测,旨在为创作者在模型选型时提供更具参考价值的判断依据。
I. Basic information on the actual model
(1) The price of each real model at 302.AI:
| 模型名称 | 分辨率 | 时长 | 价格 |
| viduq2-turbo | 720p | 1-8s | $0.05/秒 |
| 1080p | $0.1/秒 | ||
| wan2.5-i2v-preview | 480p | 5s,10s | $0.05/秒 |
| 720p | $0.1/秒 | ||
| 1080p | $0.16/秒 | ||
| MJ-Video | 一次性生成4个5s视频,$0.3/次,折合$0.015/秒 | ||
(2)测评工具:
302.AI→API超市→在线调试功能
(3) Measurement methods:
各案例均使用统一的图片和提示词进行生成,且均取第一次生成结果,评测结果仅供参考。
Ⅱ. 测评案例
案例 1:图生视频-人物微表情
clue:电影级特写镜头,背景是饱经战火的城市废墟,灰烬与雪花一同飘落。图中年轻的战士在听到同伴的呼喊后,表情从恐惧犹豫转变为坚定。重点在他的眼神:瞳孔微微收缩,目光从涣散变得锐利如鹰,仿佛锁定了目标。下眼睑绷紧,显露出决绝。他咬紧牙关,下颌线变得清晰而硬朗,最后缓缓地、有力地点了一下头。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 人物表现 | ★★★★★ | ★★★★ | ★★★ |
| 提示词遵循 | ★★★★ | ★★★★ | ★★★ |
| 简评 | Vidu Q2胜。Vidu生成的人物表情在情绪转换上的表现十分连贯,演技自然不浮夸,尤其是表现犹豫害怕时,人物双眼下垂,嘴唇微张的神态非常传神,接近真人演技。Wan2.5的演技弱在情绪转变不明显,前半段没有太明显地描绘”恐惧犹豫“的情绪;MJ前半段的人物行进状态和飘忽的眼神比较自然,但是后半段的表现似乎并未理解提示词要求。 | ||
案例 2:图生视频-人物复杂运动
clue:一段充满动感的电影级短片,图中的未来女战士形象,在充满全息投影的都市废墟中,使用她的量子利刃与敌人进行激烈战斗,她的动作迅速、利落,兼具致命的爆发力,武器碰撞时迸发出光子轨迹。赛博朋克风格,炫酷视觉效果,流畅运镜。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 人物动态表现 | ★★★★ | ★★★ | ★★★★★ |
| 环境表现 | ★★★★★ | ★★★ | ★★★★★ |
| 提示词遵循 | ★★★★★ | ★★★ | ★★★ |
| 运镜表现 | ★★★★ | ★★★★ | ★★★★★ |
