


一则新闻
今天猛然看到一则新闻标题,大意是李飞飞团队仅用 50 美金就复刻出了一个媲美 R1 的模型。我的第一反应是「不可能,又是什么标题党」;第二反应是「数据应该不是凭空捏造的,索性求证一下?」

![]()
然后,我找到了原始论文《s1: Simple test-time scaling》(https://arxiv.org/pdf/2501.19393)。仔细拜读之后发现,某种程度上来说,这则新闻居然是对的?!虽然非常地断章取义(故意隐去了很多背景条件)。
在我看来,这件事更准确、更靠近真相的表达是:李飞飞团队找到了一种新方法,让普通模型进化为推理模型。
另一种尝试
我在上一篇文章里写道,CloseAI 在 2024 年指明了未来的发展方向:增加思考时间以换取更多智能。但它没透露任何实现细节,由此,整个大模型行业开始苦苦寻找 o1 背后的奥秘。
DeepSeek 找到的是:让模型自己学会多思考。
李飞飞团队找到的是:如何强制让模型多思考。
打个比方,DeepSeek 让学生通过大量训练提高了自己的能力,之后做题的时候,自然而然就会多想一想(够学霸)。李飞飞团队则是让一个学生在做题的时候,强迫自己多审题多反思,不要着急给答案(够认真)。
其实,这两种方法还可以结合。而且,很多人猜测 o1 就是结合了这两种方法,训练时先提高自己的推理能力,推理时再强迫自己多想一想。
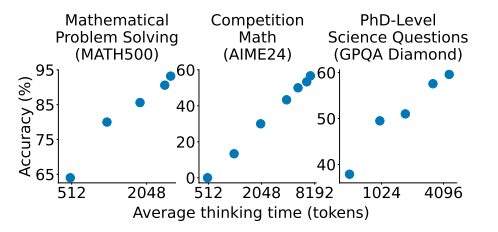
![]()
(图表显示了在其方法下,随着思考时间的线性增加,模型性能的提升。)
50 美元的来源
说回我看到的那则新闻。
整个标题最吸睛的就是 50 美元这个金额(与动辄数百万、数千万美元的花费相比,这个金额实在低到夸张)。但是,通读整篇论文,我都没看到这个数字。
原来,50 美元是由论文中提到的「仅需要 16 个 H100 GPU 训练 26 分钟」计算出来的,H100 的租金是 3 美元/时,所以 3*16 = 48(按一小时起租)。
这也是整则新闻对事实最严重的曲解。说训练这个模型仅花费 50 美元,就如同说在餐厅点了一盘龙虾,然后声称这道菜的制作成本仅为烹饪时消耗掉的燃气。
但是,话又说回来。虽然 50 美元不是模型完整的训练成本,但作为 GPU 消耗成本,这个金额之低,依然值得惊叹!
在技术视角下,这个数据讲述了这样一个故事:李飞飞团队只用1000条精选数据对Qwen2.5-32B进行微调,就将模型能力提高了几倍。
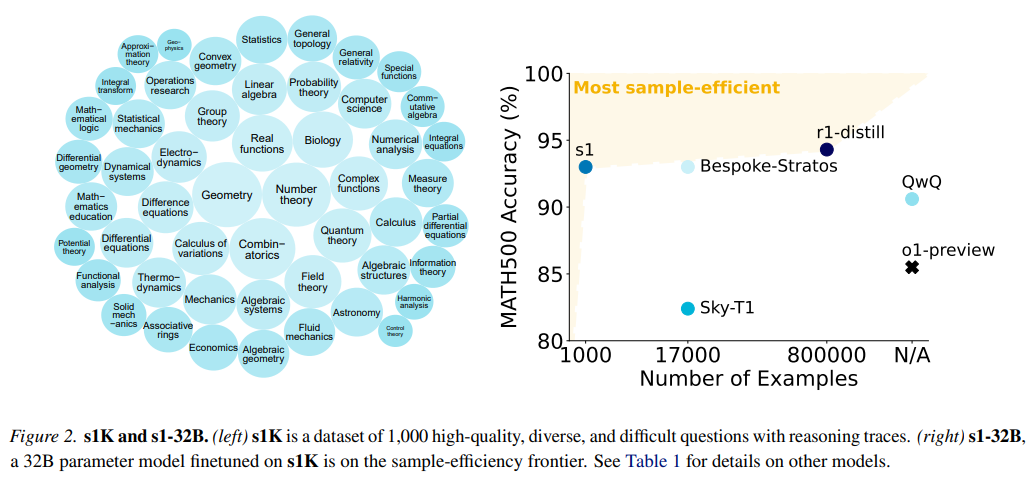
![]()
(图表展示了数据类型、不同模型的训练数据量及其性能比较)
那李飞飞团队是怎么做到的呢?
