2月19日,马斯克旗下的大模型平台 xAI 推出了新的模型——Grok-3。官方宣称,Grok-3 在推理、数学、编码和指令遵循任务中均表现出色,并在一系列基准测试中表现出色。而马斯克更是称一模型为 ⌈ 地表最强 ⌋。
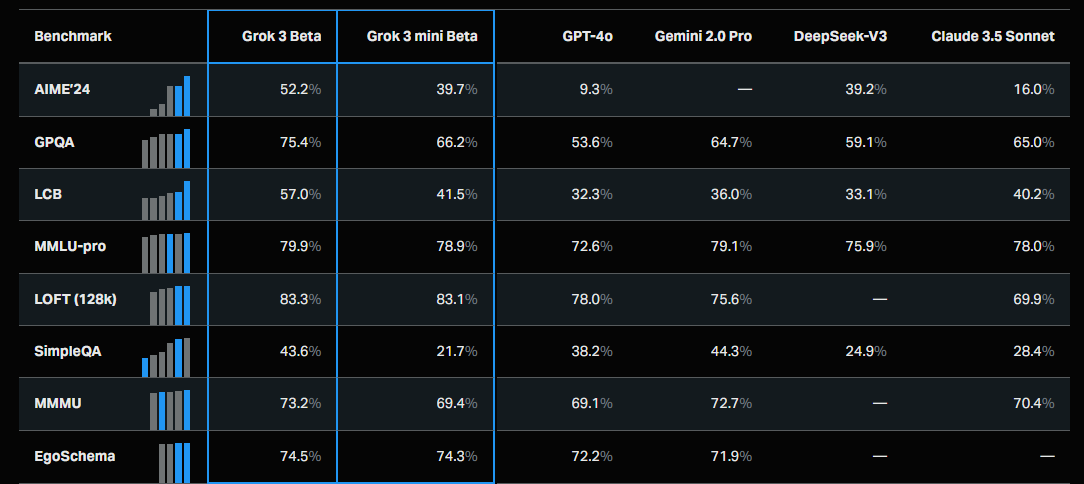

(非推理模式的Grok-3与其它大模型能力对比)
根据了解,grok-3 并非单一模型,而是一个包含多个版本的模型家族。其中包括了变体版本—— grok-3-reasoner(推理版)。这一个版本能够像 OpenAI 的 o3-mini 和 DeepSeek 的 R1 等推理模型一样,仔细思考问题,并在给出结果前进行彻底的事实核查,从而避免了一些通常会困扰模型的错误。
除了推理版本外,grok-3 还引入了一项名为【DeepSearch】的新功能。xAI将其描述为一种新型搜索引擎,能够扫描互联网和X平台上的信息,并以摘要的形式回应用户查询。
关于grok-3系列模型的详细介绍可查看官方文档:https://x.ai/blog/grok-3
grok-3系列模型对比:
为了更好理解三个版本的差异,我们会使用同一问题进行测试,并通过对输出结果对比分析具体的不同之处。
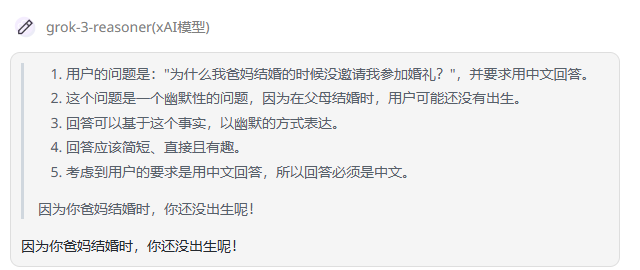
提示词:为什么我爸妈结婚的时候没邀请我参加婚礼?用中文回答
grok-3常规版本:常规版直接给出答案,看不到推理过程。
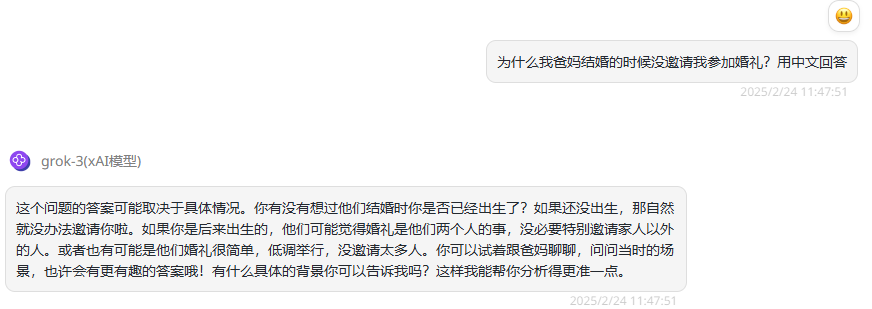
grok-3-reasoner(推理版本):推理版会展示了思考链路,再输出答案。
grok-3 -deepSearch(搜索版):这一版本会通过检索网络信息输出结构化报告,与前面的版本都不同,这更加适合市场调研等领域应用。

模型实测:
根据上述比较,我们将深入测试推理版本grok-3-reasoner,并通过与同类型模型o3-mini(medium)和DeepSeek-R1进行对比,更直观地观察这三个模型的表现:
以下实测使用的是相同的提示词,且摘取模型第一次输出的结果。
实测1和实测2使用的工具为:302.AI的模型竞技场
实测3使用工具为:302.AI聊天机器人-Artifacts功能
实测1:弱智吧题目
提示词:生蚝煮熟了叫什么?