| 简评 | Vidu Q2胜。Vidu表现更佳的最主要原因在于按提示词要求生成了与敌人打斗的场景,虽然运镜和人物动效都略显保守,但起码保证了人物不穿模和画面整体不崩;另外两个模型均未生成与主角打斗的“群演”,但各自又有可取之处,例如Wan2.5给出了一套炫酷的挥刀特效,而MJ则给出了更丝滑的肢体动态、更飘逸的人物发丝以及更具视觉冲击力的运镜。 | ||
案例 3:图生视频-镜头跟随
clue:第一人称视角镜头,紧随着图中这位青衣古代青年,人物先转过身来招手示意跟上,随后转过身去穿梭于摩肩接踵的古代夜市,镜头跟随少年在行人中灵活穿行,最终随他停驻在一个古董摊,镜头缓慢推近,焦点最终牢牢锁定在摊位中央摆放着的青铜罗盘上。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 人物动态表现 | ★★★★★ | ★★★★ | ★★★★ |
| 环境表现 | ★★★★★ | ★★★ | ★★★★★ |
| 提示词遵循 | ★★★★ | ★★★★★ | ★★★★ |
| 运镜表现 | ★★★ | ★★★ | ★★★★ |
| 简评 | Vidu Q2和MJ表现略优。三组作品中Vidu的人物表现最自然,包括人物的动作神态、衣物褶皱变化,甚至人物在背过身后还能从颧骨弧度看出保持着视频开头的微笑表情,不愧为表情管理大师。此外,对比Wan2.5来说,Vidu环生成的群演也没有出现穿模和反物理现象,唯一不足之处在于未按提示词生成青铜罗盘这个指定物件;MJ的运镜逻辑较为合理,只是衣袖和灯笼的运动轨迹依然暴露出AI痕迹。 | ||
案例 4:图生视频-动画角色处理
clue:一片雪花落到小老鼠的鼻尖上,当雪花触碰到它的鼻尖时,它眼睛瞬间对眼,紧盯着鼻尖。雪花融化后,它愣了一下,然后兴奋地抬起头,试图去追逐空中更多的雪花,场景欢快活泼。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 角色表情 | ★★★★★ | ★★★★★ | ★★★★ |
| 角色动态 | ★★★★★ | ★★★ | ★★★★★ |
| 提示词遵循 | ★★★★ | ★★★★★ | ★★★ |
| 简评 | Vidu Q2略胜。Vidu生成角色的神态和动态更还原提示词,符合物理逻辑,细节加分项在于角色触碰雪地的效果也被表现了出来。相比之下,Wan2.5后半段的角色动态略显僵硬,MJ则是前半段未遵循提示词要求。 | ||
案例 5:图生视频-经典镜头复刻
提示词: 电影镜头,4K画质,极致特写。一个男人穿着精致的红色刺绣古装,背景是温暖模糊的红色墙壁。夕阳的余晖洒在他的脸上,勾勒出他悲伤的轮廓。他的眼神复杂,充满了克制的爱、牺牲与深深的遗憾。镜头缓慢推进,捕捉到他眼中的泪光,以及那一滴最终凝结、滑落的清泪。慢动作,充满诗意的悲剧感。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 人物表现 | ★★★★ | ★★★★ | ★★★ |
