
话不多说,文接上篇,让我们从字母L继续。
字母L:
LLM (Large Language Model,大语言模型)
定义:一个在海量文本数据上进行预训练,规模巨大、参数量通常在十亿级别以上的深度学习模型,能够理解和生成人类语言。
通俗解释:把它想象成一个读完了人类历史上几乎所有书籍、网页和对话的“超级大脑”或“通天晓”。它不仅能和你聊天,更能扮演“世界模拟器”的角色。当你给Sora输入一段文字,它能生成一个视频,这背后就是LLM在理解你的剧本;当你使用Kimi K2 Thinking,它展现出的“思考链”,也是LLM在进行逻辑推演。它是所有顶尖AIGC应用的中央处理器(CPU)。
应用场景:在你的AIGC工作流中,LLM无处不在:
- 创意之源:用它来做头脑风暴,生成故事大纲、视频脚本、歌曲歌词。
- Prompt工程师:用它来帮你优化、扩写、甚至创造更专业的Prompt,以驱动AI绘画和视频模型。
- 万能助手:用它来写代码、解释概念、翻译文档,是你创作之路上的“全能副驾”。
LoRA (Low-Rank Adaptation,低秩适应)


定义:一种高效、轻量级的模型微调(Fine-tuning)技术,通过训练一个微小的“补丁”网络,来改变一个大型预训练模型的行为,而无需修改其主体参数。
通俗解释:如果说一个大型AI绘画模型(如Stable Diffusion)是一个身怀绝技、但风格泛泛的基础机器人,那么LoRA就是为这个机器人量身定做的“技能包”或“皮肤包”。这个包的体积很小(通常只有几十MB),但加载后,就能立刻让机器人学会一种全新的画风(如“二次元水彩风”),或者能完美地画出某个特定角色(如你自己的AI分身)。
应用场景:LoRA是开源AIGC社区繁荣的命脉。
风格迁移:下载并加载一个“赛博朋克风”的LoRA,你就能让任何模型都画出炫酷的霓虹城市。
角色固定:训练一个关于你笔下原创角色的LoRA,你就可以在不同场景、不同构图中稳定地生成这个角色,是制作系列漫画、故事绘本的利器。
概念学习:训练一个关于“特定盔甲样式”的LoRA,让AI精准画出你想要的设计。
Latent Space (潜空间)
定义:一个由AI模型在内部构建的、高维度的数学表示空间,所有的概念(文字、图像)在这里都被编码为特定的“坐标点”(向量)。
通俗解释:这是AI进行所有“魔法创作”的“精神世界”或“梦境空间”。当你输入“一只戴着墨镜的猫”时,模型并不是真的理解什么是猫、什么是墨镜,而是在这个“潜空间”里,找到了“猫”的坐标和“墨镜”的坐标,然后通过一系列复杂的数学运算,将这两个坐标“融合”,最终在这个空间里“雕刻”出一个全新的、代表“戴墨镜的猫”的坐标,再将其“解码”成我们能看到的像素图像。
应用场景:虽然你无法直接“进入”潜空间,但你所有的操作都在间接地影响它:
Prompt写作:你的每一个词,都在引导AI在潜空间里进行“坐标定位”。
图生图(Image-to-Image):你上传一张参考图,AI会先将其编码到潜空间,然后以这个坐标为起点,根据你的新Prompt进行“挪动”,从而生成一张既像原作又具新意的图。
风格混合:混合两个模型的Checkpoint或LoRA,本质上就是在潜空间里进行“坐标叠加”,创造出全新的风格。
Latency (延迟)

定义:从发送请求到接收到AI模型返回的第一个数据包之间的时间间隔。
通俗解释:就是AI的“反应速度”。当你发送一条指令后,需要等多久才能看到画面的第一个像素、听到声音的第一个音节。对于需要实时交互的应用(如AI数字人直播、实时语音翻译)来说,低延迟是决定用户体验的生死线。
应用场景:在选择AI服务平台时,Latency是一个关键的考量指标。一个优秀的平台会通过优化模型、部署全球节点等方式,来尽可能降低API调用的延迟,让你感觉AI的反馈“瞬息而至”,而非“望眼欲穿”。
字母M:
Minimax(稀宇科技)

定义:一家成立于2021年、相对小众但技术实力强劲的中国AI公司。它致力于构建与人类大脑一样具有通用智能的AI大脑,并提供了一系列覆盖语言、语音、视觉等多模态能力的API服务。
通俗解释:如果说一些AI巨头在追求大而全的通用智能,那么Minimax更像一个专注于打造精品工具箱的技术工坊。它在特定领域,尤其是语音合成(TTS)和视频模型的技术上,展现出了世界级的水平,并凭借其高质量的API服务,在开发者社区中赢得了小众但专业的极佳口碑。

302.AI相关测评:《终结“人机感”,MiniMax Speech 2.6 实测:低延迟+全音色复刻颠覆体验》

302.AI相关测评:《当对手已冲入2.5时代,Minimax Hailuo 2.3却在踩倒车?》
核心特色与强大之处:
- 卓越的语音合成(TTS)能力:这是Minimax最出圈、最受赞誉的技术之一。早在2025年4月,其TTS平台
MiniMax Audio就被许多评测者誉为“最强中文TTS”。不仅支持中英文,更能通过极少量的音频样本进行声音克隆,生成高度逼真、富有情感的同步语音合成。 - 前沿的智能体(Agent)平台:Minimax在Agent技术上布局深远。其
agent.minimax.io平台,旨在提供构建高级智能体所需的核心能力。Minimax的模型(如其LLM)在角色一致性(Identity)等方面表现出色,能够让AI角色在连续的对话或生成内容中,不会越画越陌生,这对于构建可靠的、可长期交互的AI Agent至关重要。 - 优秀的物理模拟视频(Video)模型Hailuo:其最大的亮点在于对物理表现的深刻理解。无论是人物的跳跃、翻转,还是物体的碰撞与运动,Hailuo 02都能生成符合力学原理、流畅自然的动态效果,在视觉真实感和物理模拟方面树立了新的行业标杆。
Model (模型)
定义:在AIGC语境下,Model特指一个经过海量数据训练、由数以亿计的参数构成的深度神经网络,它压缩了关于世界运作方式、艺术风格和逻辑规律的知识。
通俗解释:如果说AIGC是一个庞大的“魔法系统”,那么模型就是你手中那本威力无穷的“魔法书”。不同的“魔法书”有不同的专长:
GPT-5是一本百科全书,擅长语言和逻辑。
Midjourney是一本顶级画册,擅长生成极具美感的艺术图像。
Suno是一本音乐曲库,擅长创作各种风格的歌曲。 这本书的“厚度”(参数量)和“内容质量”(训练数据),直接决定了你能施展的魔法有多强大。
应用场景:在你的工作流中,选择正确的“魔法书”是第一步。你需要根据你的创作目标(是写文章、画画还是做音乐),来挑选最适合的模型。许多平台(如302.AI)就像一个巨大的图书馆,收藏了成千上万本开源的魔法书供你挑选和使用。
Multimodal (多模态)
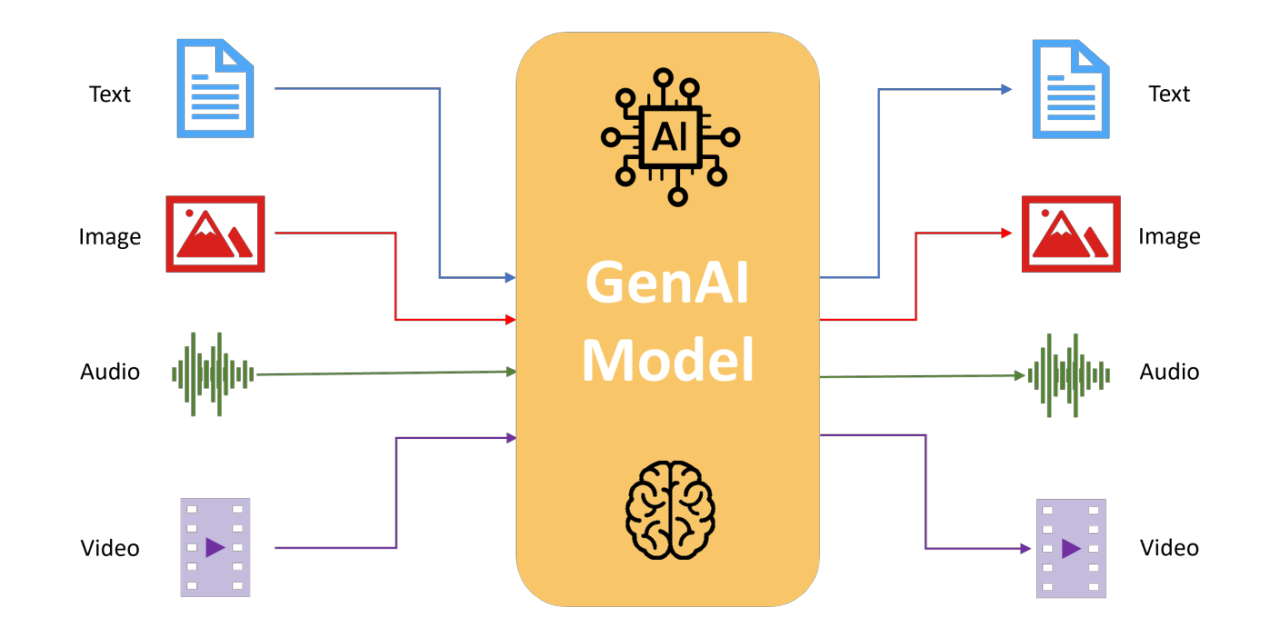
定义:指AI模型能够同时理解、处理和生成多种不同类型的数据(或称模态),如文本、图像、音频、视频等。
通俗解释:这就是让AI拥有通感能力的技术。一个多模态模型不再只能读懂文字或看懂图片,它变成了一个能够眼耳手口并用的全能选手。
你给它一张图片(视觉模态),它能用一段话(文本模态)来描述画面内容。
你对它说一句话(音频模态),它能为你画出一幅画(图像模态)。
你给它一段视频(视频模态),它能为其生成配乐(音频模态)和字幕(文本模态)。
应用场景:多模态是AIGC从单一工具走向全能助手的关键一步。GPT-4o、Gemini等顶尖模型都是强大的多模态模型。在你的工作流中,这意味着你可以用更自然、更直观的方式与AI交互,例如直接上传一张风格参考图,让AI据此创作一首同等氛围的音乐。
Midjourney