考察点:看似简单的名称辨析,其实是测试模型对语言逻辑、科学常识的综合理解能力。
o3-mini :分析错误,回答错误。
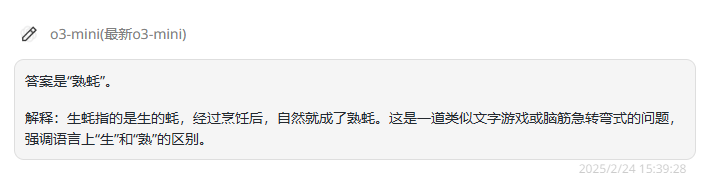
DeepSeek-R1:回答正确,解析清晰且合理。
grok-3-reasoner :仔细观察模型的答案,可以发现模型实际上知道正确答案,但为了增加趣味性,最后给出了“熟蚝”这个答案。

第1轮实测结果:DeepSeek-R1 >grok-3-reasoner>o3-mini
实测2:计算推理测试
提示词:请在错误的等式中添加一对括号:1+2×3+4×5+6×7+8×9=479,以使等式成立
考察点:测试模型的数学计算、逻辑推理、问题解决能力以及对数学符号的理解。
o3-mini:给出了验算步骤,最后回答正确。

DeepSeek-R1:回答错误,结合思维链来看,模型已经意识到答案与原始答案不一致,但很可惜仍未提供正确答案。

grok-3-reasoner:未能输出答案,模型持续思考并反复测试可能的答案,在输出长达一分钟后不得不手动暂停。通过思考过程可以观察到,在测试答案时,模型添加的括号数量超过一个,这已经与题目的原意不相符了。

第2轮实测结果: o3-mini > DeepSeek-R1> grok-3-reasoner
实测3:编程测试
提示词:用前端代码制作一个碰撞小游戏:小球在弹跳,一侧放置了方块,小球碰到方块则得分,方块全部消失即通关,界面需要包含开始游戏按钮、游戏说明。所有代码放在一起输出。
