


文 | Jomy @302.AI
编 | 南乔River @ShowMeAI
I. 一切的开端
CloseAI在24年发布了o1,指出了未来Scaling Law的方向:增加思考时间来换取更多智能,而不是用更大的模型或更多的训练数据。CloseAI没告诉任何人具体该怎么做,只是将自己的成果做成了收费产品。
虽然大家都知道了这个宏观方向,但是不知道具体的实现方式,就像只告诉你目的地在东北方向,路线一概不知,所以没有人可以复现o1的成功。之前的仿o1模型,都在尝试各种方法,虽然都叫cot(思维链),但是并没有展现出强大的思考能力,离o1还差了一大截。估计CloseAI打算靠这个独家秘籍作为技术壁垒,发家致富。

![]()
II. 大道至简
没想到2025年1月,突然Deepseek发了一个论文,并发布了R1系列模型。他们直接给大家揭开了CloseAI一直藏着掖着的秘密:如何训练出一个真正有思考能力的模型。
正所谓大道至简,Deepseek发现,想训练出一个有思考能力的模型,其实没有那么多弯弯绕绕,结论很简单:RL (强化学习) is all you need。通俗点说,就是告诉机器人目标和结果,让机器自己慢慢领悟就好了,不需要干预太多。
Deepseek在论文里很明确的写到:什么过程奖励模型,什么蒙特卡洛搜索树这种和过程相关的算法,都是失败的尝试。他们使用了一个新的目标奖励方法,剩下的就让机器自己去学习。
此时历史就像一个循环,当年AlphaGo能在围棋下出神之一手,正是因为摆脱了人类的棋谱,纯靠强化学习。而现在Deepseek给出了相同的答案,别搞什么RLHF,别搞什么SFT,人类别自以为是了,机器是无法通过模仿来超越人类的。