| 镜头表现 | ★★★★ | ★★★★ | ★★★★ |
| 还原度 | ★★ | ★★★ | ★★ |
| 简评 | Wan2.5略胜。从人物“演技”来看,Vidu生成的表情确实情绪更饱满,这体现在角色眼神和嘴部肌肉的变化上,特写运镜也比较平滑,对比之下另外两组人物神情就稍显木讷。但Vidu生成的人物落泪却不符合现实常理,使拟真度大打折扣;而Wan2.5却做到了提示词要求的“一滴最终凝结的眼泪”,画面更真实。 | ||
案例 6:图生视频-名场面复刻
clue:清宫剧特写:画面中这位妆容精致、气场强大的妃子。她目视镜头,抬起戴着华美护甲的手,将食指轻抵在唇前,做出“噤声”的手势,随后将手放下。眼神中带着一丝居高临下的威仪与慵懒的锐利,透露出霸气的气场和绝对掌控感。电影级画质,细腻的微表情。

生成效果:
| 测评点 | viduq2-turbo | wan2.5-i2v-preview | MJ-Video |
| 人物表现 | ★★★★★ | ★★★ | ★★ |
| 提示词遵循 | ★★★★ | ★★★ | ★★★ |
| 还原度 | ★★★★ | ★★★ | ★★ |
| 简评 | Vidu Q2完胜。虽然与原版片段尚存一定差距,但Vidu生成的甄嬛表情已经较为传神了,尤其体现在手指放下的动作,最后胜券在握的眼神和上扬的嘴角,已经非常近似于原版。此外,右侧宫女角色的戏份未做提示词要求,Vidu也进行了符合逻辑的处理。反观Wan2.5和MJ的作品就比较崩坏,肢体动作和面部表情都处理得有些过头。 | ||
III. Vidu Q2 实测结论

在多个侧重角色“演技”生成的实测案例中,Vidu Q2 的表现多以“略胜”收场,这一结果清晰地体现出它的技术特性与发展路径:
当谈及“电影叙事”时,视觉呈现是首当其冲的关键所在。在参考图+文字的提示模式下,模型如何准确理解提示词意图并将静态画面转化为完整的动态场景,成为最基础的能力要求。在具体测试案例中,Vidu Q2 在提示词遵循度上相较 Wan2.5 稍显不足,偶尔会出现“自主加戏”的情况,如在案例 5 和案例 6 中,自行添加了提示词未要求的角色开口说话镜头。好在这种“加戏”并未过多干扰到核心创作意图的表达,最终成片的完整度仍能达到七八成水准。不过,从画面控制的精准度与指令干扰性来看,Vidu Q2 距离完全理解提示词背后的叙事逻辑尚有进步空间,模型存在一些“自由发挥”的随机性。