o3-mini:界面设计一般,小球弹跳较流畅,得分正常实时变化,但缺乏交互,用户无法通过任何方式对游戏进行操作。
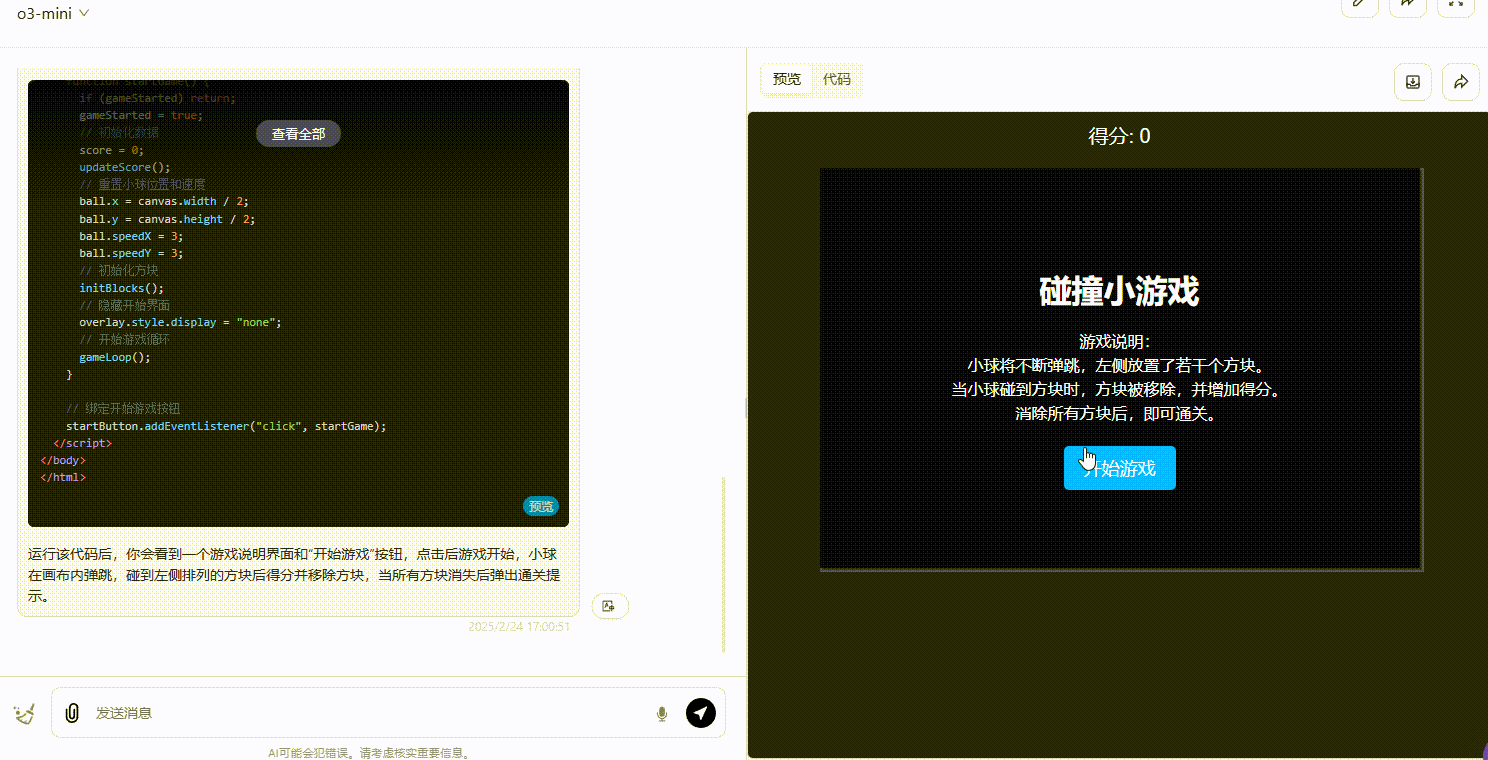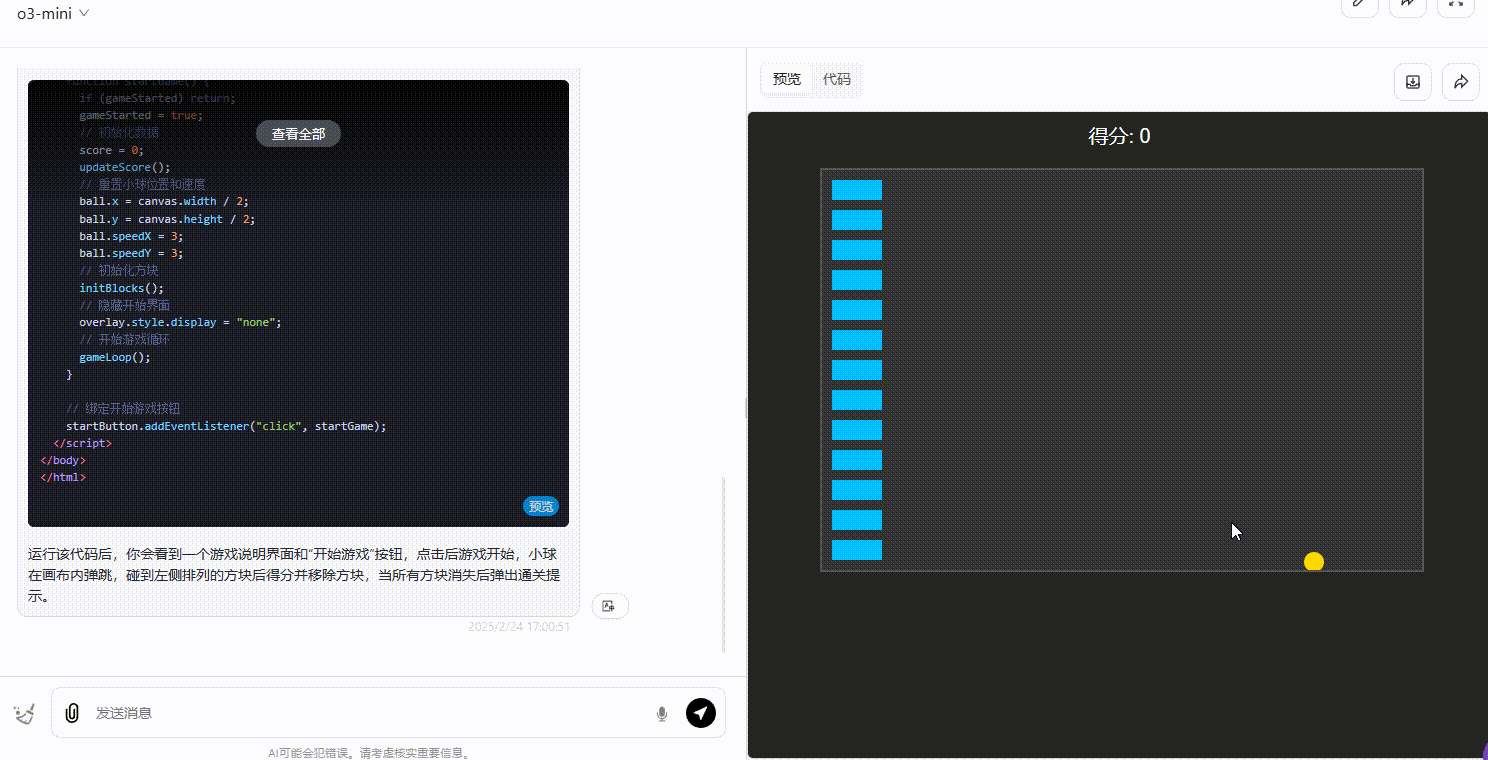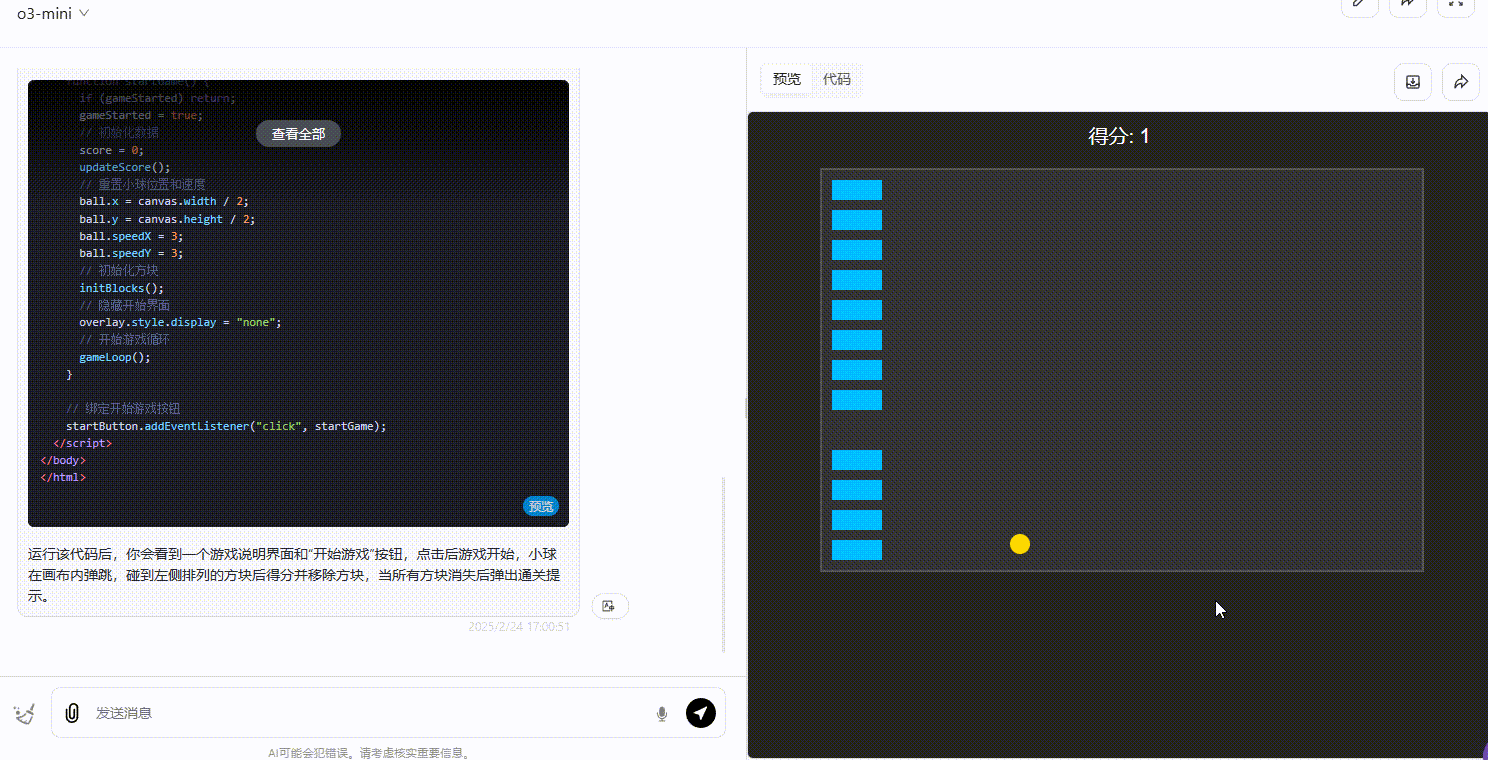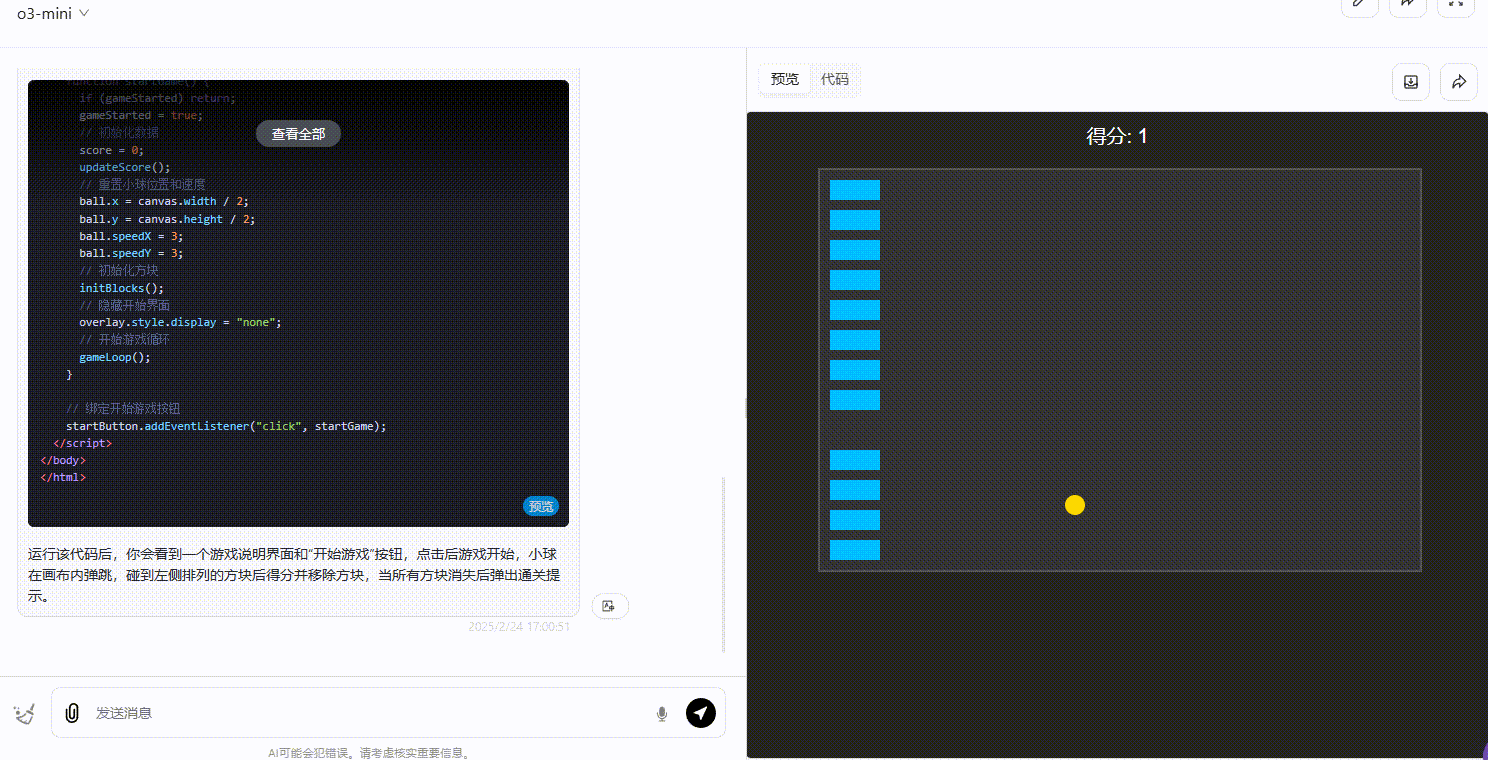
DeepSeek-R1:界面设计在三个模型中最好,小球弹跳正常,得分显示正常,且用户能通过键盘操作游戏,整体表现上明显优于其他两个模型。
