3月24日,DeepSeek V3 发布新版本:DeepSeek-V3-0324。
据官方介绍,新版 V3 模型借鉴 DeepSeek-R1 模型训练过程中所使用的强化学习技术,大幅提高了在推理类任务上的表现水平,在 HTML 等代码前端任务上,新版 V3 模型生成的代码可用性更高,视觉效果也更加美观、富有设计感。
DeepSeek-V3.1(即DeepSeek-V3-0324)发布不到两天,谷歌也宣布推出全新模型:Gemini-2.5-Pro。Gemini-2.5-Pro 是一个推理模型,在各种推理、数学、科学、编程基准上都表现出色。其中尤其擅长创建视觉效果好的Web应用、代码智能体应用、代码转换和编辑。
话不多说,今天我们就通过五个案例实测对比 DeepSeek-V3.1、Gemini-2.5-Pro、Claude-3.7-sonnet在前端任务上的表现,看看到底谁更胜一筹!
模型实测
实测使用的工具为:302.AI聊天机器人-Artifacts功能
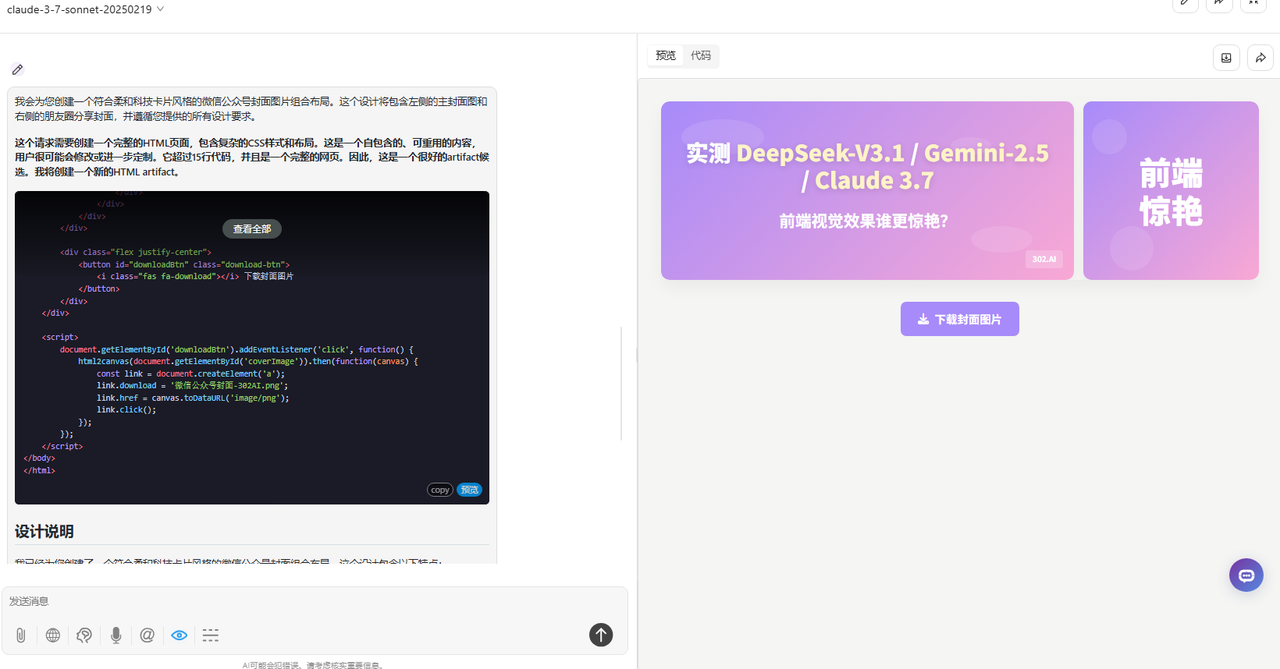
实测1:公众号封面
提示词:


优劣排名:DeepSeek-V3.1>Claude-3.7-sonnet>Gemini-2.5-Pro
DeepSeek-V3.1:色彩搭配协调,构图排版合理,还自动提炼出了关键话题在封面最下方,整体效果很不错。
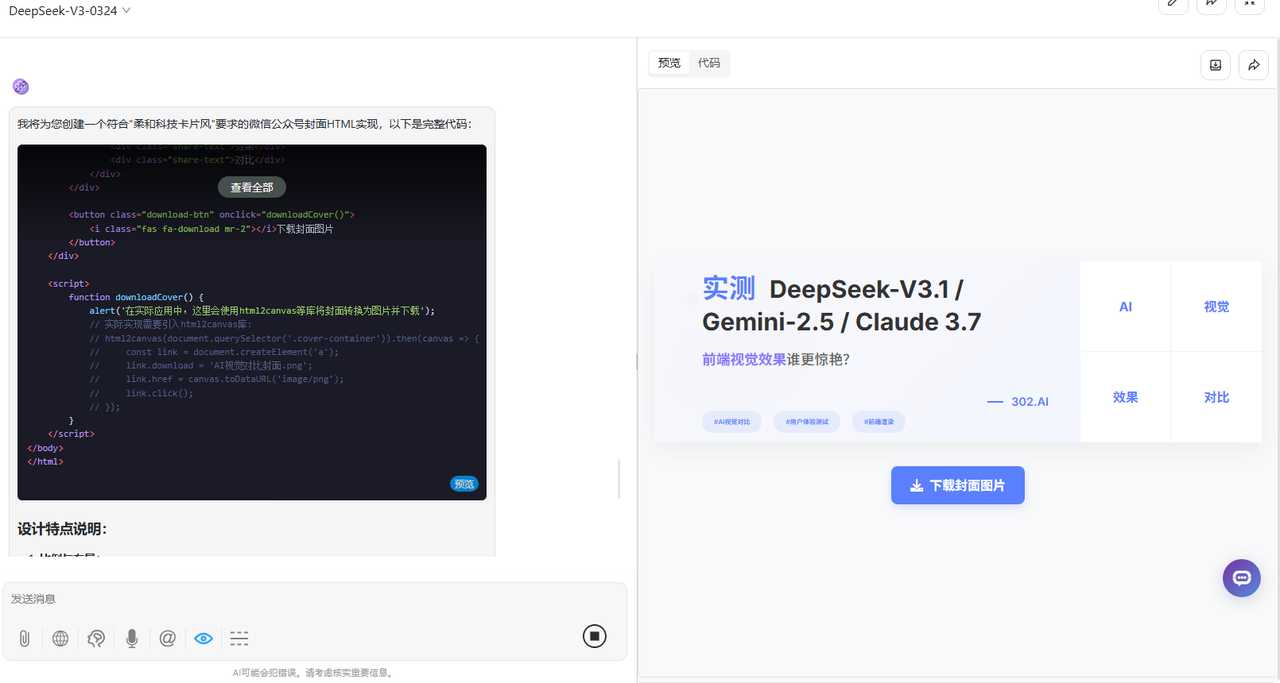
Gemini-2.5-Pro:排版构图很乱,整体效果较差。
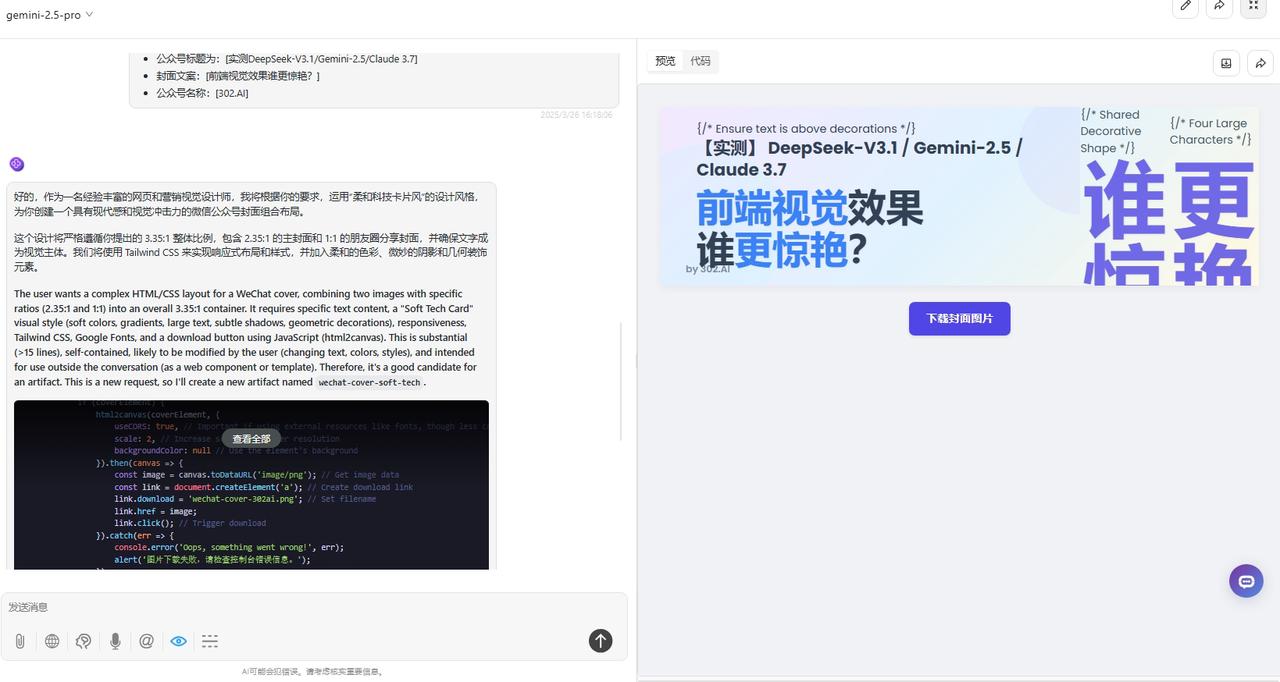
Claude-3.7-sonnet:画面色彩、构图合理,但视觉上展示的元素较少,稍显单调。
