
12月3日,字节跳动豆包上线了一项新功能——图片理解。官方表示,这一功能可精准识别图片内容,并对相关问题进行解答,无论是查找景点位置,还是辨认动漫人物身份,都能轻松应对。
据了解,图片理解功能的底层技术来源于豆包视觉模型——Doubao-vision-pro-32k,Doubao-vision-pro-32k 是字节跳动豆包大模型视觉团队研发的多模态基础模型,专注于视觉理解和生成领域,适合处理复杂任务,支持32k上下文长度。
> 在302.AI上使用
想直接使用Doubao-vision-pro-32k模型,或者接入这一模型的用户,可以在302.AI上获得。目前,302.AI已经提供了Doubao-vision-pro-32k模型,用户可以通过聊天机器人或者API超市等获取使用,而且302.AI提供按需付费的使用方式,无需担心有月费和捆绑套餐,以下就是详细的获取步骤:
【聊天机器人】
进入302.AI,点击使用机器人——聊天机器人——选择模型——在国产模型分类中找到Doubao-vision-pro-32k。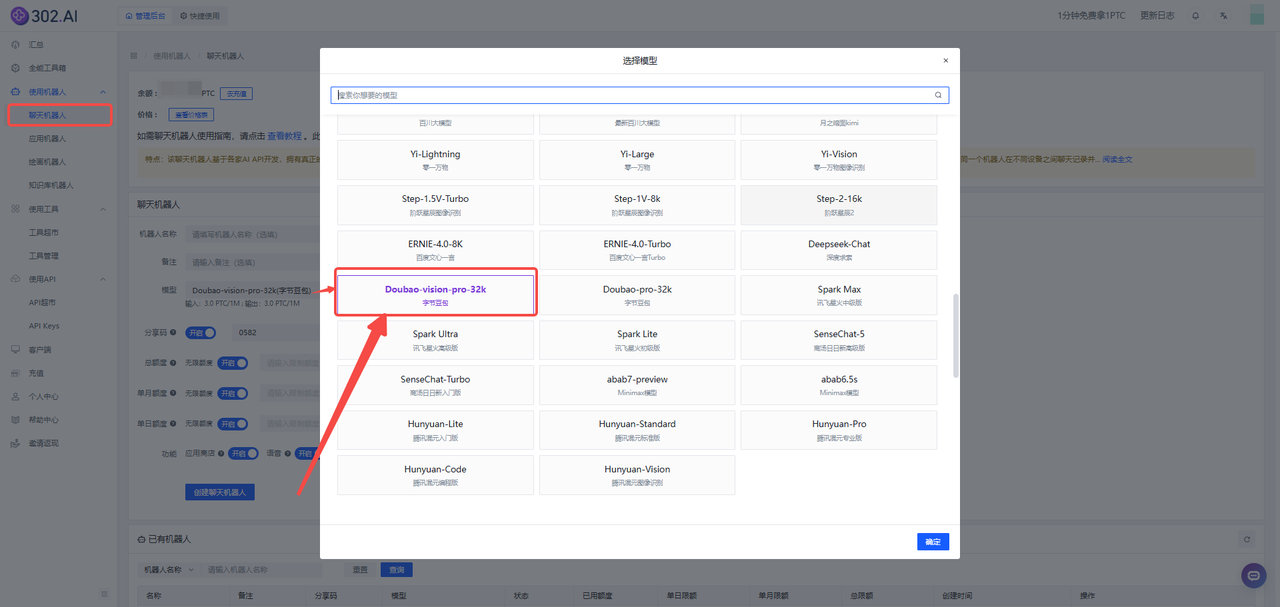

【API超市】
1、点击使用API——API超市——分类中选择语言大模型——点击国产模型。
2、下滑可以看到Doubao-vision-pro-32k的API已经在列表中,这里可以根据需求选择查看文档或者在线体验功能,查看文档可帮助用户快速接入模型API或者在线体验则可以更高效地对模型参数进行测试。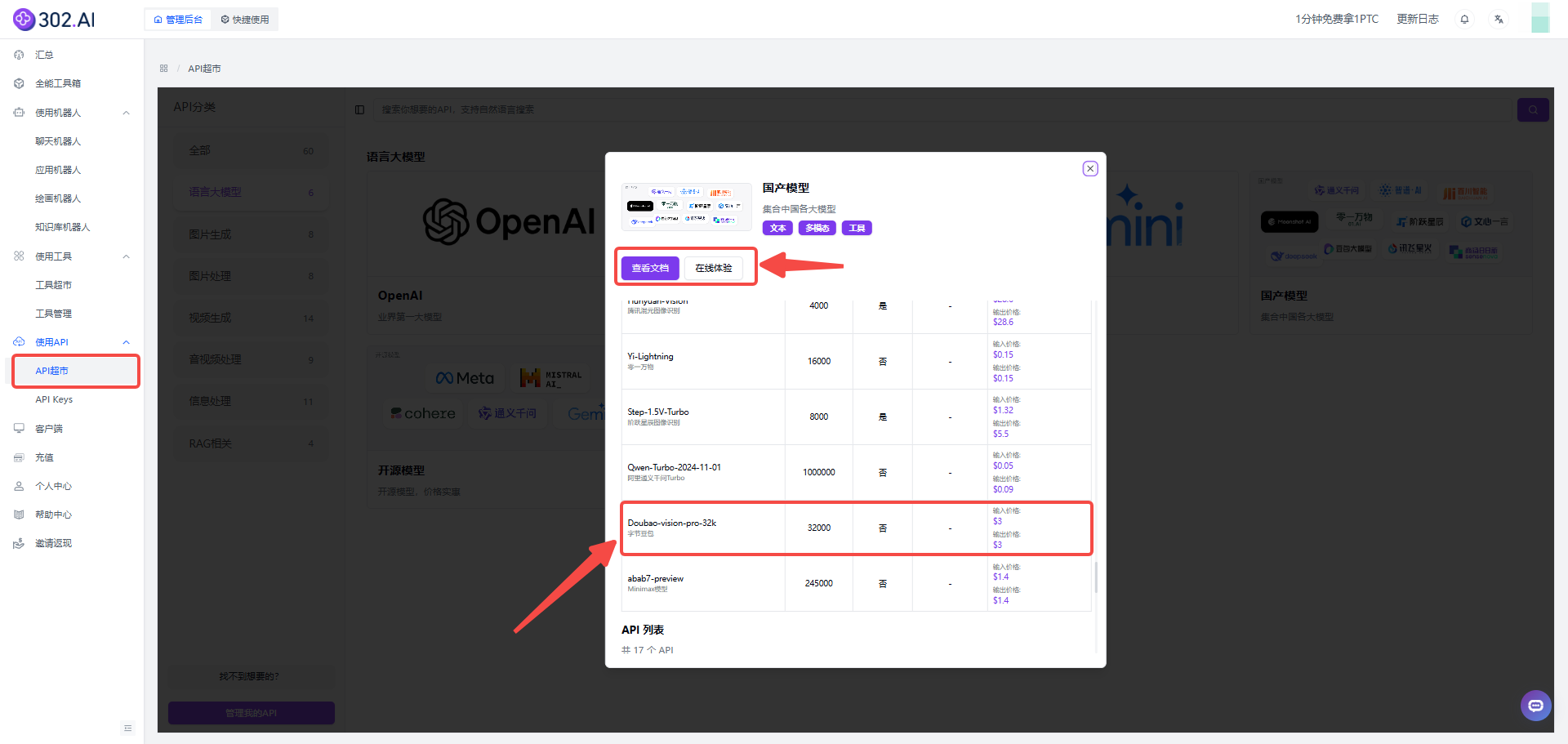
> 实测:
接下来会通过实测对比模型的表现如何,参与实测的模型有三个:Qwen-VL-Plus、GLM-4V-Plus、Doubao-vision-pro-32k,三个模型均是擅长图像理解的国产模型,且性能相近。
实测1:地点识别
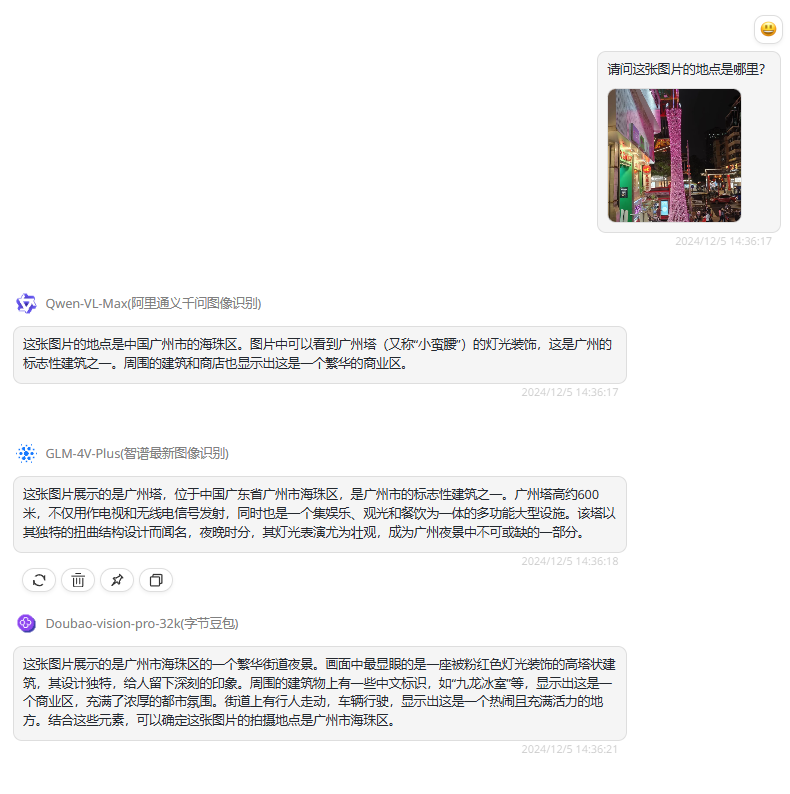
提示词:请问这张图片的地点是哪里?