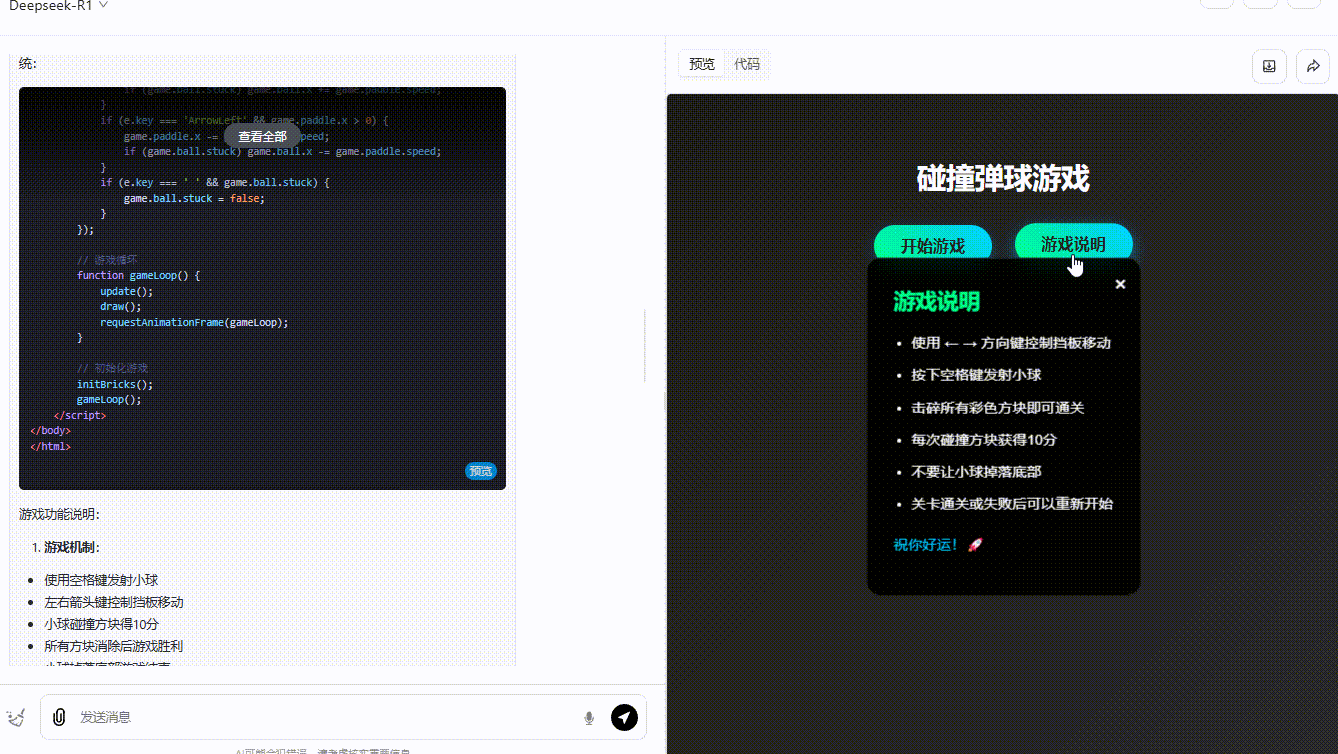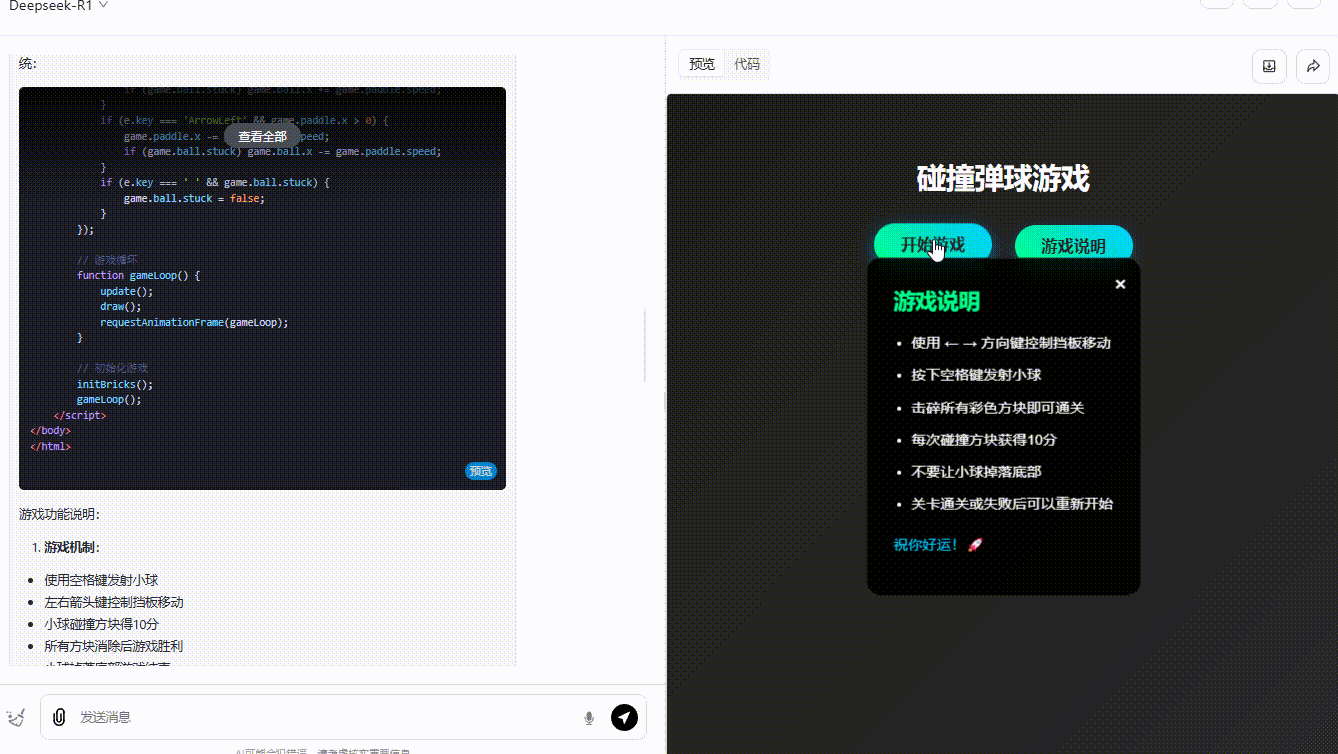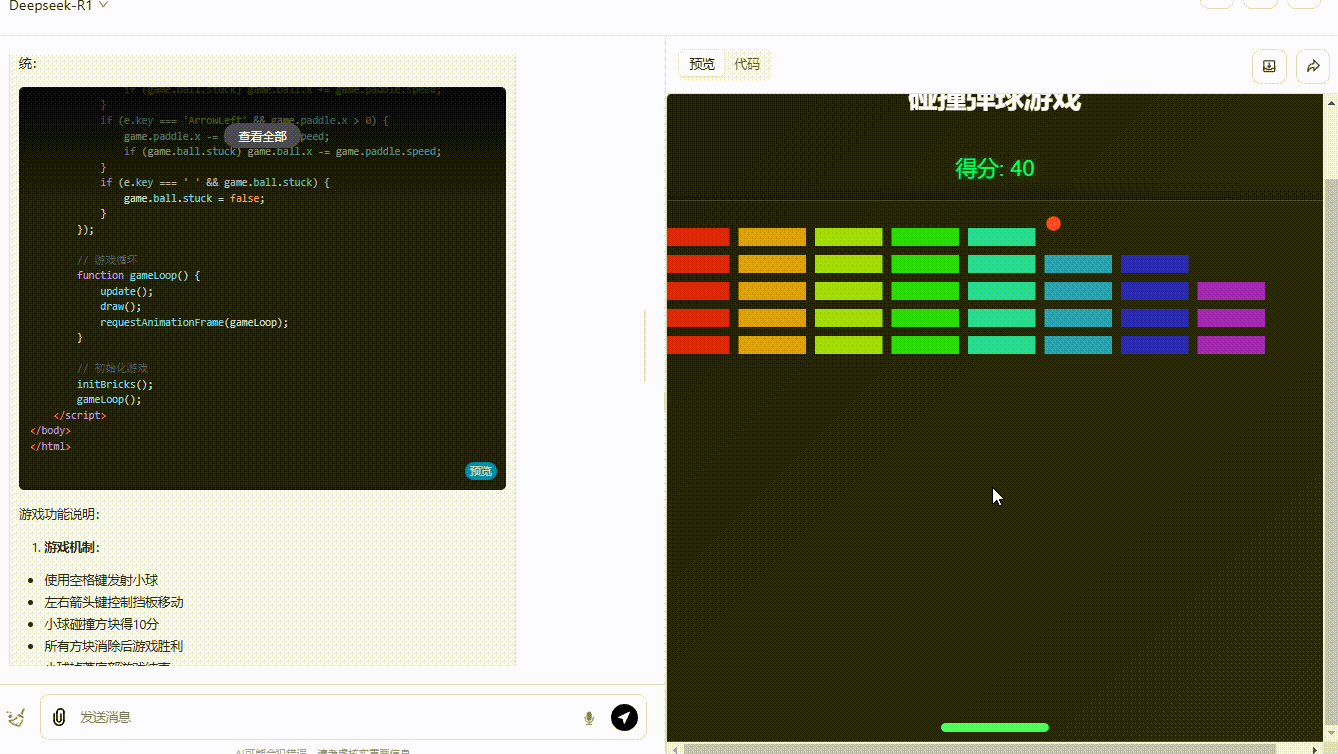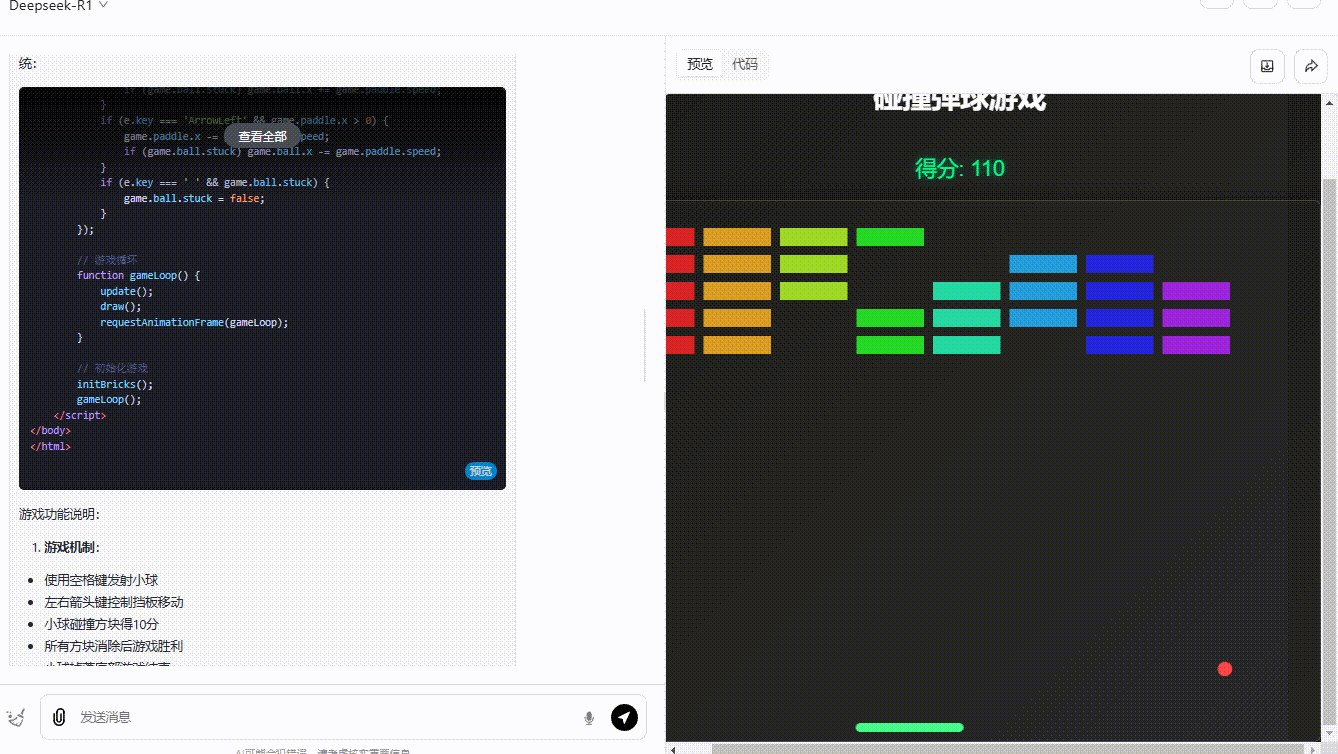
grok-3-reasoner :界面设计中规中矩,功能实现基本符合预期,得分系统能够实时更新显示,小球的弹跳也还算流畅自然。然而,缺乏足够的互动性,玩家无法对游戏进行操作。
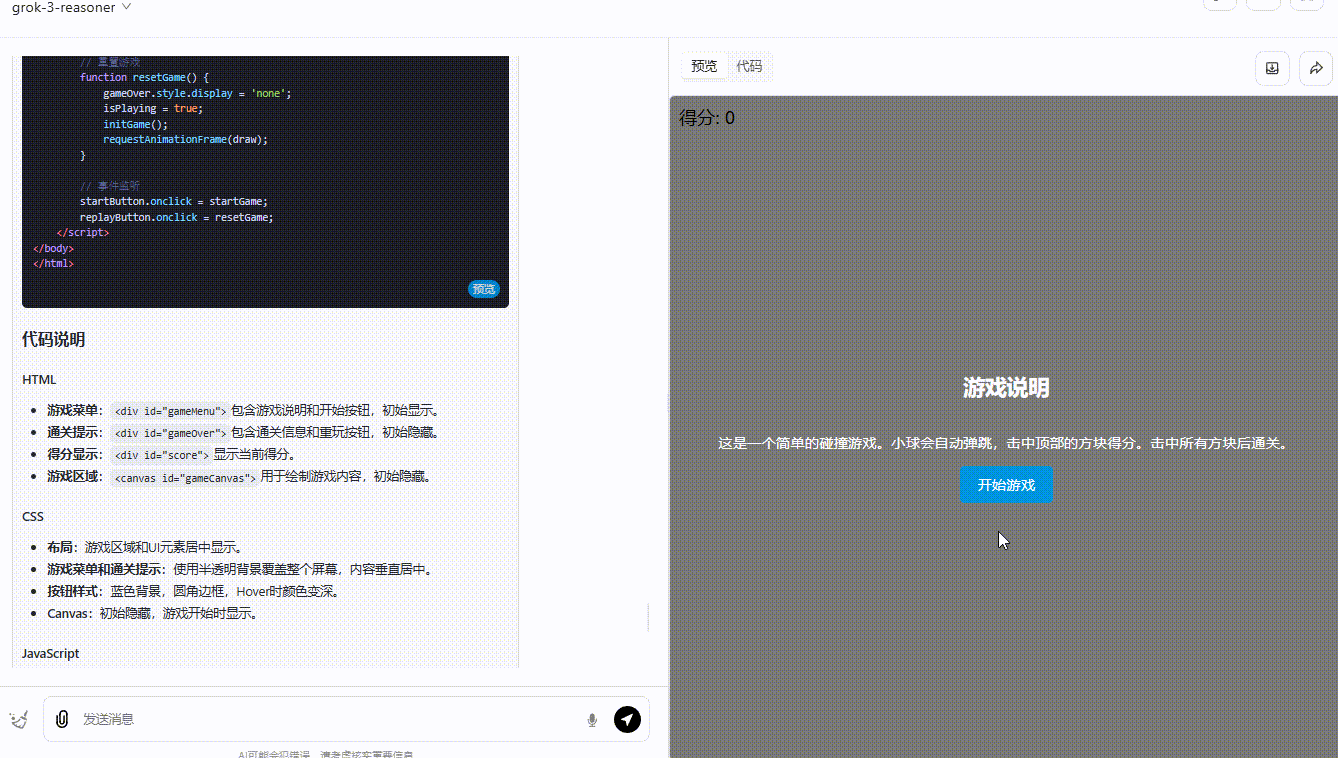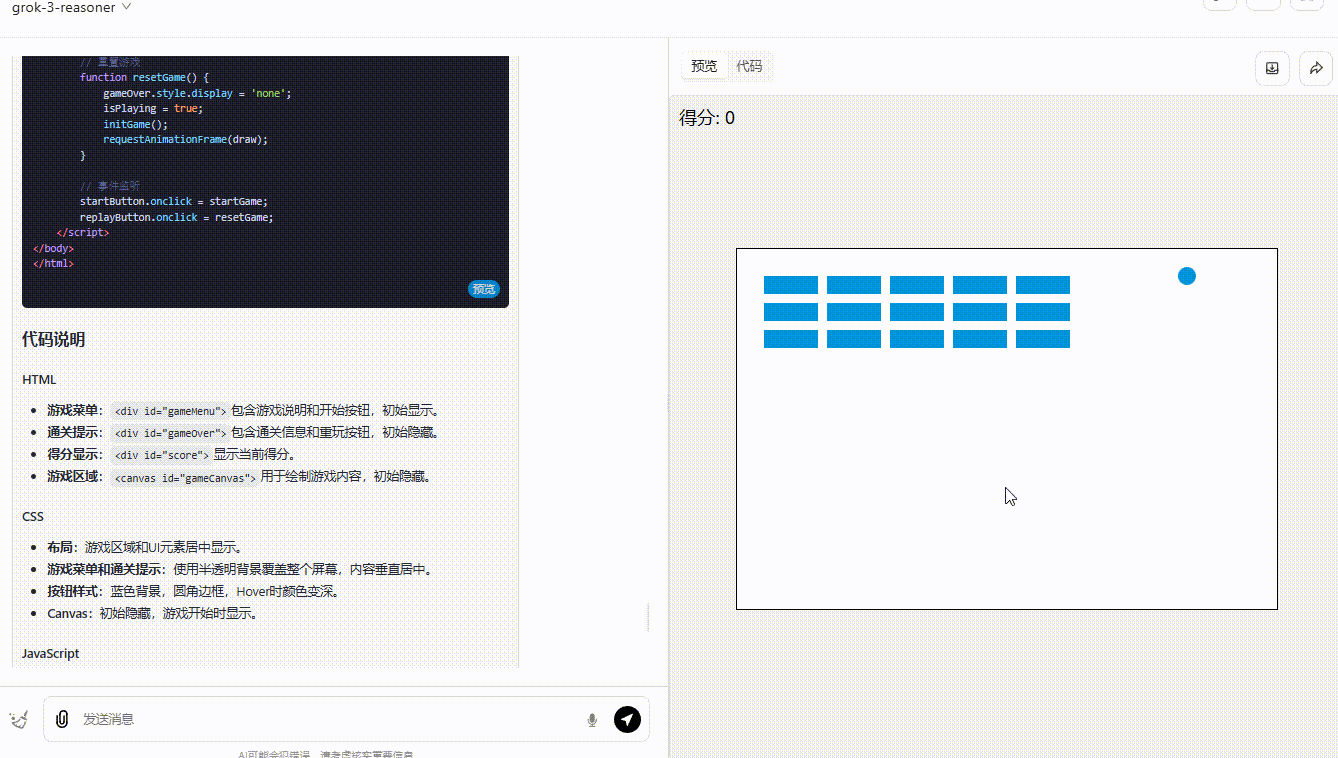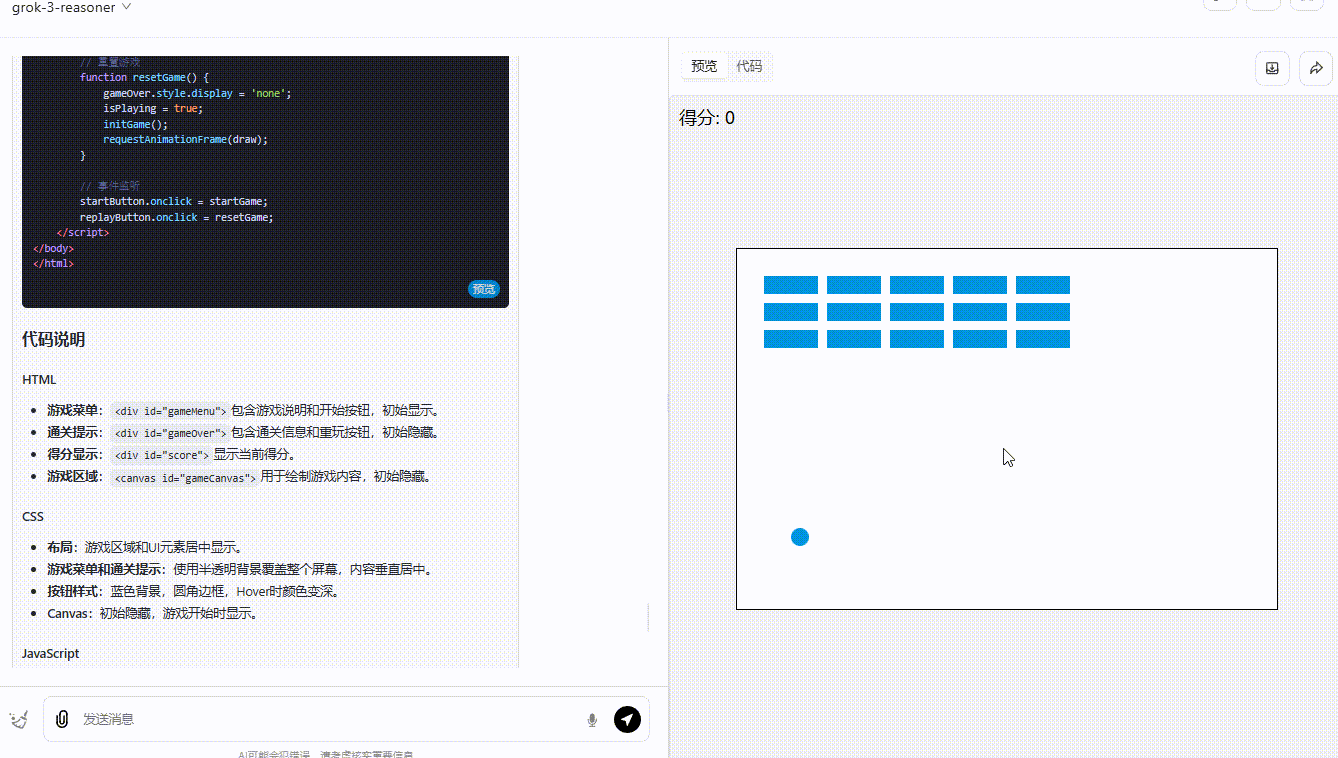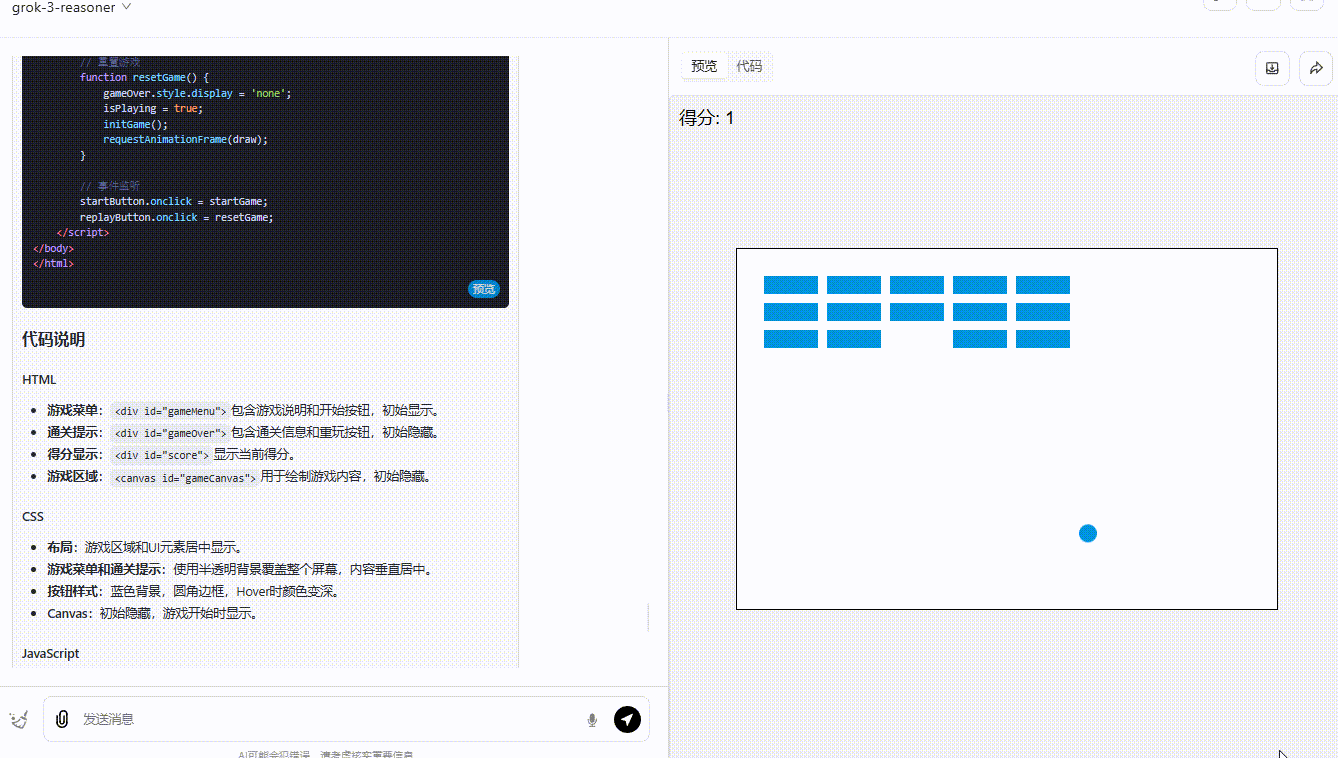