激活潜能
DeepSeek 在研究 R1 的过程中发现,小模型经过强化学习训练的效果并不好,远不如直接使用大推理模型的数据进行微调。
相似的,李飞飞团队第一步也是先微调了一个新的模型——s1-32B,其微调数据集由「人工挑选问题搭配 Gemini-2.0-Flash-Thinking 生成的过程」组成,然后在 Qwen2.5-32B 上进行监督微调(SFT)。
在这个过程中,团队有一些新的发现:只用 1,000 条精选的高质量数据微调,与用 59,000 条高质量数据微调,效果居然差不多。

![]()
至于原因,他们解释道:执行推理的能力已经存在于我们的模型之中,高效的样本微调阶段只是激活了它。也就是说,小样本微调并不是让模型学习如何思考,而是模型本来就会,它只需要一些引导。
“Wait”
只激活推理能力是不够的,此时的模型在输出时还不会主动思考。第二步的工程发明才是整个论文的重点,即 Budget forcing(BF),中文翻译过来就是强制预算,在输出时强制让模型进入思考。
这个方法的原理也特别简单:在模型输出阶段,先设定一个「时间范围」,如果模型没到时间就停止思考了,就强制让模型再想一想,直至达到设定时间;如果模型超过了设定时间还在思考,就强制让模型停止思考。
此处的时间并非实际的时间,而是输出的 token 数量,为了便于理解而加以类比。

![]()
(让模型再想想的最佳指令也很简单,就是“Wait”)
听起来是不是很熟悉?以前考试,老师都嘱咐别提前交卷,有时间多检查几遍,到时间了立马停笔交卷。这都是同样的道理。
四个推断
1,000 条精选数据微调+强制预算,这套组合拳直接让 Qwen2.5-32B 模型跑分超越了 o1-preview。所以,李飞飞团队的发现,还是很有价值的:第一大大降低了训练数据的要求,第二强制预算这个方法也非常容易实现。
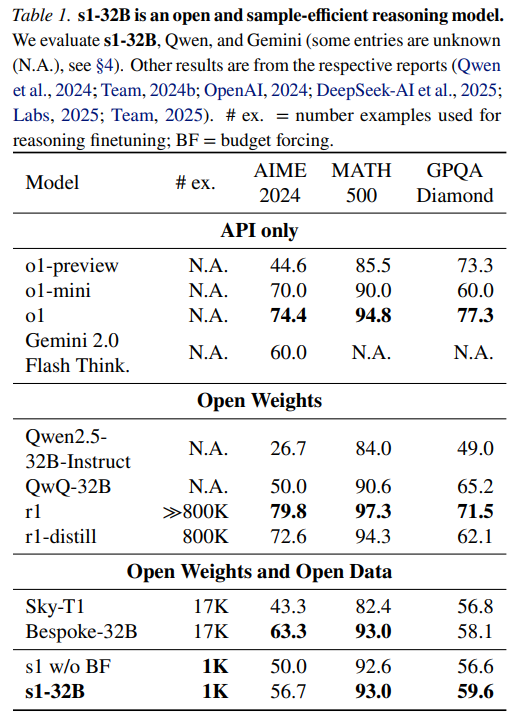
![]()
(s1-32B 跑分超越 o1-preview,但离 r1-distill 仍有差距)
更本质上的阐述是:DeepSeek 的发现侧重于训练时增强模型的推理能力,李飞飞团队的发现侧重于推理时控制模型的思考时间。
