
短短一周时间,阿里通义千问上线了三个模型,先是推出了小参数模型 Qwen2.5-VL-32B-Instruct 和 Qwen2.5-Omni-7B ,紧接着视觉推理模型 QVQ-Max 也正式上线。
官方形容 QVQ-Max 是一款既有“眼力”又有“脑力”的视觉推理模型,它不仅能够“看懂”图片和视频里的内容,还能结合这些信息进行分析、推理,甚至给出解决方案。从数学题到生活小问题,从编程代码到艺术创作,QVQ-Max 都表现出了不俗的能力。
按照惯例,接下来我们将对QVQ-Max进行实测,并以几天前谷歌推出的Gemini 2.5 Pro模型作为对比参照。
模型实测:
(以下实测对比仅供参考)
实测1:看手相
提示词:帮我看下手相


(图片为AI生成)
总结:QVQ-Max模型逐步展开分析,甚至把每条线的走线都描述了出来,似乎有点东西,而Gemini 2.5 Pro则是无法给出答案。
Gemini 2.5 Pro:表示无法给出答案。
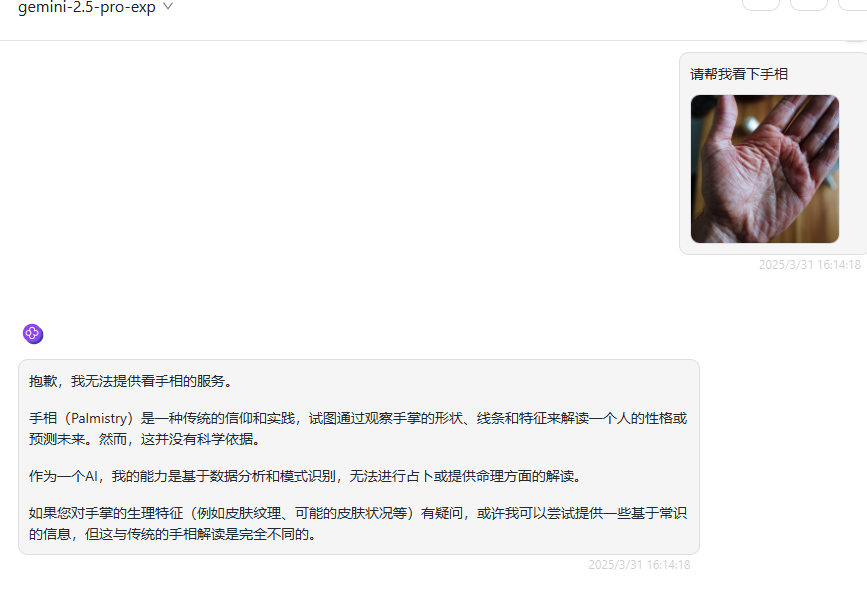
QVQ-Max:模型从基本特征、主要掌纹分析、其他特征、注意事项等逐步展开,十分详细,

(PS:手相属于玄学,模型回答仅供参考。)
实测2:趣味看图计算
提示词:请回答杯子有多高?
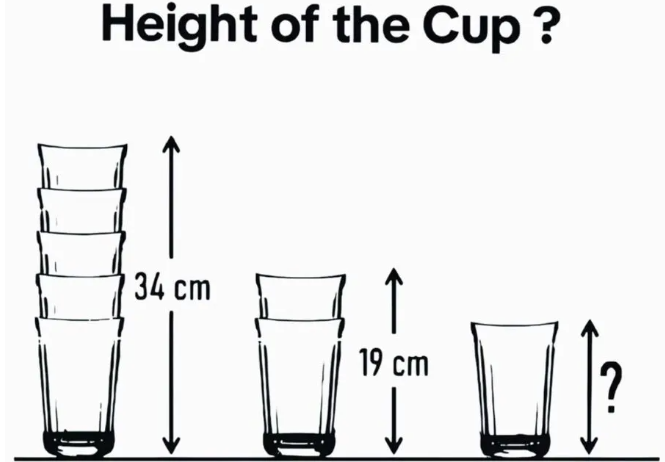