其实之前其他人也不是没走过这条路,毕竟强化学习都算是“古典AI”了,Deepseek之所以走通,也是因为他们找到了一个合适的算法(GRPO),才能够让机器在有限的资源下,不断的学习和成长。
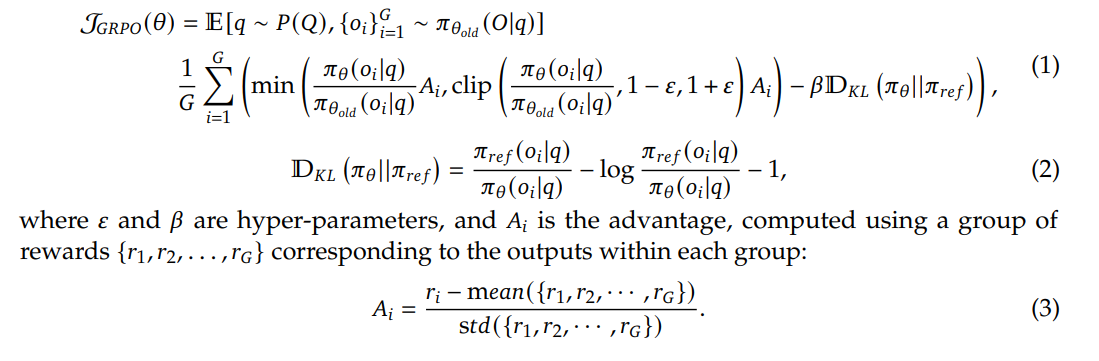
![]()
(摘选自原论文的GRPO算法公式)
III. 原型机
Deepseek通过让Deepseek-V3模型纯强化学习(RL),训练了个模型叫Deepseek-R1-Zero,其实这玩意比较像一个原型机,用来验证这个概念是正确的。结果也如图片所示,能力超群,经过8000步的训练后,模型能力提高了几倍,甚至超越了o1-0912。但是这个模型放到生产环境,会有很多问题(比如多语言混杂,输出看不懂等),需要再精加工一下,让这个模型变得更用户友好。
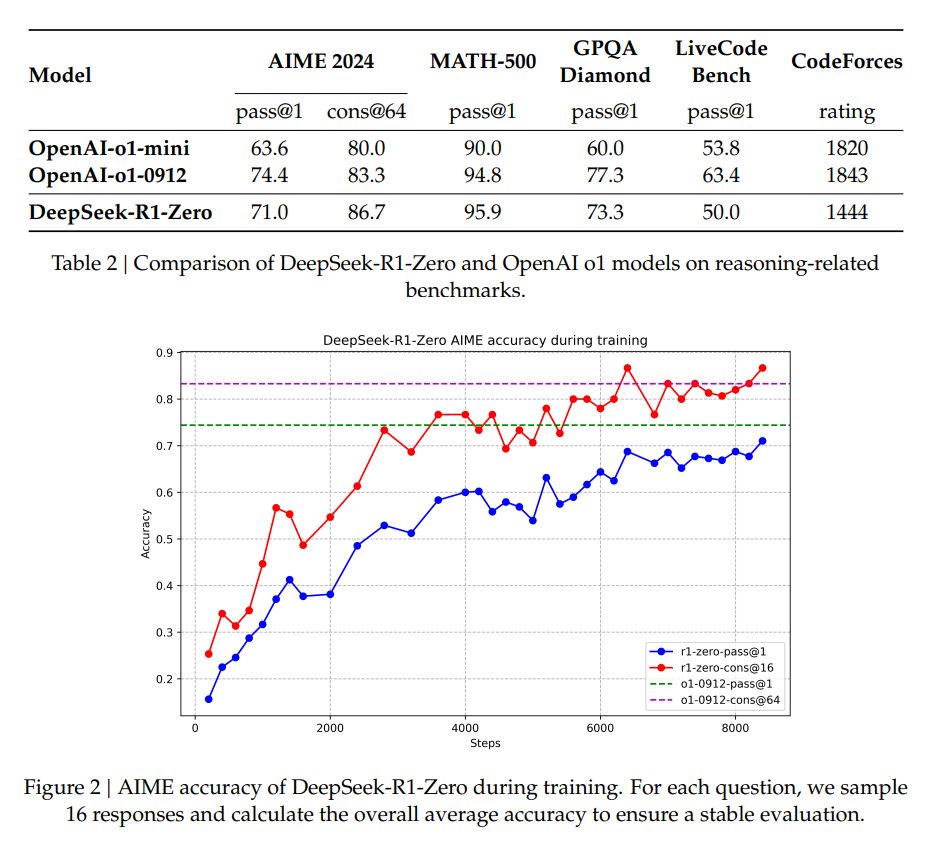
![]()
(模型能力随着RL训练次数的增加,线性上升)
IV. 成熟产品
他们就继续搞了个现在大家熟知的Deepseek-R1。R1其实就是在原来的纯强化学习(RL)基础上,加了很多人类的干预(SFT),让输出更加可控,让整个模型更加友好。过程比较复杂,大概就是结合了微调和强化学习,算是传统和创新结合,重新训练了一个生产环境可用的模型:Deepseek-R1。
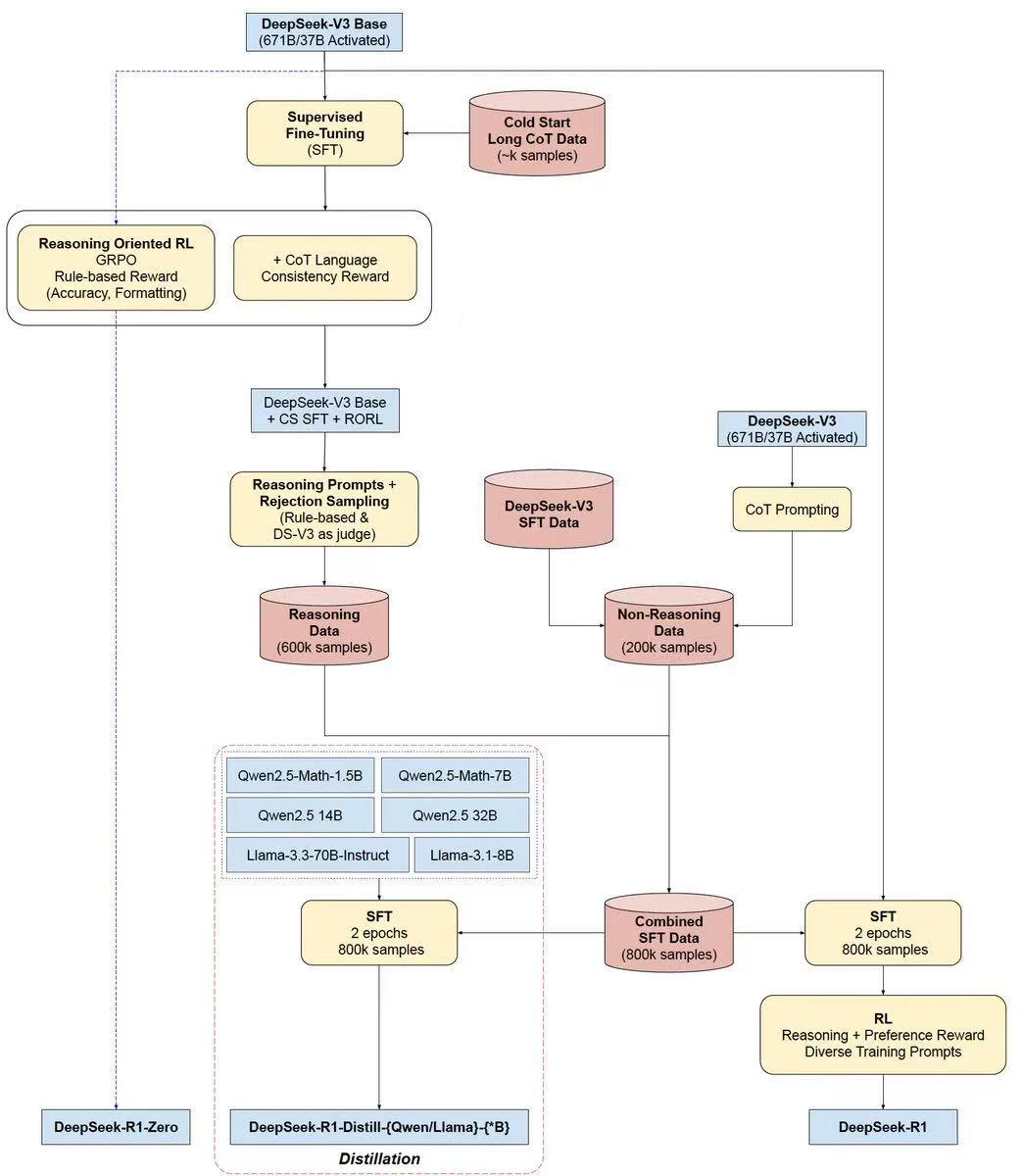
![]()
(R1的训练步骤图解)
V. 从大到小
但是这玩意本质还是Deepseek-v3基于训练的,参数很大,普通机器是跑不起来的,他们又继续搞了一些小模型出来,大大降低部署门槛,甚至做到个人电脑可部署。