定义:一款顶级的、闭源的AI文生图模型,以其生成图像的极高艺术性和独特的社区驱动创作模式而闻名。
通俗解释:如果说Stable Diffusion是开源的安卓,给了你无限的自由度和定制空间,那么Midjourney就是封闭的苹果iOS,它为你提供了一个极致简化、但美学输出极其稳定的创作环境。你无需关心复杂的参数,只需专注于用最优美的语言去创作你的Prompt,它就会为你献上一幅幅堪比艺术品的画作。
创作模式:Midjourney独特之处在于,它的所有创作都在一个公共的Discord社区频道里进行。这意味着你可以实时看到全世界其他创作者的作品和他们使用的Prompt,这本身就是一个无与伦比的、互相学习和激发灵感的巨大灵感池。
应用场景:当你追求极致的视觉美感、艺术氛围和画面质感时,Midjourney通常是专业设计师和艺术家的首选。它尤其擅长幻想、概念艺术和富有故事性的宏大场景。
Moderation (审查)
定义:一套用于自动检测、过滤和标记潜在有害或不当内容的AI系统或策略,是确保AI平台安全与合规的“守门人”。
通俗解释:这就是AI平台内置的“纪律委员”。当你试图生成一些违反平台规则(如暴力、色情、仇恨言论)的内容时,Moderation API就会介入,拒绝你的请求,甚至给你的账户打上一个警告标签。
应用场景:作为创作者,你需要了解并遵守你所使用平台的Moderation规则。这不仅是为了避免你的账户被封禁,更是为了共同维护一个健康、有创造力的AIGC社区生态。理解审查的边界,也是创作自由的一部分。
字母N:
Nano Banana

302.AI相关测评:《六战全胜!4K输出,从信息图到超写实人像:Nano Banana Pro重回王座》
定义:由Google于2025年8月末推出的,一款极其先进的AI图像生成与编辑模型。它基于强大的Gemini模型构建,如最新的Nano Banana Pro就是基于Gemini 3打造。
通俗解释:如果说传统的AI绘画模型是一个遵命画师,你给一个指令,它画一幅画;那么Nano Banana更像一个视觉魔术师。它的核心魔法在于,能够将多幅图像、多种风格、甚至文字的含义都巧妙地融合(blend)在一张全新的、且逻辑自洽的图像中。它不仅仅是画,更是在理解和重组视觉元素。
核心特色与强大之处:
- 多图融合与角色一致性:这是Nano Banana最令人惊叹的能力。它可以将多张不同的图片(比如一张梵高的星空、一张蒙娜丽莎的微笑)融合成一幅画,并且能在融合过程中,保持核心角色(如蒙娜丽莎)的身份一致性。为了专门研究和提升这一能力,社区甚至基于Nano-Banana构建了名为
Nano-consistent-150k的高质量数据集,专攻复杂场景下的人物身份保持。 - 卓越的文字处理与图形融合:在需要将文字融入图像的创意设计中,Nano Banana表现出色。它能理解单词的含义,并将其与字母的形态巧妙地结合在一起,生成极具创意的字体设计或品牌Logo。
- 强大的姿势控制与场景生成:Nano Banana支持基于姿势的生成。你可以用简单的“火柴人”简笔画来指定角色的动作,然后让模型将其转换为一个具有特定角色、场景动态丰富的动漫或写实画面。
应用场景:
- 创意海报与字体设计:将品牌理念、Slogan与视觉元素无缝融合,创造出独一无二的宣传物料。
- 角色概念设计:通过融合多张参考图,快速生成具有特定血统、装备和风格的角色设定图。
- 超现实艺术创作:将毫不相关的概念(如“星空下的向日葵田里,蒙娜丽莎在弹吉他”)进行富有想象力的视觉化呈现。
- 故事板与分镜创作:利用其姿势控制能力,快速生成具有特定角色和动作的故事分镜草图。
Noise (噪声)
定义:在信号处理中,指信号中不期望出现的、随机的扰动。但在AIGC的扩散模型语境下,噪声是生成过程的起点和基础,是一切创造的“原始材料”。
通俗解释:如果说AI绘画是一场从无到有的创世,那么噪声就是创世之初那个充满了无限可能性的混沌宇宙或创意原浆。它是一张看起来像电视雪花屏的、完全随机的像素图。扩散模型(Diffusion Model)的全部工作,就是根据你的提示词作为宇宙法则,一步步地从这片混沌中降噪,让秩序(你想要的图像)从中浮现出来。
应用场景:虽然你通常不直接与噪声互动,但它贯穿了整个生成过程:
Seed(种子):你设定的种子值,就是用来生成这张初始噪声图的“随机数”,它决定了你的混沌宇宙最初的形态。
Denoising Strength(降噪强度):在图生图模式下,这个参数控制了AI对原始图片添加噪声的程度,从而决定了再创作的自由度。
Noise Schedule(噪声策略):这是模型内部的一个参数,决定了在去噪的每一步中擦除多少噪声。不同的策略会影响最终图像的细节和质感。
Negative Prompt (负面提示词)
定义:一组与主提示词(Prompt)相对的、用来告诉AI模型在生成图像时不要包含哪些元素的关键词。
通俗解释:如果说主提示词是你给AI画家的“正面指令”(画什么),那么负面提示词就是你给他的“负面清单”或“避雷针”(不要画什么)。这是AIGC绘画中一个极其强大、几乎是必用的功能。通过精准地列出你不想要的元素,可以极大地提升出图质量,避免常见的AI翻车现场。
应用场景:你的负面提示词库通常会包含以下几类:
质量规避:low quality, worst quality, blurry, jpeg artifacts (低质量,最差质量,模糊,JPEG压缩瑕疵)
畸形规避:deformed, mutated, extra limbs, missing fingers, bad anatomy (畸形,突变,多余的肢体,缺手指,糟糕的人体结构)
风格规避:cartoon, 3d, render, painting (如果你想要一张照片,就排除卡通、3D渲染、绘画等风格)
元素规避:watermark, text, signature (水印,文字,签名)
Neural Network (神经网络)