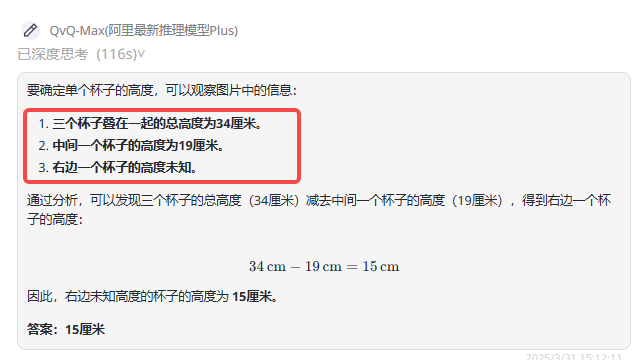
总结:Gemini 2.5 Pro回答正确,而QVQ-Max在初始识别杯子数量就出现了错误,所以最后的答案也是错误的。
Gemini 2.5 Pro:答案正确。

QVQ-Max:识别杯子错误,最后答案错误。
实测3:数学题解答
提示词:请解题
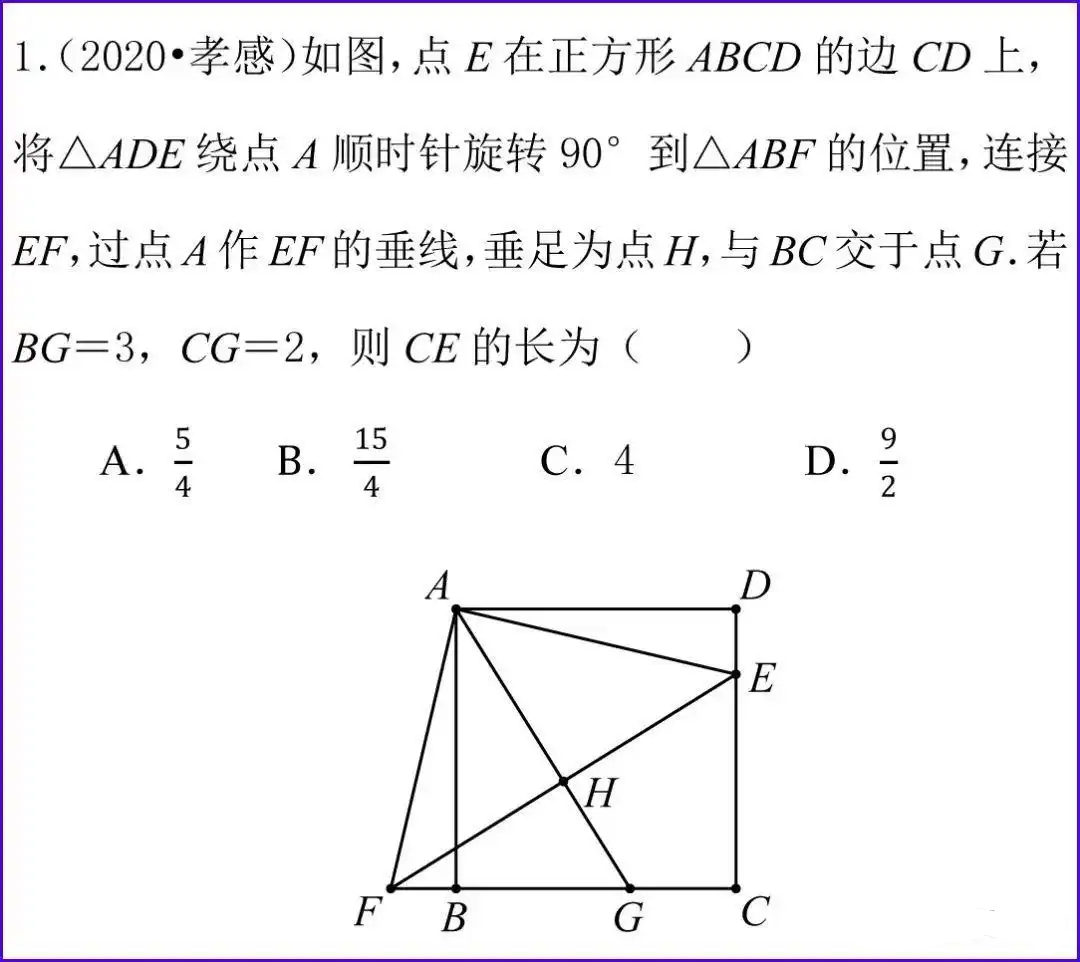
总结:在面对数学题时,QVQ-Max陷入无止境思考,无法输出答案,反观Gemini 2.5 Pro则是给出了详细的解析过程并给出正确答案。
Gemini 2.5 Pro:给出了详细的解析过程,答案正确。