分析:图片的正确位置为广州市海珠区江南西商业圈,而图片中的广州塔仅为缩小版的装饰。此前因外地游客到广州游玩曾误认为这是真正的广州塔,而在社交媒体平台引起广泛关注,江南西也因此被广大网友认识。
Qwen-VL-Plus:Qwen从周边的环境信息中得出位置是在广州市海珠区,这可以看出模型的基本识别能力没问题的,但是仅仅停留在看图说话的阶段,没有更深入的分析。
GLM-4V-Plus:GLM则直接把图片位置当作是广州塔,完全被误导了。
Doubao-vision-pro-32k:豆包整体回答和Qwen差不多,都只是把图片中能看到的信息描述出来,未能进一步识别这是江南西。
实测2:卡路里计算
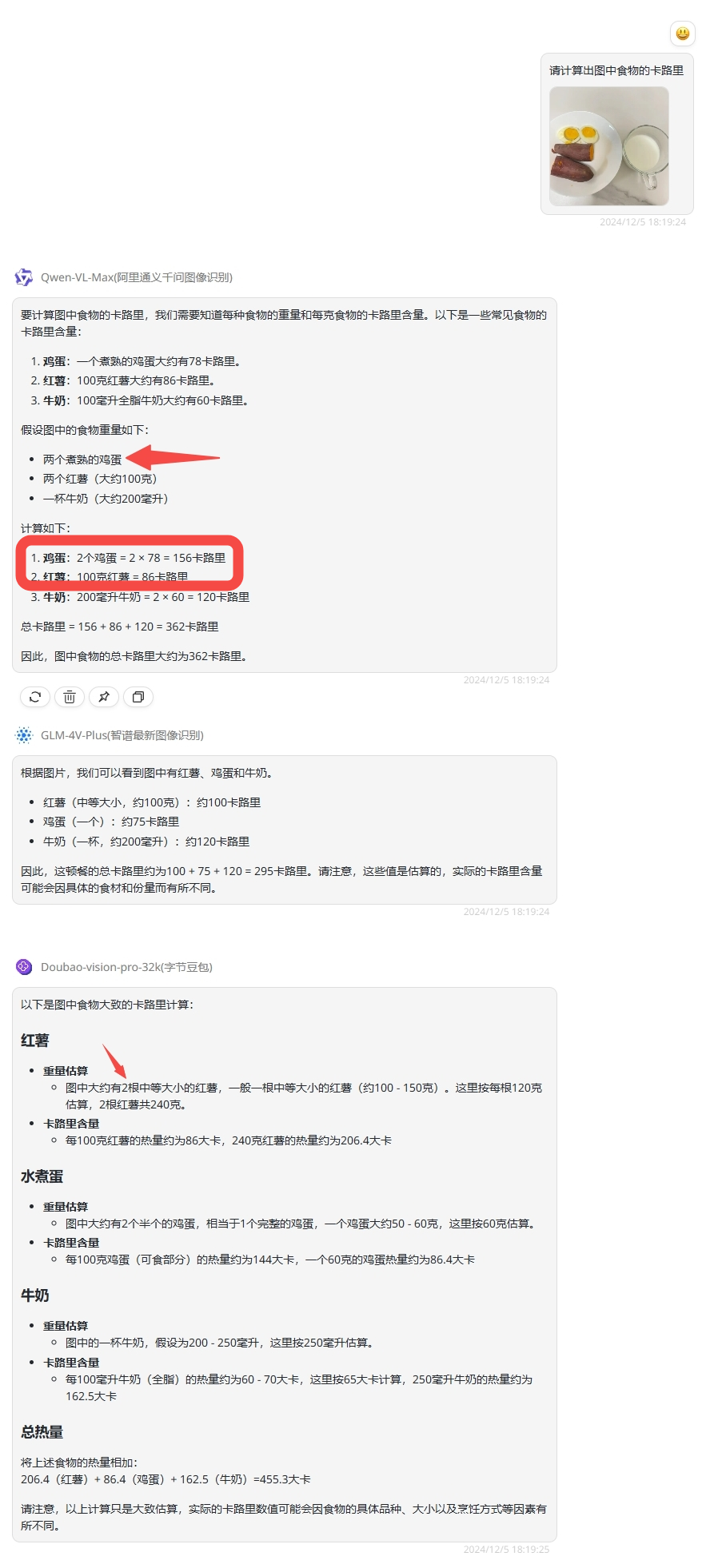
提示词:请计算出图中食物的卡路里

分析:图中为一个鸡蛋、一杯牛奶、和一根完整的红薯。