由此我大胆推断一下:
- 此方法针对更大的普通模型应该也有效,例如 DeepSeek-v3
- 更大的推理模型,也可以通过强制预算的方法来提高模型能力,例如 DeepSeek-r1
- 专业领域的推理小模型,训练会变得简单,「少量精选数据 + 强制预算」即可
- 大模型通过强化学习+推理越来越强,小模型通过蒸馏 + 推理越来越强
一些感想
论文关于「如何精选数据」「为什么没使用并行思考而是串行思考」等等,有着非常详细的讲解,而且都很有意思。但和主体关系不大,我就没在本文详细阐述,推荐有兴趣的话可以查看原论文(https://arxiv.org/pdf/2501.19393)。
如此有价值的论文,在媒体的包装下,给读者留下「哗众取宠」的感受和印象,不得不说是一种遗憾。
而我再经历了「鄙视->怀疑->求证->认可」这四个阶段后,再回头看这个标题:《李飞飞团队训练出媲美 DeepSeek R1 的推理模型,云计算费用不到 50 美元》
信息无可指摘,只是存在巨大的误导。但是,让人误以为「只需要 50 美元就可以复刻出 DeepSeek R1」,又怪不到作者头上。不懂的人觉得厉害,懂的人觉得在乱吹。在这种混乱下,一不小心,读者可能就错过了背后真正有价值的信息。
现在的 AI 早已不再只是科技行业内的话题,随着 DeepSeek 的爆火,AI 已经成为所有人的狂欢。但其实,AI是一个知识门槛很高、信息差巨大的行业,只有很少部分人才能看明白背后的本质。希望从业者可以更多地科普原理,带领普通人更加理性地看待 AI,而不是为了一时的流量走到真相的反面。
原论文:https://arxiv.org/pdf/2501.19393
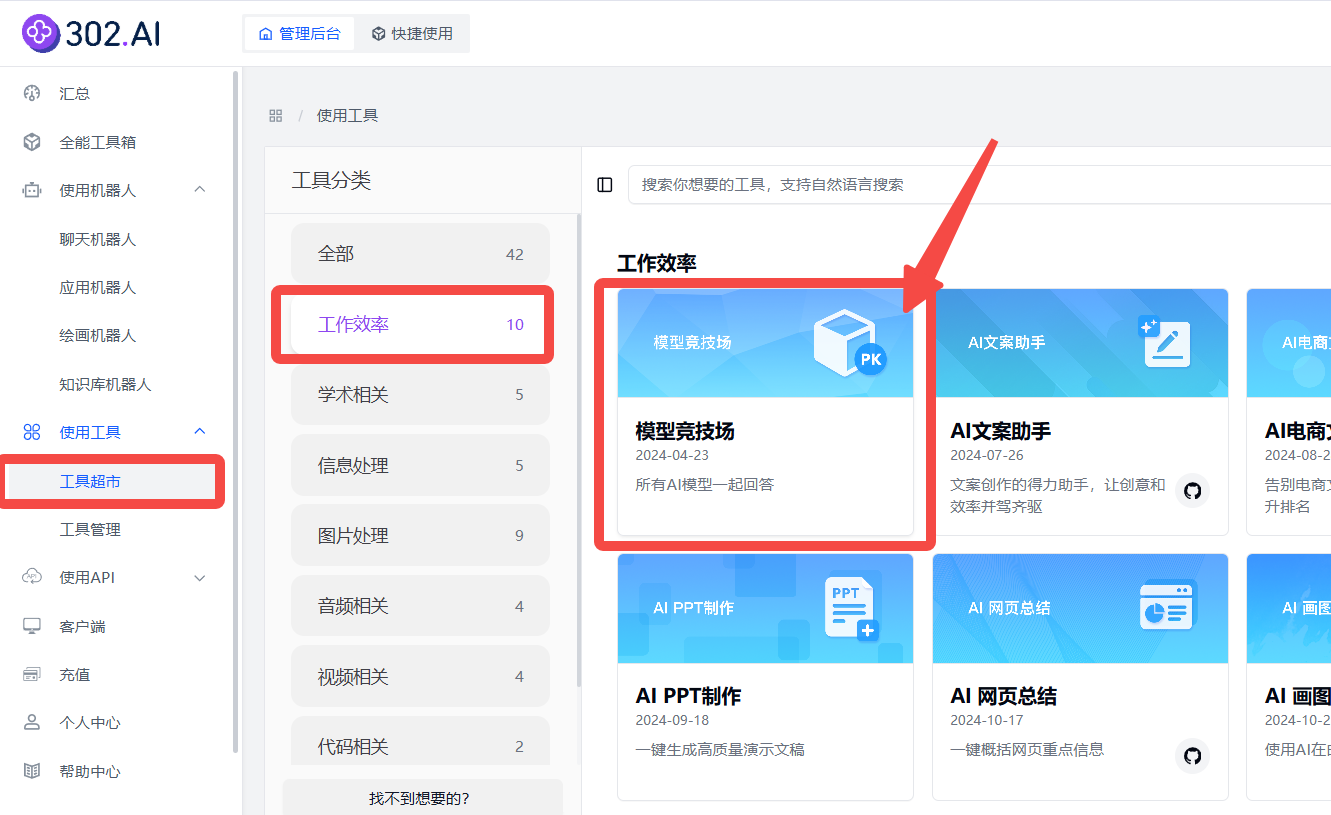
如何在 302.AI 快速对比不同模型的表现
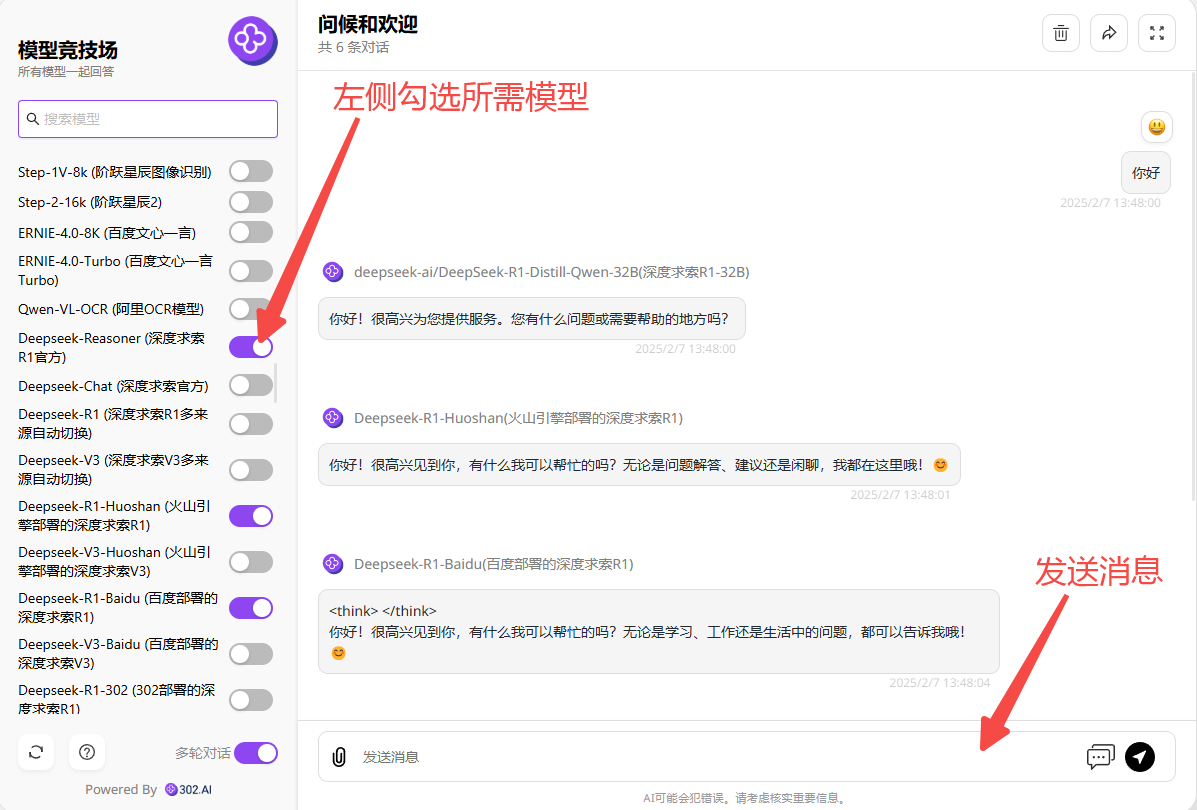
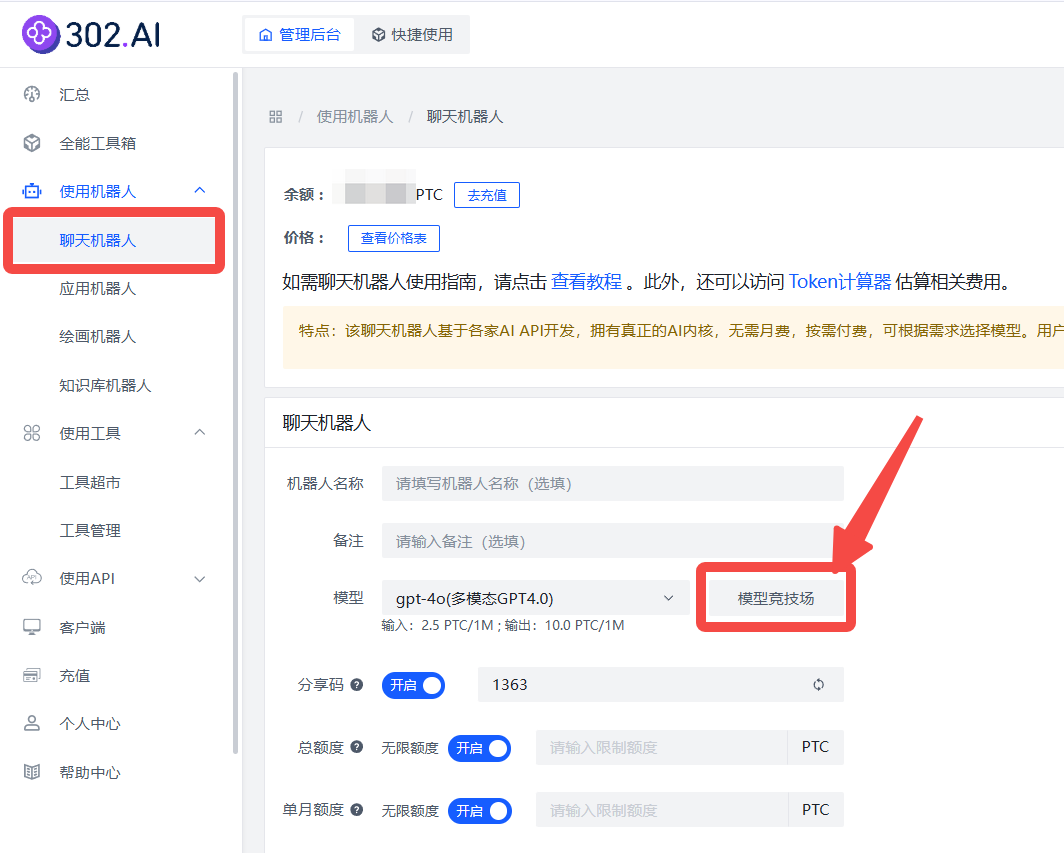
使用 302.AI 的模型竞技场能以直观且简洁的方式对比各模型的性能表现,且无需任何复杂的操作步骤。模型竞技场汇集了 302.AI 的所有模型,用户只需在左侧选择所需的模型并输入问题,即可同时获得所选模型的回答。