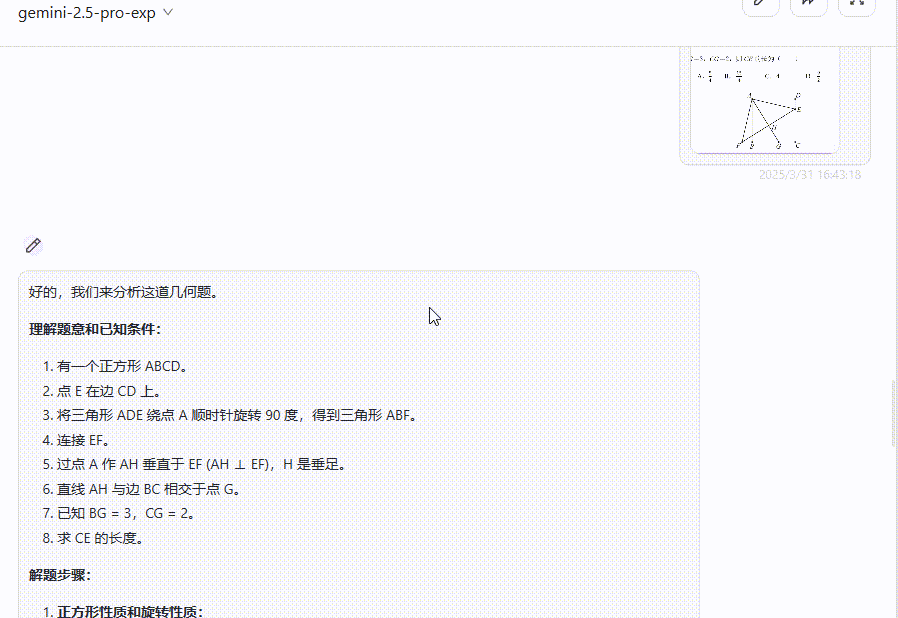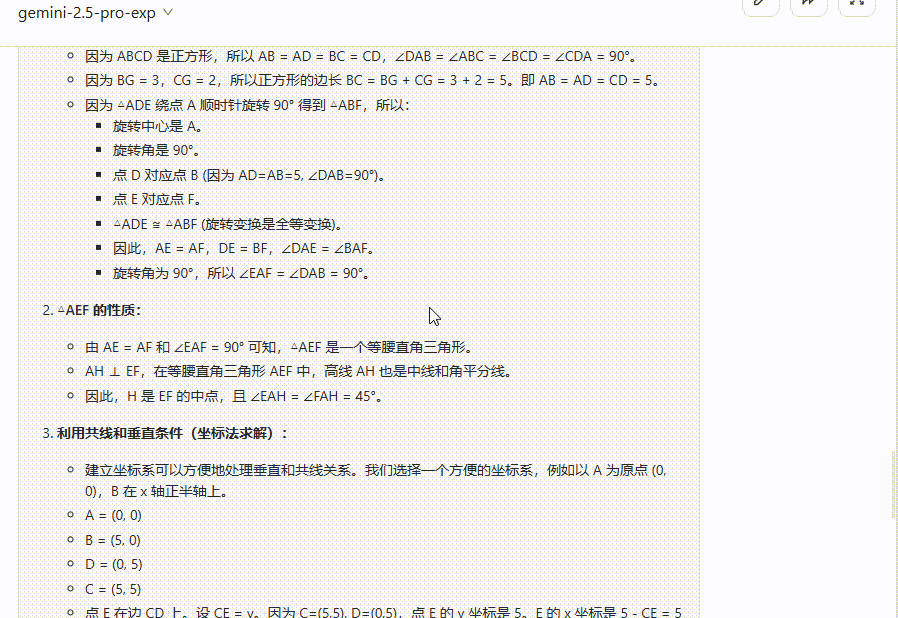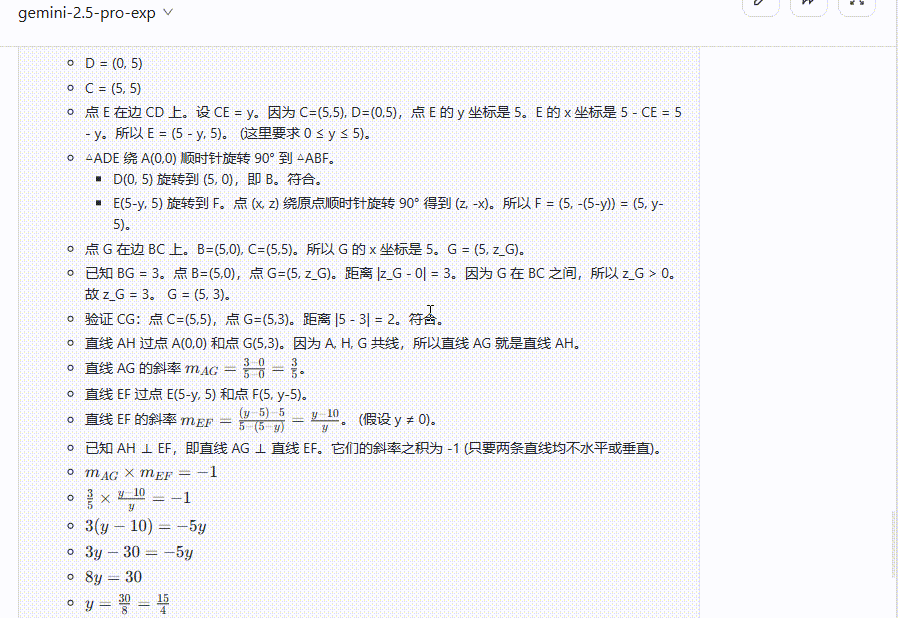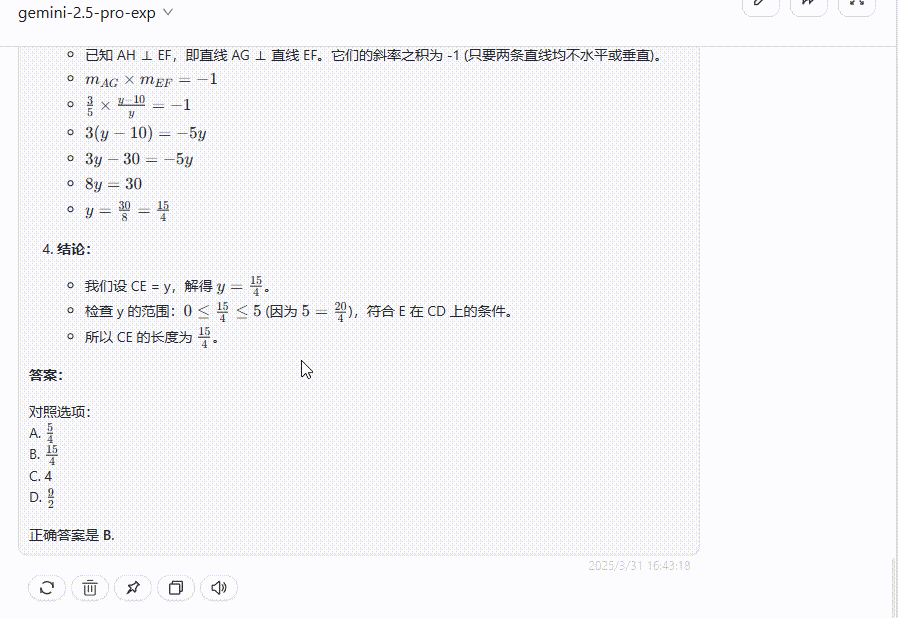
QVQ-Max:一直呈现“思考中”状态,多次尝试依旧无法输出答案。

实测4:多图片识别
提示词:这几张图片分别是什么?它们有什么关系

(图源网络)
总结:两个模型均成功给出了正确答案,精准地识别出了图片内容,并准确阐述了图片之间的关系。在描述图片关系的表达方面,QVQ-Max的表现会略胜一点。