Qwen-VL-Plus:Qwen识别出为两个煮熟的鸡蛋和两根红薯,但是在卡路里计算过程中仅计算了一个红薯的卡路里,比较混乱,最终卡路里计算结果是不准确。
GLM-4V-Plus:物品识别数量是正确的,最终计算过程也没问题。
Doubao-vision-pro-32k:豆包也是识别出了有两根红薯,其实图片中只是完成的一根红薯掰成了两半,所以红薯数量是错误的,最终计算结果也是不准确的。
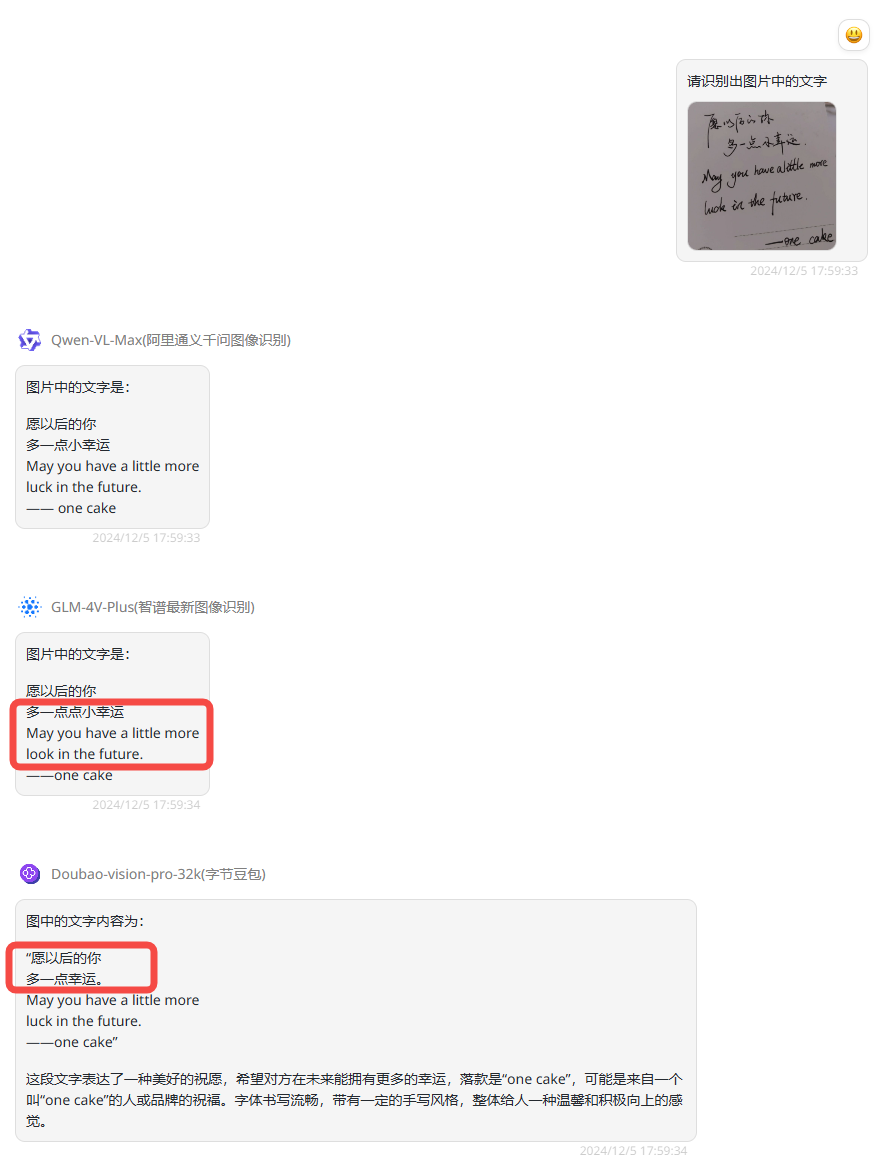
实测3:文字识别
提示词:请识别出图片中的文字

分析:
Qwen-VL-Plus:识别中文、英语都完全正确。
GLM-4V-Plus:GLM识别结果不够准确,中文多了“点”字,英语luck识别成“look”。
Doubao-vision-pro-32k:豆包英语识别没问题,但是中文少字,少了个“小”字。
实测4:梗图理解
提示词:请问这个图片是什么意思?