此外,运镜能力也是电影叙事的另一关键要素。富有生命力的镜头运动能够有效增强观众的沉浸感。从实测结果来看,运镜也并非 Vidu Q2 的优势所在。当前 AI 视频领域不乏优秀的“掌镜者”,譬如效果炫酷的 PixVerse V5、后起之秀 Wan2.5 以及最新的 Sora 2,这些模型都在运镜效果上做出了很大提升。相比之下,Vidu Q2 在案例 2 和案例 3 中的运镜处理就略显保守了。然而,可能正因这种保守,反而给画面带来了稳定性优势,有效减少了复杂运动场景下的角色穿模问题,以及多主体情况下背景元素失真的情况,倒也不失为一种务实的策略。
接下来就得提到影响电影叙事的第三个要素——情感与表演。这是最容易被忽视的一点。当众多AI video模型在声画质感、物理动态和镜头逻辑上激烈竞争时,Vidu Q2 这次给自己打出的标签是“AI 演技”,这也算是一种另辟蹊径。而其实际表现如何呢?答案是确有成效。
Vidu Q2 在对角色的表情处理上是相对克制和小幅度的,这保证了人物表情和动作不容易崩,从而避免太快地暴露明显 AI 痕迹。这种对角色表情张弛度的细微把控,或许正是 Vidu Q2 的过人之处。这种“小幅度”的面部表情管理于现实中演员的表情管理也一样,很多情绪其实就蕴藏于毫秒之间,如何自然而不夸张地呈现出多种情绪,关键就在于度的把控。而 Vidu Q2 也正是抓住这一点,选择了一个差异化路线,在上文出现的所有有关角色演技的 battle 中,Vidu Q2 都脱颖而出,旗帜鲜明地占领了一方优势。
而在成本方面,Vidu Q2 相较主打“电影级叙事”的 Wan2.5 来说,价格相对低廉,但短板也在于无法像 Wan2.5 一样做到音画一体生成。各有所长,如何选择取决于具体需求。对于需要 focus 角色面部表情的慢动作或特写镜头来说,背景音效要求不高的场景,Vidu Q2 配合后期加工是不错的方案;而对于复杂场景或特殊音效要求的项目,则可能需要考虑其他支持音画同步生成的模型。
如前文所述,Vidu Q2 在多个案例实测中均以“略胜”收场。然而,别小看这种“略微取胜”,它还没有小到可以忽略不计的地步,而是揭示了 AI 视频向“电影级叙事”演进过程中的一个不可忽略的突破方向——情感与表演。这个方向的价值,正在这些细微之处悄然显现。
Ⅳ. 如何在 302.AI 上使用
302.AI 提供按需付费无订阅的服务模式,用户可以根据自身业务需求灵活选择使用。
使用模型 API
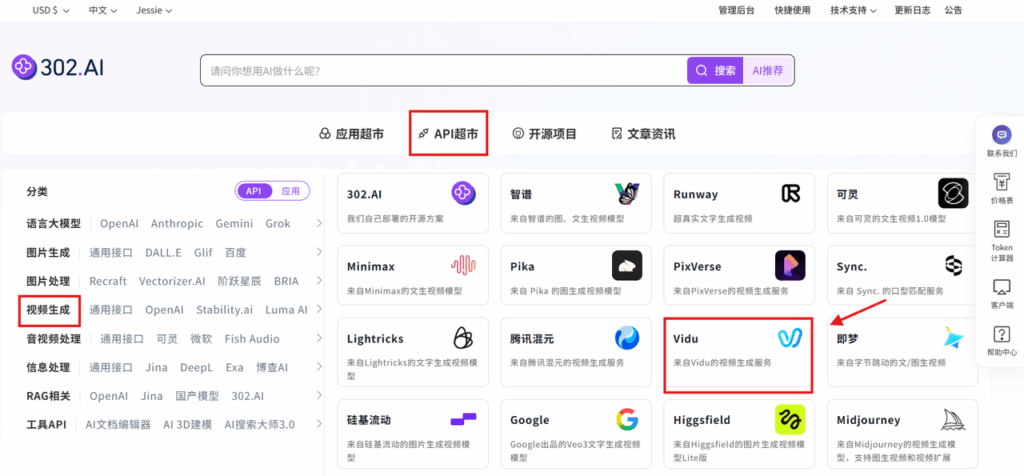
步骤指引:API超市→视频生成→Vidu→viduq2-turbo/viduq2-pro
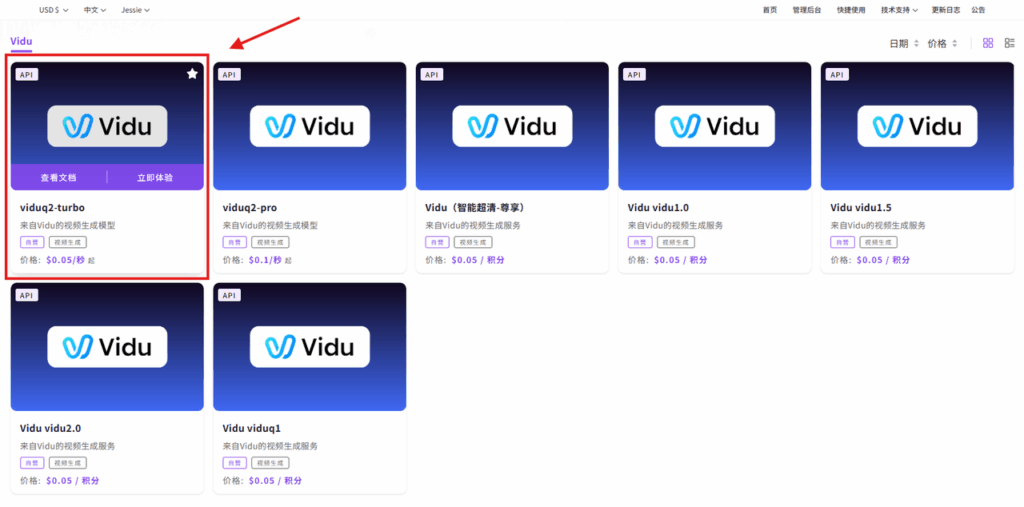
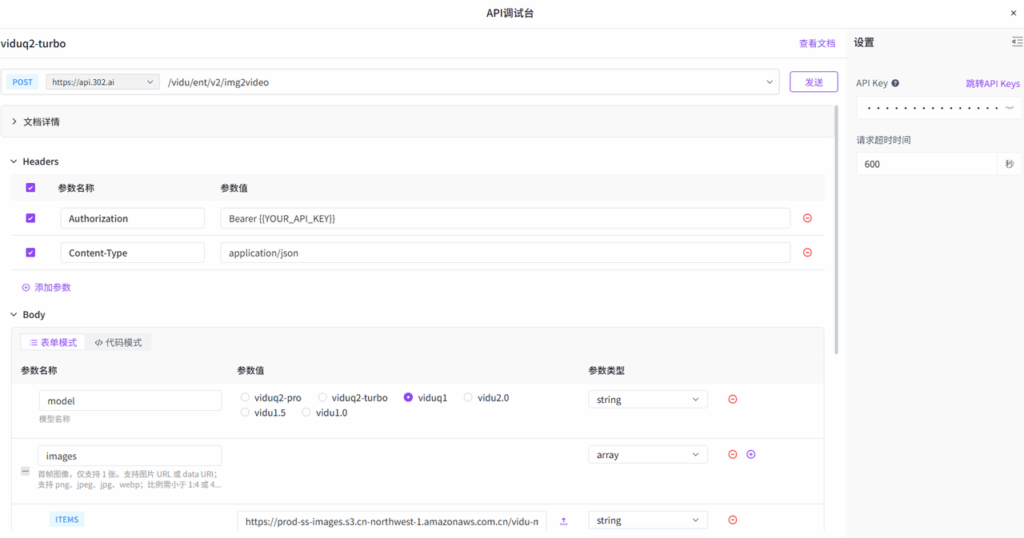
点击【立即体验】在线调用 API
想即刻体验 Vidu Q2 模型?
👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