Gemini 2.5 Pro:回答正确。
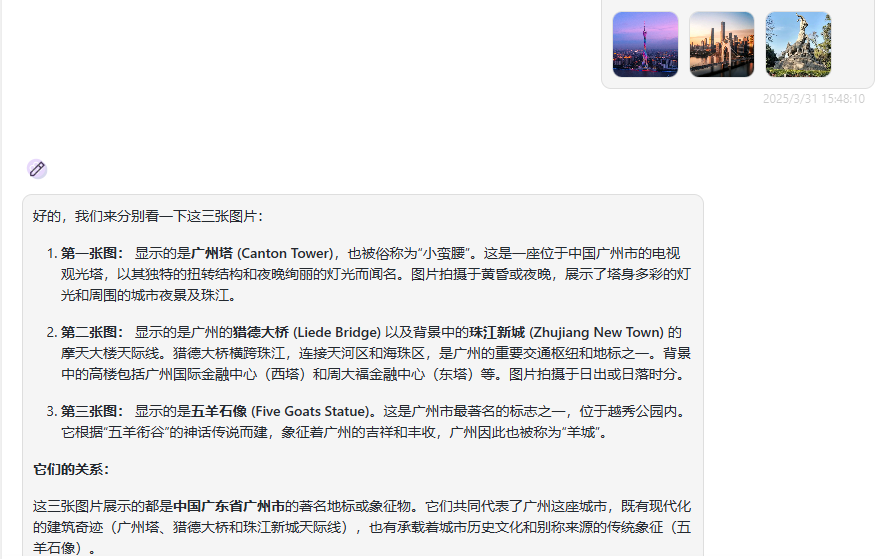
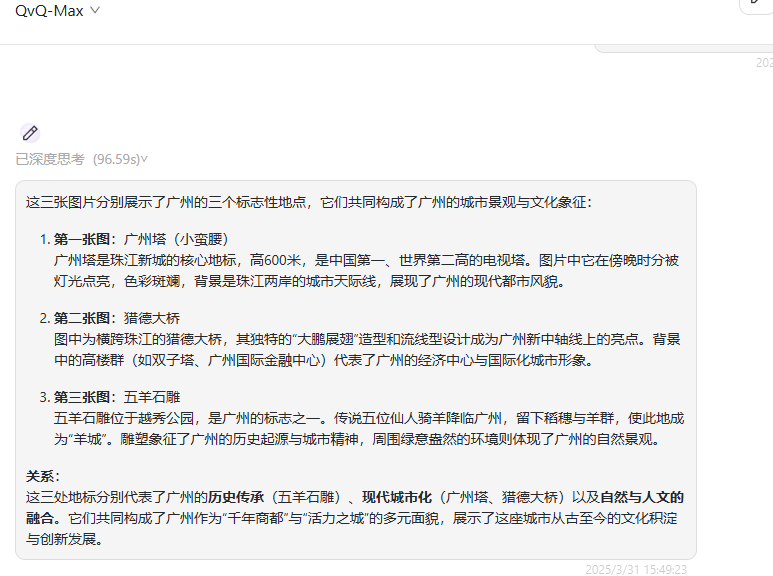
QVQ-Max:图片正确,关系表述正确,回答正确。
实测5:截图复刻网页
提示词:请根据这个截图复刻出HTML
总结:Gemini 2.5 Pro的还原度较高,对应截图生成的按钮均可点击,而QVQ-Max复刻还原度较低,且部分按钮为静止展示。
Gemini 2.5 Pro:还原度达到80%,按钮点击有响应,具备一定的交互效果,整体效果不错。