但是这个小模型也是有些隐秘门道,小模型本质是基于R1的合成数据训练的微调模型,并没有经过强化学习训练,所以说本质上他们不算是真正的“思考模型”。而Deepseek为什么这么做呢,其实他们论文也写了:他们发现小模型经过强化学习效果并不好,远不如经过思考数据微调的。个人猜测是因为小模型本来智力就比较低,学也学不明白,所以别搞什么思考了,不如照葫芦画瓢,照着大模型思考的模式抄一抄,效果也不错,就像那些抄学霸答案的学渣,总比自己乱答强。
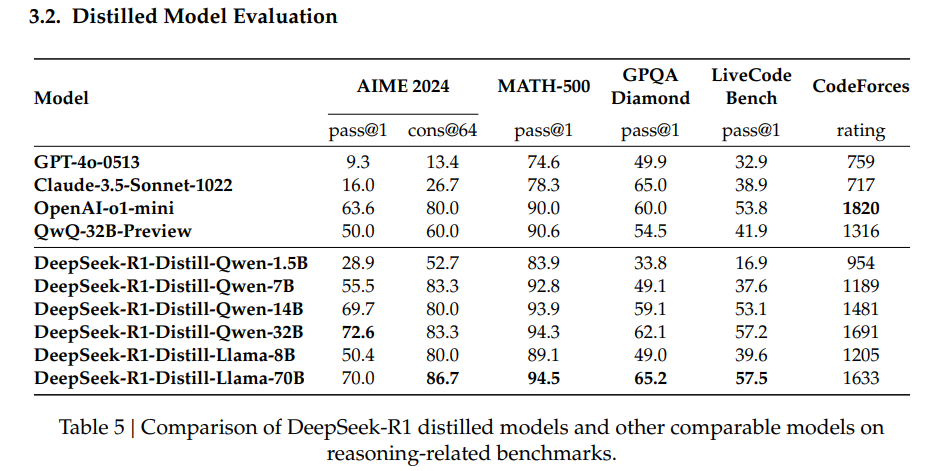
![]()
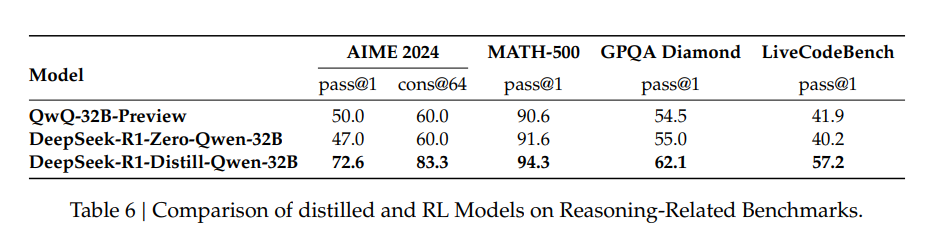
![]() (Deepseek-R1-Zero-Qwen-32B是经过RL训练的小模型,远不如蒸馏模型)
(Deepseek-R1-Zero-Qwen-32B是经过RL训练的小模型,远不如蒸馏模型)
VI. 三个结论
所以Deepseek这个研究成果,展示了三个结论:
1.模型的思考能力的锻炼靠强化学习就可以了,这个阶段人类不要干预(Deepseek-R1-zero)
2.模型学会思考后,还是需要人类的参与才能让模型学会如何和人类沟通(Deepseek-R1)
3.小模型就别自己思考了,蒸馏的效果更好。思考能力的增强和原来的模型的能力密切相关。(Deepseek-R1-distill)
VII. 四个推断

这三个结论,把CloseAI藏着掖着的商业秘密直接揭露了(有可能CloseAI了解得还没Deepseek多,who knows),并且我也得出几个推断:
1.更大的基础模型可能不是没有意义,而是需要经过强化学习的后训练,才知道提升有多大。这就是新的Scaling Law。
2.小模型可以不用学会思考,越强的思考模型可以蒸馏出越好的小模型,小模型应该很快就会超越现在顶级模型的水平