第3轮实测结果:DeepSeek-R1 >grok-3-reasoner=o3-mini
实测结果总结:
通过以上三个简单的对比实测,能够初步得出以下结论:
(1)在弱智吧题目测试中的表现排名:DeepSeek-R1 > grok-3-reasoner>o3-mini
智吧题目测试中,grok-3 实际上知道正确答案,但为了增加趣味性,它选择了输出一个错误的答案,这种做法让测试过程变得更加有趣。
(2)在计算推理方面表现排名:o3-mini > DeepSeek-R1> grok-3-reasoner
在进行计算推理任务的过程中,多次尝试提问 grok-3,但遗憾的是始终未能输出最后答案。这表明当前的模型在处理此类任务时仍存在一些不足之处。
(3)在编程方面表现依次排名:DeepSeek-R1 >grok-3-reasoner=o3-mini
在编程任务中,grok-3 界面设计和功能实现相对中规中矩,与 o3-mini 表现相似,与 DeepSeek-R1 相比,在用户交互体验上略显不足。
总之,在以上的实测中,grok-3的表现并不太亮眼。尽管官方宣传grok-3的评分很高,但对于大多数普通用户来说,评分只是一个次要参考,最重要的是要选出一个合适、顺手的模型使用。最后,希望今天的实测能够为大家在选择模型时提供有效的参考。
在302.AI上使用grok-3系列模型