定义:一种模仿生物大脑神经元网络结构和功能的数学模型,是深度学习和现代AI技术的核心。
通俗解释:这就是所有AIGC模型(LLM、扩散模型等)的“大脑结构”。它由大量相互连接的、被称为“神经元”的计算单元(Node)组成,这些神经元分布在不同的“层”(Layer)中。数据从输入层进入,经过一个或多个“隐藏层”的复杂处理,最终在输出层得到结果。模型的学习,就是通过调整这些神经元之间连接的“权重”(Weight)来完成的。
应用场景:你使用的每一个AI模型,无论其功能多么神奇,其底层都是一个庞大而复杂的神经网络。当你看到一个模型拥有“数百亿参数”时,指的就是这个网络中连接权重的数量。
Normalization (归一化)
定义:一种数据预处理技术,将不同尺度、不同范围的数值数据,缩放到一个统一的、特定的范围(如0到1或-1到1)内,以便于模型处理。
通俗解释:这就像是在模型吃饭前,先把所有的食材(数据)都处理成统一大小的食材颗粒,方便模型吸收消化。例如,图像的像素值范围是0-255,而另一个描述亮度的参数范围可能是0-10000。如果不做归一化,模型可能会被那个大数值的参数带偏,认为它更重要。归一化就是把它们都统一到相似的起跑线上。
应用场景:这是模型训练幕后一个至关重要的步骤。虽然创作者不直接操作,但理解它有助于明白为什么高质量、经过精细处理的数据集对于训练出好模型如此重要。
字母O:
Open-source (开源)
定义:一种软件开发与分发的模式,其核心是将软件的源代码、设计文档和相关资源向公众开放,允许任何人自由地使用、修改、研究和重新分发。
通俗解释:这就是AIGC世界的共产主义理想与文艺复兴的基石。如果说闭源模型(如Midjourney、GPT-4)是顶级大厨为你精心烹制的米其林大餐,你只能享用,不能探究其秘方;那么开源模型(如Stable Diffusion、Llama 3)就是把完整的米其林厨房——包括所有厨具、食谱和独家香料——全部向你开放。你可以直接使用,也可以根据自己的口味进行魔改,甚至可以开一家属于你自己的新概念餐厅。
应用场景:开源精神是AIGC社区繁荣的命脉。
- 无限的定制化:基于开源的Stable Diffusion模型,社区开发者创造出了ControlNet、LoRA、海量的微调模型和数不清的插件,共同构建了一个功能远超任何闭源工具的庞大生态系统。
- 技术的民主化:开源让顶尖的AI技术不再是少数巨头的专利。全世界的研究者、开发者和爱好者都能站在巨人的肩膀上,进行二次创新,共同推动技术的边界。
- 本地化部署:你可以将开源模型下载到自己的电脑上运行,这不仅保护了数据隐私,也让你免于支付API调用费用。
OpenAI

定义:可以说是全球最为著名的人工智能研究和部署公司,以其发布的一系列具有里程碑意义的AIGC模型(如GPT系列、DALL-E、Sora)而闻名于世。
通俗解释:如果说AIGC是一场席卷全球的工业革命,那么OpenAI就是那个发明了蒸汽机(Transformer架构)、并率先造出火车(GPT-3)和飞机(Sora)的瓦特和莱特兄弟。它以一己之力,反复为整个行业设定了新的技术标杆,是所有AIGC玩家都无法忽视的王座上的巨人。
应用场景:在你的AIGC工作流中,OpenAI的模型几乎是不可或缺的组成部分。
GPT系列:用于生成高质量的文本、代码和创意脚本。
DALL-E系列:深度集成于ChatGPT中,是生成高质量、且与上下文紧密结合的图像的强大工具。
Sora系列:文生视频领域的“核武器”,其发布的每一个演示视频,都在重新定义我们对AI video能力的想象。
Outpainting (外补)
定义:一项图像编辑技术,与Inpainting(内补)相对,它允许AI在现有图像的画框之外,根据图像内容和用户提示词,智能地“想象”并绘制出更多的画面。
通俗解释:这就是AI绘画工具里的画框魔法,能让你手中的照片无限延展。你有一张蒙娜丽莎的肖像画,想知道画框之外是什么样子?使用Outpainting,AI就能为你脑补出她的全身、身后的背景乃至整个达芬奇画室。它打破了原始画框的束缚,赋予你重构画面、延伸想象的自由。
应用场景:
改变构图:将一张竖构图的人物照片,扩展成一张包含广阔风景的横构图大片。
修复裁剪不当的照片:为那些被“砍掉”了头顶或脚的家庭老照片,重新“画”出完整的部分。
无尽的艺术探索:在一个名为无限画布的工作流中,你可以反复使用Outpainting,像卷轴一样不断延展画面,创造出一幅永无止境的宏伟画卷。
字母P:
Prompt (提示词)

302.AI相关教程:《翻车救星:谷歌官方Nano Banana提示词教程详解,附实测案例对比》

302.AI相关教程:《指令的艺术:深度评测JSON格式与自然语义提示词对于AI创作的影响》
定义:用户向生成式AI模型输入的、用以描述期望输出内容的自然语言指令、关键词或句子。
通俗解释:这就是你与AI沟通的语言,是你递给AI画家的需求清单,是你交给AI音乐家的曲谱大纲,是你对AI导演下达的剧本和分镜。在AIGC的世界里,Prompt就是生产力,Prompt就是艺术。一个好的Prompt不仅仅是简单的词语堆砌,它是一门结合了精确描述、艺术风格指定、镜头语言运用、甚至情感引导的复杂学问。
应用场景:
- 文生图:一个典型的图像Prompt结构通常是“[主体] + [细节] + [场景] + [风格] + [画质与参数]”。例如:“A portrait of a beautiful elven queen (主体), with intricate silver jewelry and glowing blue eyes (细节), standing in an ancient, moonlit forest (场景), in the style of Artgerm and Greg Rutkowski, cinematic lighting, ultra-detailed, 8K (风格与画质)”。
- 文生视频:Prompt需要更具动态感和叙事性,如:“A majestic eagle soars through a dramatic, stormy sky, its wings catching the last rays of the setting sun, close-up shot of its intense eye, slow motion.”
- 文生音乐:Prompt则侧重于描述曲风、情绪、乐器和节奏,如:“An epic orchestral cinematic trailer music, powerful brass section, driving percussion, tense string ostinatos, choir, uplifting and heroic mood.”
Pipeline/Workflow (工作流)
定义:为了完成一个复杂的AIGC任务,将多个不同的AI模型或功能按顺序串联起来,形成的一套自动化或半自动化的处理流程。
通俗解释:这就是你的AIGC内容生产线。如果说单个AI模型是一个独立的工匠,那么Pipeline就是把一群各怀绝技的工匠组织起来的现代化工厂。这个工厂的生产线上,每一个工位都负责一道独特的工序。
应用场景:
AI短片制作流水线:
- 工位1(编剧):调用LLM(如GPT-5)生成故事脚本。
- 工位2(配音):调用TTS模型(如ElevenLabs)为脚本生成配音。
- 工位3(配乐):调用Suno生成符合故事氛围的背景音乐。
- 工位4(原画):调用Midjourney或Stable Diffusion生成关键帧画面。
- 工位5(动画):调用Sora或Kling将关键帧转化为视频片段。
- 工位6(剪辑):调用剪辑软件或AI剪辑工具,将所有素材合成为最终影片。
AI数字人MV流水线:从角色训练、音乐生成到口型同步和视频合成,每一个环节都可以是一个独立的工位。
Parameters (参数)
定义:在神经网络模型中,指模型在训练过程中学习到的、用于进行预测和生成决策的数值,通常表现为网络中神经元之间连接的“权重”(Weights)和“偏置”(Biases)。
通俗解释:如果说AI模型是一个极其复杂的超级函数,那么参数就是这个函数中成千上万个需要被求解的未知数。模型的学习过程,本质上就是在海量数据的指导下,不断调整这些未知数的值,直到这个函数能够做出最准确的预测。一个模型的参数量(如175B,即1750亿个参数),在很大程度上决定了它的智力上限和知识容量。
应用场景:虽然你通常不直接修改模型的内部参数,但你几乎时刻都在与模型的外部参数打交道:
CFG Scale:控制AI绘画时,画面在多大程度上听从你的Prompt。
Sampling Steps:控制生成一张图片需要进行多少步去噪计算。
LoRA Weight:控制一个LoRA风格插件对画面的影响强度。 理解并善用这些外部参数,是从业余玩家迈向专业创作者的关键。
Post-processing (后期处理)

302.AI相关教程:《Topaz Labs评测:当“修复式”专业工具遇上“生成式”大模型,AI修图的未来将走向何方?》
定义:在AI生成了初步内容之后,对其进行的一系列修改、优化和增强操作,以达到最终的交付标准。
通俗解释:AI很少能“一键毕业”,它更像是一个才华横溢但略显粗糙的初稿创作者。后期处理就是你作为总编辑或后期总监,对AI的初稿进行精修的过程。这个过程可能简单,也可能极其复杂。
应用场景:
图像后期:使用Photoshop或Topaz AI,对AI生成的图片进行调色、修复瑕疵(如修复手指)、添加光影特效。
视频后期:使用Premiere Pro或剪影,将AI生成的多个视频片段进行剪辑、转场、调色,并与音轨对齐。
音频后期:使用Logic Pro或Audition,对AI生成的音乐进行混音、母带处理,使其听感更专业。
Pixel (像素)