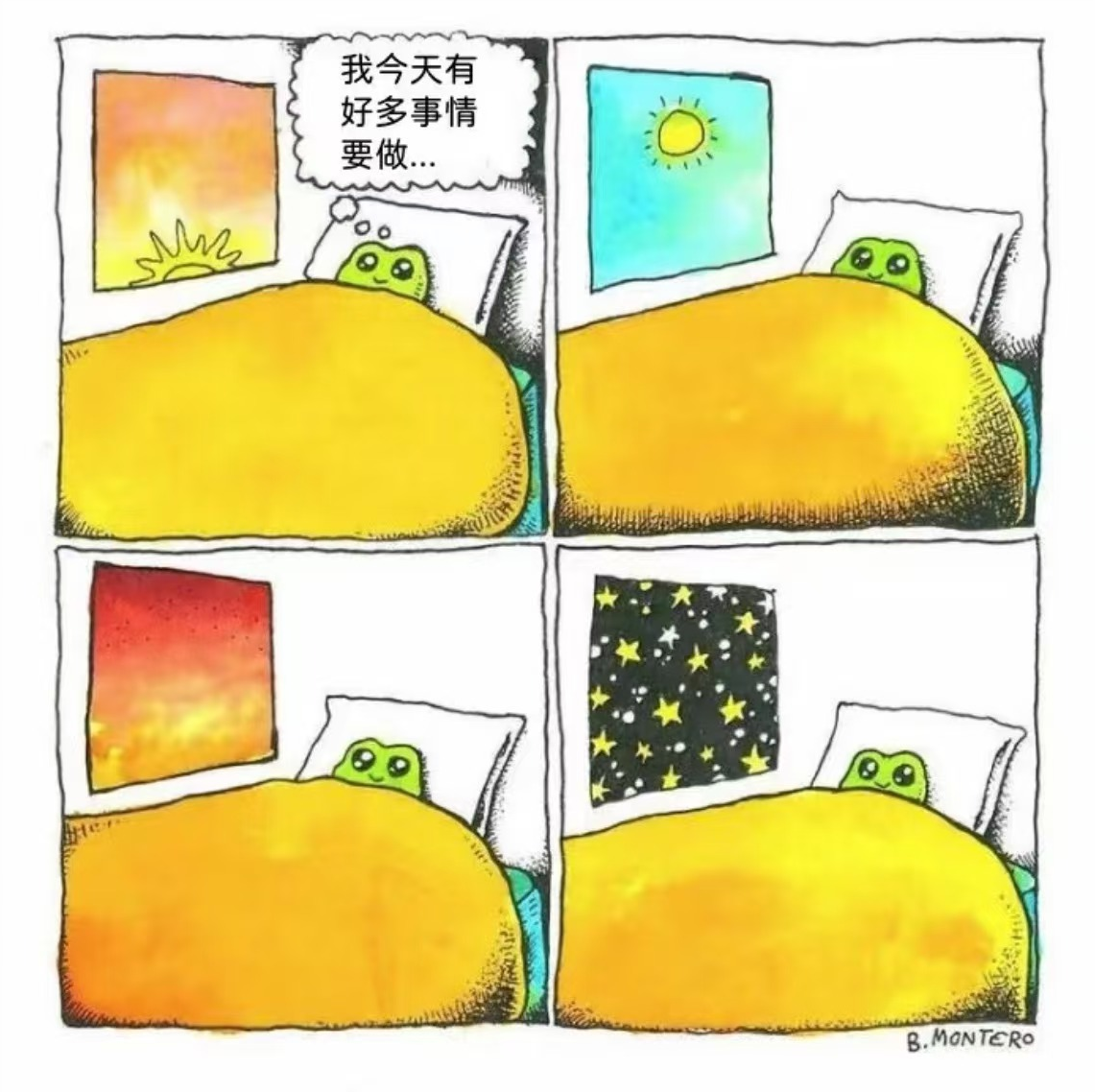
分析:这是一道四宫格梗图理解,展示的是人们在生活中存在的拖延现象:
Qwen-VL-Plus:先是描绘了图片的场景,再阐述自己的理解,回答是正确的。
GLM-4V-Plus:GLM在回答最后指出“这个漫画是对拖延症和累的一种轻松表达”,其实漫画并没有展示出累的方面,所以整个理解不够准确的。
Doubao-vision-pro-32k:豆包先是对四格漫画逐一分析,再指出深层含义,可以说整个回答非常有条理,也非常清晰完整的。

实测5:图表理解
提示词:广州在2017年的人口是多少?