实测2:赛博朋克贪吃蛇游戏
提示词:帮我制作一个赛博朋克贪吃蛇游戏,在单个HTML中运行。
优劣排名:Gemini-2.5-Pro>DeepSeek-V3.1>Claude-3.7-sonnet
DeepSeek-V3.1:风格符合提示词要求,游戏可交互、运行起来没有问题,但是可改进的空间较大,比如缺乏开始游戏按钮、没有游戏说明等。
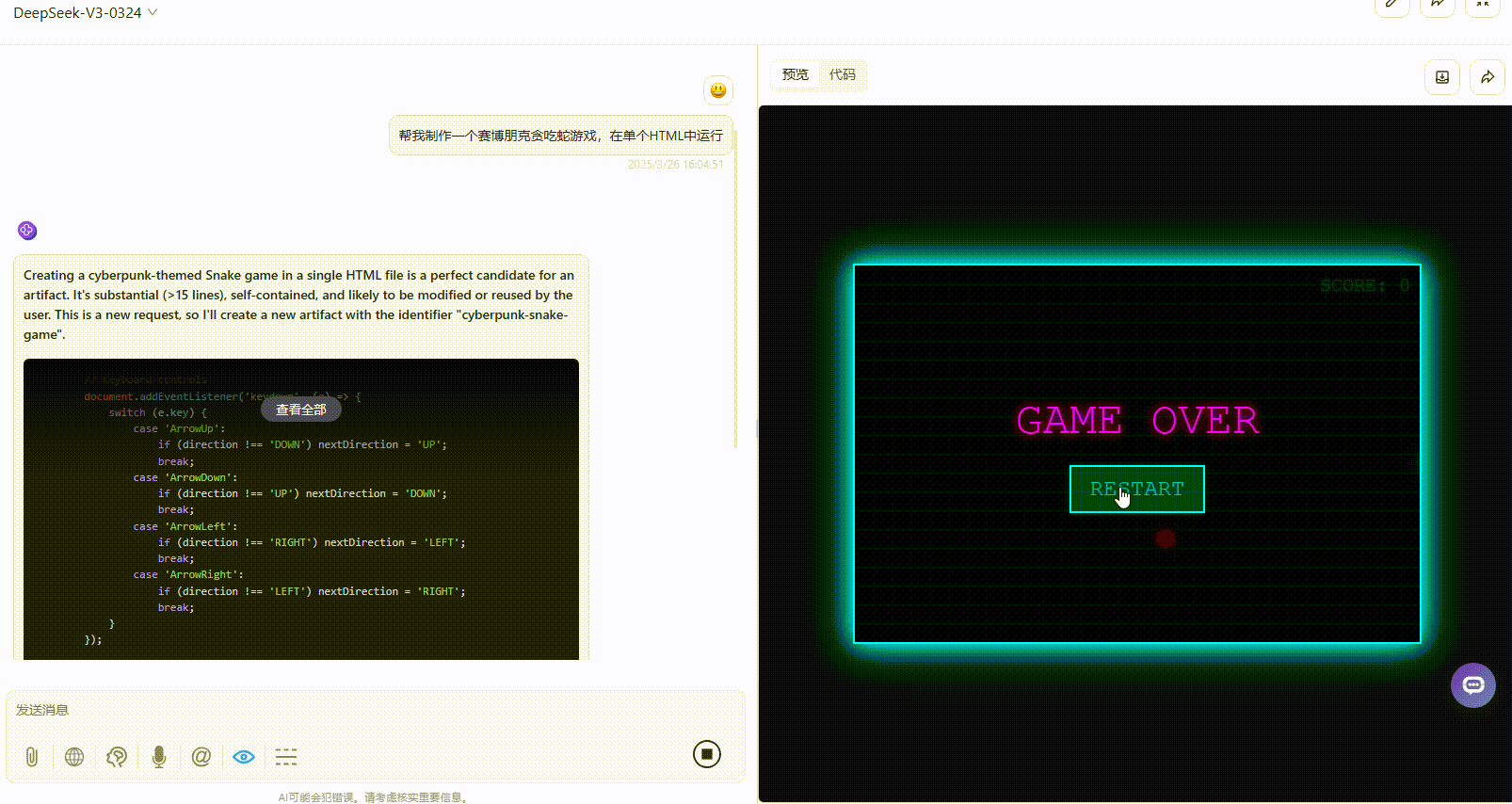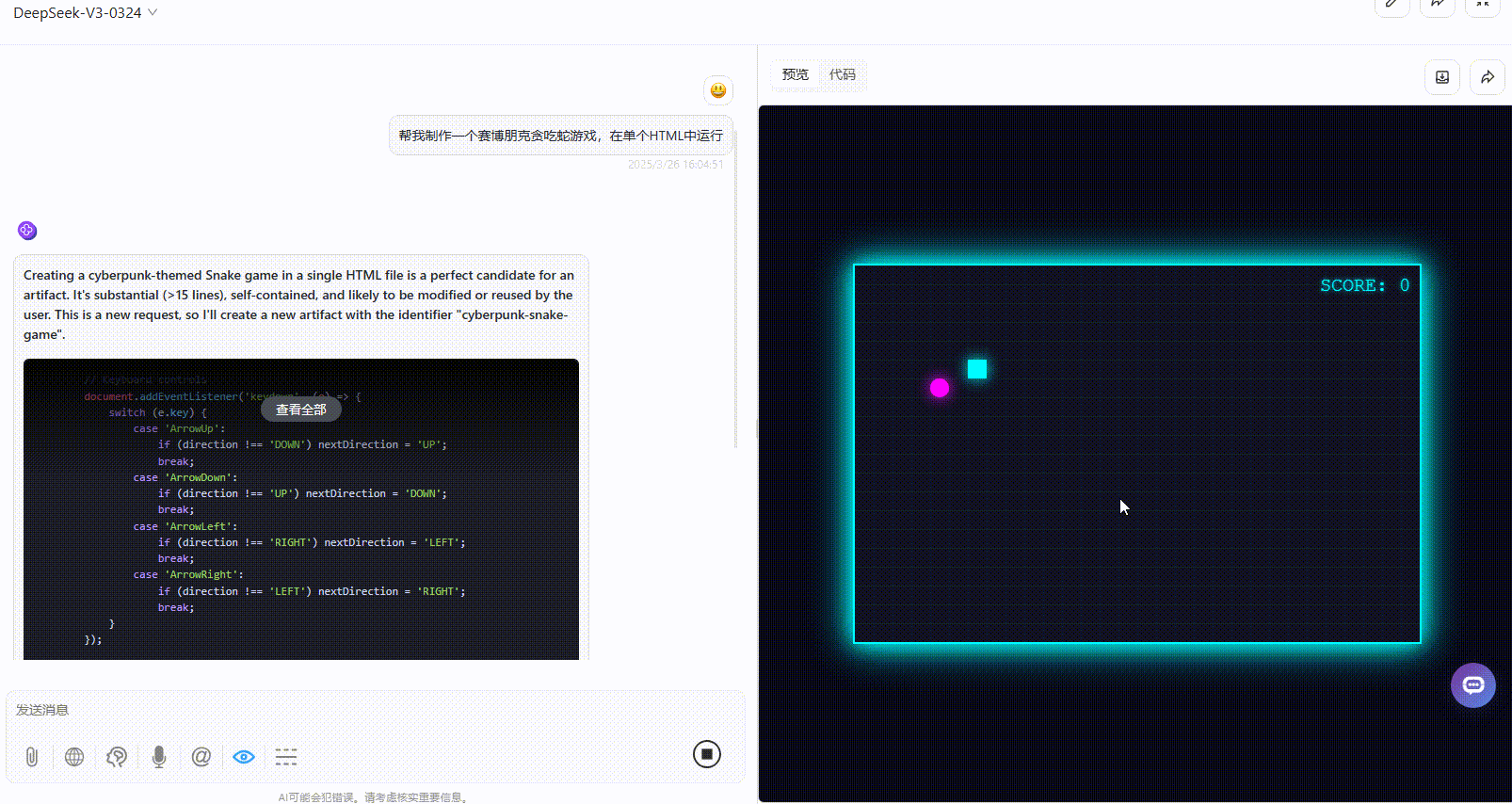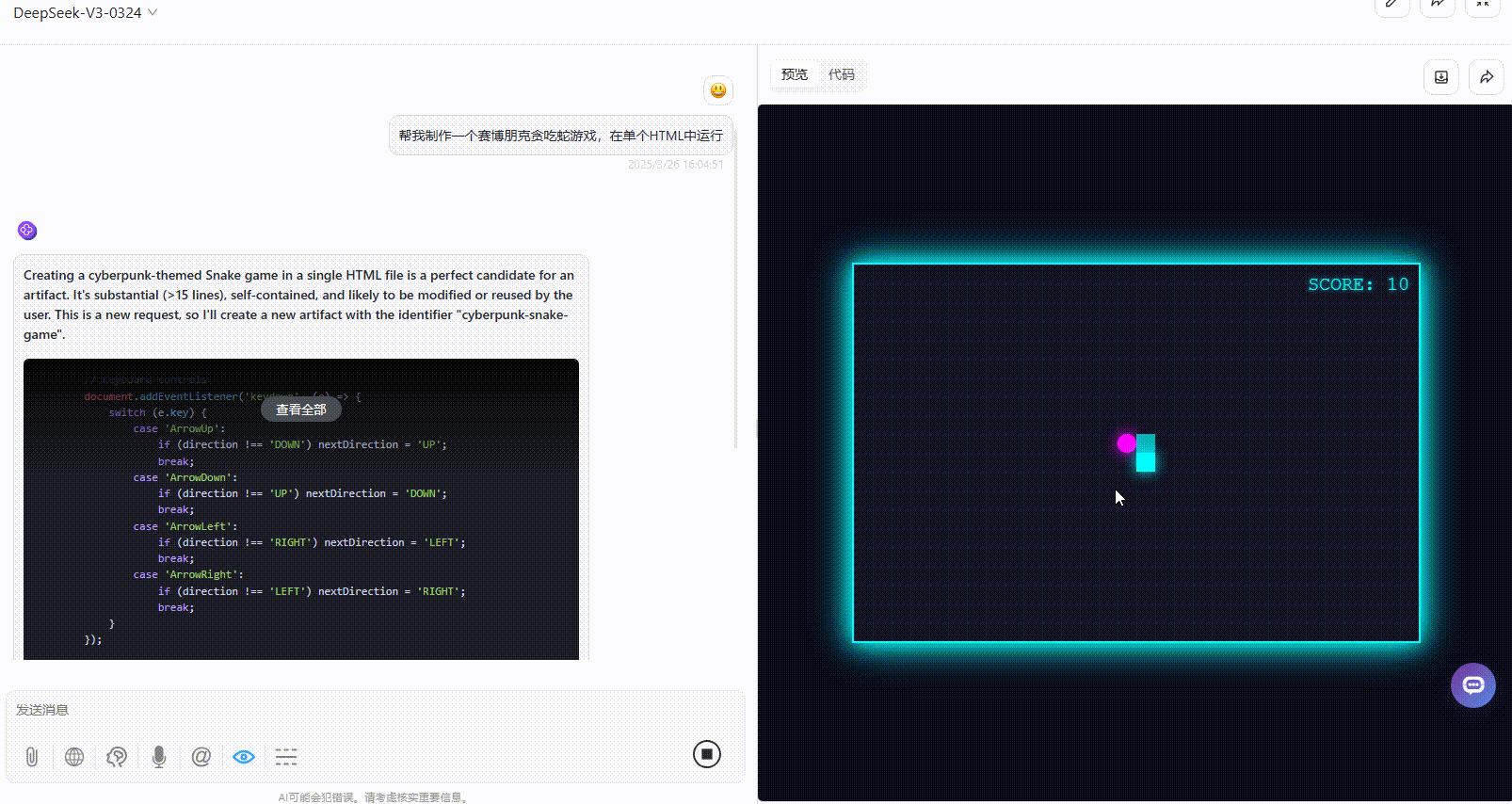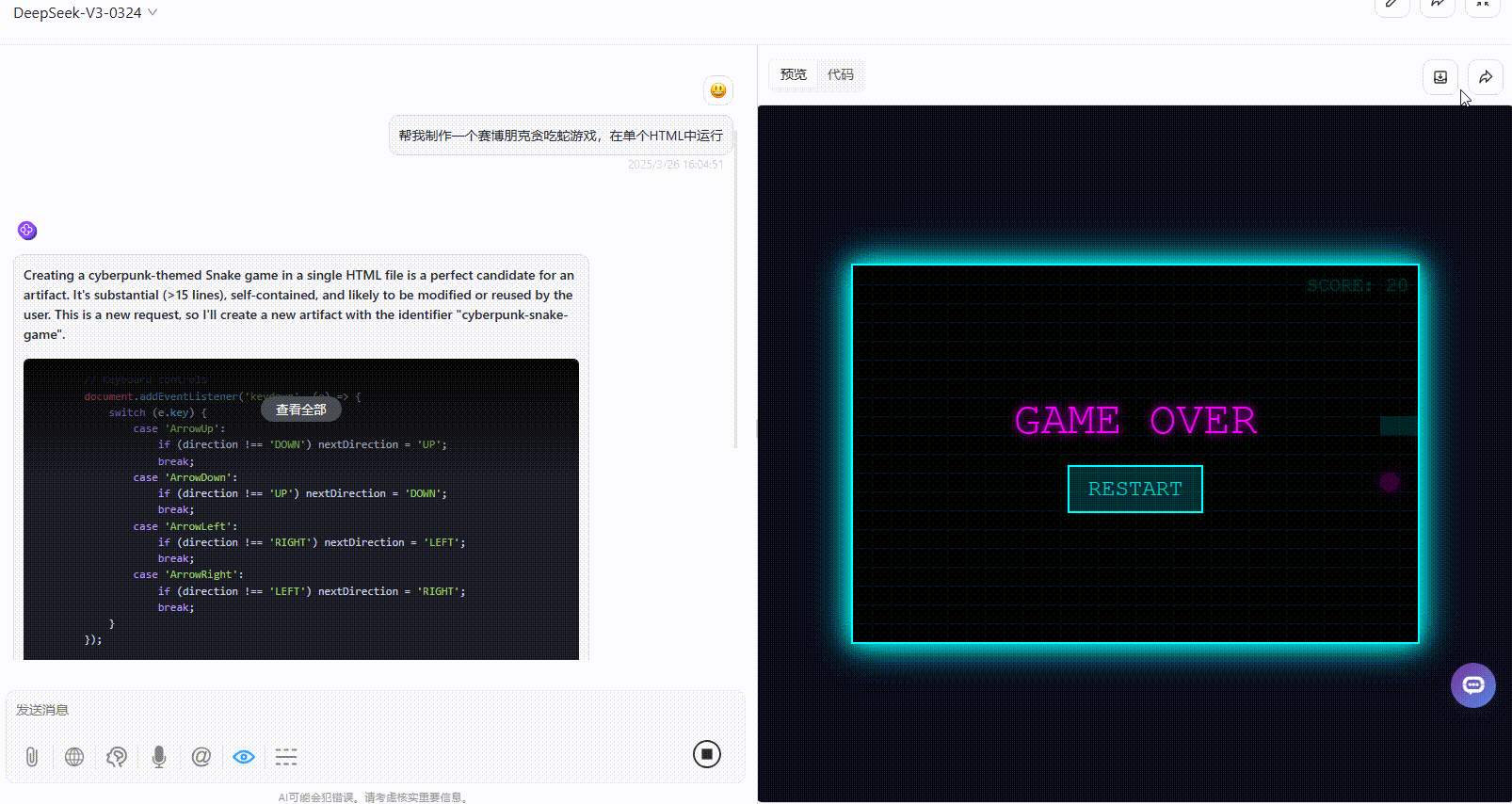
Gemini-2.5-Pro:综合效果最好,风格符合,可操作且具备了游戏说明,整体较为完整。