定义:构成数字图像的最基本、最小的单位,一个像素通常包含颜色和亮度信息。
通俗解释:像素就是数字画布上的原子。你看到的任何一张数字图片,无论多么复杂,放大到极致后,都是由一个个微小的、纯色的小方块组成的。一张图片的分辨率(如1920×1080),就代表了它是由横向1920个、纵向1080个像素点构成的。
应用场景:
分辨率:像素的数量直接决定了图像的清晰度。AIGC的Upscaling(放大)技术,其本质就是智能地创造出更多的像素,来提升图像的分辨率。
像素艺术(Pixel Art):一种复古的艺术风格,创作者通过有意识地控制每一个像素的颜色和位置,来创作出独特的、颗粒感强的图像。一些AI绘画模型也支持专门生成这种风格。
字母Q:
Quality (品质)
定义:在AIGC语境下,品质是一个综合性指标,用于衡量生成内容在技术、艺术和逻辑等多个维度上的优劣程度。它不仅仅是像不像,更是好不好。
通俗解释:这就是决定你的AIGC作品是惊艳的神作还是廉价的行货的灵魂所在。高品质意味着:
- 高保真度(High Fidelity):图像清晰锐利,没有模糊和噪点;视频稳定流畅,没有抖动和伪影。
- 低瑕疵率(Low Artifacts):没有多余的手指、扭曲的背景或不合逻辑的物理现象。
- 高美学价值(High Aesthetic Value):构图、色彩、光影和谐统一,具有艺术美感。
- 高一致性(High Consistency):在系列作品或长视频中,角色和风格保持稳定,不会忽美忽丑或瞬间变脸。
应用场景:品质是你整个AIGC工作流的终极目标。你所做的每一个选择——从挑选模型、撰写Prompt,到调整参数、进行后期处理——都是为了无限逼近你心中的最高品质。
Quantization (量化)
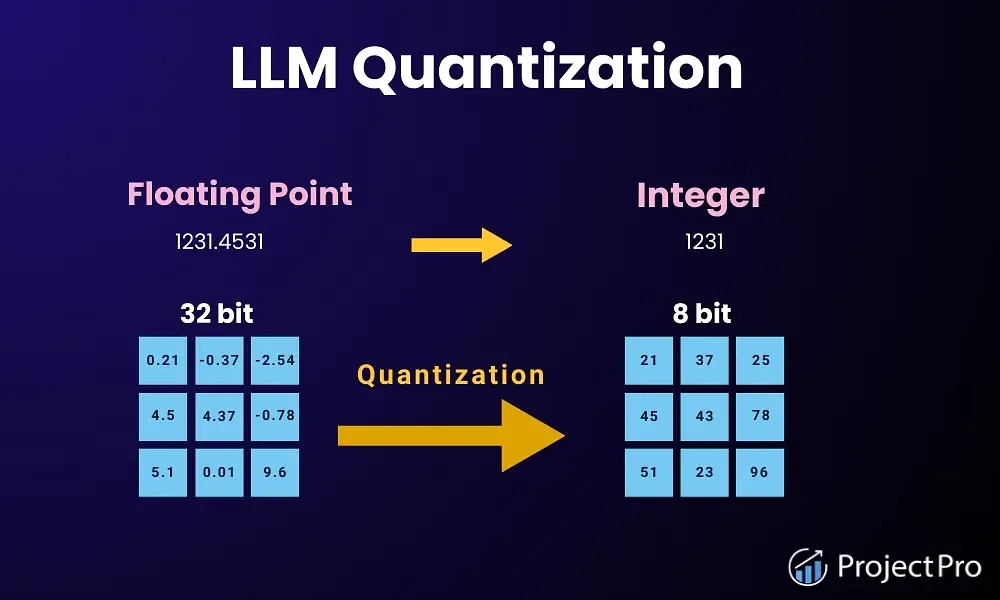
定义:一种模型压缩技术,通过降低神经网络模型中参数(权重和偏置)的数值精度,来减小模型的体积和计算量,从而提升其推理速度并降低内存消耗。
通俗解释:如果说一个庞大的AI模型是一本用精装铜版纸印刷的、内容详尽的大英百科全书,那么量化就是把它重新排版,用更轻便的新闻纸印刷成一本口袋本。
内容还在:知识的核心内容基本没有损失。
体积变小:口袋本的重量和体积远小于精装版,更便于携带(部署在个人设备上)。
阅读更快:因为更轻便,你翻阅(模型推理)的速度也更快了。 这个过程通过将高精度的数字(如32位浮点数FP32)转换为低精度的数字(如8位整数INT8或4位浮-点数FP4)来实现。
应用场景:量化是实现AI技术普惠化的关键。
- 端侧部署:经过量化处理,原本需要高端服务器GPU才能运行的百亿参数大模型,现在可以在你的笔记本电脑、甚至手机上流畅运行,实现了真正的本地化AI。
- 提升推理速度:对于在线AI服务而言,使用量化后的模型可以大幅降低API调用的延迟(Latency),让用户体验更丝滑。
- 降低成本:更小的模型、更快的推理速度,意味着更低的服务器成本和能耗。
Query (查询)
定义:用户向信息系统(如搜索引擎、数据库或AI模型)发出的一个明确的请求或问题。
通俗解释:这就是你与AI对话的每一次发言。在AIGC的语境下,Query与Prompt的概念高度重合,但Query更侧重于信息检索或问答的意图。当你问ChatGPT“帮我解释一下什么是量化”时,这是一次典型的Query;而当你对Midjourney说“画一只在月球上弹吉他的宇航员猫”时,这更常被称为Prompt。
应用场景:构建一个高效的AIGC Agent,其核心能力之一就是能将用户模糊的自然语言指令,拆解成一系列可以被不同工具(如搜索引擎、代码解释器)执行的、清晰的查询(Queries)。
Qwen (通义千问)

定义:由阿里巴巴集团旗下的通义实验室(Tongyi Lab)自主研发的、一个涵盖了大规模语言与多模态能力的超大规模系列模型。其英文名Qwen,是其品牌理念与技术实力的精妙融合。
核心特色与强大之处:
- 全面的能力矩阵:Qwen并非单一模型,而是一个庞大的模型家族。它不仅能执行强大的自然语言理解、文本生成、逻辑推理和编程任务,更具备出色的多模态能力,能够理解和处理视觉信息。
- 技术深度与开源贡献:作为中国自研AI模型的杰出代表,Qwen的技术实力不容小觑。阿里巴巴团队不仅持续迭代其闭源商用模型,更向开源社区贡献了一系列强大的基座模型。其发布的技术报告,详细阐述了从大规模预训练到RLHF(基于人类反馈的强化学习)对齐的完整技术细节,为整个行业的技术发展提供了宝贵的参考。
- 专精领域的突破:Qwen系列还在不断向更专精的领域拓展。例如,其推出的Qwen-Image模型,就是一个专注于图像生成的基础模型,在复杂文本渲染和精确图像编辑等领域取得了显著进展。这表明Qwen正在从一个“通才”,向多个领域的“专家”进行演化。
应用场景:
通用智能助手:作为个人或企业的“万能大脑”,用于回答问题、创作文案、进行数据分析和逻辑推理。
多模态内容创作:结合其视觉理解能力,可以进行看图写作、图像描述生成,甚至驱动更复杂的图文视频创作流程。
专业领域赋能:通过在其基座模型上进行微调(Fine-tuning),可以快速构建出服务于金融、医疗、法律等垂直领域的专业AI应用。
字母R:
Runway