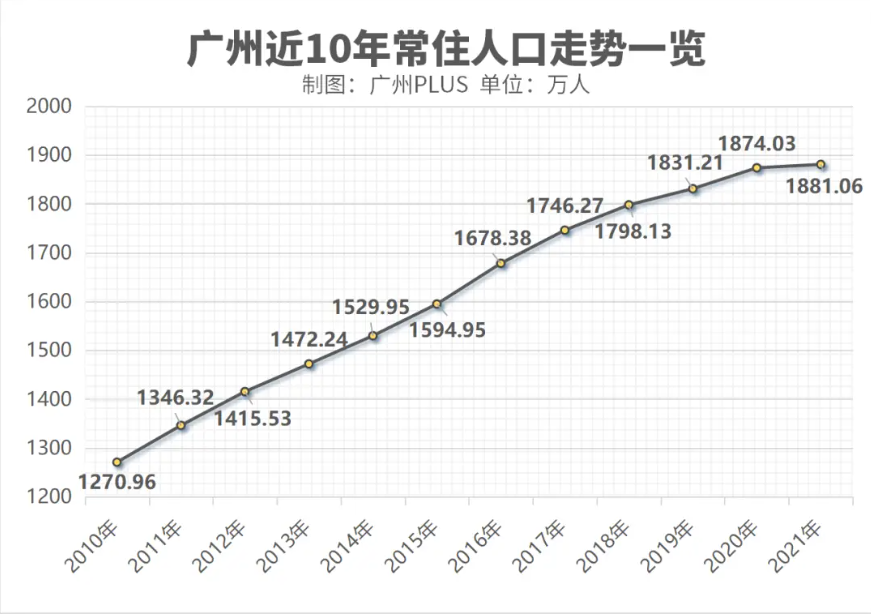
分析:从图中可以看到2017年常住人口是1746.27万人。
Qwen-VL-Plus:回答错误,回看整个图表,并没有出现过1490.44万人这个数值,这表明是出现了模型幻觉。
GLM-4V-Plus:是三个模型中唯一回答正确的。
Doubao-vision-pro-32k:回答错误,同样出现了模型幻觉。

> 总结:
通过以上五轮实测,可以初步得出以下结论:
地点识别测试:三个模型中,Doubao-vision-pro-32k虽然未能完全正确答出地点,但其在回答时能够对图片中的细节进行描述,展示了一定的理解能力。
卡路里计算测试:Doubao-vision-pro-32k的物品数量识别不够灵活,不如GLM-4V-Plus。
文字识别测试:文字识别测试上,Doubao-vision-pro-32k还有小细节需要注意,会出现遗漏字的情况。
梗图理解测试:三个模型中,Doubao-vision-pro-32k在梗图理解方面尤为突出,其对四宫格漫画的分析不仅逻辑清晰,还能深刻揭示出图像所传达的深层含义。
图表理解测试:这一轮测试中,Doubao-vision-pro-32k和Qwen-VL-Plus都出现了模型幻觉的问题,回答了图片中没有出现过的数值。
总的来看,三个国产模型的图片理解能力各有所长,没有完全的胜者。多模态模型的图片理解能力在一定程度上受限于训练数据的质量与多样性,根据实测结果来看,或许模型未来的优化方向可以集中在增强模型对特定领域知识的理解,比如电影、文化和地理等与大众生活更贴切的方面。