3.在不同领域通过强化学习训练出强大的专业思考模型,再将思考模型蒸馏出轻量的小模型,再本地化部署,可能会是一个不错的生意
4.真正的思考模型展示了真正的智能,AI不仅是知识的压缩,而是真的可以学会思考,最终超越人类,AGI又往前迈出了一步。

![]()
VIII. 一些感想
CloseAI可能早就明白了这个道理,但想通过闭源来获得商业的垄断。可是现实并没有如意,因为在大的科技浪潮面前,没有任何成果是不可复制的,如果不是Deepseek发现,我相信迟早都还会有其他的公司发现。但是机会总是留给最强者,Deepseek实至名归。
虽然Deepseek没有开源所有的细节和研究过程,但我相信有了现在的理论基础,业内的人已经开始在这个基础上研发更强大的思考模型了。原来那些参数巨大但表现不佳的模型,可能经过RL的后训练,摇身一变成为强大的思考模型,强大的思考模型又蒸馏出更多强大的小模型,不断的循环。我预测2025年,AI行业大概率会迎来真正的奇异点,而下一次爆发,我相信还是会在中国。
论文链接:https://arxiv.org/pdf/2501.12948
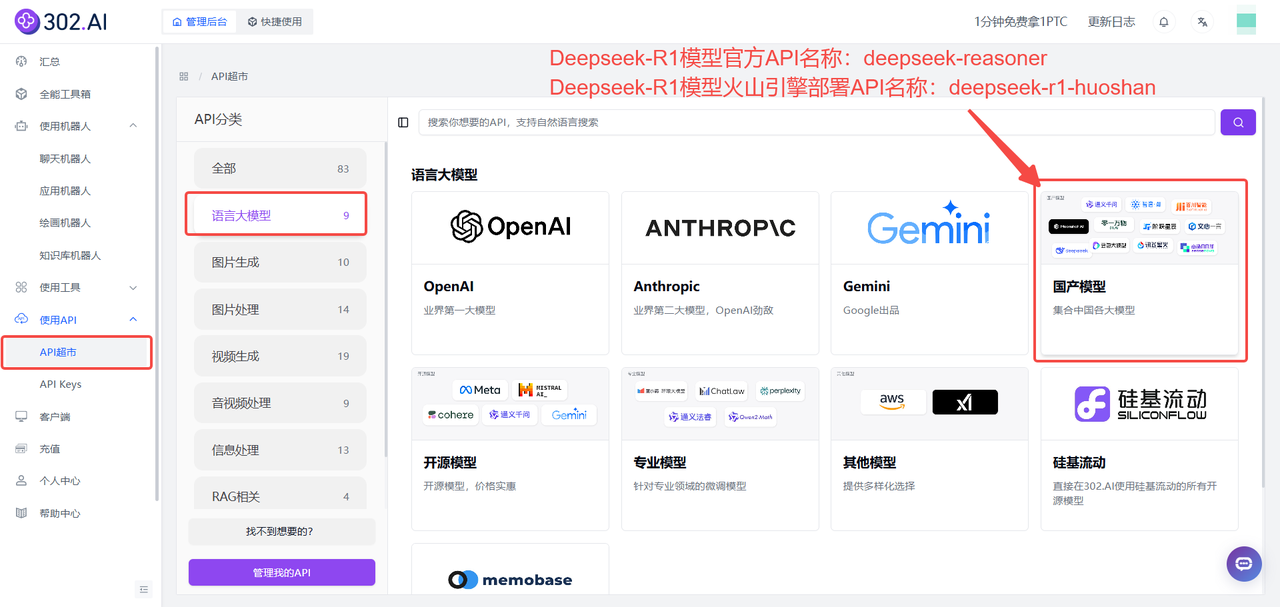
如何在302.AI上使用Deepseek-R1:
302.AI提供按需付费的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
(1)可使用官方Deepseek-R1模型:
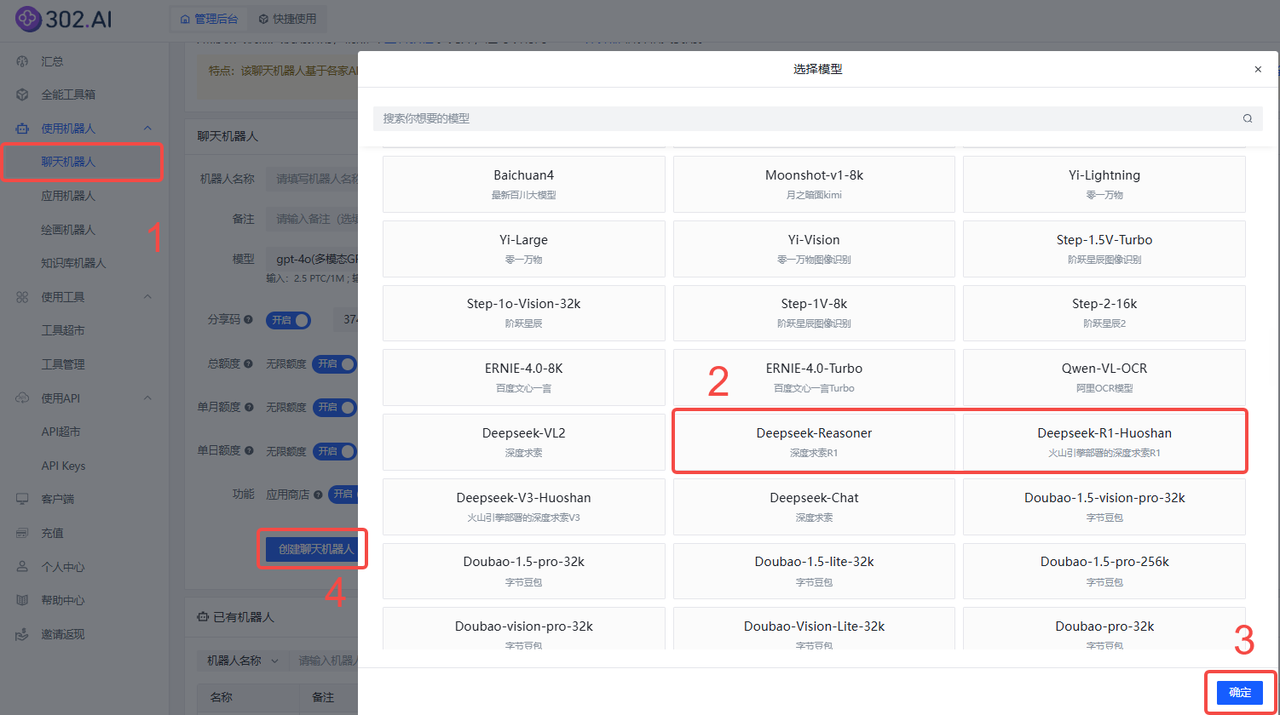
依次点击:使用机器人→聊天机器人→ 模型→国产模型→Deepseek-Reasoner→ 确定→ 创建聊天机器人;