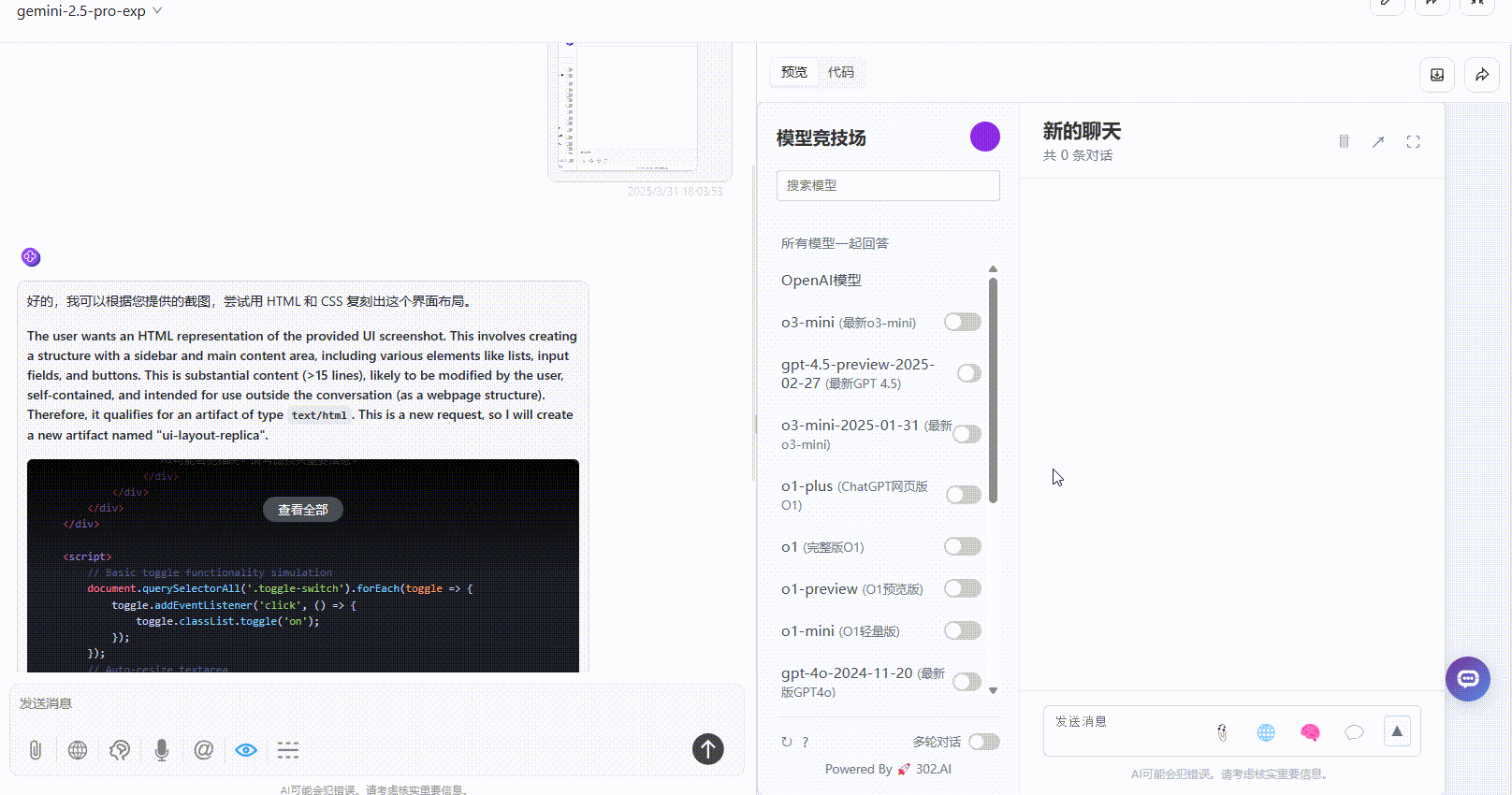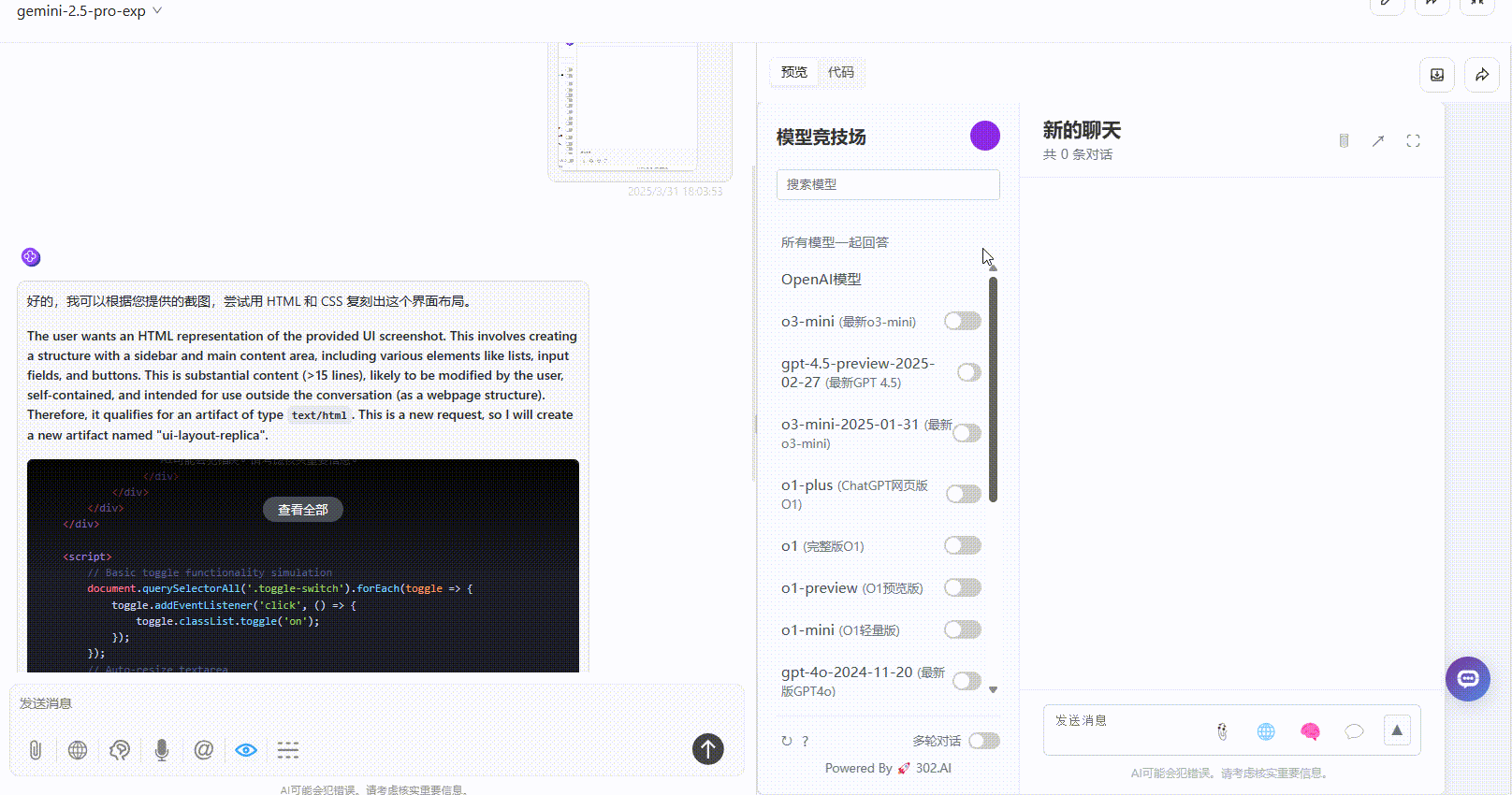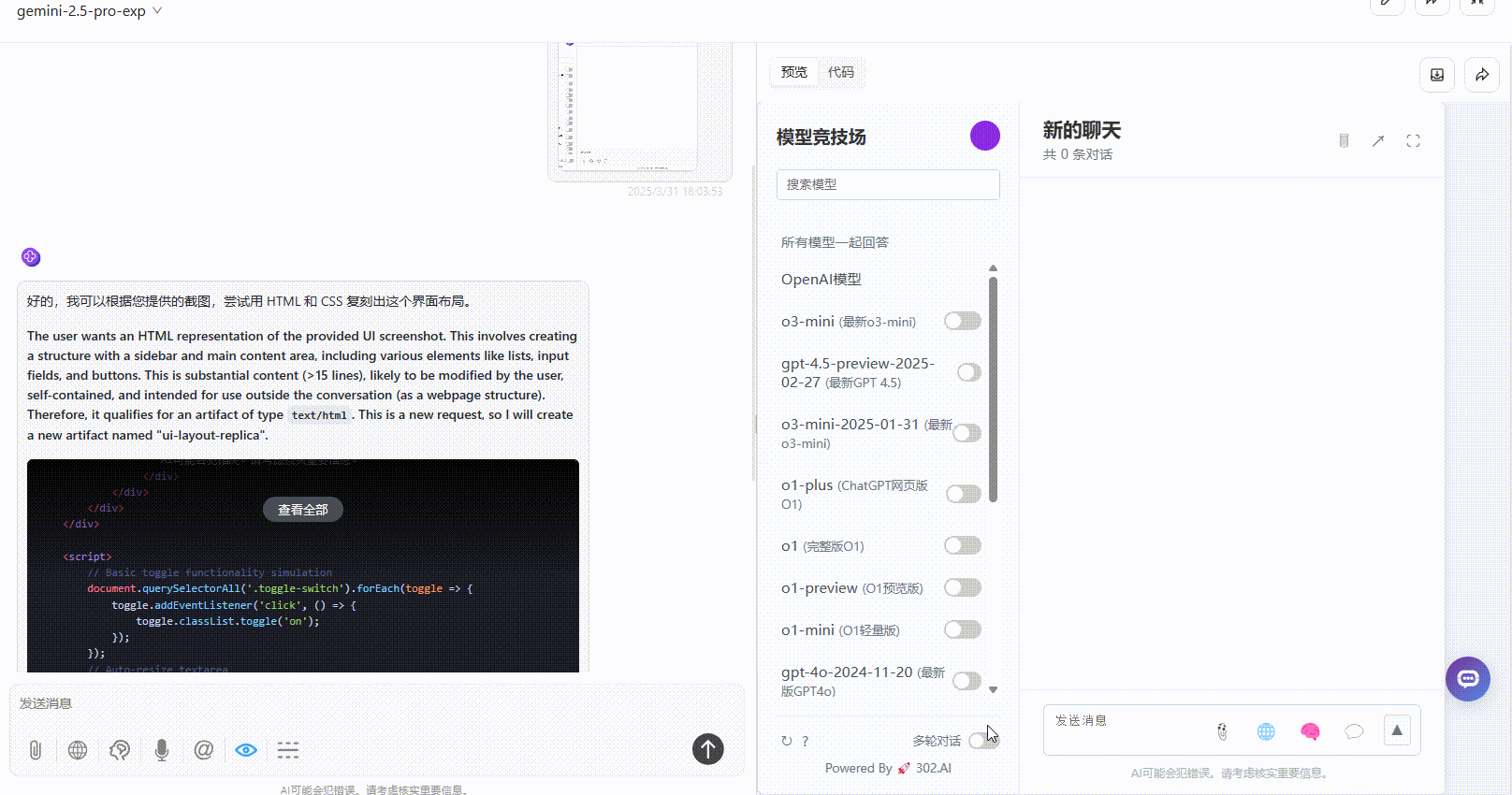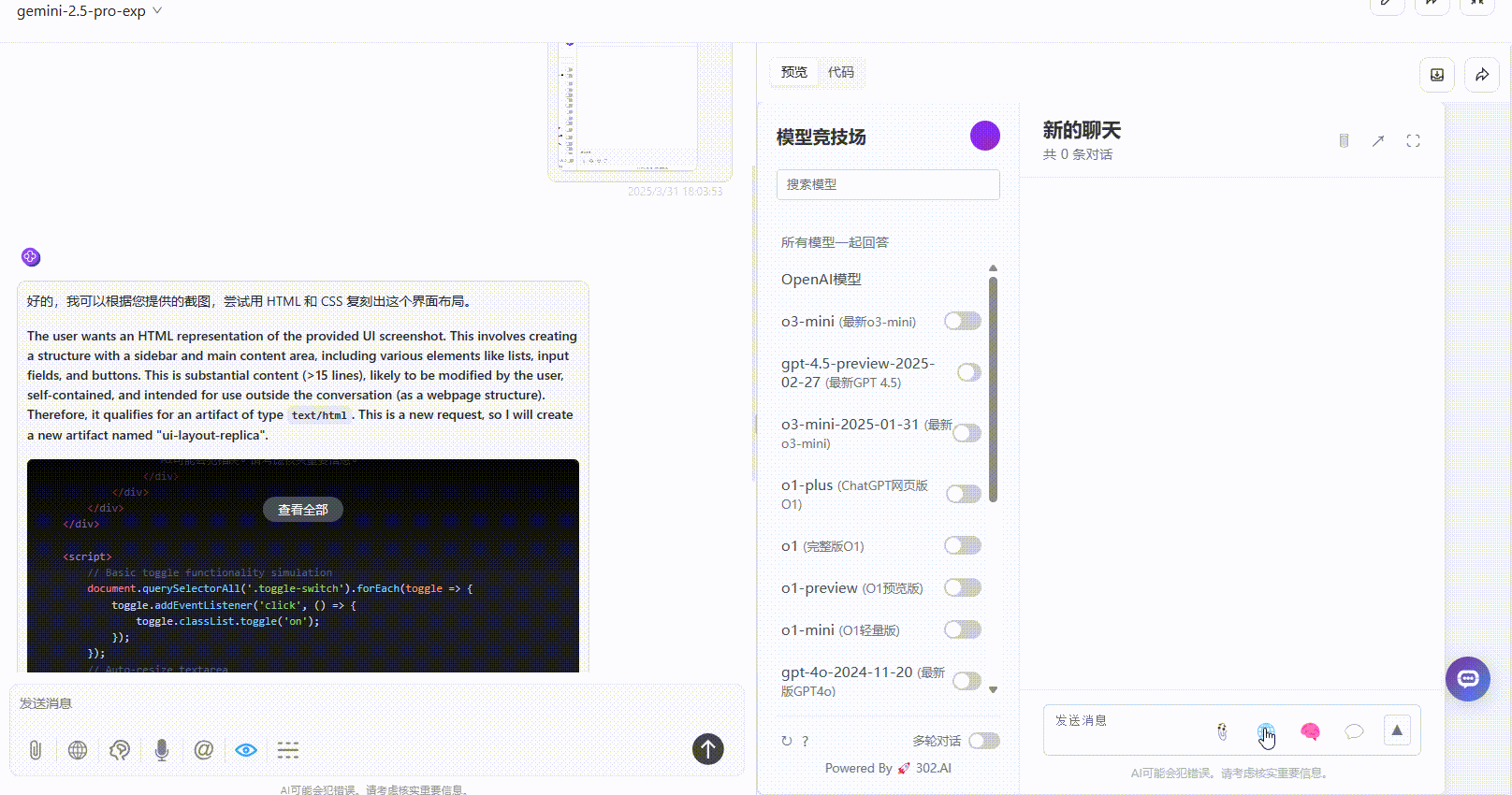
QVQ-Max:生成的速度较慢,思考了250秒后才开始生成。最终展示的效果较为简陋,部分按钮仅用于展示,无法点击,整体效果一般。

实测总结:
| 看手相 | 趣味看图计算 | 数学题解答 | 多图片识别 | 截图复刻HTML | |
| Gemini 2.5 Pro | ❌ | ✔️ | ✔️ | ✔️ | 不错 |