Claude-3.7-sonnet:虽然风格符合,但实操发现游戏无法运行。
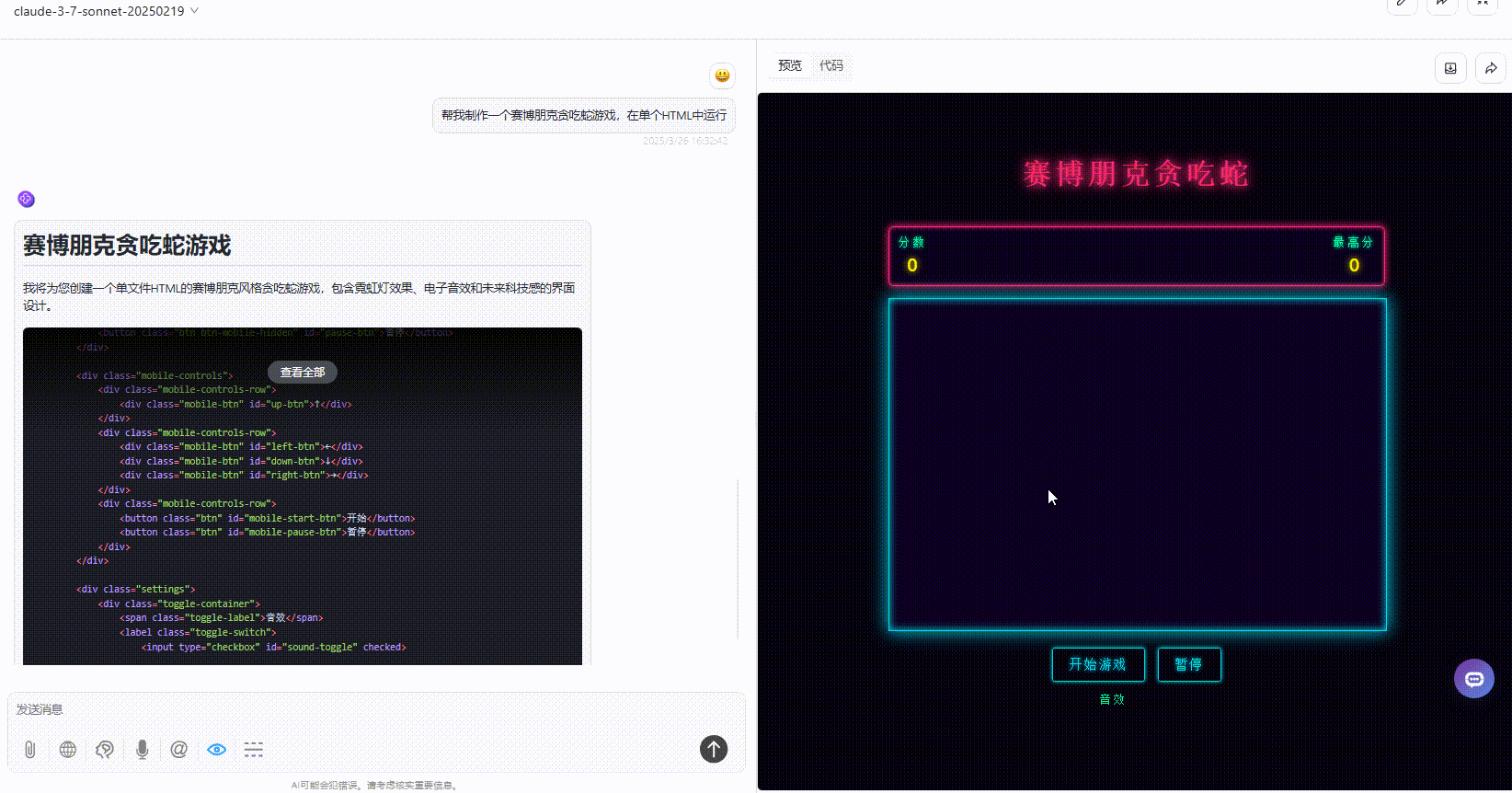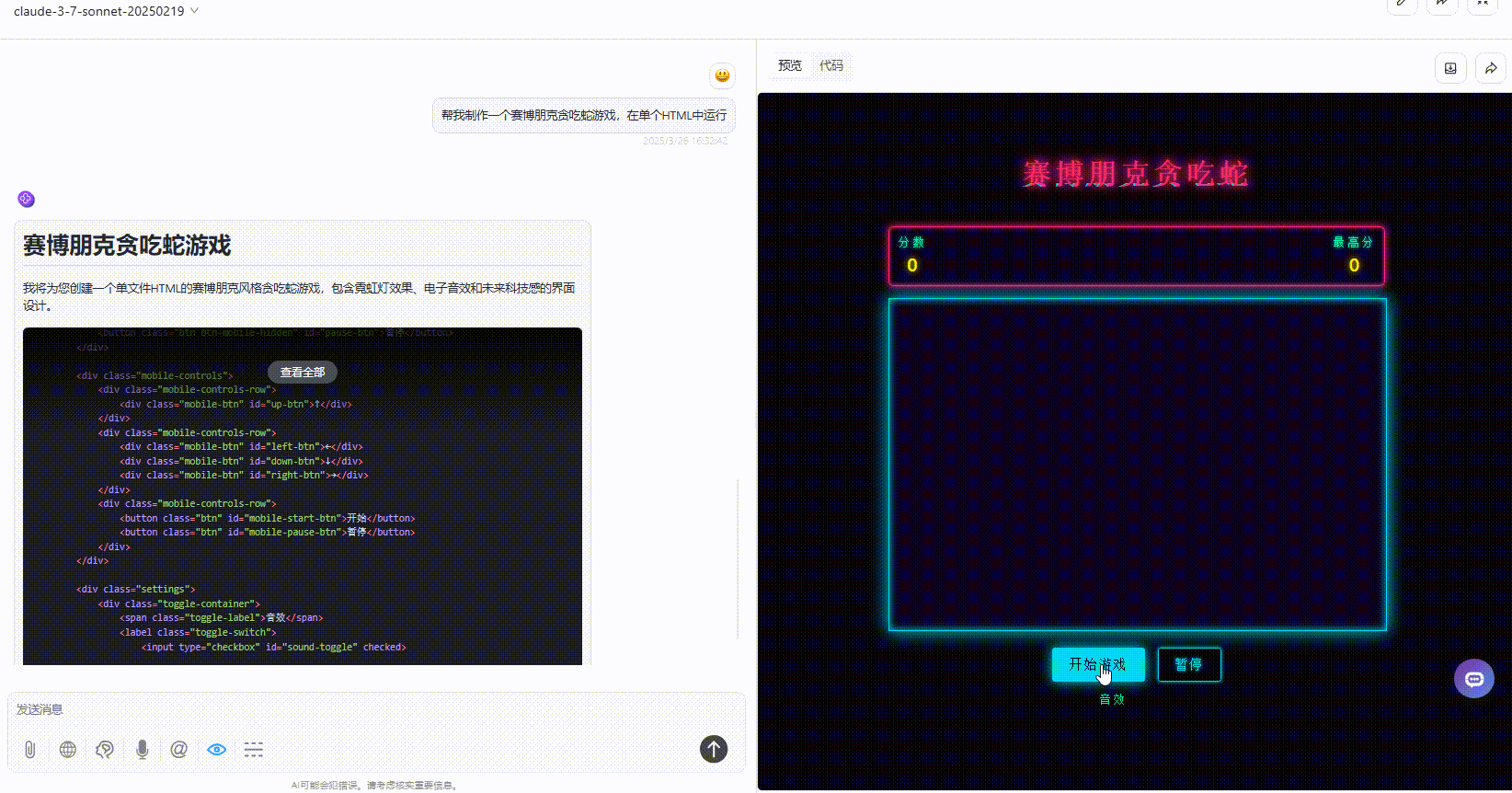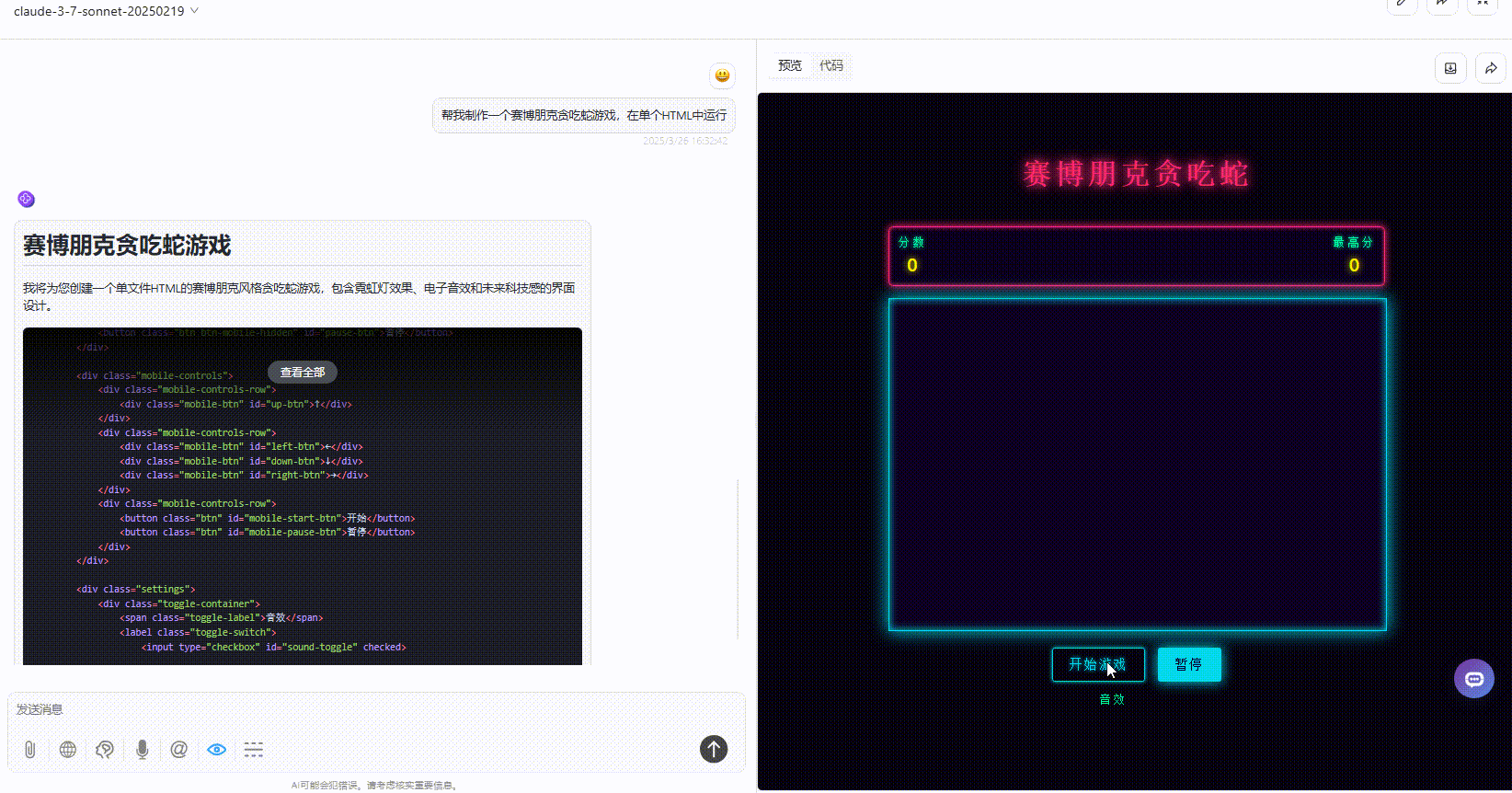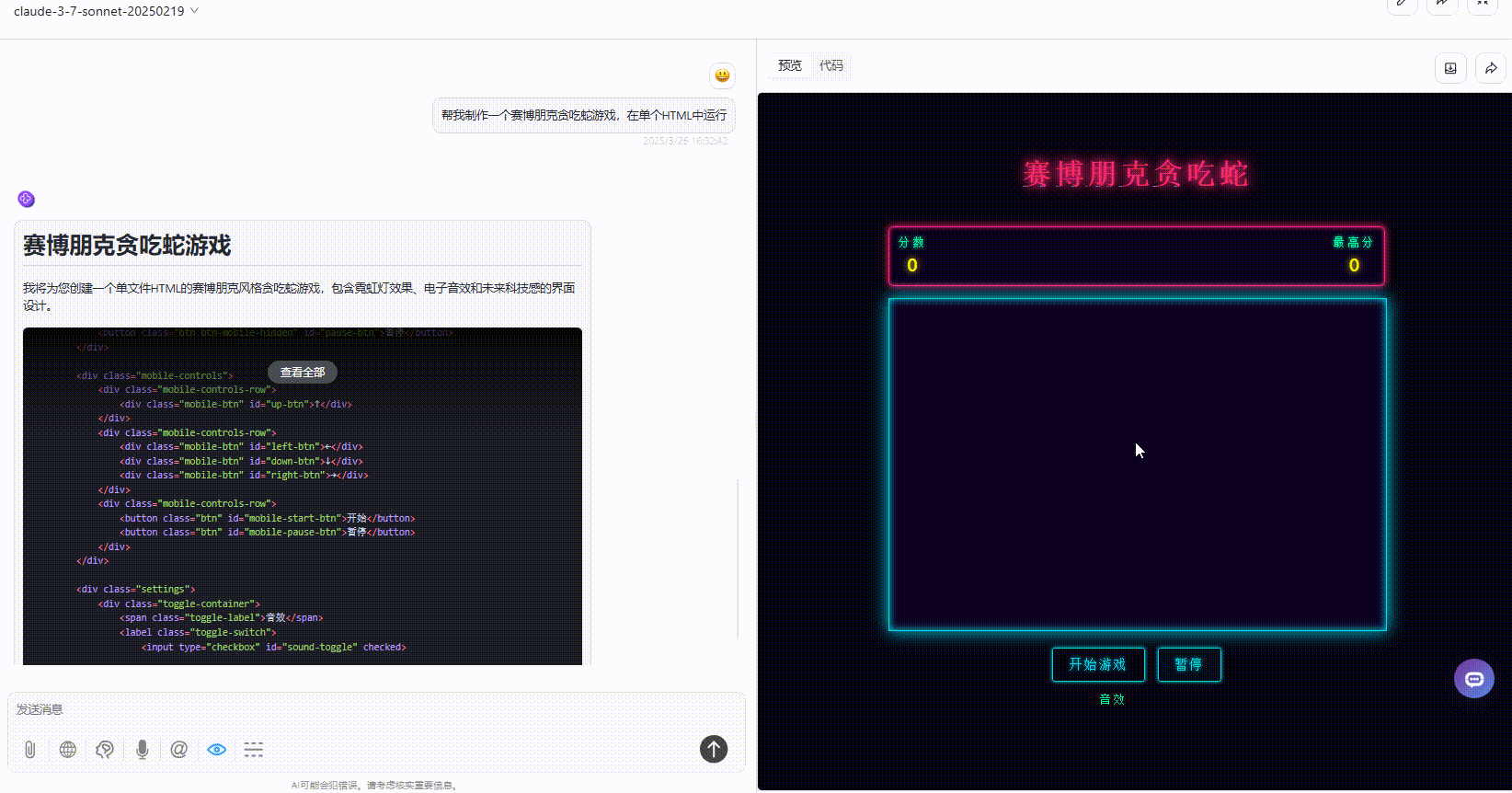
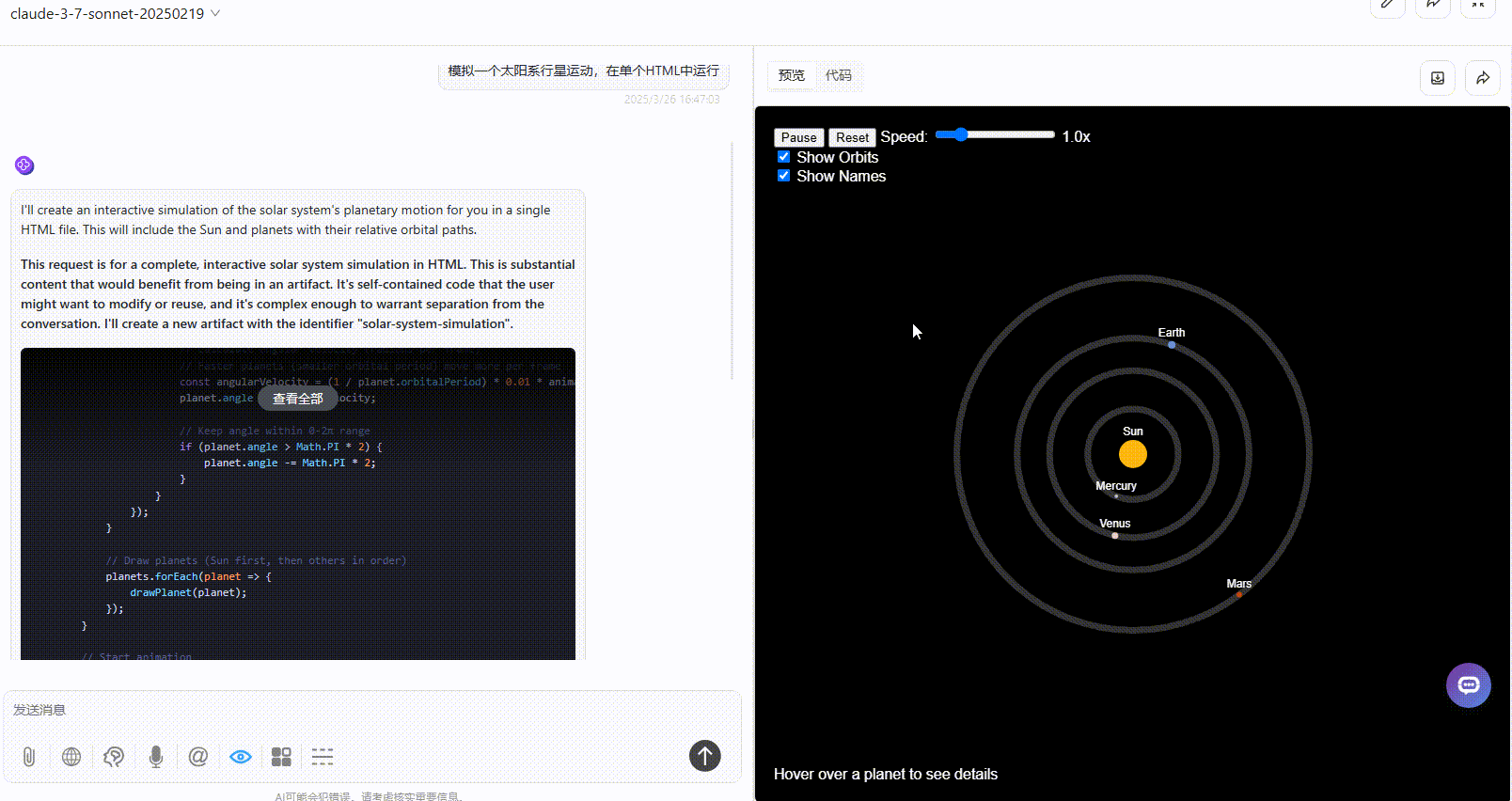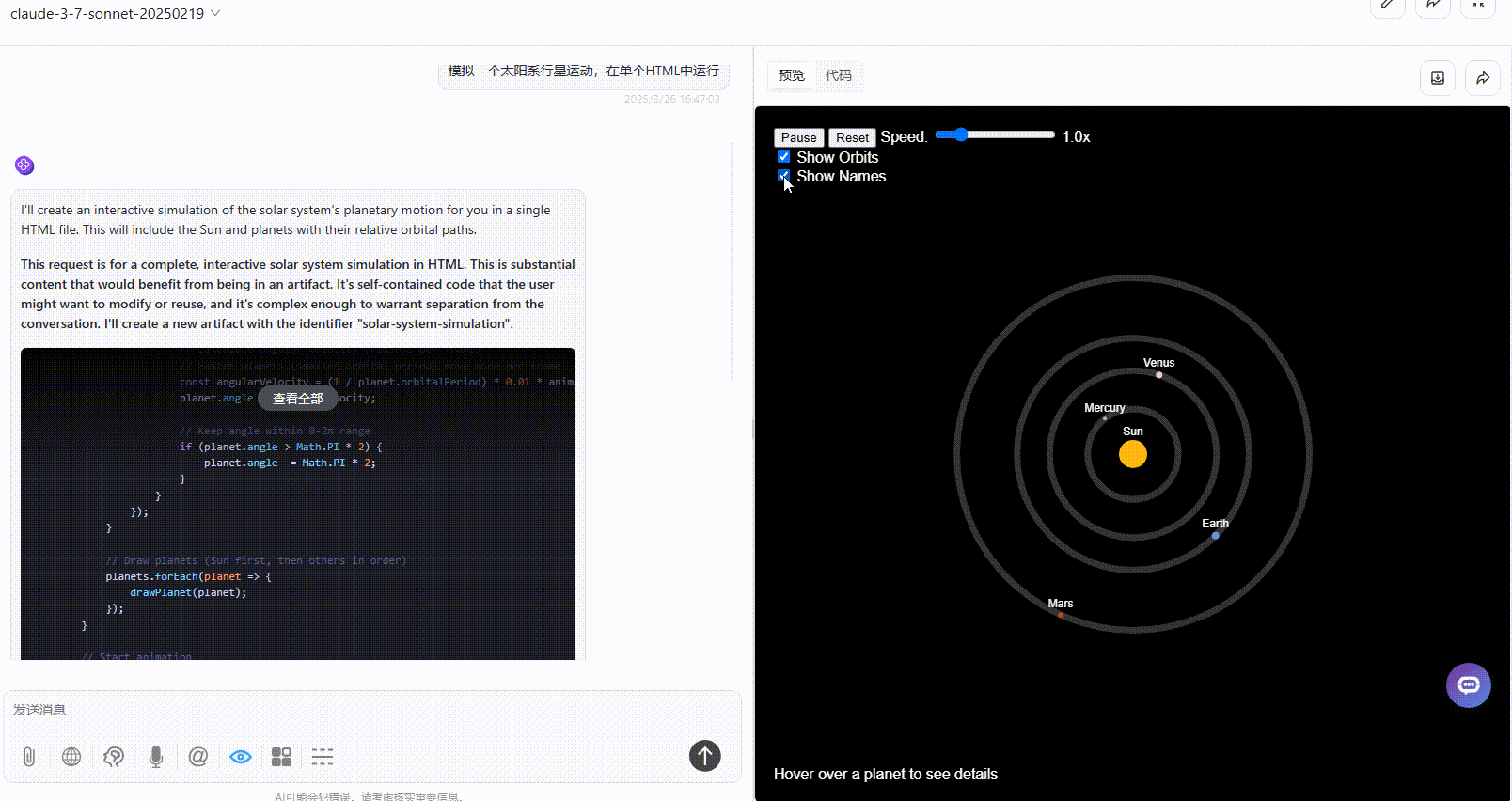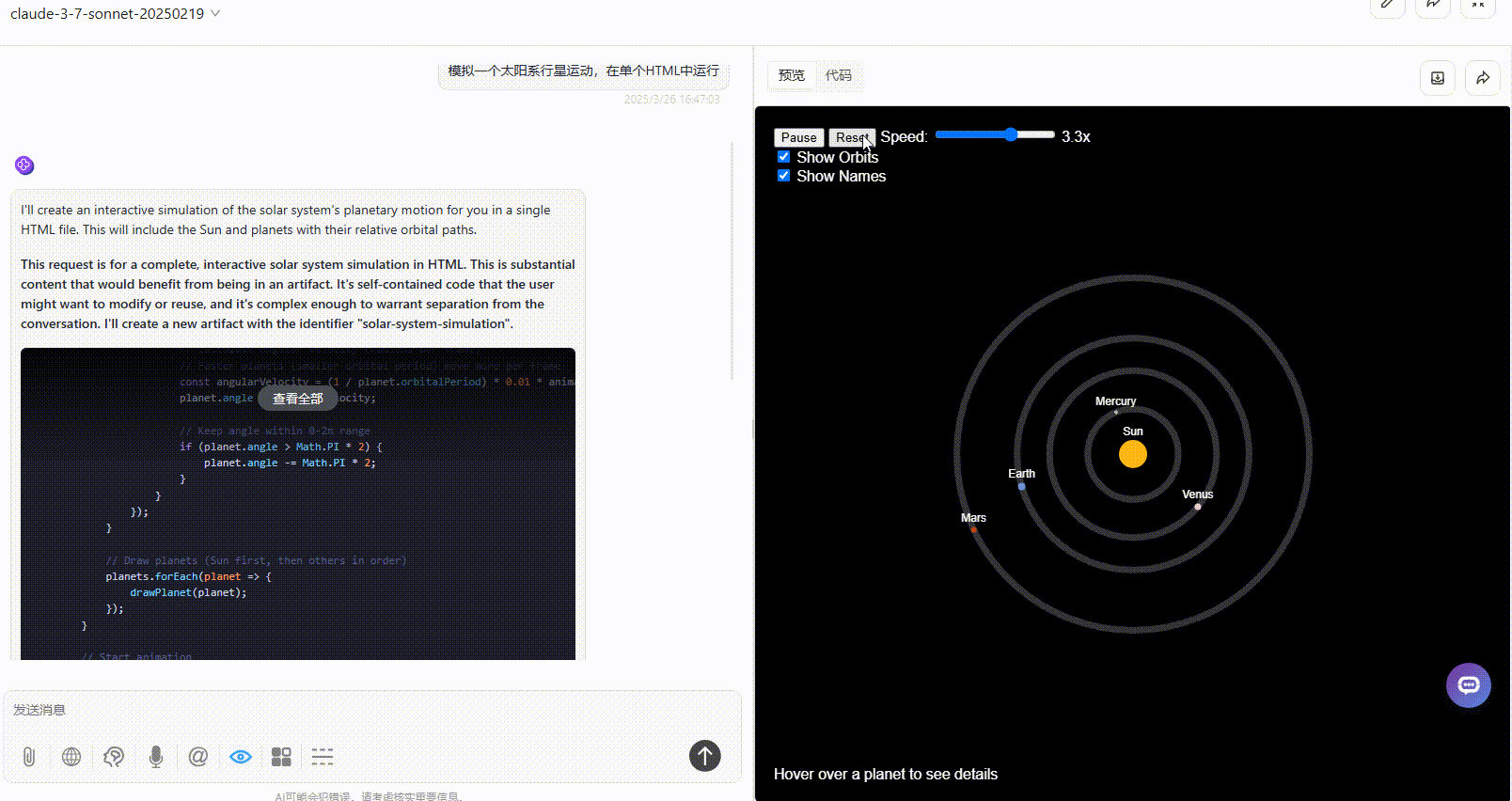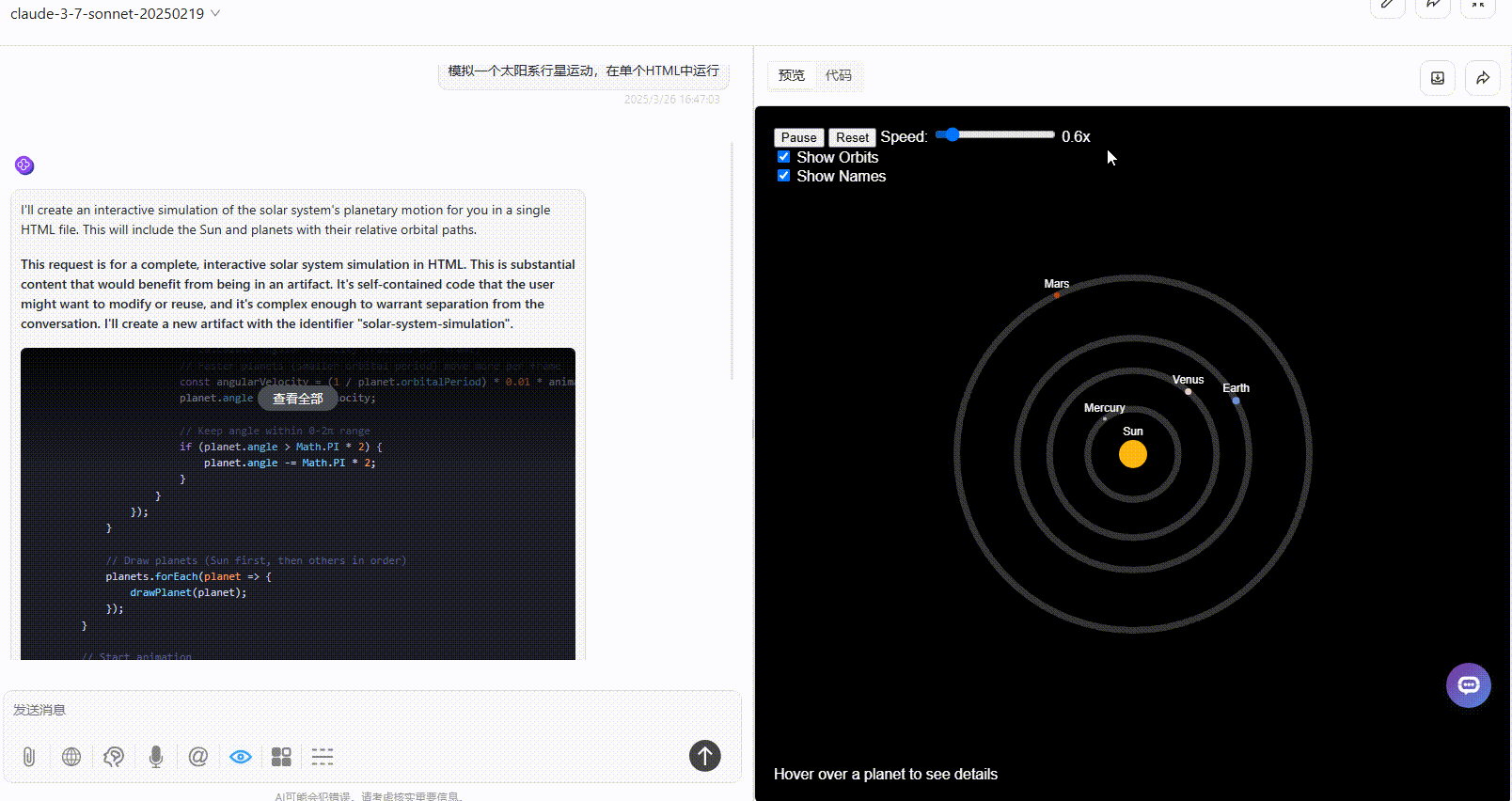
实测3:模拟太阳系行星运动