定义:一家在AI视频生成与编辑领域处于领先地位的AI公司,以其推出的Gen-1和Gen-2等强大的视频模型而闻名,是AIGC视频创作生态的奠基者和重要推动者之一 。
通俗解释:如果说Sora的出现是AI视频界的原子弹爆炸,那么Runway就是那个率先发明了火药并不断迭代火枪的先驱。它最早将“视频转视频”(Video-to-Video)和“文本转视频”(Text-to-Video)等概念产品化,并提供了一整套围绕视频创作的AI工具箱。你可以把它想象成一个AI驱动的云端视频特效工作室。
核心产品与技术:
- Gen-1(视频转视频):允许你上传一段现有视频,然后通过文本或参考图片,将其转换成全新的风格。例如,将一段真人在街上走路的视频,一键转换为一个在赛博朋克城市中行走的机器人。
- Gen-2(文本/图像转视频):这是其更进一步的产品,可以直接从文本或单张图片生成短视频片段,极大地降低了动态影像创作的门槛。
Remix (重混)
定义:在AIGC创作中,指基于一个现有的作品(如图片、音乐、提示词),通过改变参数、添加新元素或融合不同风格,来创造出一个既保留原作部分特征又具有全新面貌的新作品的过程。
通俗解释:这就是AIGC社区的核心玩法和快乐源泉——万物皆可Remix。它是一种开放、共享、迭代的创作文化。看到别人生成了一张很酷的图?拿来他的Prompt,改几个词,换个LoRA,你就能得到一张属于你的、独一无二的Remix版。这就像音乐界的DJ对经典曲目进行混音,创造出全新的版本一样。
应用场景:
图生图(Image-to-Image):这是最经典的Remix模式。一张图进去,另一张风格迥异但构图相似的图出来。
Prompt Remix:在Midjourney等社区,直接点击“Remix”按钮,你就可以在他人的Prompt基础上进行修改,快速学习和迭代。
音乐风格迁移:用AI将一首古典音乐的旋律,用电子舞曲的风格重新编排和演绎。
Realism (现实主义/真实感)

302.AI相关测评:《AI人像专题测试:腾讯混元微调的Flux-1-SRPO有何独门绝技?》
定义:一种艺术和创作风格,其目标是尽可能准确、不加修饰地再现或模拟客观现实。在AIGC中,它特指模型生成的内容在视觉上与真实世界的照片或视频无法区分的能力。
通俗解释:这就是我们常说的以假乱真的境界。一个追求现实主义的AI模型,它生成的人像会有皮肤的毛孔和瑕疵,生成的风景会有真实的光影和大气感,生成的视频会遵循物理规律。它追求的不是艺术夸张,而是对真实的无限逼近。
应用场景:
照片级产品渲染:为电商网站生成看起来像真实棚拍的商品图。
虚拟数字人:创造出与真人无异、能够跨越“恐怖谷”的超写实数字人。
影视特效:生成无法通过实拍获得的、但又需要完全符合物理逻辑的特效镜头(如建筑坍塌、海啸等)。
Resolution (分辨率)
定义:指数字图像所包含的像素(Pixel)数量,通常表示为“宽度 × 高度”。它决定了图像的清晰度和细节层次。
通俗解释:这就是我们常说的“清晰度”或“画质”。一张1920×1080的图片,就比一张512×512的图片拥有更多的细节,看起来也更清晰。分辨率是AIGC绘画中最基础、也最重要的参数之一。更高的分辨率意味着更多的计算量和更长的生成时间。
应用场景:
初始生成:通常在较低分辨率(如512×512或1024×1024)下进行,以保证生成速度,快速迭代构图。
放大(Upscaling):在得到满意的低分辨率图像后,通过High-Res Fix或专门的放大算法,将其提升至2K、4K甚至8K的高分辨率,以满足打印或高清展示的需求。
Reinforcement Learning (强化学习)
定义:机器学习的一个分支,其核心思想是让一个智能体(Agent)在与环境的互动中,通过不断试错,根据收到的奖励或惩罚来学习如何做出最优决策。
通俗解释:这就像训练一只宠物。当它做出一个正确的动作(如坐下),你就给它一个奖励(零食);当它做出错误动作时,你就不给奖励。久而久之,它就学会了为了获得最多奖励而选择正确的行为。在AI领域,最著名的应用就是RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),它通过让人类对AI的多个回答进行排序和打分,来教会ChatGPT等模型生成更符合人类偏好、更有用、更无害的回答。
应用场景:虽然强化学习更多地应用于模型训练的后端,但它深刻地影响着你与AI交互的体验。一个经过良好RLHF训练的模型,会更“懂事”、更会“说人话”,也更不容易“发疯”或产生“幻觉”。
字母S:
Seedream (即梦)

302.AI相关测评:《AI生图新王登基?即梦Seedream 4.0对决Nano Banana六轮实测全揭晓》
定义:由字节跳动(ByteDance)研发的一系列世界级、多模态、多任务生成式AI模型的总称。它并非单一模型,而是一个庞大的、旨在全面覆盖AIGC创作需求的模型家族,其目标是构建一个能够深刻理解和模拟物理世界、并在此基础上进行高质量内容生成的“世界模型”(World Model)。
通俗解释:Seedream是字节跳动集全公司之力打造的银河战舰,它不仅仅想做图像,而是要打造一个能统一处理和生成文本、图像、视频、音频乃至3D内容的终极创意引擎。
核心特色与强大之处 (以Seedream 4.0为例):
- 世界模型架构(World Model Architecture):这是Seedream最核心的设计哲学。它通过学习海量视频数据,构建了一个关于现实世界运作规律的内在知识库,包括对空间、时间、物体交互和因果关系的深刻理解。这使得它生成的视频不仅仅是会动的图片,而是具有逻辑和物理真实感的微型世界模拟。
- 多模态融合输入(Multimodal Fusion Input):你不仅可以用文本来描述场景,更可以结合图像作为视觉风格或角色的参考,甚至可以加入音频(Audio)来驱动视频的情绪和节奏。这种多模态输入能力,赋予了创作者前所未有的控制力。
Stable Diffusion (稳定扩散模型)

定义:由Stability AI公司主导开发的一款强大的、开源的文生图扩散模型,以其高度的可定制性、丰富的生态系统和对本地化部署的友好性而闻名。
通俗解释:如果说Midjourney是iPhone,提供了极致简化、美学统一的创作体验,那么Stable Diffusion就是安卓。它将整个AI绘画的厨房——从灶台(模型本身)到锅碗瓢盆(各种插件和脚本)再到秘制酱料(LoRA和ControlNet)——全部向你开放。它的学习曲线更陡峭,但一旦你掌握了它,你就能实现几乎任何你能想象到的、天马行空的视觉效果,成为一个真正意义上的“AI视觉炼金术士”。
应用场景:
- 高度定制化的艺术创作:通过组合不同的模型、LoRA和提示词,创造出独一无二的个人艺术风格。
- 可控的商业应用:利用ControlNet进行精准的构图和姿势控制,生成符合商业需求的插画、设计图和产品概念图。
- 构建自动化工作流:得益于其开源特性,你可以将其作为核心引擎,集成到更复杂的AIGC应用或Pipeline中,实现自动化的图像生产。
Sora

302.AI相关测评:《别再只谈电影级画质,Sora 2评测:当AI开始真正讲中文、做导演,真实感什么水平?》
定义:由OpenAI公司开发的、具有里程碑意义的文生视频大模型,其目标是构建一个能够深刻理解并模拟真实物理世界的“世界模拟器”(World Simulator)。
通俗解释:堪称AI视频领域的王炸。在Sora出现之前,AI生成的视频大多是时长几秒、缺乏逻辑、充满“AI味”的动态片段。而Sora则展示了生成长达一分钟、多镜头、具有复杂场景互动和一致性的、几乎与实拍无异的视频的能力。它不仅仅是在画视频,更是在一个内在的虚拟世界中,演算出一段符合物理规律的动态影像。今年10月发布的Sora 2代更是将音画拟真度拉到了新的高度,全球爆火。
应用场景:
- 电影预演与概念可视化:导演只需输入剧本,Sora就能为其生成动态分镜,极大提升电影前期制作的效率。
- 广告与营销内容制作:快速生成高质量、富有创意的广告短片和社交媒体内容。
- 教育与培训:模拟复杂的科学实验、历史事件或手术过程,创造出沉浸式的学习体验。
Suno