(2)使用火山引擎部署的Deepseek-R1模型:
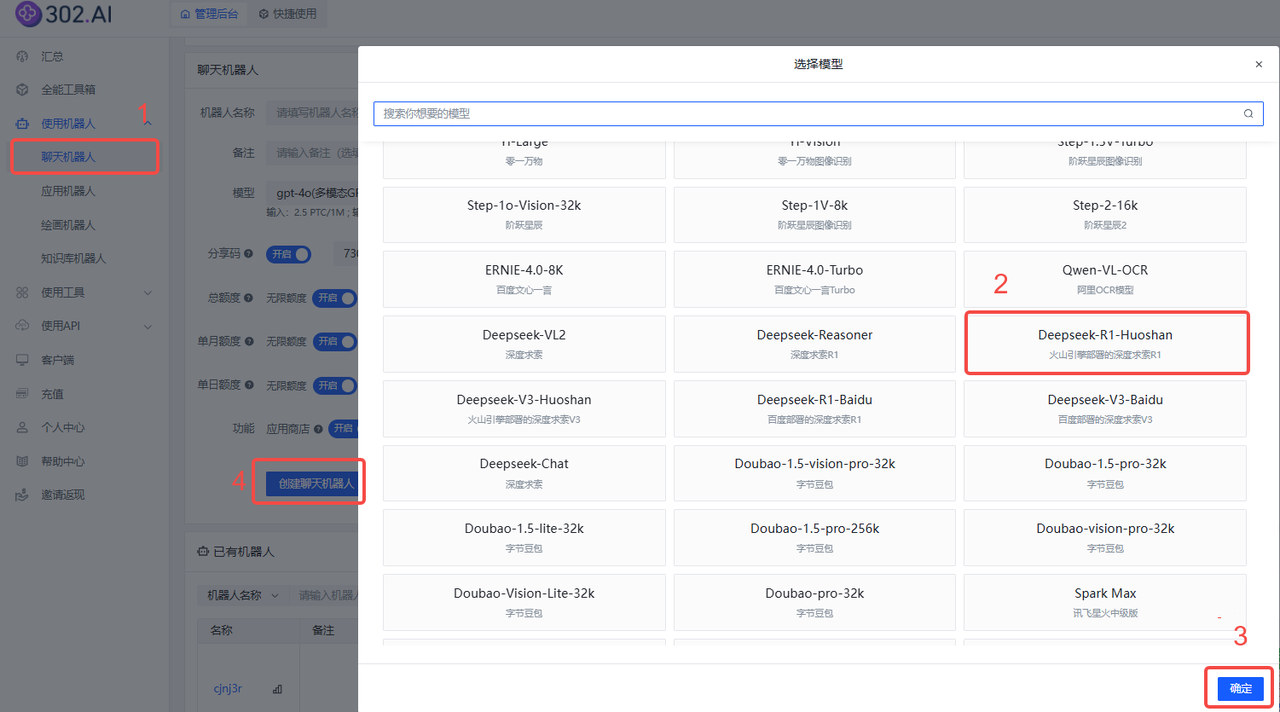
依次点击:使用机器人→聊天机器人→ 模型→国产模型→Deepseek-R1-Huoshan→ 确定→ 创建聊天机器人;
(3)也可使用硅基流动部署的Deepseek-R1模型:
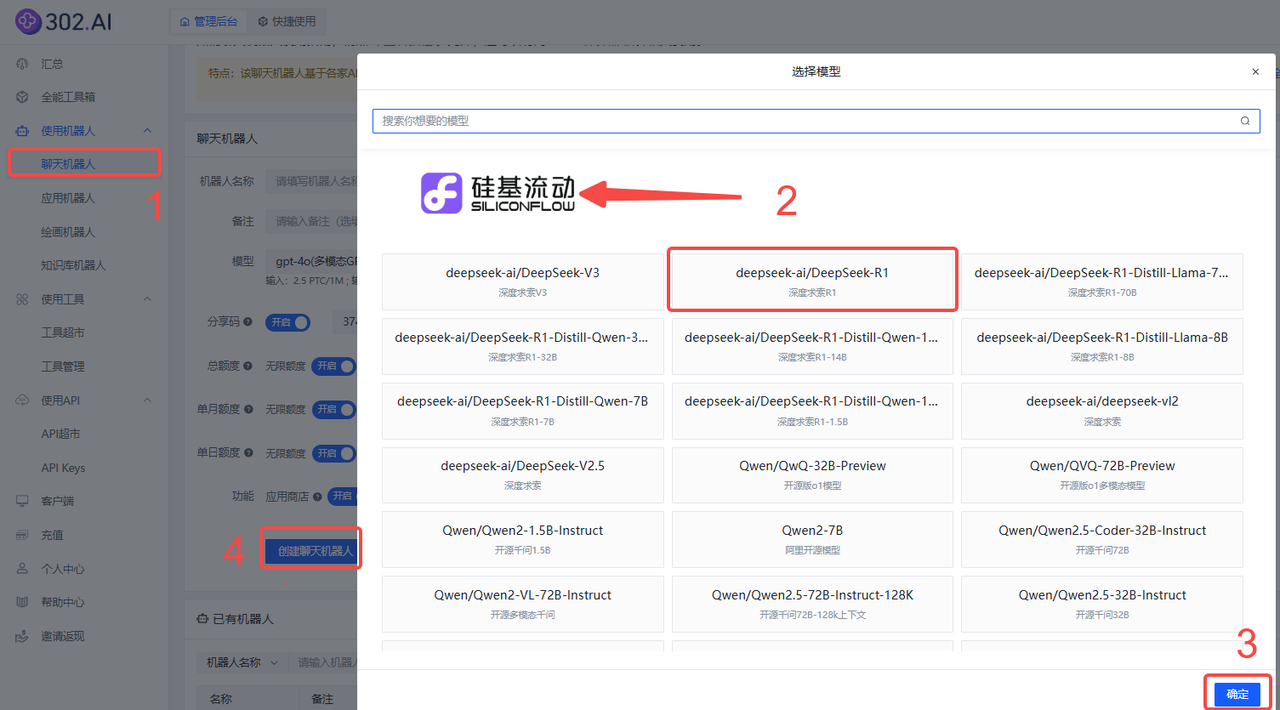
依次点击:使用机器人→聊天机器人→ 模型→硅基流动→deepseek-ai/DeepSeek-R1→ 确定→ 创建聊天机器人;
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
(1)Deepseek-R1模型官方API名称:deepseek-reasoner
(2)Deepseek-R1模型火山引擎部署API名称:deepseek-r1-huoshan
(3)Deepseek-R1模型硅基流动部署API名称:deepseek-ai/DeepSeek-R1
(4)Deepseek-R1模型百度部署API名称:deepseek-r1-baidu
相关文档:使用API→API超市→语言大模型→ 国产模型;
相关文档:使用API→API超市→语言大模型→ 硅基流动;


评论(12)
[…] 我在上一篇文章里写道,CloseAI 在 2024 年指明了未来的发展方向:增加思考时间以换取更多智能。但它没透露任何实现细节,由此,整个大模型行业开始苦苦寻找 o1 背后的奥秘。 […]
I am happy that I noticed this web site, just the right information that I was looking for! .
Hello! I just would like to give a huge thumbs up for the great info you have here on this post. I will be coming back to your blog for more soon.
It’s actually a nice and useful piece of information. I am glad that you shared this useful info with us. Please keep us up to date like this. Thanks for sharing.
Thank you for the auspicious writeup. It in reality used to be a enjoyment account it. Glance complex to far delivered agreeable from you! However, how could we keep up a correspondence?
It¦s actually a great and helpful piece of info. I¦m happy that you shared this helpful info with us. Please keep us informed like this. Thank you for sharing.
Good write-up, I¦m normal visitor of one¦s site, maintain up the excellent operate, and It is going to be a regular visitor for a long time.
I really lucky to find this site on bing, just what I was searching for : D also bookmarked.
I would like to thank you for the efforts you have put in writing this site. I’m hoping the same high-grade site post from you in the upcoming also. Actually your creative writing skills has inspired me to get my own site now. Actually the blogging is spreading its wings fast. Your write up is a good example of it.
But a smiling visitant here to share the love (:, btw great style.
I like this site very much, Its a rattling nice position to read and receive info .
Hiya! I just want to give a huge thumbs up for the great info you’ve got here on this post. I shall be coming back to your blog for extra soon.