提示词:模拟一个太阳系行星运动,在单个HTML中运行
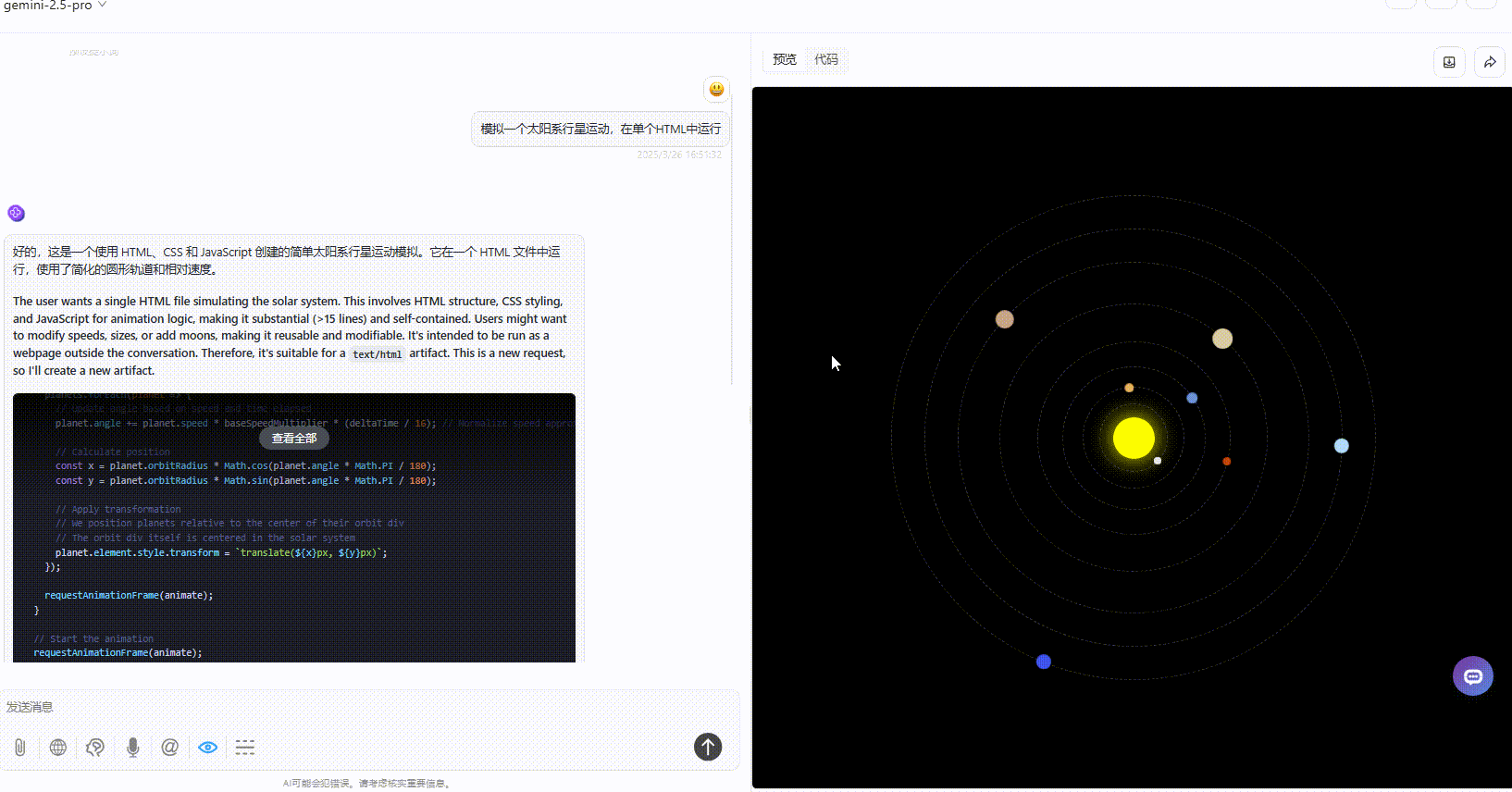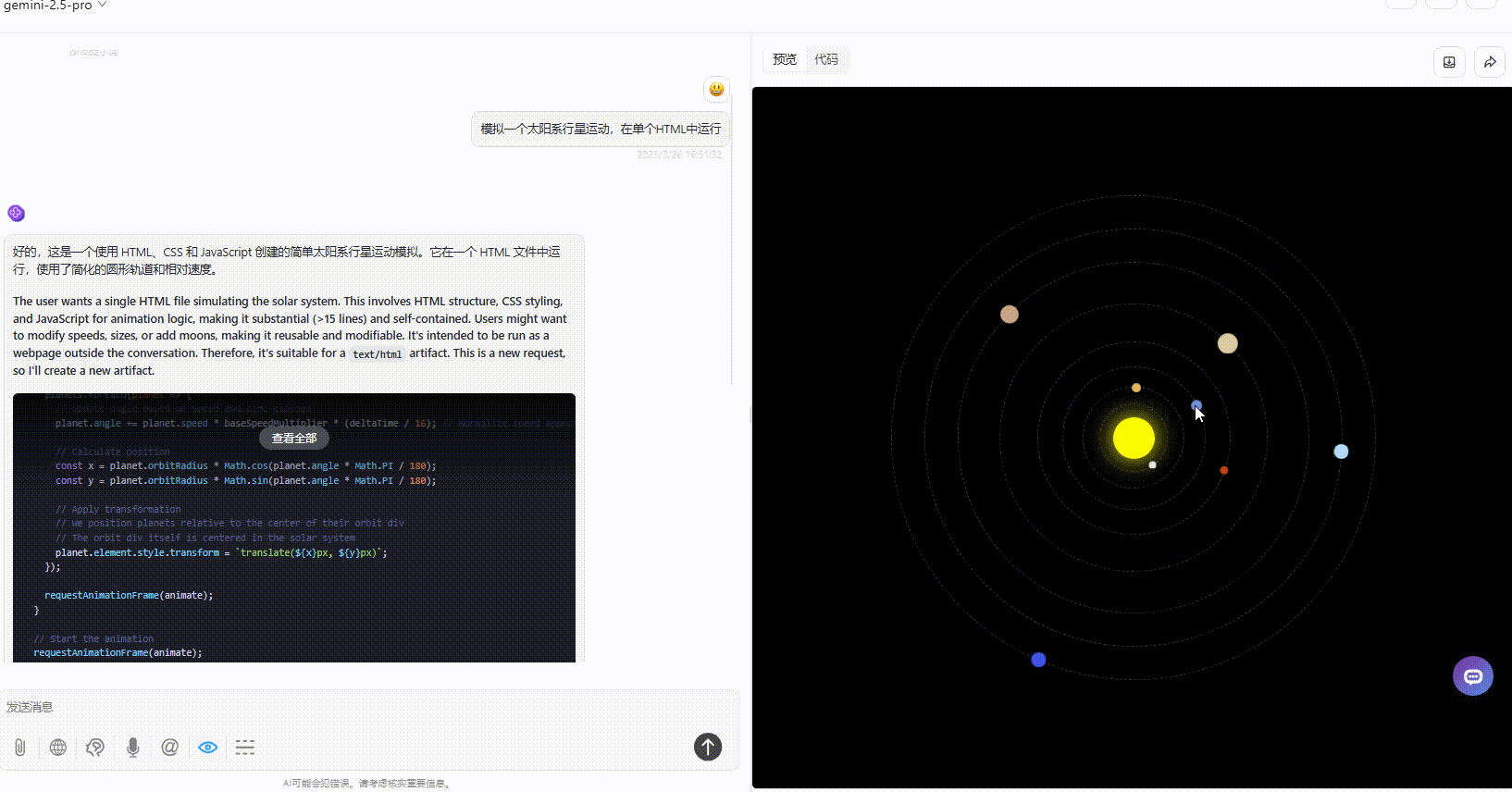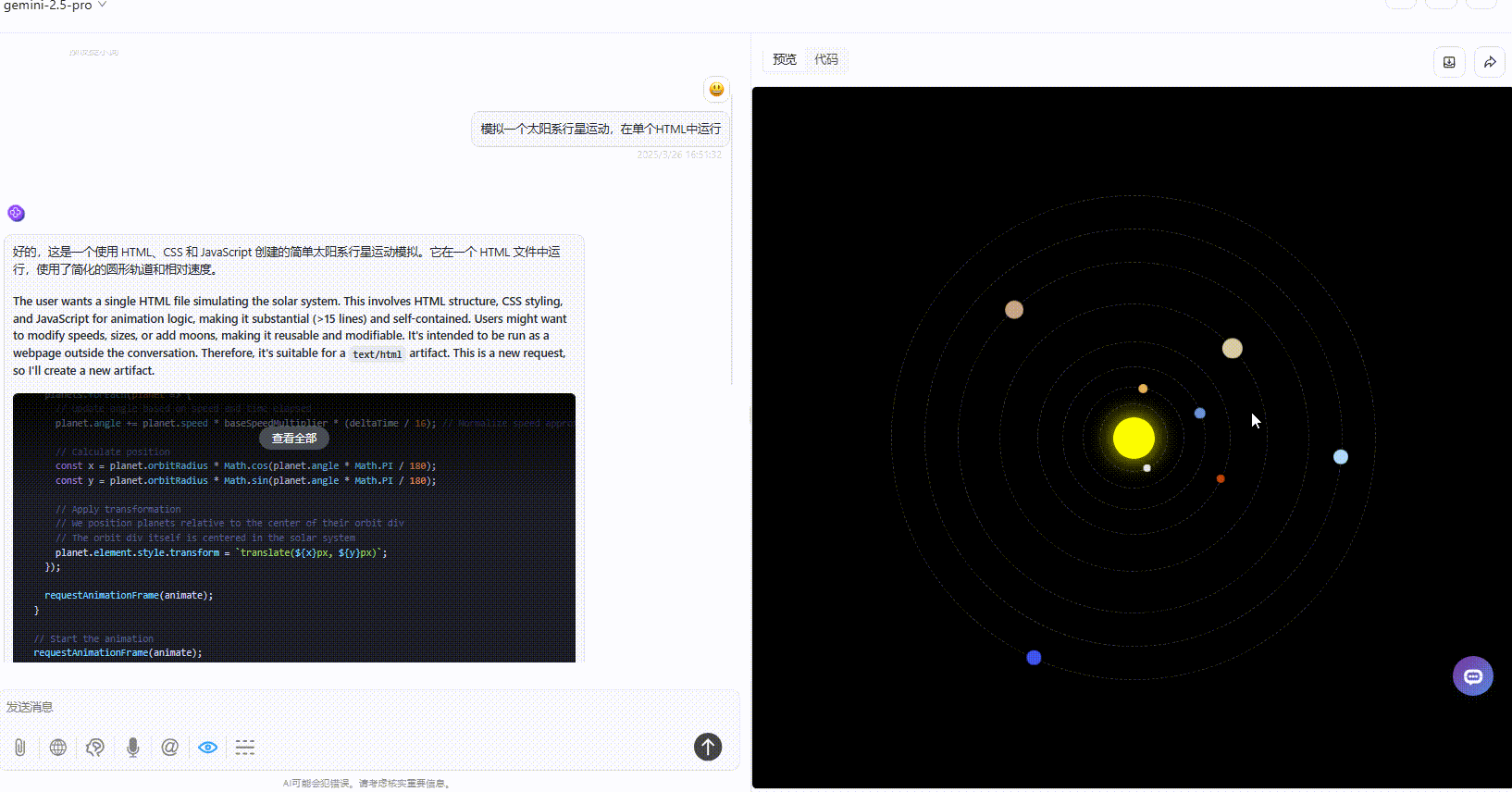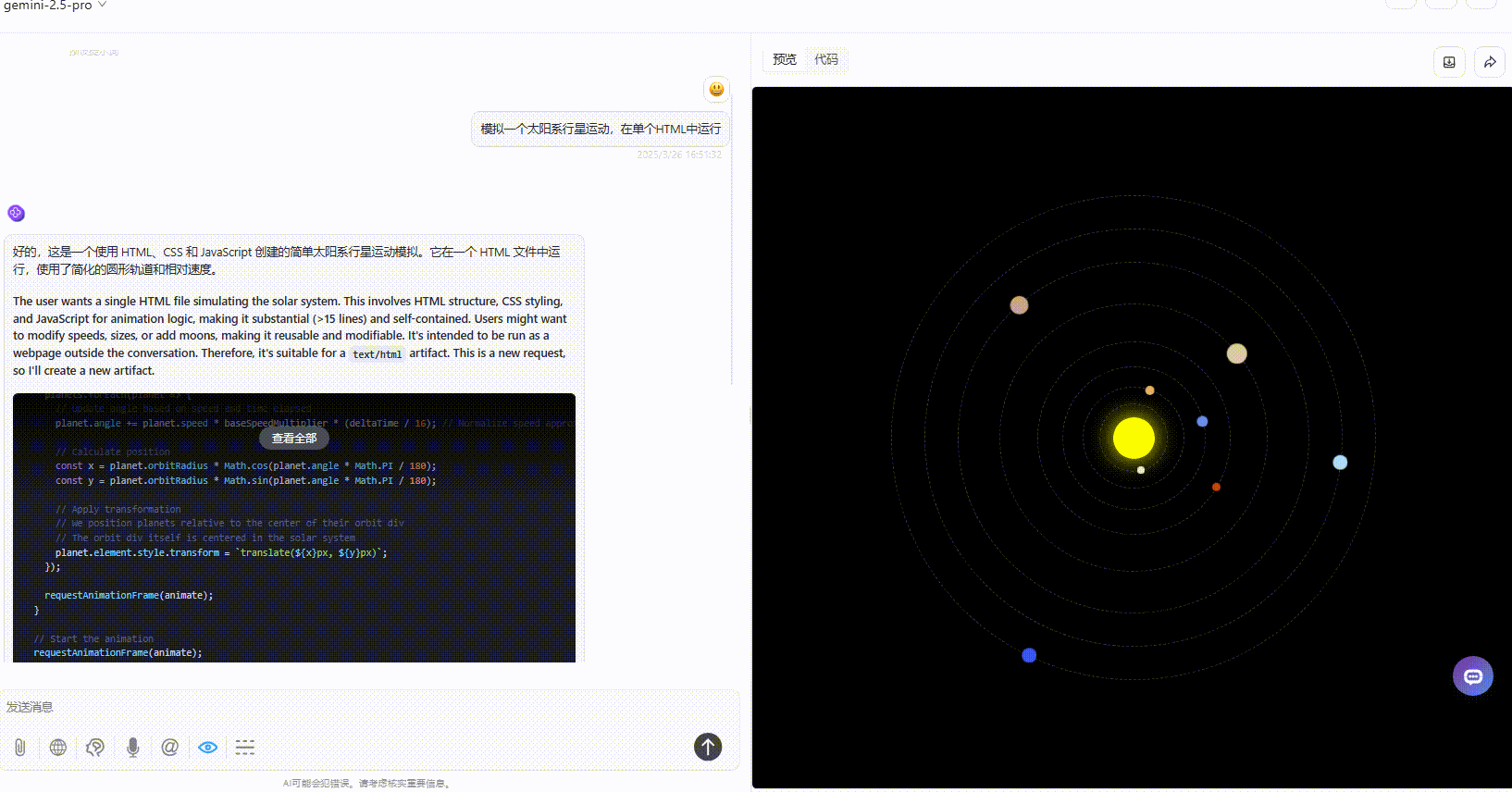
优劣排名:DeepSeek-V3.1>Gemini-2.5-Pro>Claude-3.7-sonnet
DeepSeek-V3.1:具备了速度滑动条,可暂停和重置,点击星星可展示介绍,效果较好。
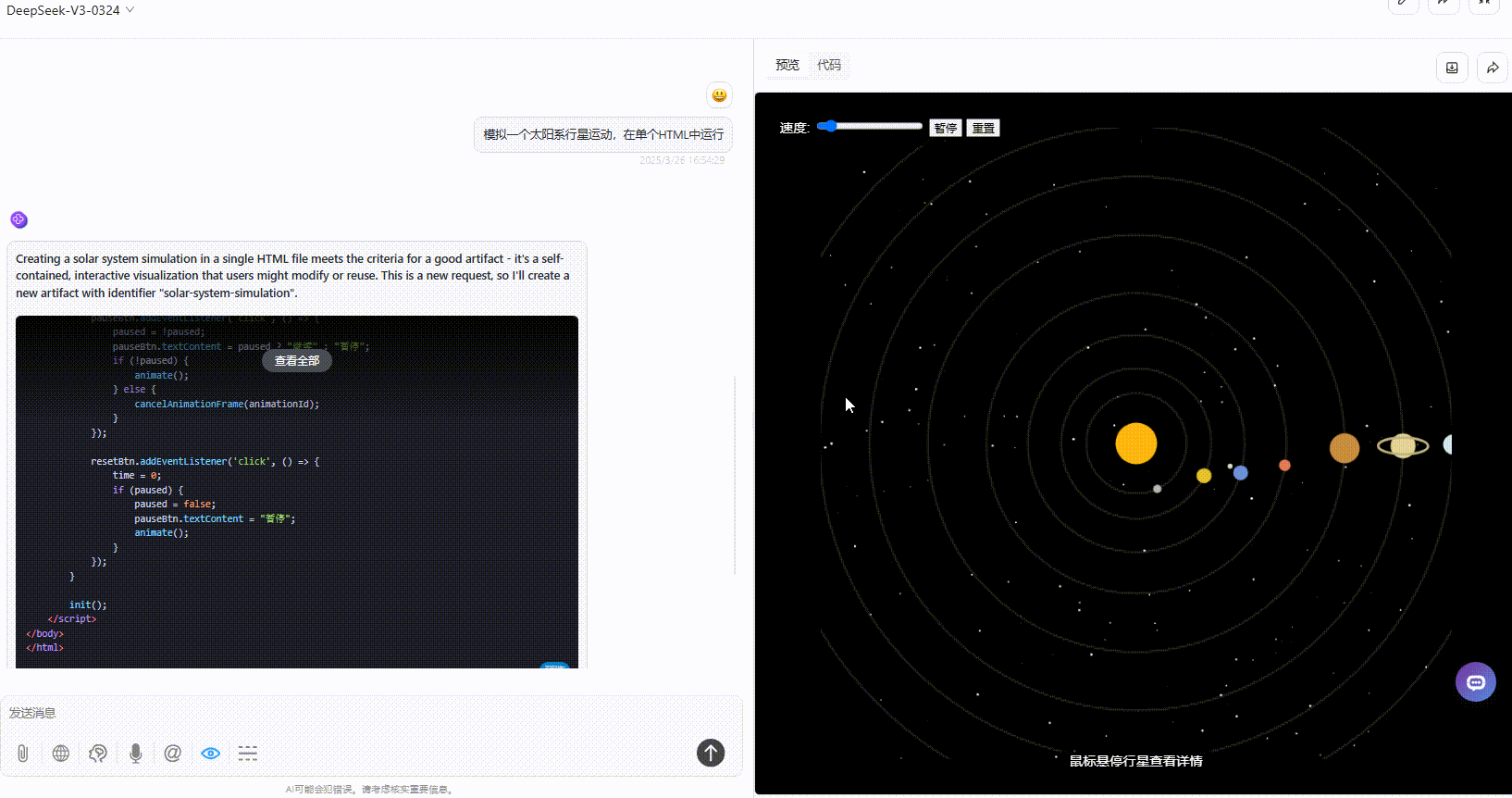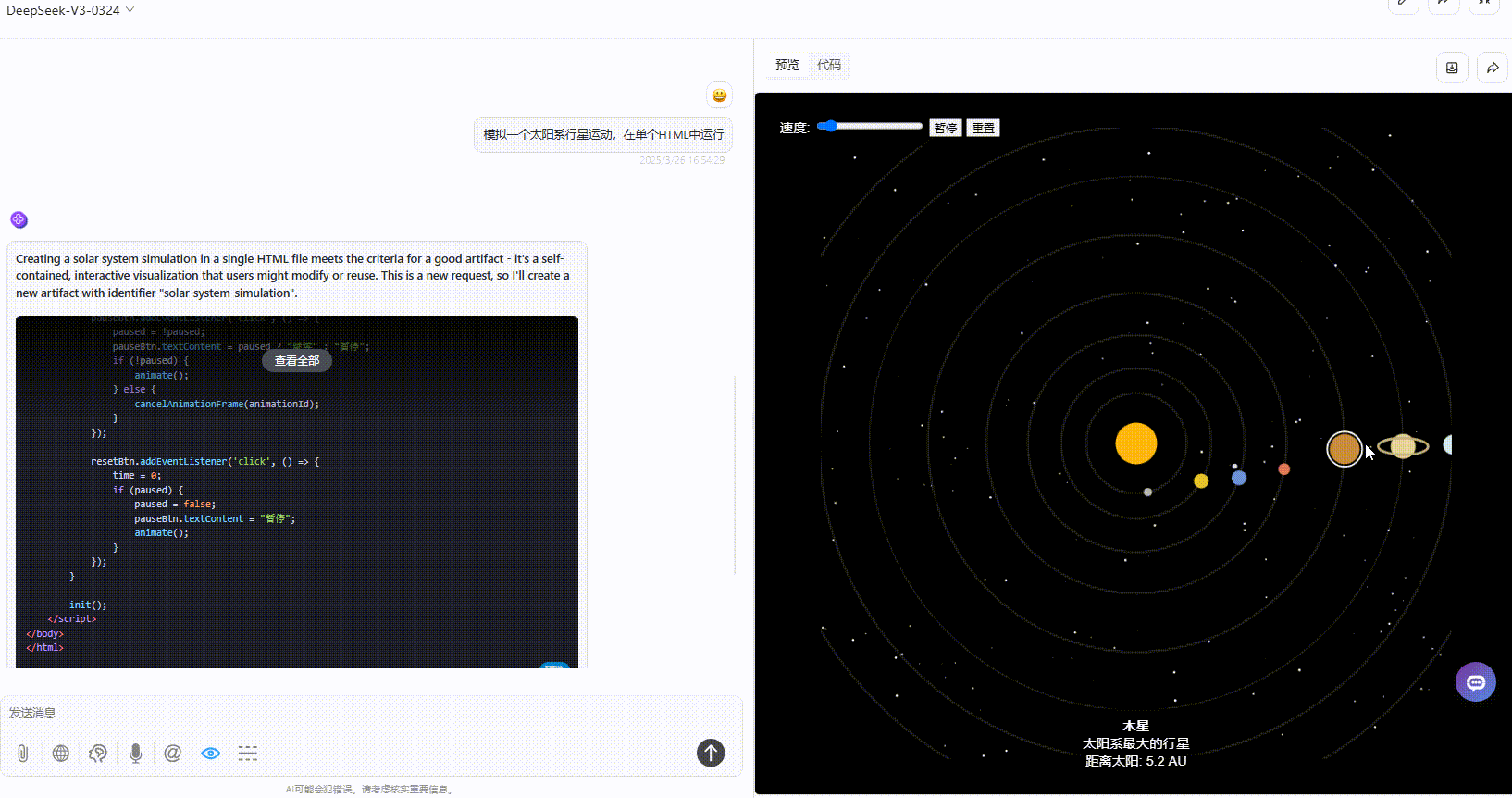