302.AI相关测评:《2025年AI音乐模型评测:孤独的Suno与国产模型的追赶者们》
定义:一款领先的AI音乐与歌曲生成模型,能够根据用户输入的文本提示词,生成包含人声、伴奏和完整编曲的高质量原创歌曲。
通俗解释:这就是你的随身AI乐队和AI金牌制作人。你只需提供歌词,并用简单的语言描述想要的音乐风格(如“一首80年代复古合成器流行风格的歌曲,女声主唱,充满希望和怀旧感”),Suno就能在几分钟内为你创作出一首完整的、可以媲美专业制作的歌曲。它极大地降低了音乐创作的门槛,让每一个五音不全的普通人,都有机会成为唱作人。
应用场景:
- 快速音乐创作:为短视频、播客、游戏或个人Vlog快速定制原创背景音乐(BGM)和主题曲。
- 歌词可视化:将你的诗歌、日记或突发的灵感,转化为一首可以听、可以分享的歌曲。
- 音乐教育与启发:通过尝试不同的风格组合,学习和理解各种音乐流派的构成元素。
Seed (种子)
定义:一个用于初始化随机数生成器的数字。在AIGC的扩散模型中,它决定了初始噪声图的具体形态。
通俗解释:这就是AI创作的“出生证明”或“DNA序列号”。在所有其他参数(模型、提示词、尺寸等)都保持不变的前提下,只要Seed值相同,你就能100%复现出完全一样的生成结果。这个特性至关重要。当你“抽卡”得到一张“神图”时,立刻记下它的Seed值,就意味着你锁定了这个完美的创意基因,可以在此基础上进行各种微调和优化。
应用场景:
- 复现作品:保存并分享你的“神种”,让其他创作者也能生成与你同样惊艳的作品。
- 保持一致性:在创作一个系列作品时,固定Seed值可以帮助你保持角色或风格的高度一致。
- 可控的探索:在固定Seed值的基础上,只改变一个参数(如某个提示词),你就能非常直观地看到这个参数对画面的具体影响,是进行精细化调试的必备技巧。
Stylization (风格化)

定义:在AIGC创作中,指将一种独特的艺术风格(如梵高、赛博朋克、水墨画)应用到生成内容上的过程或能力。
通俗解释:这就是为你的AI作品穿上华服的魔法。它让你的创作不再是千篇一律的AI通用脸,而是拥有了独特的艺术灵魂。风格化可以通过多种方式实现:
通过提示词:在Prompt中直接加入风格描述,如“in the style of Hayao Miyazaki”(宫崎骏风格)。
通过LoRA:加载一个专门的风格LoRA插件,这是实现特定、小众风格最有效的方式。
通过图生图:上传一张你喜欢的风格参考图,让AI在生成新图时学习其风格。
应用场景:风格化是AIGC创作中最富乐趣、也最能体现个人创造力的环节。通过不断尝试和组合不同的风格,你可以探索出专属于你的、独一无二的视觉语言。
字母T:
Transformer (变换器)
定义:一种由Google在2017年提出的、基于“自注意力机制”(Self-Attention)的深度学习模型架构,最初用于机器翻译,现已成为几乎所有顶尖大语言模型(LLM)和主流AIGC模型的基础。
通俗解释:如果说神经网络是AI的“大脑”,那么Transformer就是这个大脑的“操作系统”或“思维模式”,它的出现彻底改变了AI处理序列数据(如语言)的方式。在此之前,AI处理一句话时,就像一个线性思维者,必须按顺序逐字阅读。而Transformer架构则赋予了AI一种全局视野,它在处理任何一个词时,都能同时关注到句子中所有其他的词,并计算出它们之间的关联强度。这种一心多用的能力,让AI能够更深刻地理解上下文、长距离依赖和语言的微妙之处。
应用场景:Transformer是你所使用的几乎所有强大AIGC工具的隐形引擎。从驱动ChatGPT对话的GPT系列模型,到Sora用来理解剧本的语言模块,再到Midjourney用来解析你复杂Prompt的大脑,其底层都是Transformer或其变体在不知疲倦地运转。
Token (令牌/代币)

定义:AI模型在处理文本时,所使用的最小、不可再分的语义单位。
通俗解释:这就是AI阅读和思考的基本“字块”。它不是简单的按单词或汉字来切分。
对于英文:一个Token可能是一个完整的单词(如apple),也可能是一个词根(如trans-)或一个标点符号。通常来说,100个Token约等于75个英文单词。
对于中文:一个Token通常对应一个汉字,有时也可能是一个常见的词语。 在AIGC的世界里,Token就是货币。几乎所有的AI服务都是根据你输入(Input Tokens)和模型输出(Output Tokens)的总Token数量来计费的。
应用场景:
- 成本估算:在你提交一个长篇文档让AI总结或翻译前,先用在线Token计算工具估算一下它的Token数量,你就能大致了解需要花费多少钱。
- 上下文长度:每个模型都有一个“最大上下文窗口”(Max Context Window),比如8K、32K或128K Tokens。这代表了模型一次性能够记住和处理的信息量上限。你需要在这个窗口内,高效地组织你的Prompt和背景资料。
Translate (翻译)

302.AI相关教程:《解锁沉浸式翻译的终极形态,自由调用302.AI各大顶尖大模型》
定义:将一种语言的文本或语音,转换为另一种语言的等效内容的过程。在AIGC时代,这一过程由大型语言模型驱动,其质量和流畅度远超以往的统计机器翻译。
通俗解释:这曾是AI最早、最广泛的应用之一,而现在,它已演变成AIGC工作流中的润滑剂和通用接口。热门的插件如沉浸式翻译,通过调用各大LLM模型能够在指定的语言之间即时翻译整个网页,乃至实时视频。
应用场景:
Prompt翻译:看到国外大神分享的惊艳AI作品和Prompt,但看不懂?用AI翻译一下,你就能立刻掌握其咒语精髓。反之,你也可以用中文构思好Prompt,再让AI帮你翻译成更地道、更丰富的英文,以获得更好的出图效果。
Temperature (温度)
定义:一个在AI文本生成中常用的、用于控制生成结果随机性和创造性的参数,其取值通常在0到1之间。
通俗解释:你可以把它想象成AI的“创意兴奋度”调节器。
低温度(如0.1 – 0.4):AI会变得非常“冷静”和“保守”。它倾向于选择最常见、最符合逻辑、概率最高的词语来构建句子。这使得它的回答非常确定、稳定,但也可能显得有些呆板和重复。
高温度(如0.7 – 1.0):AI会变得“热情奔放”和“富有冒险精神”。它会更有可能选择一些不那么常见、但可能更有趣、更具创意的词语。这使得它的回答更具多样性和惊喜感,但也增加了AI幻觉(Hallucination)的风险。
应用场景:
需要事实和准确性时:在进行代码生成、事实问答或文章总结时,调低温度,以获得更可靠、更可预测的结果。
需要创意和灵感时:在进行头脑风暴、故事创作或市场营销文案写作时,调高温度,以激发AI的“想象力”,获得更多意想不到的灵感。
TTS (Text-to-Speech,文本转语音)

302.AI相关测评:《终结“人机感”,MiniMax Speech 2.6 实测:低延迟+全音色复刻颠覆体验》
定义:一种将书面文本转换为人类语音的技术。
通俗解释:这就是让你的电脑或手机开口说话的魔法。早期的TTS声音机械、生硬,被戏称为“机器人腔”。而现代的AIGC驱动的TTS,如ElevenLabs等,已经可以生成与真人录音几乎无法区分的、富有情感和韵律的自然语音。
应用场景:
- 视频配音:为你的教学视频、产品演示或动画短片快速生成高质量的旁白。
- 有声书与播客制作:将长篇小说或文章,一键转换为可以听的有声内容。
- 数字人:为你的AI数字人提供声音,让它能够与用户进行自然的语音交互。
字母U:
UI (User Interface,用户界面)
定义:指人与机器(特别是计算机程序)进行交互和信息交换的媒介,它包括了用户看到的所有图形、控件、菜单和视觉元素。
通俗解释:这就是你打开任何一个AI应用时,所看到的那个操作台。一个好的UI就像一辆设计精良的汽车的驾驶舱,方向盘、油门、刹车、仪表盘都布局合理、触手可及,让你能专注于驾驶(创作)本身,而不会被复杂的操作搞得手忙脚乱。反之,一个糟糕的UI则会让你感觉像是在开一架按钮上万、说明书比字典还厚的古董飞机。
应用场景:
- Stable Diffusion WebUI:最著名的例子之一。由社区开发者(特别是AUTOMATIC1111)创建的这个WebUI,将极其复杂的Stable Diffusion模型,封装成了一个相对直观、布满各种滑块和输入框的图形界面,极大地降低了普通用户的使用门槛。
- Midjourney on Discord:采用了极简的“对话框式”UI,你所有的操作都通过输入斜杠命令(
/imagine)来完成。这种设计虽然初看有些简陋,但却非常符合其社区驱动的创作模式。 - ComfyUI:一种节点式的UI,你需要像连接电路图一样,将不同的功能模块(加载模型、输入Prompt、采样、保存图片)用“线”连接起来。这种UI虽然学习成本最高,但它给予了用户最大程度的自由度和对工作流的控制力。
UX (User Experience,用户体验)
- 定义:指用户在使用一个产品、系统或服务时,所建立起来的纯主观的感受和情绪。它涵盖了从易用性、效率到情感共鸣等所有方面。
- 通俗解释:如果说UI是“长相”,那么UX就是“灵魂”。一个拥有漂亮UI但反应迟钝、频繁卡顿、操作反人类的应用,其UX是灾难性的。好的UX意味着:
应用场景:UX是你选择并长期使用一个AIGC平台的最终决定性因素。一个平台可能模型不是最顶尖的,但如果它的UX做得足够好,让创作过程成为一种享受,那么它依然能赢得大量忠实用户。
Upscaling (放大/变高清)