在302.AI中可通过多种方式进入模型竞技场,以下是常用的一些方式:
(1)可依次点击:使用工具→工具超市→工作效率→模型竞技场;
(2)也可点击使用机器人→聊天机器人,在聊天机器界面进入模型竞技场。
免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手

评论(11)
Woah! I’m really loving the template/theme of this blog. It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance” between superb usability and appearance. I must say you have done a fantastic job with this. In addition, the blog loads super quick for me on Safari. Exceptional Blog!
F*ckin’ remarkable issues here. I’m very satisfied to peer your article. Thank you a lot and i’m looking forward to contact you. Will you please drop me a mail?
It’s truly a great and useful piece of information. I’m satisfied that you simply shared this helpful info with us. Please stay us informed like this. Thanks for sharing.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
Howdy! I just would like to give an enormous thumbs up for the nice info you have here on this post. I will be coming back to your blog for more soon.
Good blog! I really love how it is easy on my eyes and the data are well written. I am wondering how I might be notified whenever a new post has been made. I have subscribed to your feed which must do the trick! Have a great day!
My brother recommended I may like this blog. He was once entirely right. This publish truly made my day. You cann’t believe just how so much time I had spent for this information! Thanks!
Wow! Thank you! I continually wanted to write on my site something like that. Can I implement a part of your post to my blog?
Hello there! Do you use Twitter? I’d like to follow you if that would be ok. I’m undoubtedly enjoying your blog and look forward to new updates.
Enjoyed looking at this, very good stuff, thanks. “All of our dreams can come true — if we have the courage to pursue them.” by Walt Disney.
You are a very intelligent person!