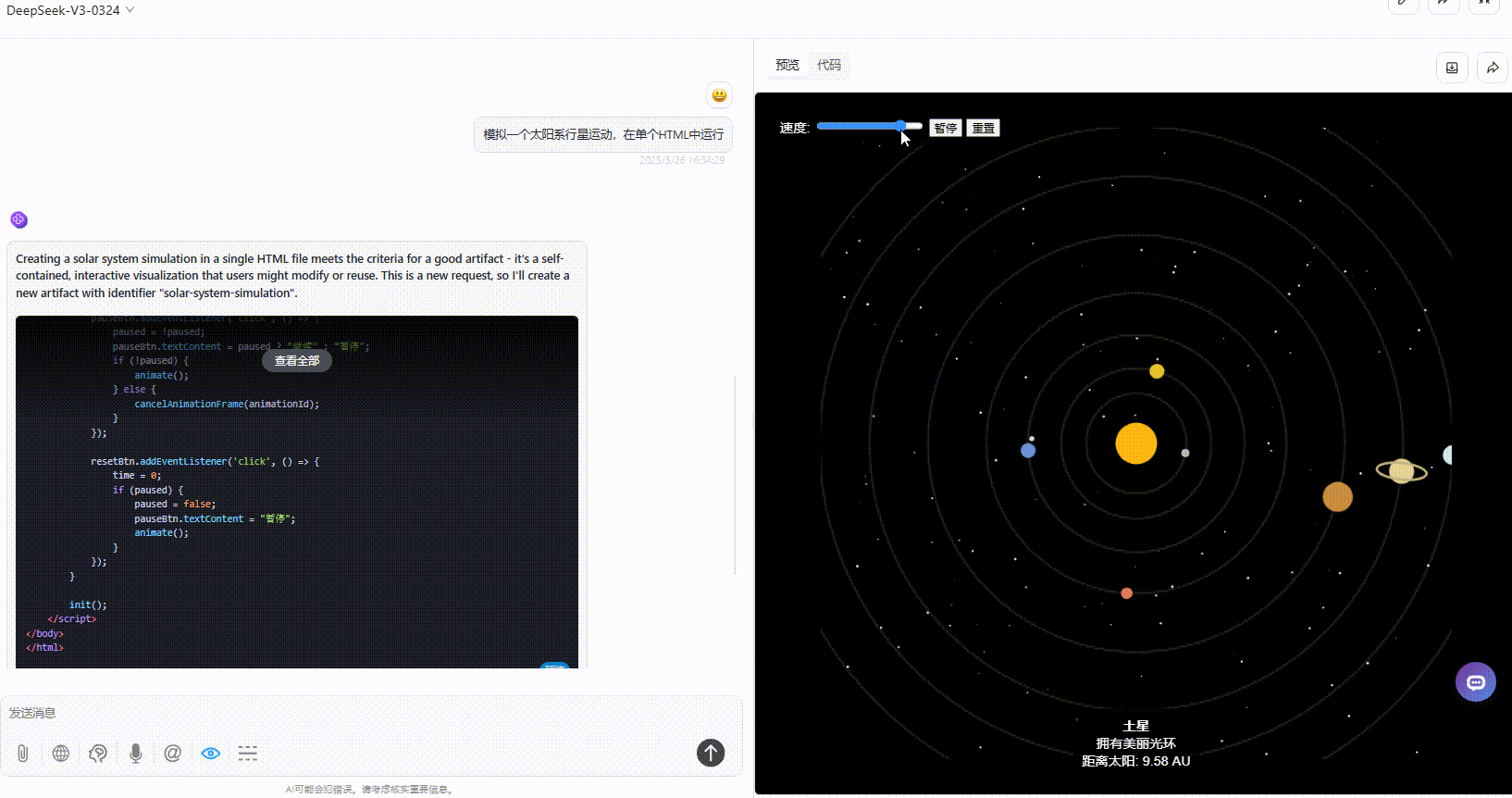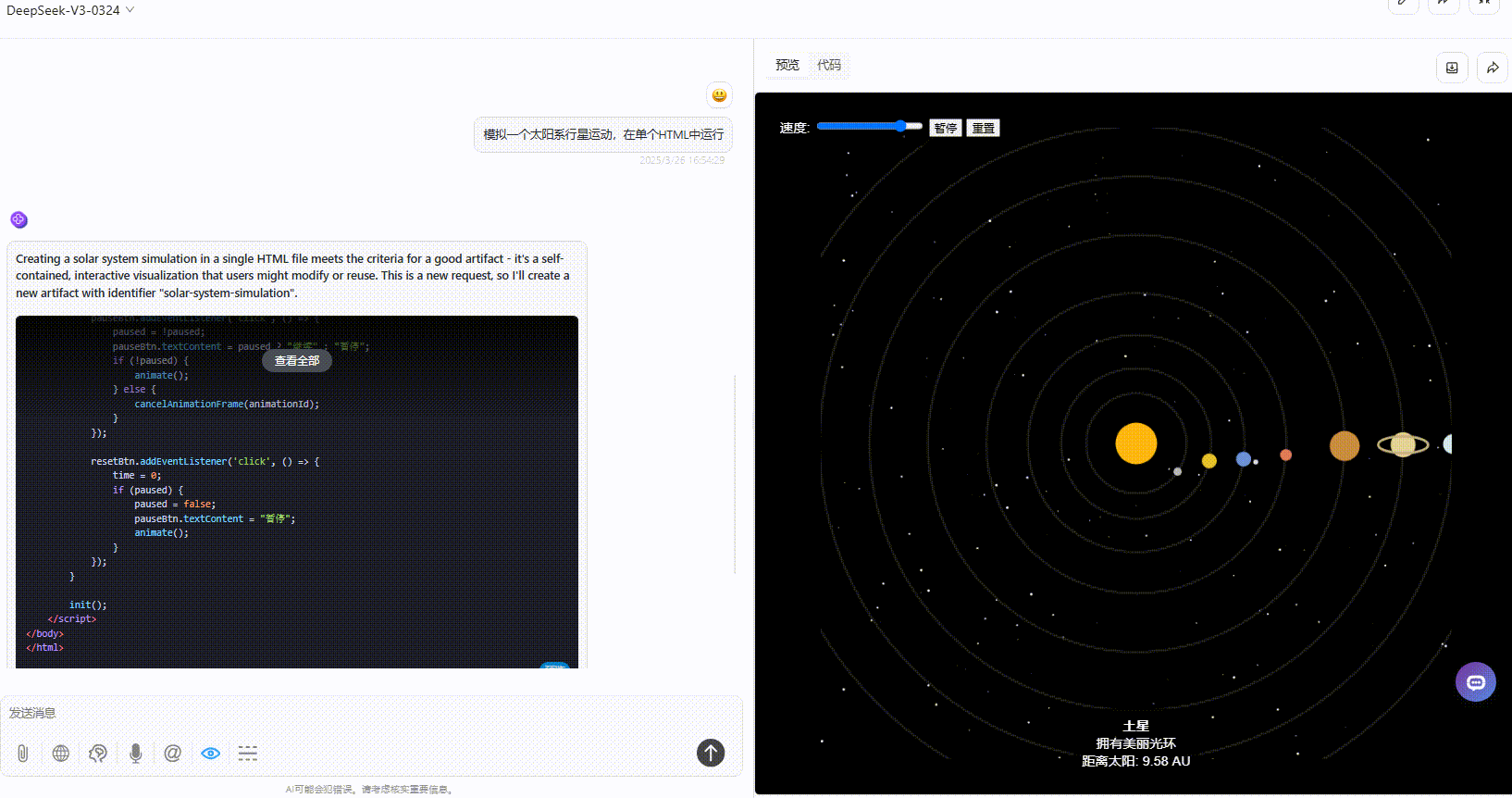
Gemini-2.5-Pro:效果没有太多的问题,但是对比其他模型较为单调。
Claude-3.7-sonnet:页面元素较丰富,但可惜只展示了四颗行星,效果不完整,不知模型是存在常识错误还是故意简化展示。
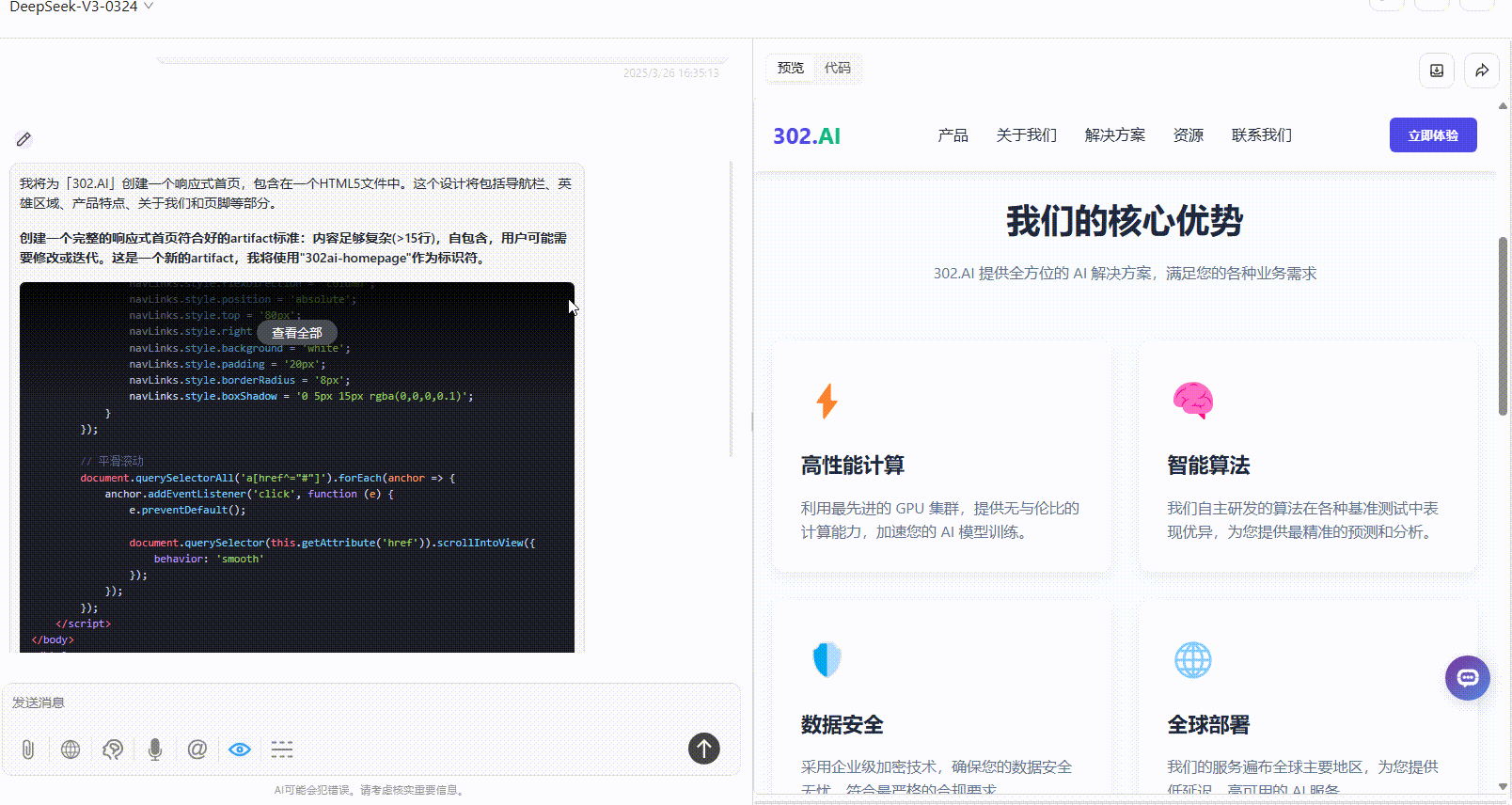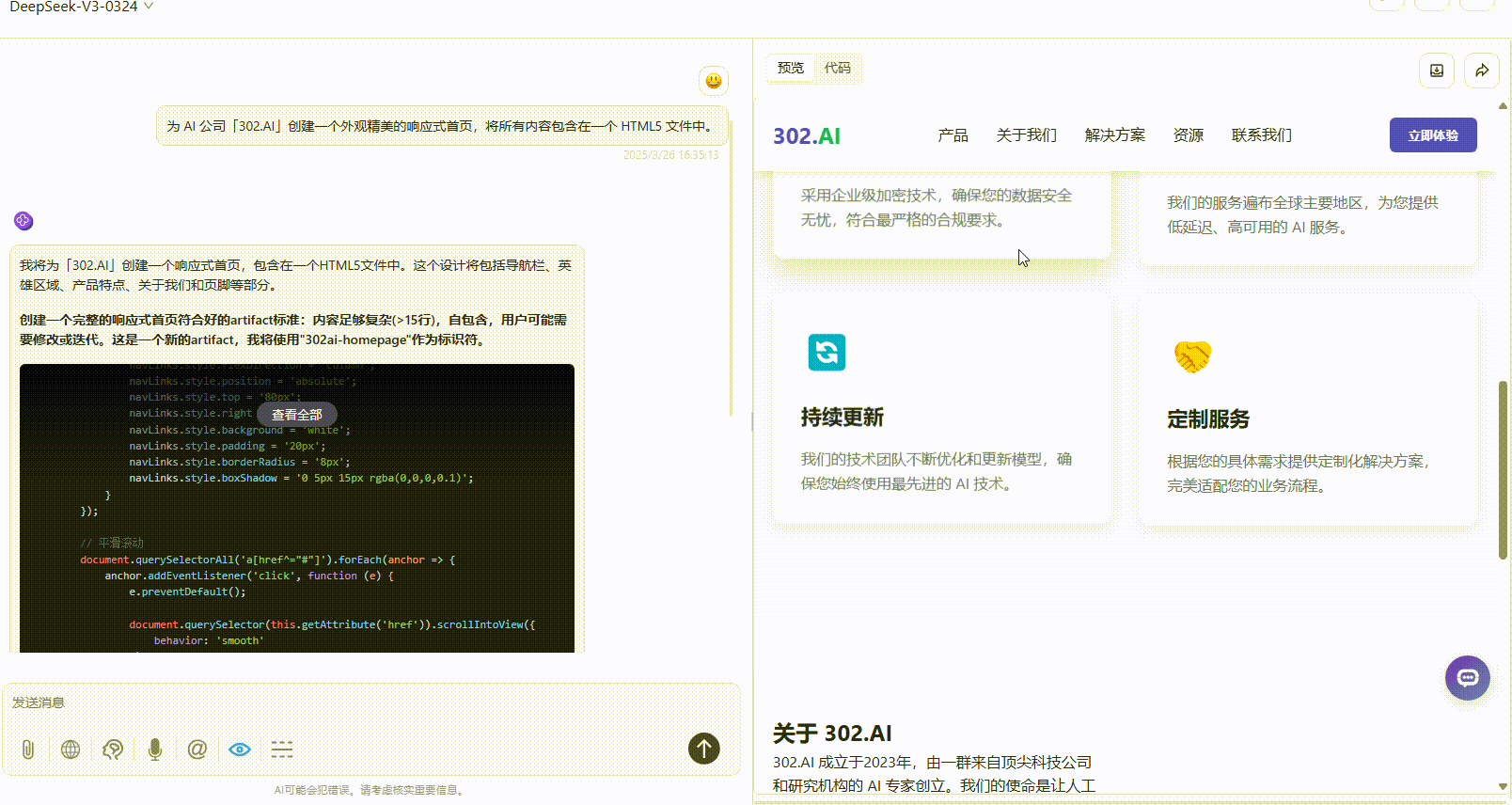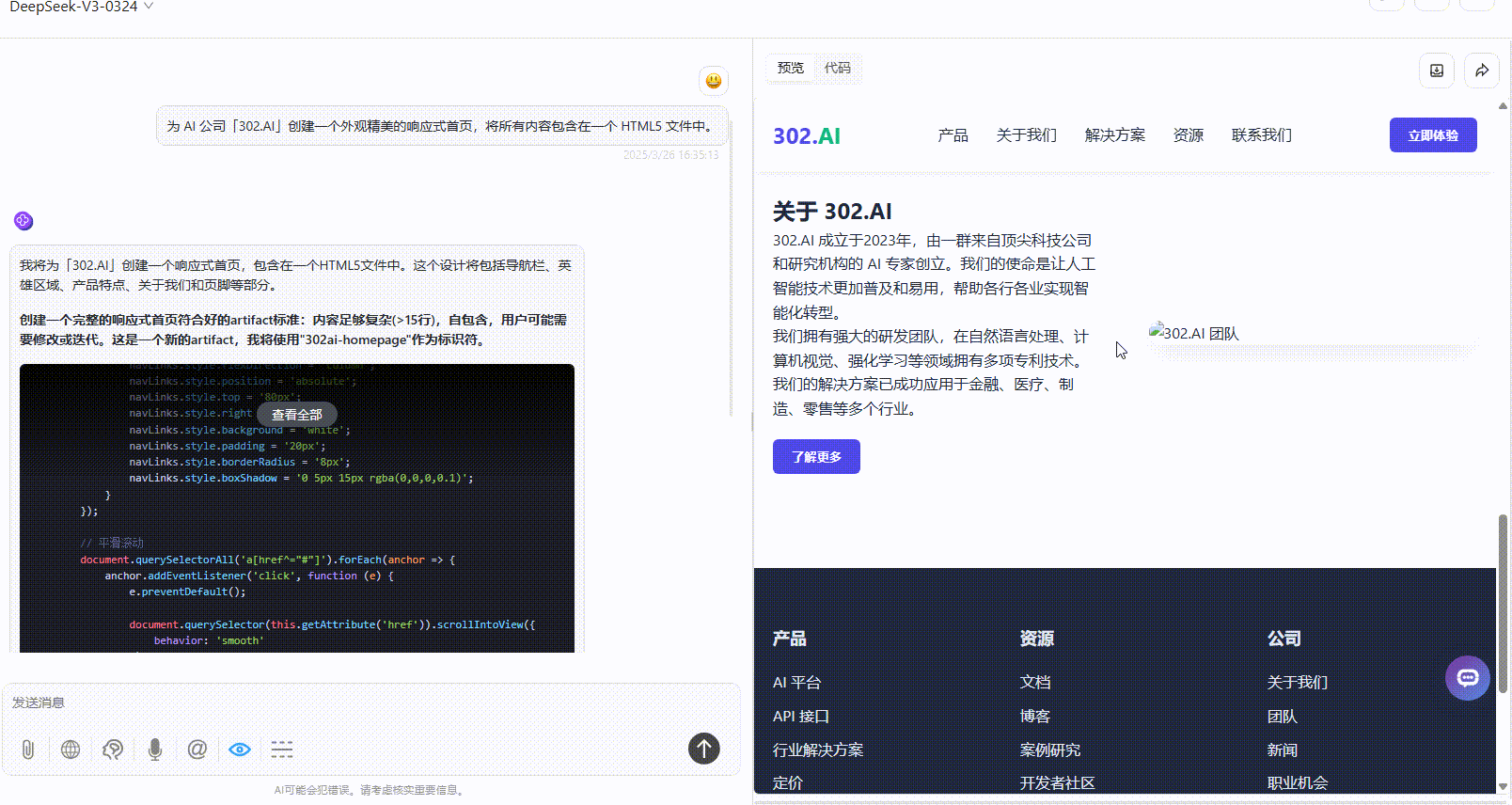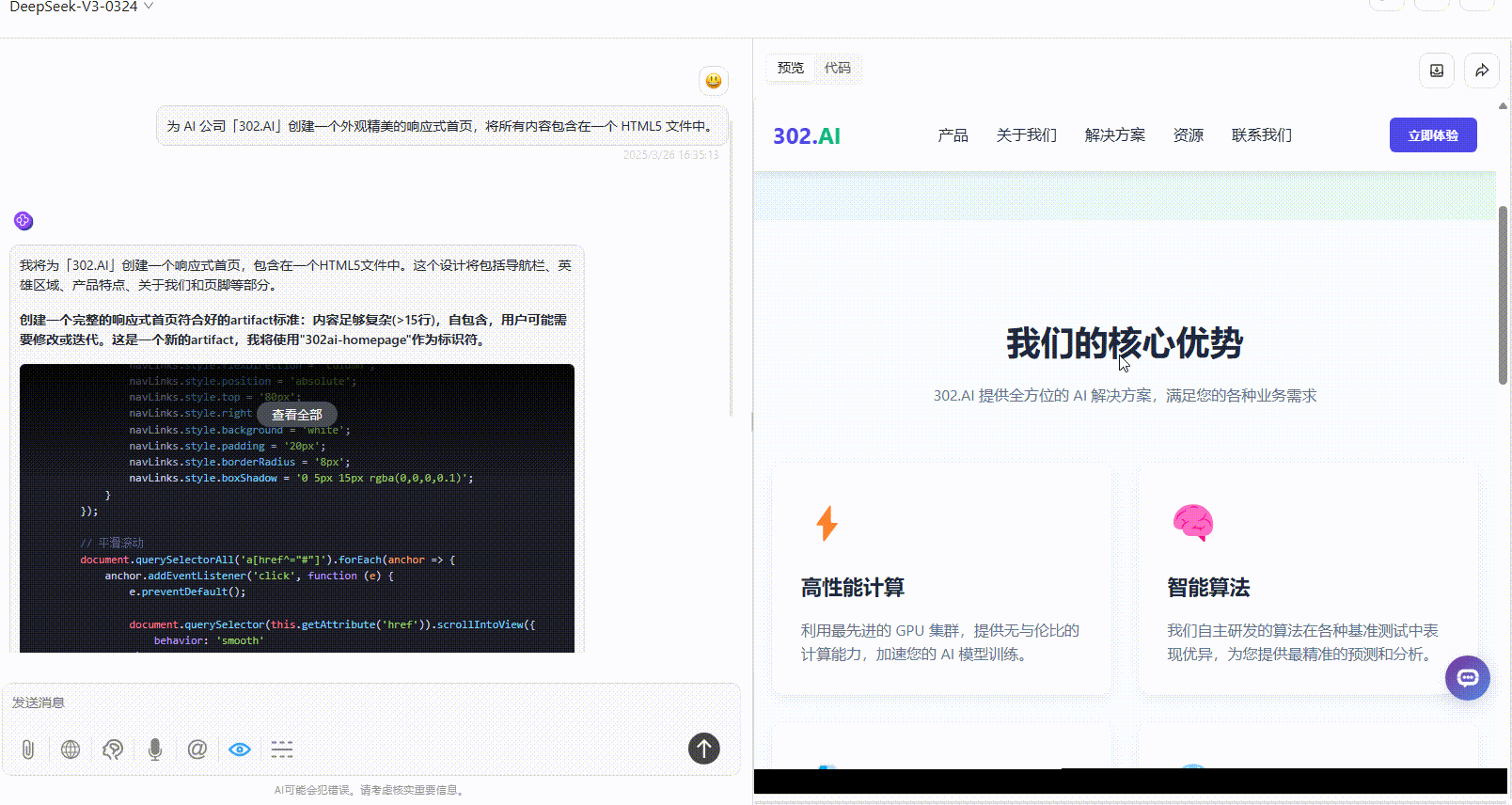
实测4:网页设计