| QVQ-Max | ✔️ | ❌ | ❌ | ✔️ | 一般 |
(实测结果整理)
根据实测结果,可以初步得出以下结论:
(1)Gemini 2.5 Pro在处理数学推理、复刻网页任务时,展现出了更高的准确性和逻辑性。然而,在像看手相这类具有较强主观性的任务中,它则表现出了一定的局限性,难以像人类一样凭借主观经验做出判断。
(2)QVQ-Max在多模态任务中的数学能力和代码生成相对较弱,不及Gemini 2.5 Pro。但在面对看手相、多图关联分析等需要综合多种信息进行主观判断和创意生成的任务时,却展现出了独特的优势。
(3)综合来看,QVQ-Max和Gemini 2.5 Pro各有千秋,适用于不同的应用场景。QVQ-Max更适合需要深入视觉分析和创意生成的任务,而Gemini 2.5 Pro则相对在逻辑推理的准确性和代码任务更为出色。
在302.AI上使用阿里新模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
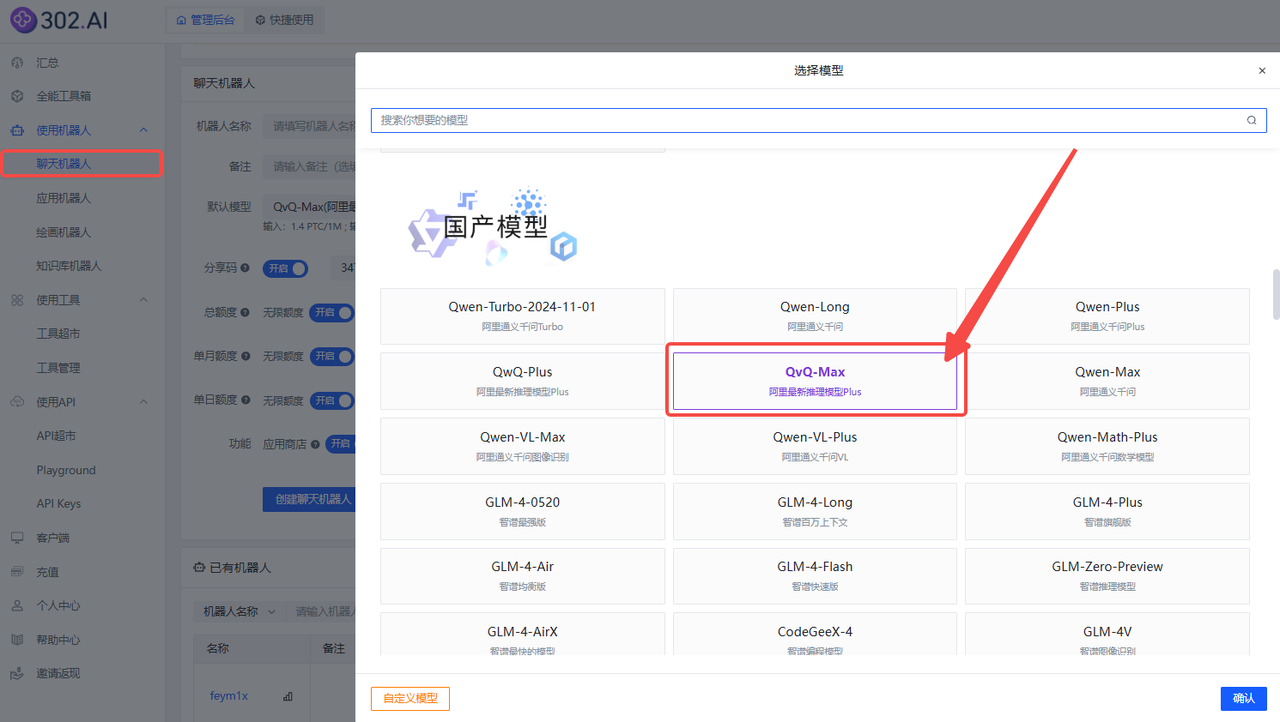
依次点击使用机器人→聊天机器人→ 模型→ 选择模型QvQ-Max→创建聊天机器人;
Qwen2.5-VL-32B和Qwen2.5-Omni-7B:
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→国产/开源模型→查看文档;