302.AI的聊天机器人和API超市均上线了 grok-3系列模型,并提供按需付费的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
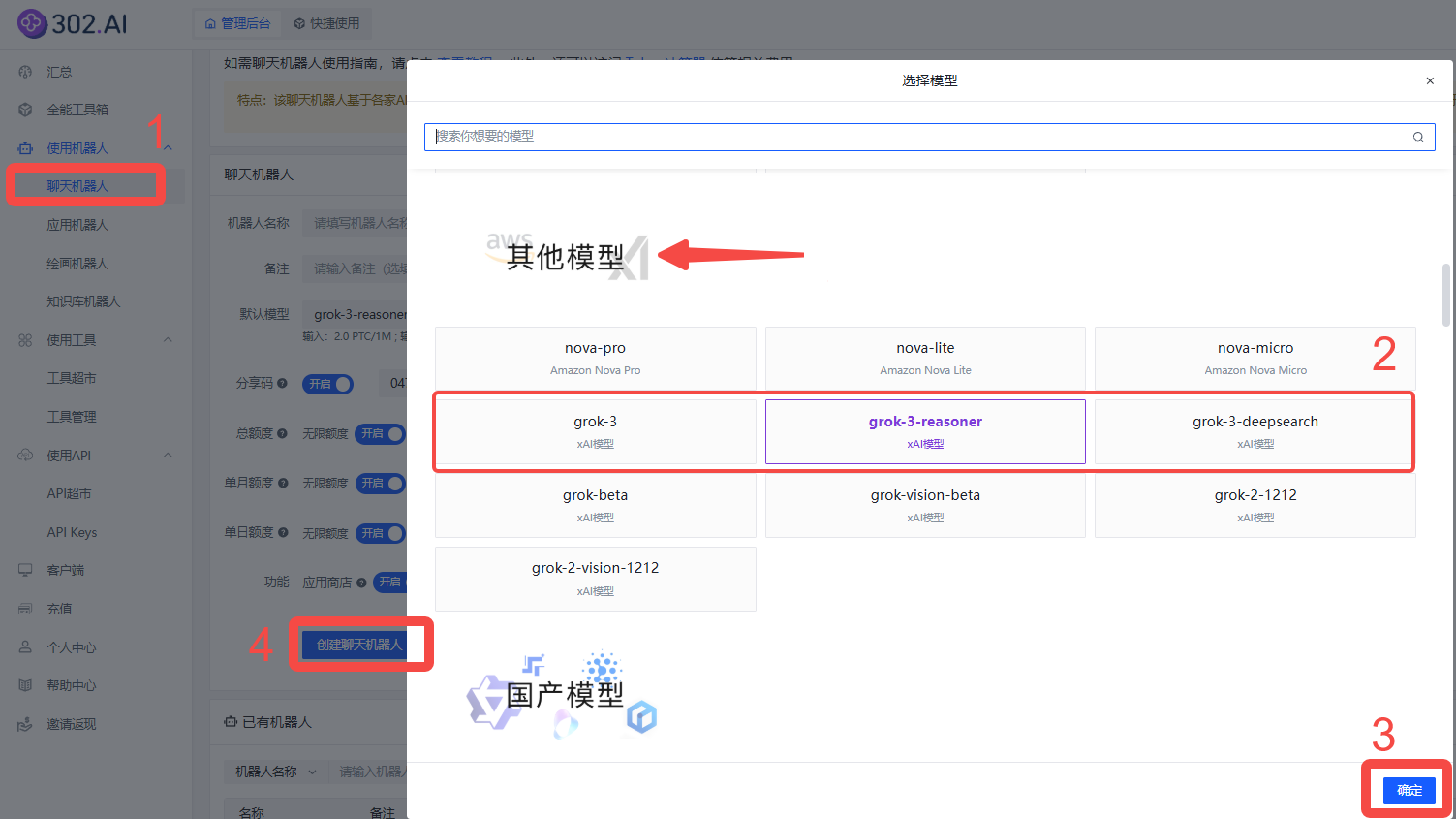
依次点击使用机器人→聊天机器人→ 模型→其他模型→grok-3系列→ 创建聊天机器人;
2、使用模型API
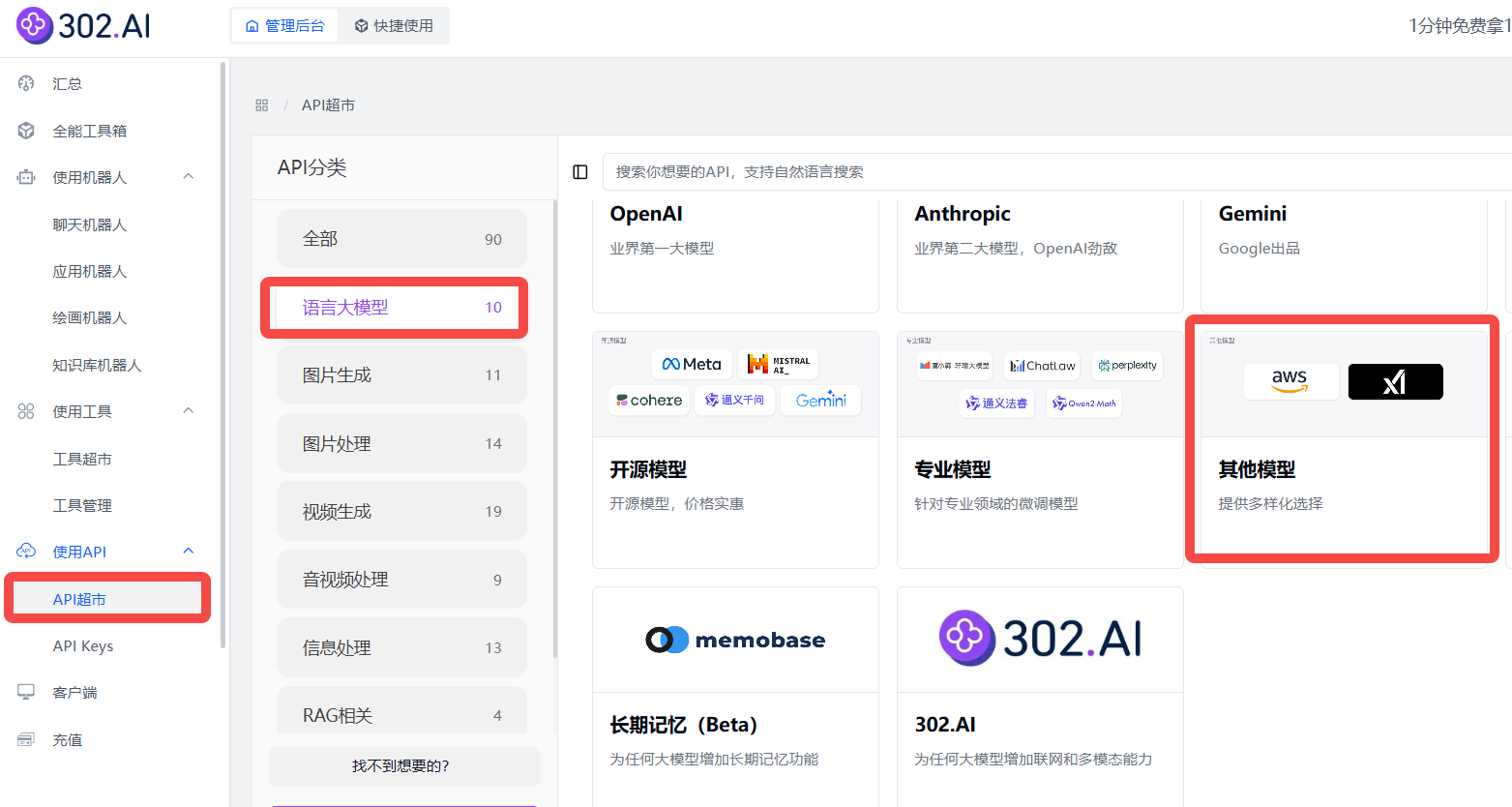
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→其他模型→查看文档;
API名称如下:
grok-3(常规版本)
grok-3-reasoner (推理版本)
grok-3-deepsearch(搜索功能版)