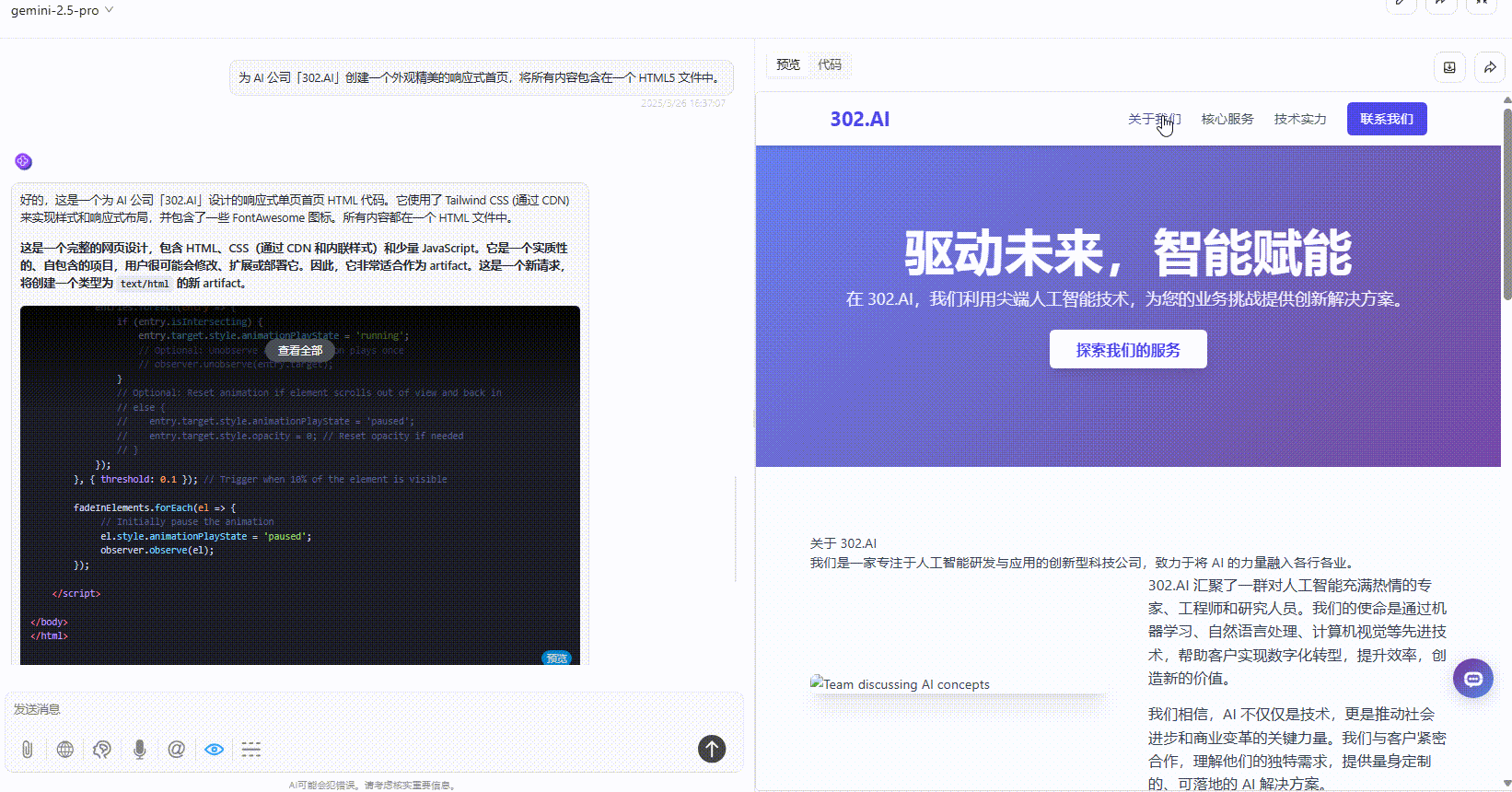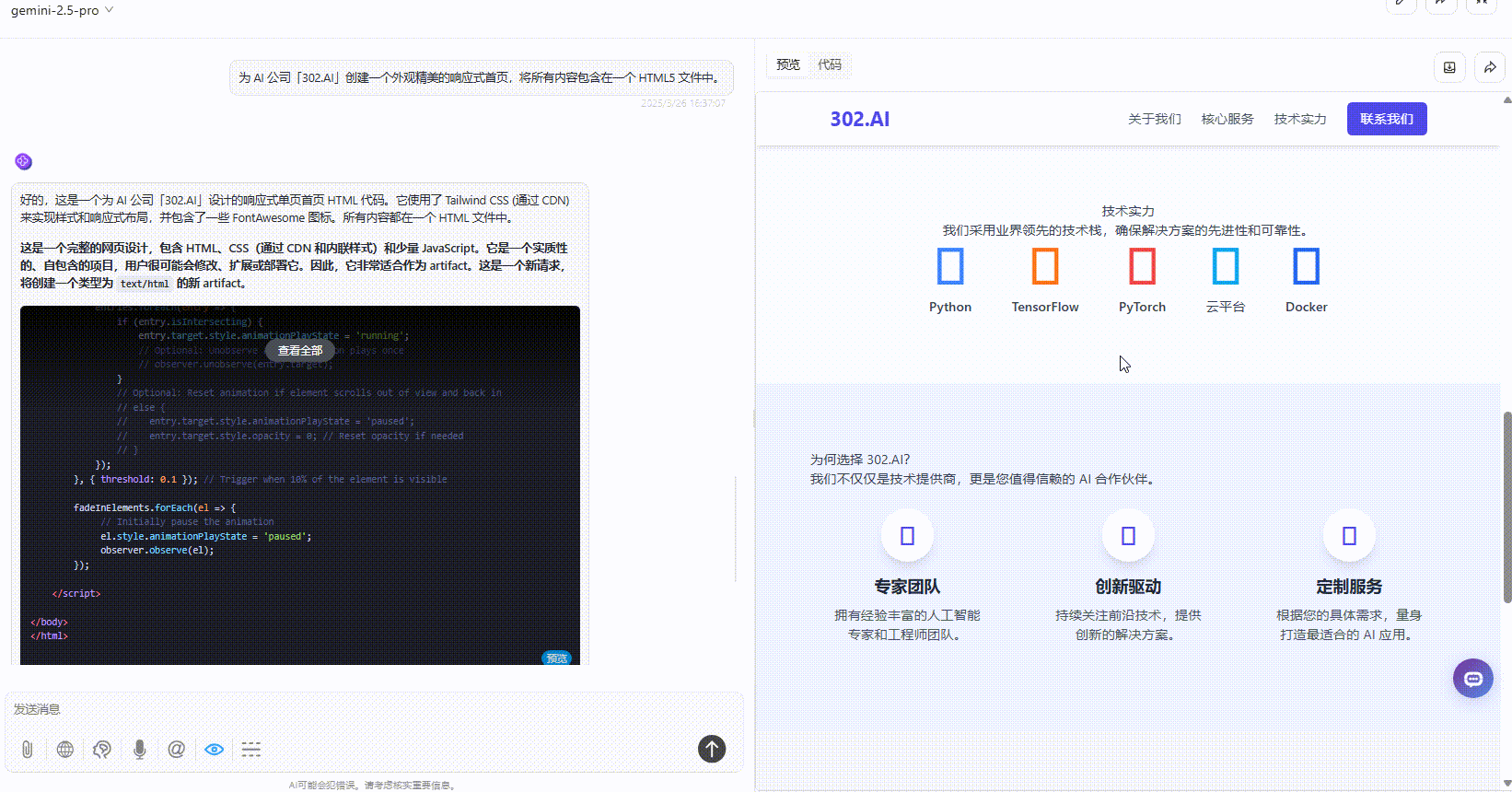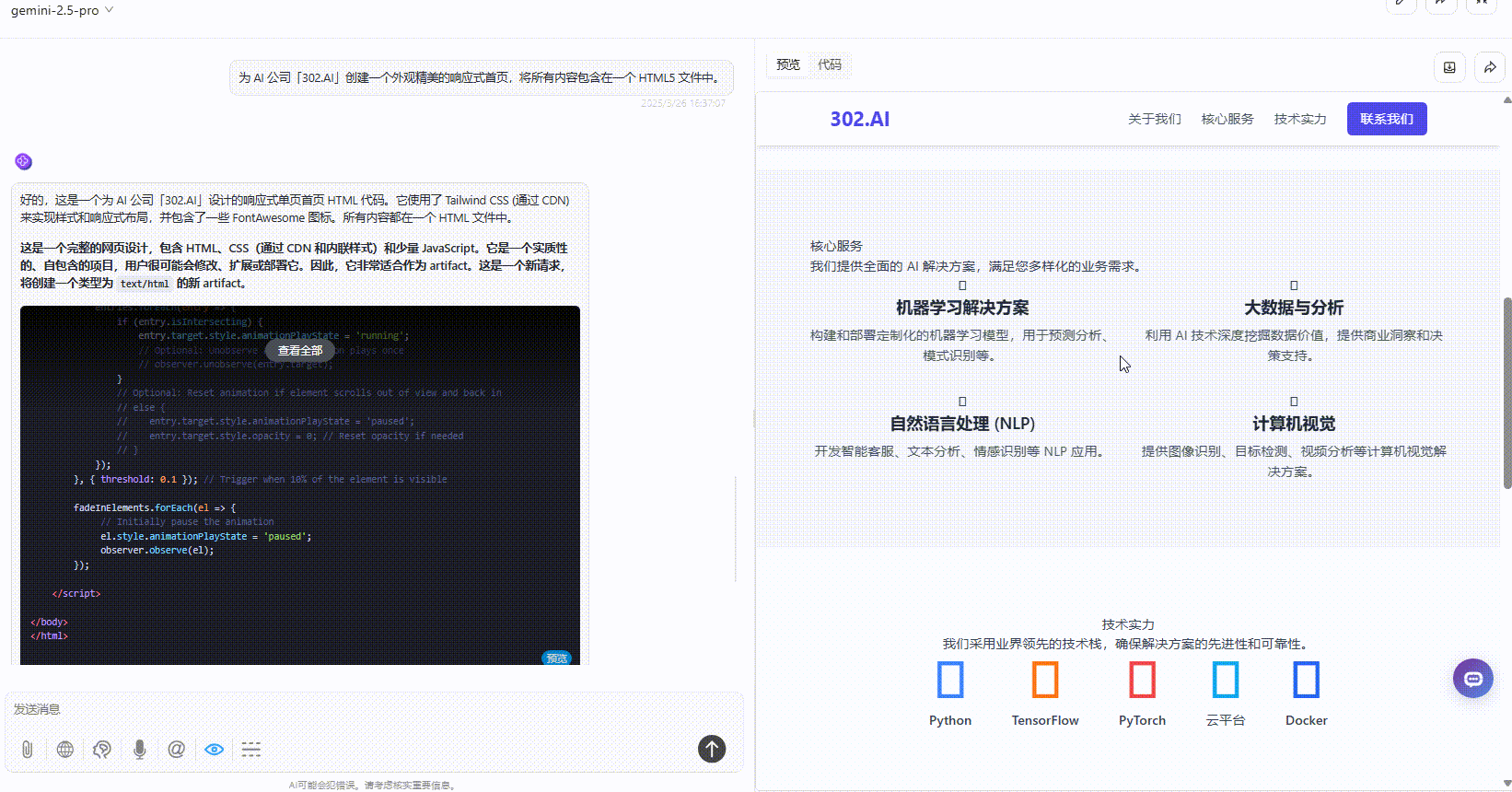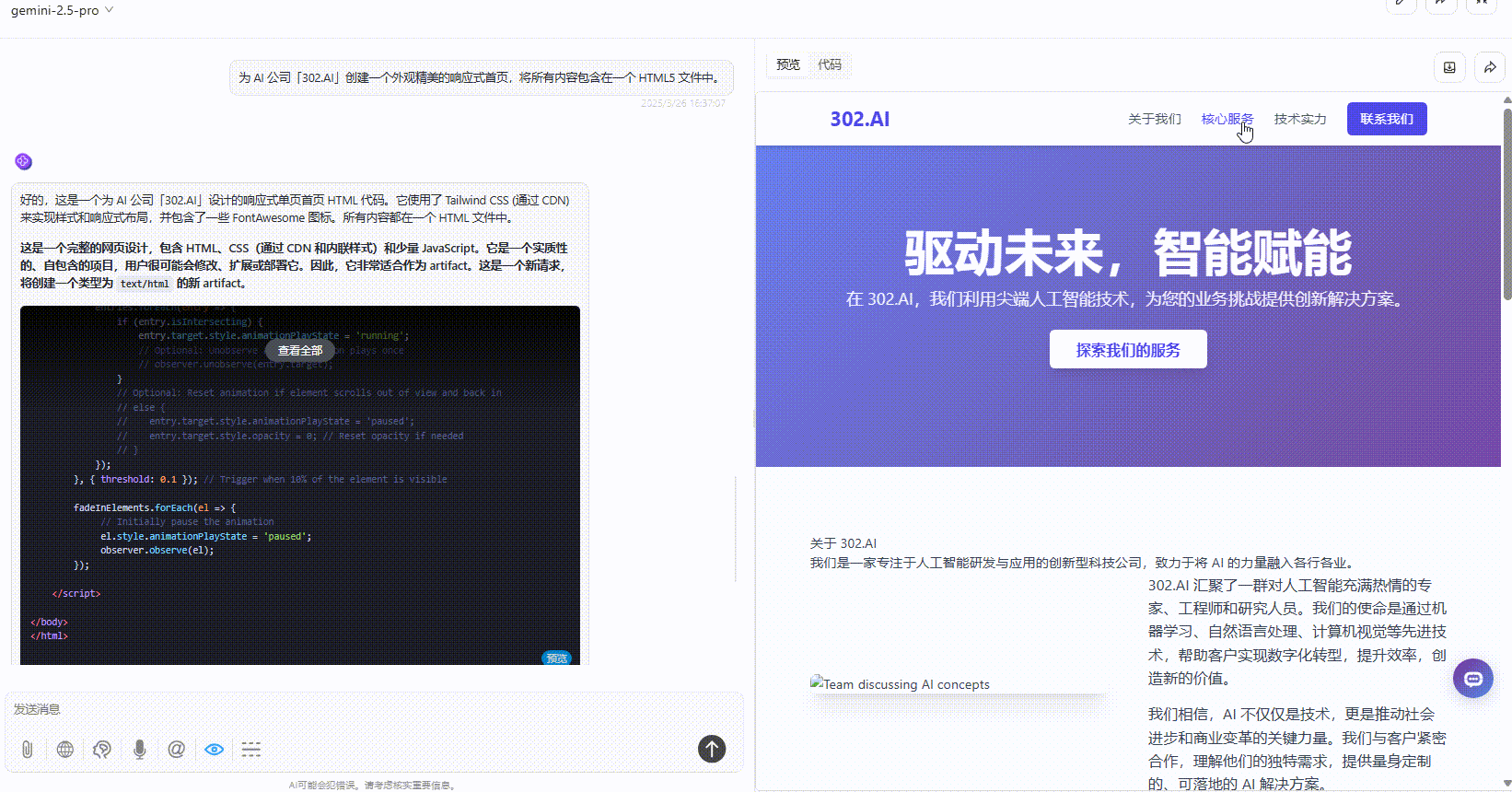
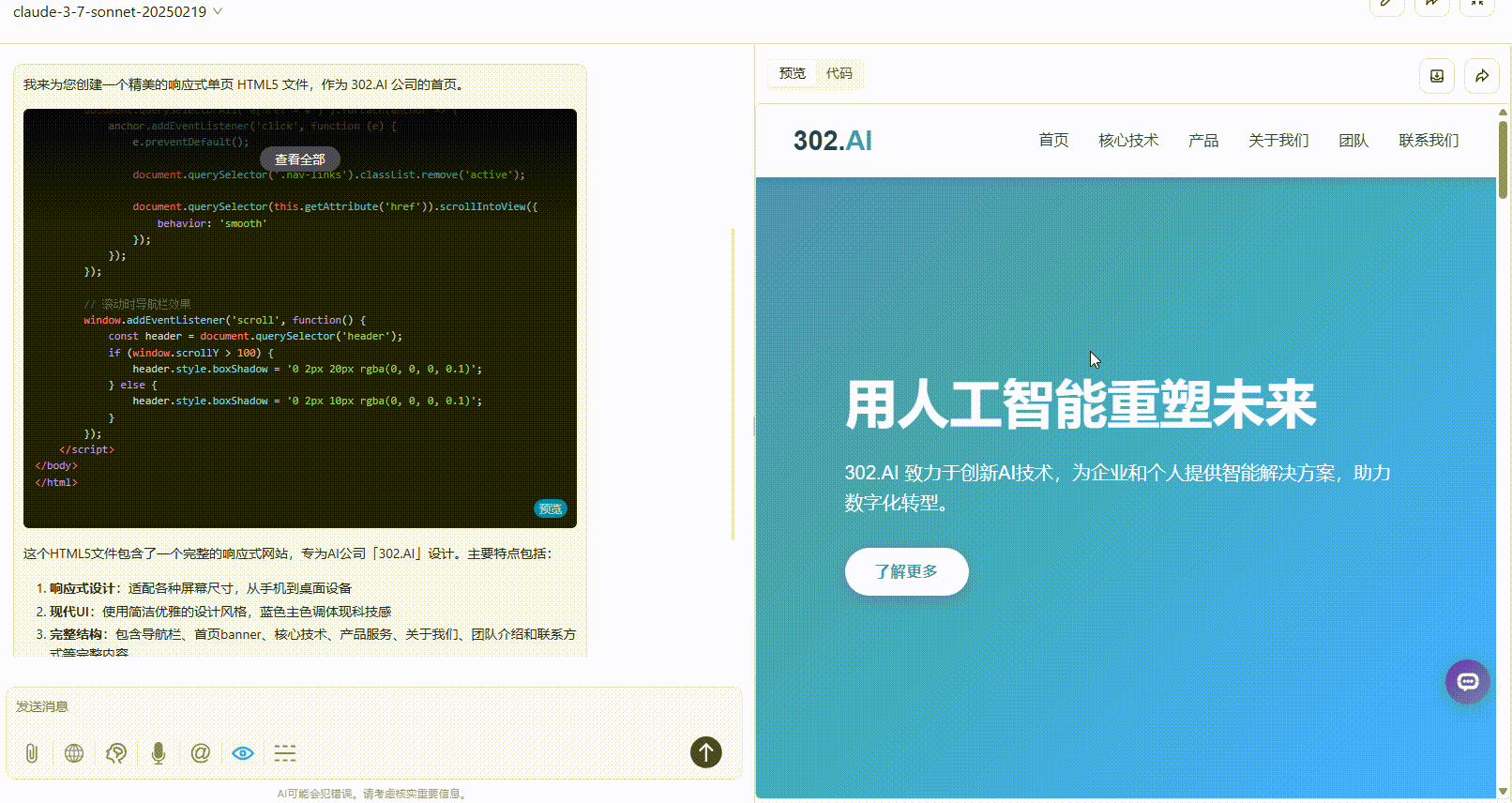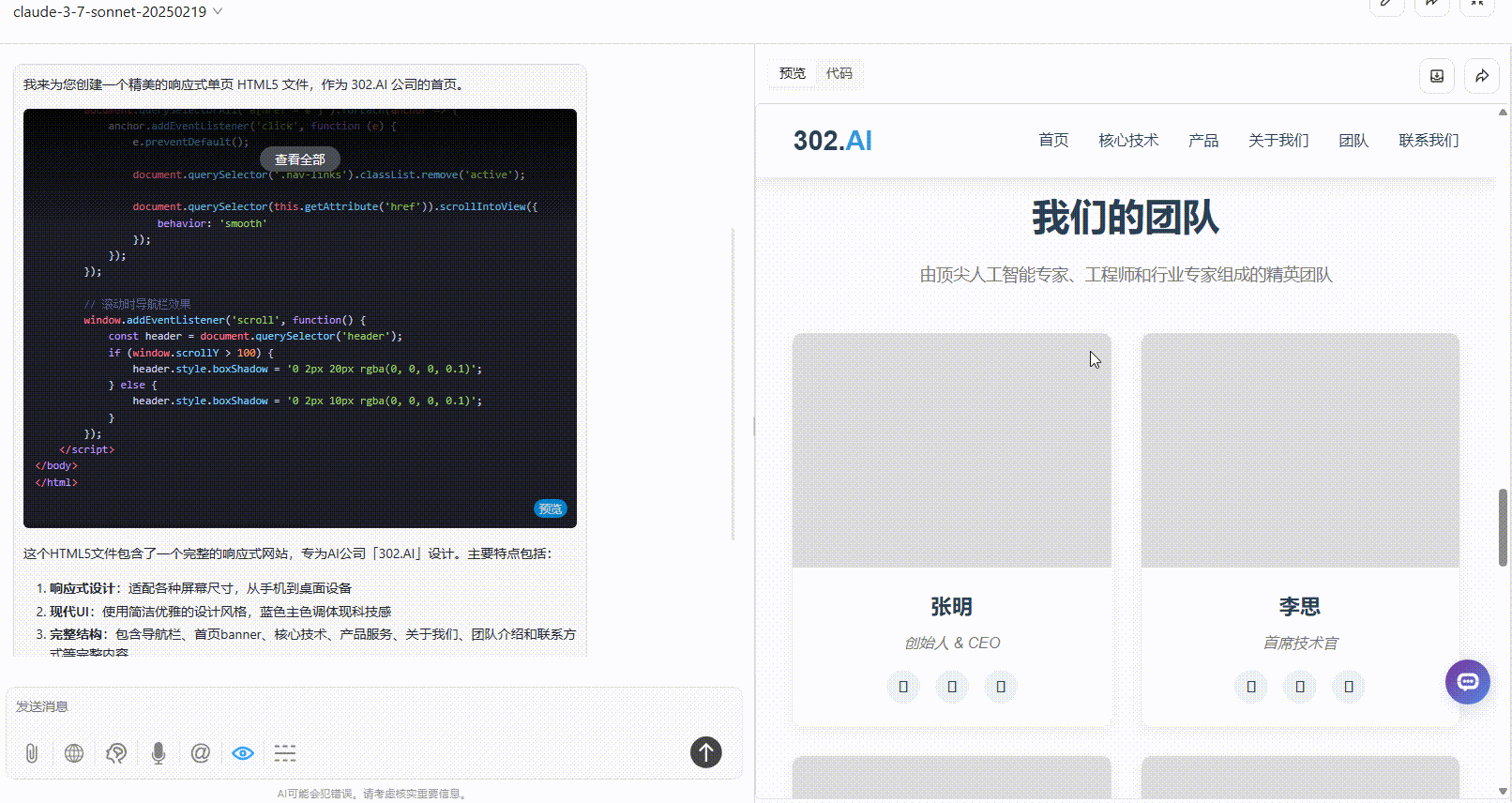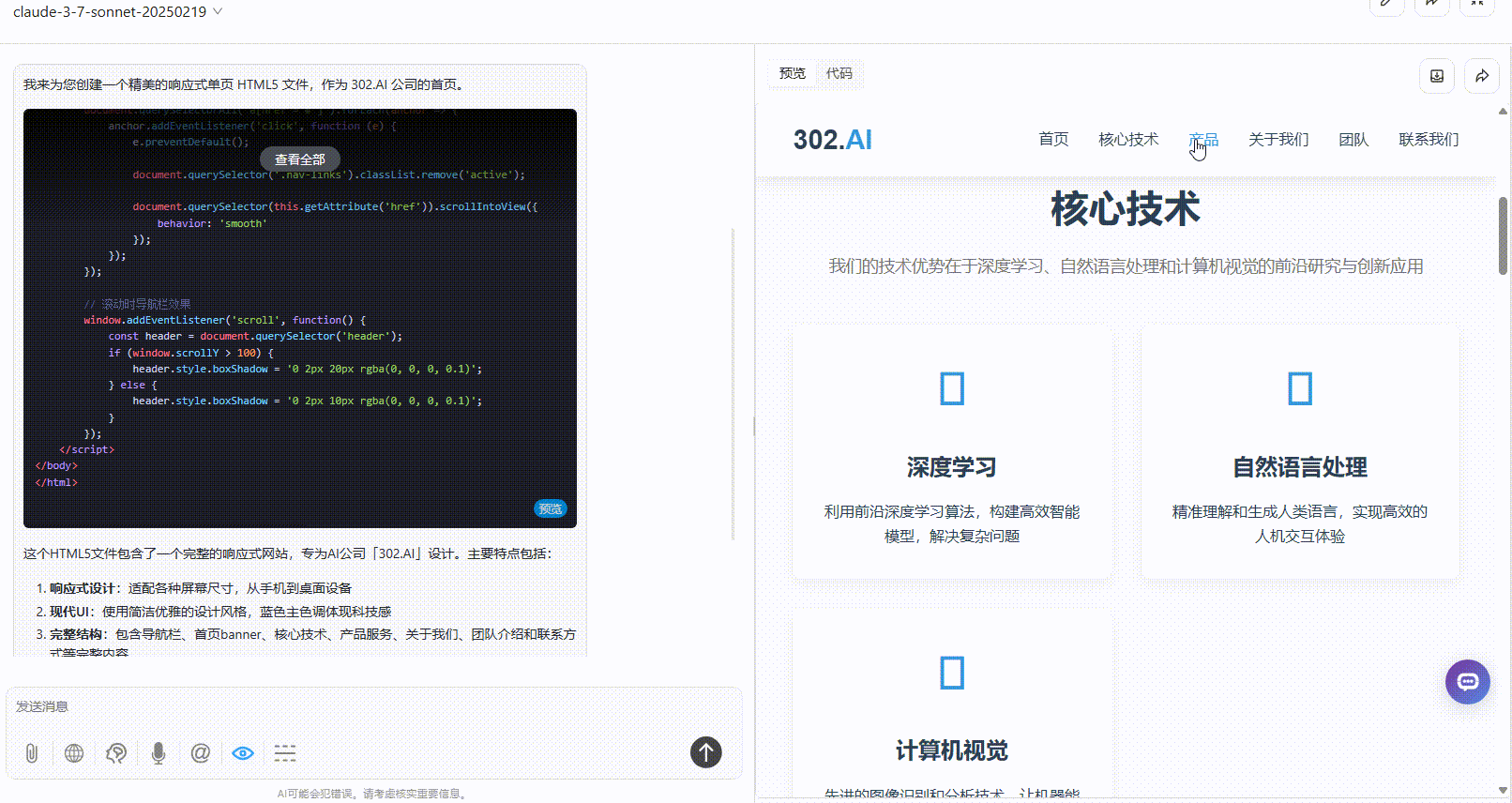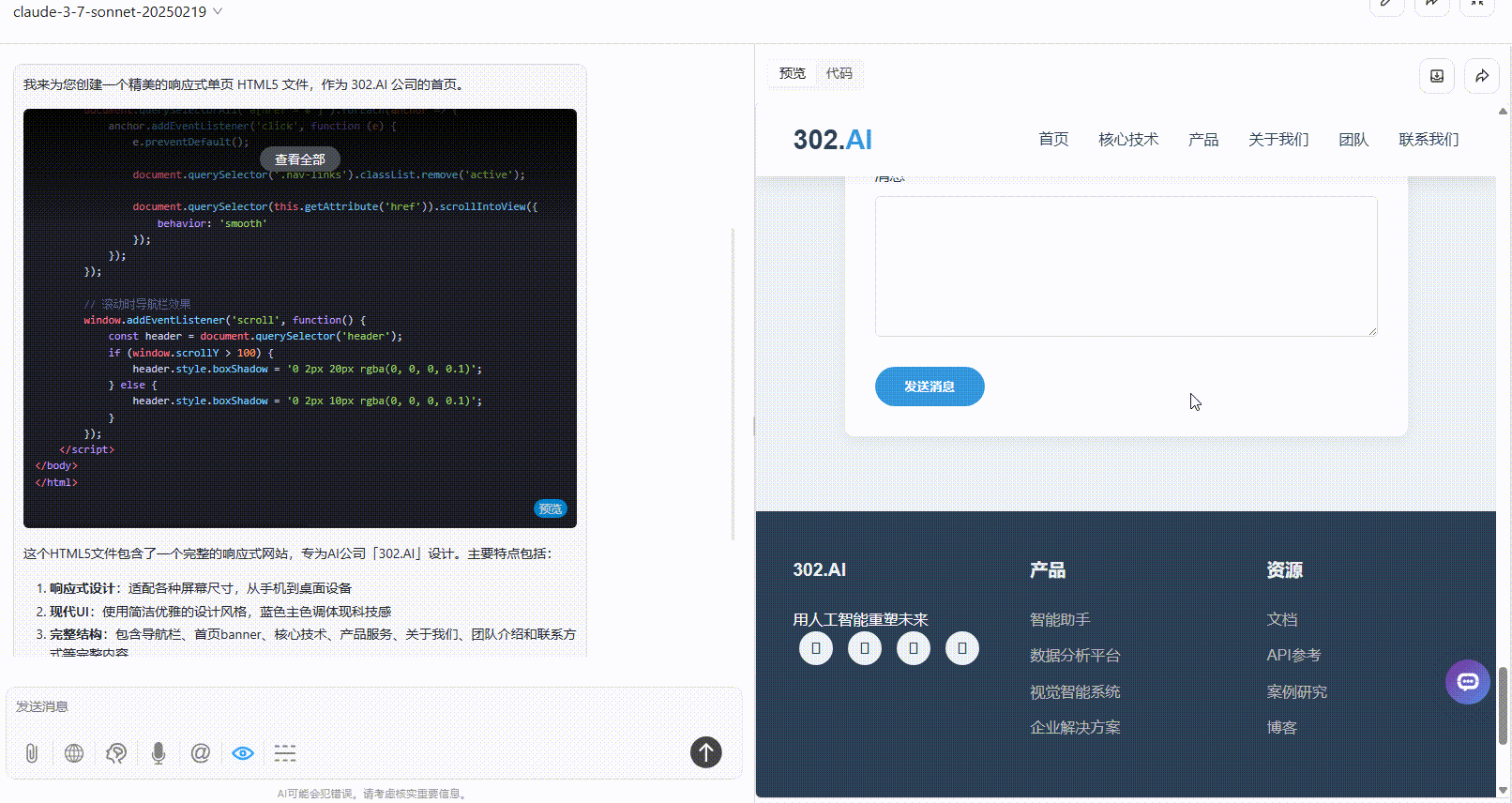
提示词:为 AI 公司「302.AI」创建一个外观精美的响应式首页,将所有内容包含在一个 HTML5 文件中。