定义:一种图像处理技术,通过特定的算法(如插值算法或AI驱动的生成算法),将低分辨率的图像提升至高分辨率,同时尽可能地保持或增强其清晰度和细节。
通俗解释:这就是AIGC工具箱里的“放大镜”和“修复画笔”。当你用AI生成了一张512×512的小样,但想把它打印成海报时,你就需要使用Upscaling功能,把它变成一张4K甚至8K的高清大图。
技术流派:
- 传统算法:如Lanczos、Bicubic等,它们通过数学计算来填充新增加的像素,速度快,但效果通常比较模糊。
- AI修复式放大:如Topaz Gigapixel AI,它通过学习大量高清与低清图像的对应关系,来智能地“脑补”出缺失的细节,效果锐利,保真度高。
- AI生成式放大:最新的技术流派,它会先“理解”图像内容,然后重新绘制一个更高清的版本,能创造出惊人的细节,但有轻微的失真风险。
- 应用场景:
字母V:
VAE (Variational Autoencoder,变分自编码器)
定义:在Stable Diffusion等扩散模型中,VAE是一个至关重要的组成部分,负责在“像素空间”(我们能看到的图像)和“潜空间”(AI进行创作的数学空间)之间进行转换。
通俗解释:如果说潜空间是AI的“梦境”,那么VAE就是连接“梦境”与“现实”的“双向传送门”或“视觉翻译官”。
- 编码(现实 -> 梦境):当进行图生图时,VAE负责将你上传的图片翻译成潜空间中的一串数学代码。
- 解码(梦境 -> 现实):当AI在潜空间中完成创作后,VAE负责将那串最终的数学代码翻译回我们能看到的、五彩斑斓的像素图像。 不同的VAE“翻译官”有不同的“口音”和“风格”,因此,更换VAE文件会显著改变生成图像的色彩、对比度和光泽感,有时甚至能修复一些细节瑕疵。
应用场景:在Stable Diffusion工作流中,选择和更换VAE是一个简单而有效的“后期调色”技巧。当你觉得生成的图片色彩发灰、不够鲜艳时,尝试换一个更受欢迎的VAE文件,往往能带来立竿见影的改善。
Vector (矢量)
定义:在线性代数中,指一个同时具有大小和方向的量。在AIGC语境下,矢量(特指嵌入矢量 Embedding Vector)是一个由一长串数字组成的数组,它被用来在多维数学空间中,表示一个特定概念(如一个词、一张图片)的坐标。
通俗解释:这就是AI用来理解世界的通用语言和GPS定位系统。在AI的精神世界(潜空间 Latent Space)里,每一个概念都有一个独一无二的坐标,这个坐标就是矢量。
“国王”的矢量与“女王”的矢量在空间中的位置非常接近。
“国王”的矢量 – “男人”的矢量 + “女人”的矢量 ≈ “女王”的矢量。这个著名的例子展示了矢量运算如何捕捉到概念之间的逻辑关系。
你的每一个Prompt,都会被分解成一堆词的矢量,AI通过计算这些矢量的关系,来理解你的创作意图。
应用场景:矢量是整个现代AI技术的数学基石。
- 语义搜索:当你进行图片搜索时,系统会将你的文字查询和图库中的图片都转换为矢量,然后寻找在矢量空间中距离最近的图片,从而实现用文字搜图。
- 推荐系统:视频网站会根据你看过的视频的矢量特征,为你推荐在矢量空间中与它们品味相近的其他视频。
- 模型训练:AI的学习过程,本质上就是不断调整其内部参数,以便能将输入数据(如图片)正确地映射到潜空间中对应的矢量坐标上。
Veo

302.AI相关测评:《 Veo 3.1评测:Google的0.1次迭代能否撬动Sora 2的王座?》
定义:由Google DeepMind开发、并深度集成于其下一代AI助手Gemini中的顶尖视频生成模型系列。VEO并非单一模型,而是一个不断进化的技术家族,旨在根据文本或图像指令,生成具有高度逼真感、电影级质感和丰富细节的视频内容。
通俗解释:Veo不仅仅是一个工具,更是Google将其在计算机视觉、自然语言理解和视频技术领域数十年积累融为一体的集大成者。它能深刻理解复杂的物理世界和镜头语言,捕捉细腻的人类表情,并创造出风格多样的视觉奇观。
核心特色与迭代:
- 深度集成于Gemini:与竞品不同,VEO从诞生之初就与Google的旗舰AI助手Gemini紧密绑定。用户可以直接在Gemini的移动应用或网页端,通过简单的文字或图片提示,调用VEO生成视频,极大地降低了使用门槛。
- 电影级质感与控制:VEO的设计强调电影感。用户不仅能描述场景,更能指定“航拍”、“延时摄影”等专业镜头语言,甚至可以选择电影级(cinematic)风格模板,一键生成带有背景音乐(BGM)和字幕的完整视频片段。
- 快速迭代的强大版本:
- Veo 3.1:这是目前最先进的版本,能够生成长达8秒、720p或1080p的高保真视频,并实现了原生音画同步,在逼真度上达到了惊人的水准。
Vidu (视界)

302.AI相关测评:《不止于形,更在于神——Vidu Q2 实测:“演技派”领跑AI视频内卷新方向》
定义:由生数科技(Shengshu Technology)与清华大学联合研发的一款新兴的、强大的AI视频生成模型。它旨在通过人工智能技术,帮助用户快速、便捷地创造出高质量的视频内容,实现个人化的艺术创想。
- 核心特色与强大之处:
- 参考图生视频(Reference-to-Video):这是Vidu最引人瞩目的核心功能之一。在2025年第三季度发布的Q1版本中,Vidu正式开放了这一功能,允许用户上传多张(3张或更多)参考图片。Vidu会根据用户的文本提示词,将这些不同的视觉元素(如特定的人物、物体或场景风格)智能地“融合”在一场无缝衔接的视频中。这极大地提升了视频内容的可控性和角色一致性。
- 高质量与高效率:Vidu致力于帮助用户快速创建高质量的视频内容。这意味着它在算法层面不仅追求生成画面的精美度,也同样注重推理速度和用户体验,力求在“效果”与“效率”之间找到最佳平衡。
Video-to-Video (视频转视频)

302.AI相关教程:《视频版“一键换装”来了!动作生成模型Wan2.2-Animate测评》
定义:一种AIGC工作模式,它以一段现有的视频作为基础输入(通常是其动作和结构),结合用户的文本提示词,来生成一段内容和风格被完全改变、但保留了原视频动态轨迹的新视频。
通俗解释:这就是AI视频领域的“Remix”或“一键换装”。你可以上传一段自己跳舞的视频,然后输入Prompt“一个身穿中世纪盔甲的骑士,在城堡里跳舞,电影级画质”,AI就会生成一个骑士,完美复刻你视频中的所有舞蹈动作。
应用场景:
创意特效制作:将普通的生活视频快速转化为科幻、奇幻或动漫风格的大片。
降低动画制作门槛:真人演员先进行动作表演,再通过Video-to-Video技术将其转化为动画角色,极大地提升了动画制作的效率。
VFX (Visual Effects,视觉特效)

定义:在影视制作中,为了创造或增强那些无法通过实拍获得的镜头,而利用计算机生成的图像、动画和模拟效果。
通俗解释:这就是电影中的“魔法”。从《阿凡达》中潘多拉星球的奇珍异兽,到《复仇者联盟》中毁天灭地的宏大战争场面,都离不开VFX的功劳。
AIGC如何颠覆VFX:AIGC正在将原本属于好莱坞顶级工作室的VFX能力,民主化给每一个普通创作者。
- 工具代表:Higgsfield等平台,就以提供“好莱坞级”的AI视觉特效为核心卖点,让用户可以一键生成“地球拉远”、“魔法能量波”等病毒式传播的特效视频。
- 降低门槛:过去需要专业特效师在Houdini、Maya等复杂软件中耗费数周才能完成的镜头,现在可能只需要几句Prompt和几分钟的渲染时间。
应用场景:短视频特效、广告创意、独立电影制作、个人艺术项目等。
字母W:
Wan (通义万象)

302.AI相关测评:《国产AI视频“2.5时代”首战:Wan2.5的“电影感”与Kling 2.5的“稳定美学”,能否击败Veo 3?》
定义:由阿里巴巴集团通义实验室研发的一套全面、开源的视频基础模型套件,旨在推动视频生成技术的边界,其命名“万象”寓意着包罗万象、森罗万象的强大生成能力。
通俗解释:Wan 可谓是致力于将视频模型开源化和体系化的铺路巨匠。它不仅仅是一个单一的视频生成模型,而是一个包含了从图像、视频到音频处理的全套工具箱。你可以把它想象成视频生成领域的Stable Diffusion——它向全世界的开发者和研究者,开放了构建顶级视频生成能力的核心技术。
核心特色与强大之处:
- 开源的视频基础模型套件:这是Wan最核心的价值。它提供了一套完整的、用于构建大规模视频生成模型的开源方案,涵盖了图像、视频和音频的先进扩散模型技术。这极大地降低了研究和开发视频生成技术的门槛,让更多人能参与到这场技术革命中。
- 全面的多模态生成能力:以其最新的Wan 2.2版本为例,它是一个在多模态生成领域取得突破性进展的模型,正在重新定义文生视频(text-to-video)与图生视频(image-to-video)的技术边界。它不仅能生成720P分辨率、24fps的视频,还能在消费级的4090显卡上运行,展现了其在性能与效率上的出色优化。
- 活跃的开源社区生态:正如其在GitHub上的
Wan-Video/Wan2.1和Wan2.2代码库所展示的,Wan拥有一个极其活跃的开发者社区,数以百计的问题(Issues)和拉取请求(Pull requests)代表着全球开发者正在持续不断地为其贡献代码、修复问题和拓展功能。这种社区驱动的迭代模式,是其保持技术活力的关键。
WebUI (Web User Interface,网页用户界面)

定义:一种通过网页浏览器来访问和操作的图形用户界面。在AIGC领域,它特指那些将复杂的命令行工具或后端模型,封装成一个直观、可视化的网页操作界面的应用。
通俗解释:这就是让你能够在浏览器里,通过点点鼠标、拖拖滑块就能使用强大AI能力的“控制台”。它把你从需要输入晦涩代码的“黑客模式”中解放出来,进入了所见即所得的“艺术家模式”。最著名的例子就是AUTOMATIC1111开发的Stable Diffusion WebUI,它凭借其强大的功能、丰富的插件和开源的特性,成为了事实上的开源AI绘画“操作系统”。
- 应用场景:
- 本地部署:在自己的电脑上安装Stable Diffusion WebUI,你就可以无限制地、免费地生成图片,并且可以自由安装各种模型和插件,实现最大程度的定制化。
- 云端服务:许多云平台(如Google Colab)也提供预装好的WebUI环境,让你可以在没有高端显卡的情况下,也能体验到完整的AIGC创作流程。
- 社区生态:WebUI的出现,催生了庞大的插件和扩展生态。无论你需要更精细的姿势控制、更强大的批量处理,还是更智能的提示词辅助,几乎都能找到相应的WebUI插件来满足你的需求。
Weights (权重)
定义:在神经网络中,指模型在训练过程中学习到的、用于衡量神经元之间连接强度的数值参数。它们是模型知识和能力的数学体现。
通俗解释:如果说神经网络是AI的“大脑”,那么权重就是连接大脑中亿万个“神经元”的“突触强度”。AI的学习过程,本质上就是通过海量数据的“刺激”,不断调整这些“突触”的强度(即权重值),最终形成一个能够对新信息做出正确反应的复杂网络。我们常说的模型文件(如.ckpt或.safetensors格式的文件),其核心内容就是这一整套庞大而精密的权重数值。
应用场景:
- 模型选择:你下载和切换不同的AI模型,实际上就是在加载不同的权重文件,体验由不同知识结构带来的不同画风和能力。
- 模型合并(Merge):一些高级玩法允许你将两个或多个模型的权重文件按一定比例进行混合,从而创造出一个兼具两者风格的全新模型,这就像是在进行AI基因重组。
- LoRA的原理:LoRA之所以轻量,就是因为它并不修改模型主体庞大的权重,而是额外训练一个微小的权重补丁,在推理时动态地添加到主权重上,从而实现对模型行为的微调。
Watermark (水印)
定义:为了标识版权、声明来源或进行溯源,而在数字内容(如图片、视频、音频)中嵌入的一种可见或不可见的标记。
通俗解释:这就是AI作品的“出生印记”或“数字身份证”。它有两种主要形式:
- 可见水印:一些AI服务(如Midjourney的早期版本)会在生成的图片角落加上自己的Logo,这是最直接的品牌宣传和来源标识。
- 不可见水印(数字水印):更先进的技术,通过对图像的像素或音频的频谱进行微不可察的修改,将版权信息隐藏在作品中。这种水印肉眼无法察觉,但可以通过特定的算法进行读取,用于追踪作品的来源和传播路径,是打击盗用和虚假信息的重要技术手段。
应用场景:
- 版权保护:作为创作者,你可以为你发布的作品添加自己的水印,以防止未经授权的使用。
- 真伪辨别:随着AIGC内容越来越逼真,检测是否存在数字水印,将成为辨别一张图片或一段视频是真实拍摄还是AI生成的关键方法之一。
- 平台责任:为了应对AI滥用的风险,越来越多的AIGC平台被要求为其生成的内容添加不可见的溯源水印,以确保内容的可追溯性。
字母X,Y,Z:
X/Y/Z Plot (X/Y/Z图表/多维对比图)
定义:一种在Stable Diffusion WebUI等工具中内置的、强大的脚本功能,它允许用户选择最多三个不同的变量(分别对应X轴、Y轴和Z轴),来自动生成一个网格状的对比图,以系统地、可视化地比较这些变量对最终生成图像的影响。
通俗解释:这就是AIGC绘画领域的控制变量实验法和终极大杀器。你是否曾纠结于“哪个采样器效果最好?”、“CFG Scale设为7还是8.5更合适?”、“这个LoRA的权重应该给多少?”。X/Y/Z Plot就是为了解决这些选择困难症而生的。它让你告别了凭感觉炼丹的时代,进入了有理有据、眼见为实的科学炼丹时代。
X轴:你可以设置成不同的采样器(Samplers)。
Y轴:你可以设置成不同的CFG Scale值(如从5到10,步长为0.5)。
Z轴:你可以设置成不同的模型(Checkpoints)。 运行这个脚本后,它会自动生成一个巨大的图片网格。每一行、每一列都代表着一种参数组合下的出图结果。你只需扫一眼这张大图,就能立刻找到你最喜欢的那张最优解,并洞悉不同参数的细微影响。
应用场景:
- 参数调优:系统性地测试不同CFG Scale、采样步数(Steps)、采样器对特定Prompt的影响,找到黄金参数组合。
- 模型/LoRA对比:将多个同风格的模型或LoRA作为变量,快速对比它们在相同Prompt下的表现力差异。
- Prompt探索:在Prompt中设置一个变量,例如“a cat in [season] style”(一只[季节]风格的猫),然后在X轴输入“spring, summer, autumn, winter”,脚本就会自动生成四张分别对应春夏秋冬风格的猫图,是进行创意探索的利器。
当我们的旅程抵达最后一个字母“Z”,我们既到达了这本《万字指南》的终点(Zenith),也站在了一个全新的起点(Zero Point)。从Agent的自主规划,到LoRA的个性定制,再到Sora 2与Veo 3所开启的世界模拟器时代,我们共同见证了AIGC技术如何将复杂的学术词汇转化为我们触手可及的黑科技。
这篇万字指南的初衷,并非是让你成为一名AI科学家,而是希望通过翻译这些技术名词,为你拆除那座由认知壁垒构成的巴别塔,让你在面对AI时不再感到手足无措。
技术的浪潮终将趋于平静,而真正能在时代中留下印记的,永远是那些掌握了新语言、并用它来讲述全新故事的创作者。现在,钥匙已经交到你的手中。去探索、去创造、去犯错、去定义属于你的AIGC工作流吧。
因为,下一个颠覆行业的伟大作品,或许就将诞生于你下一次点击生成的瞬间。
了解更多AI行业动态,原创测评内容,干货教程,欢迎关注订阅302.AI各平台账号。