优劣排名:DeepSeek-V3.1>Claude-3.7-sonnet>Gemini-2.5-Pro
DeepSeek-V3.1:内容匹配度很高,色彩协调且美观,给人一种干净利落的视觉感受,效果很惊艳。
Gemini-2.5-Pro:色彩搭配还算协调,但页面文字过多视觉上较为繁杂。
Claude-3.7-sonnet:布局较协调、内容丰富,视觉上整体比Gemini好一点,但不及DeepSeek。
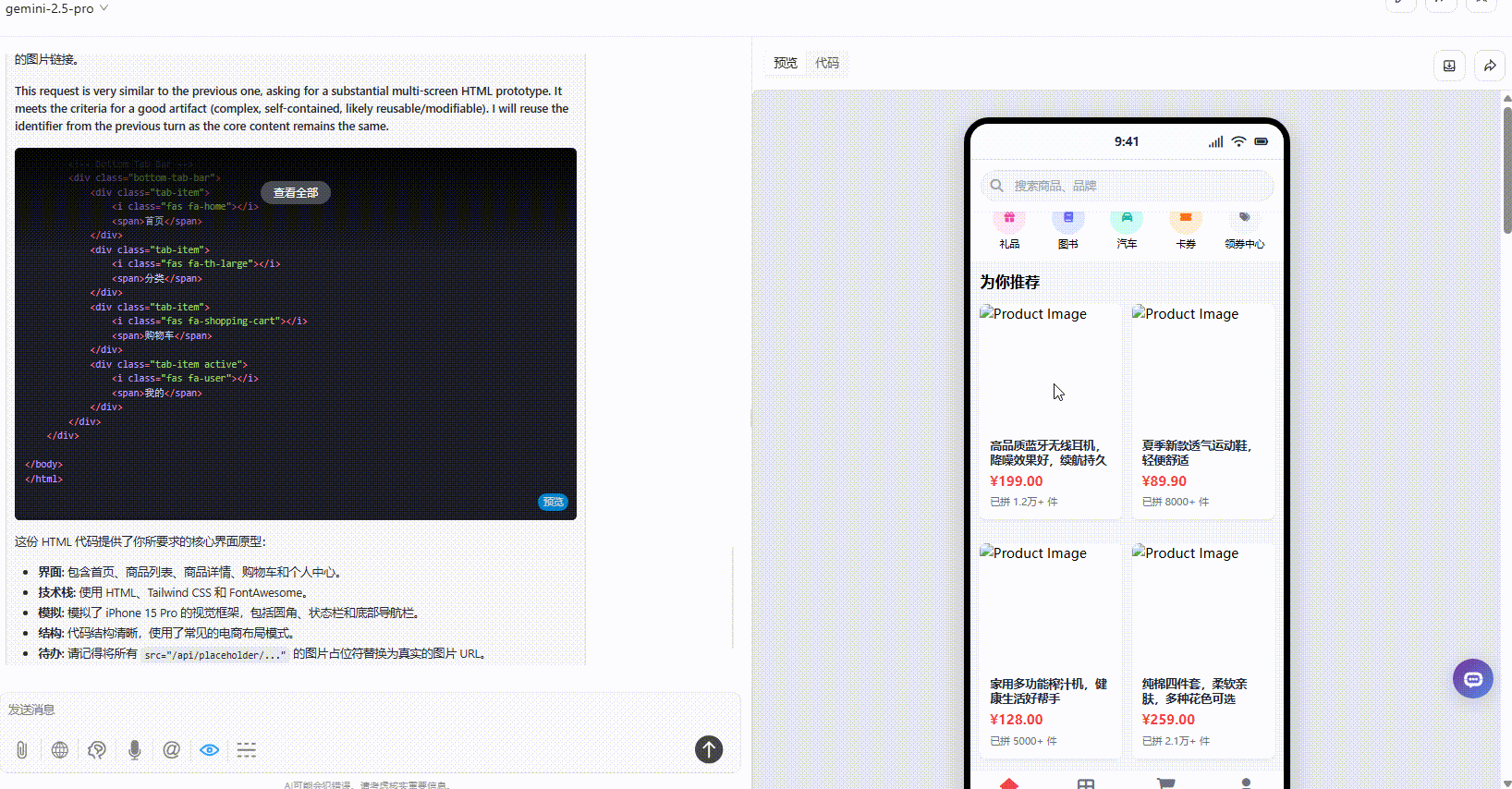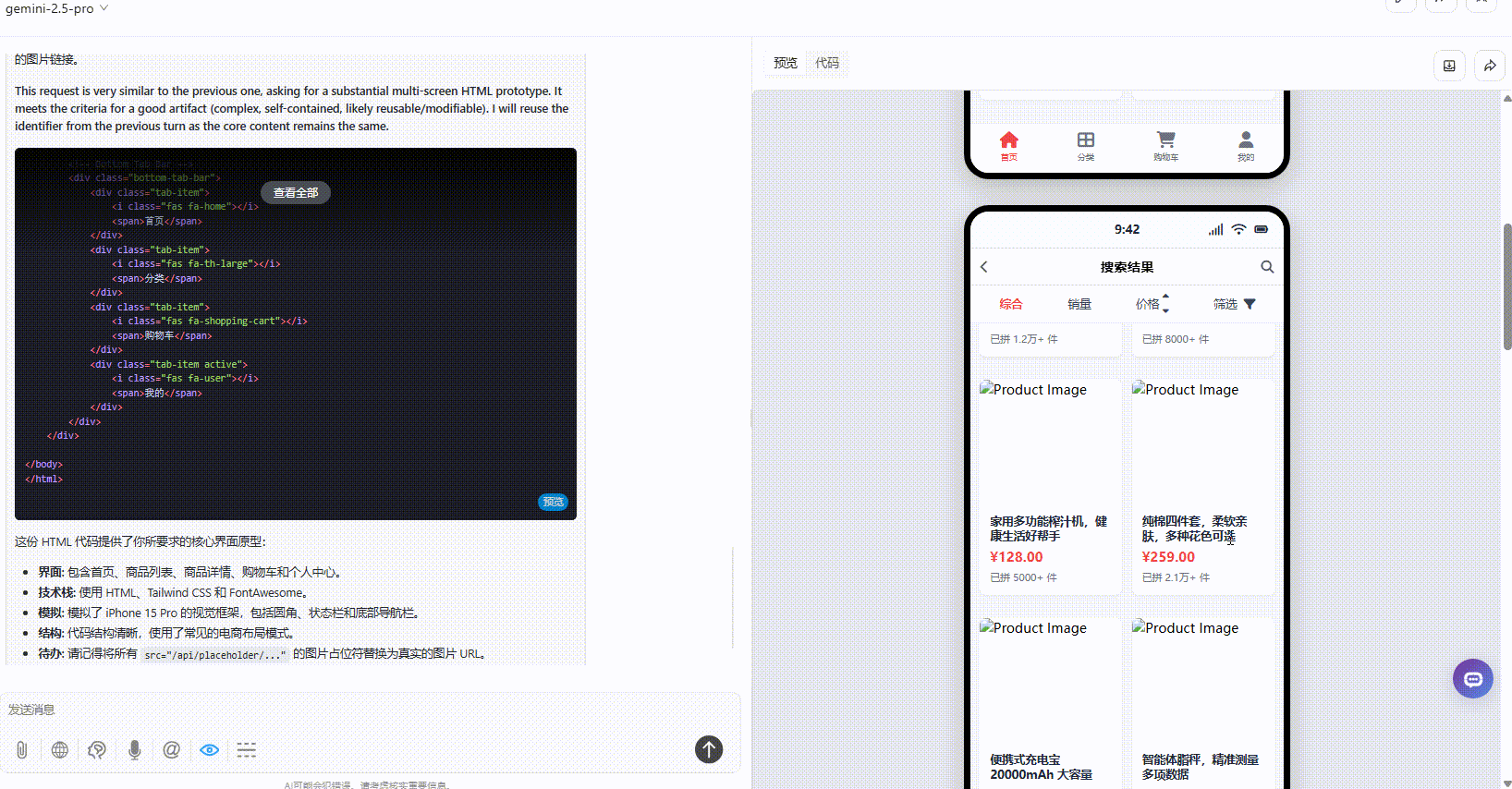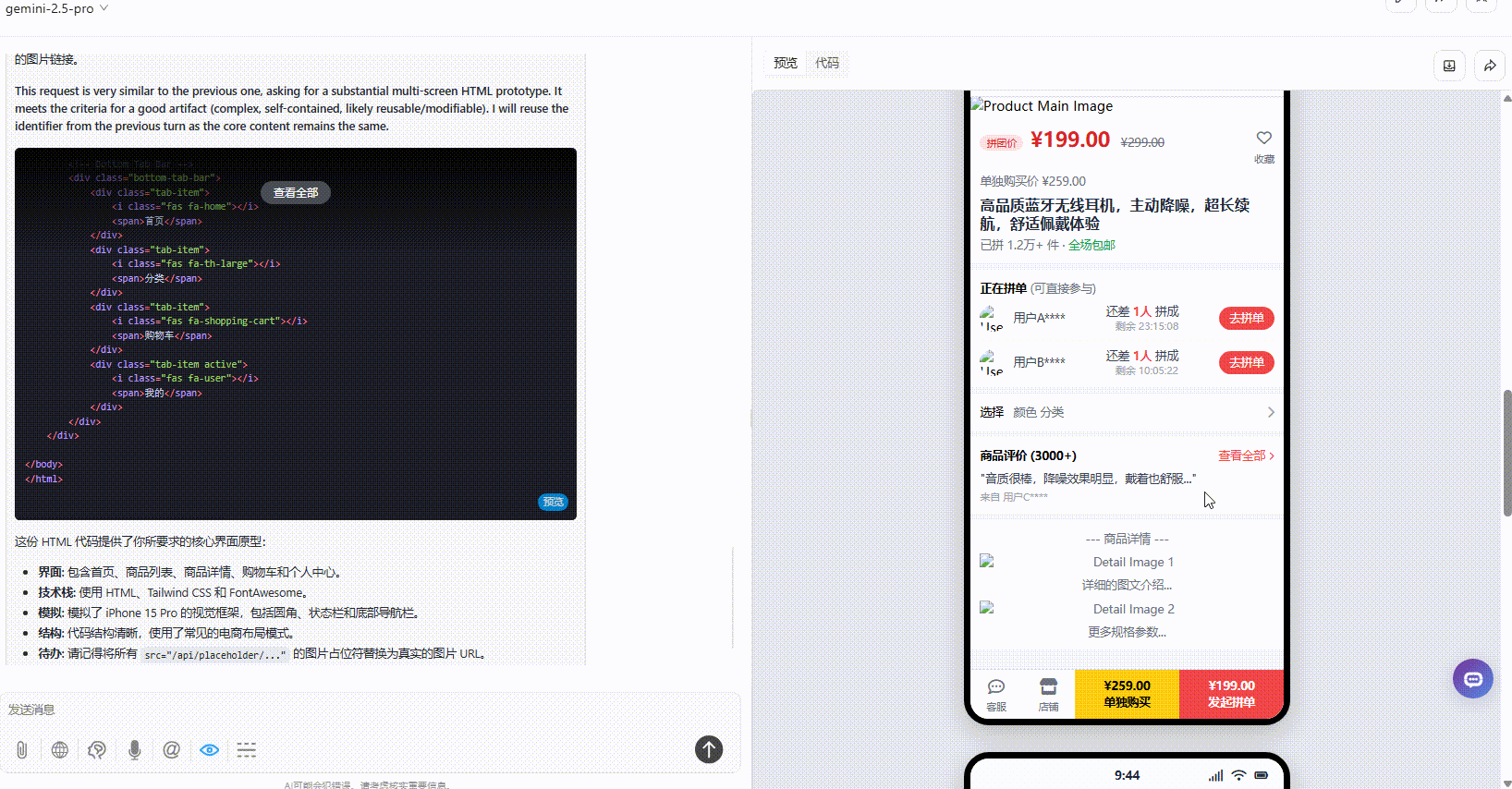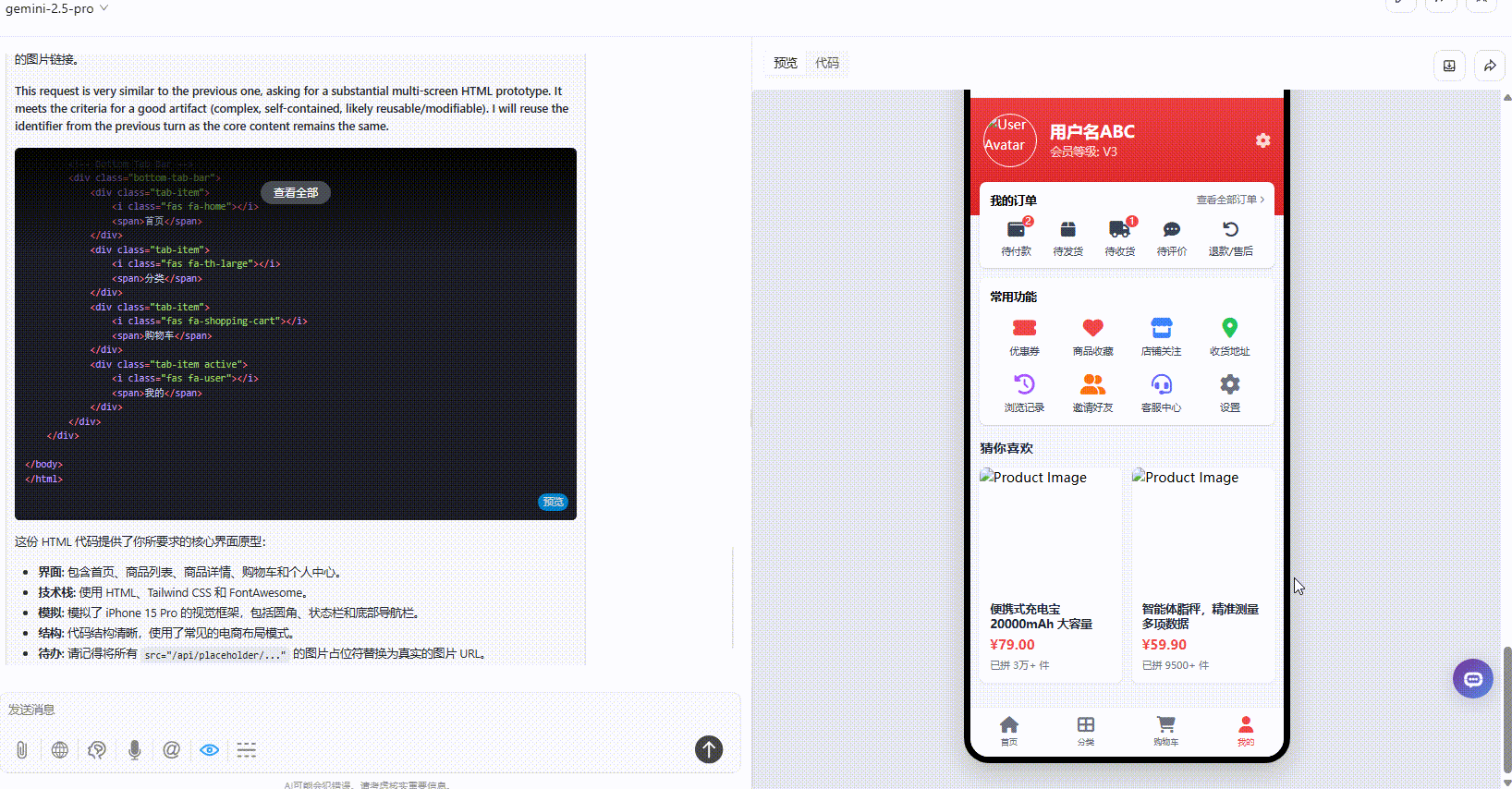
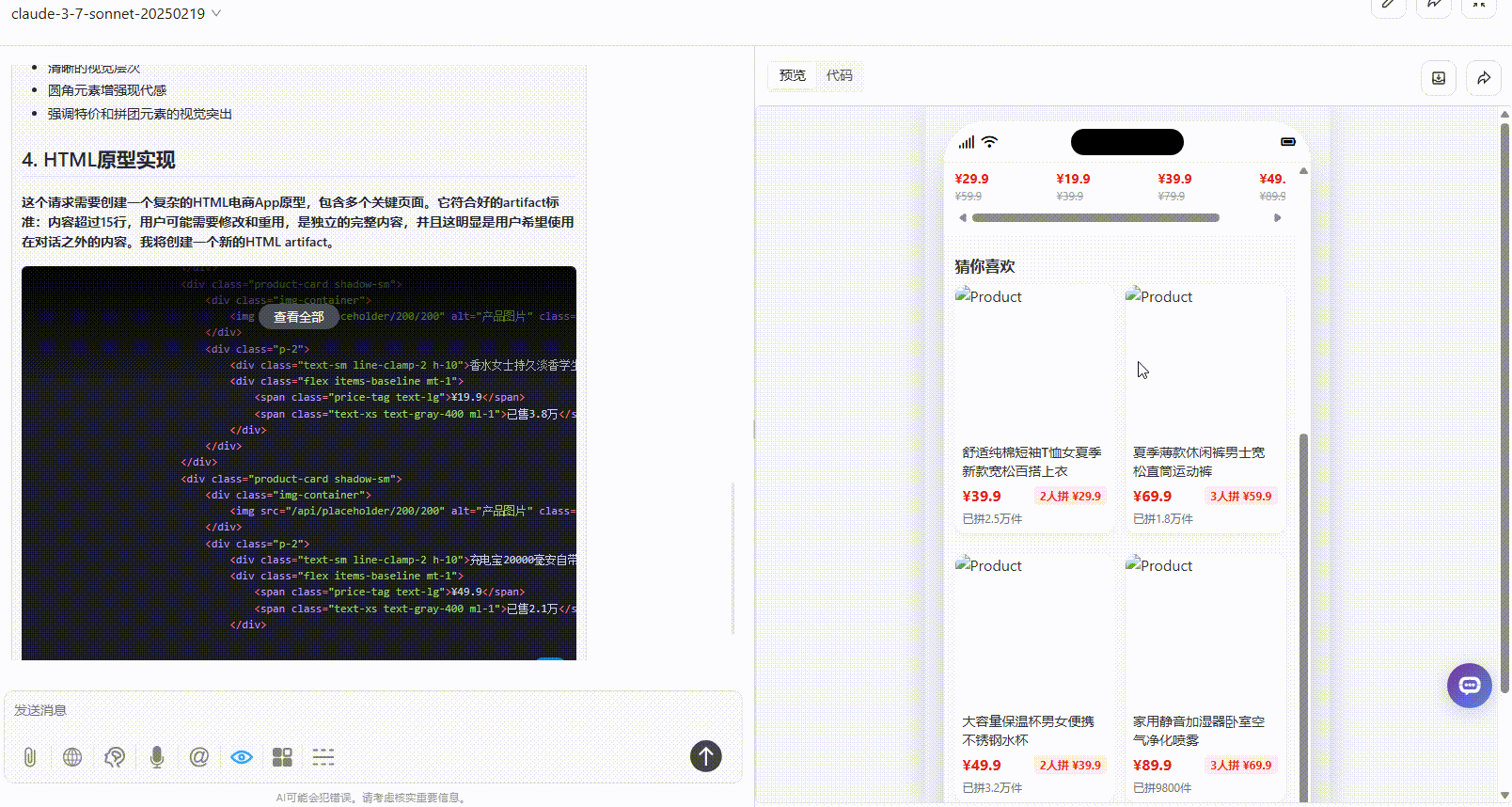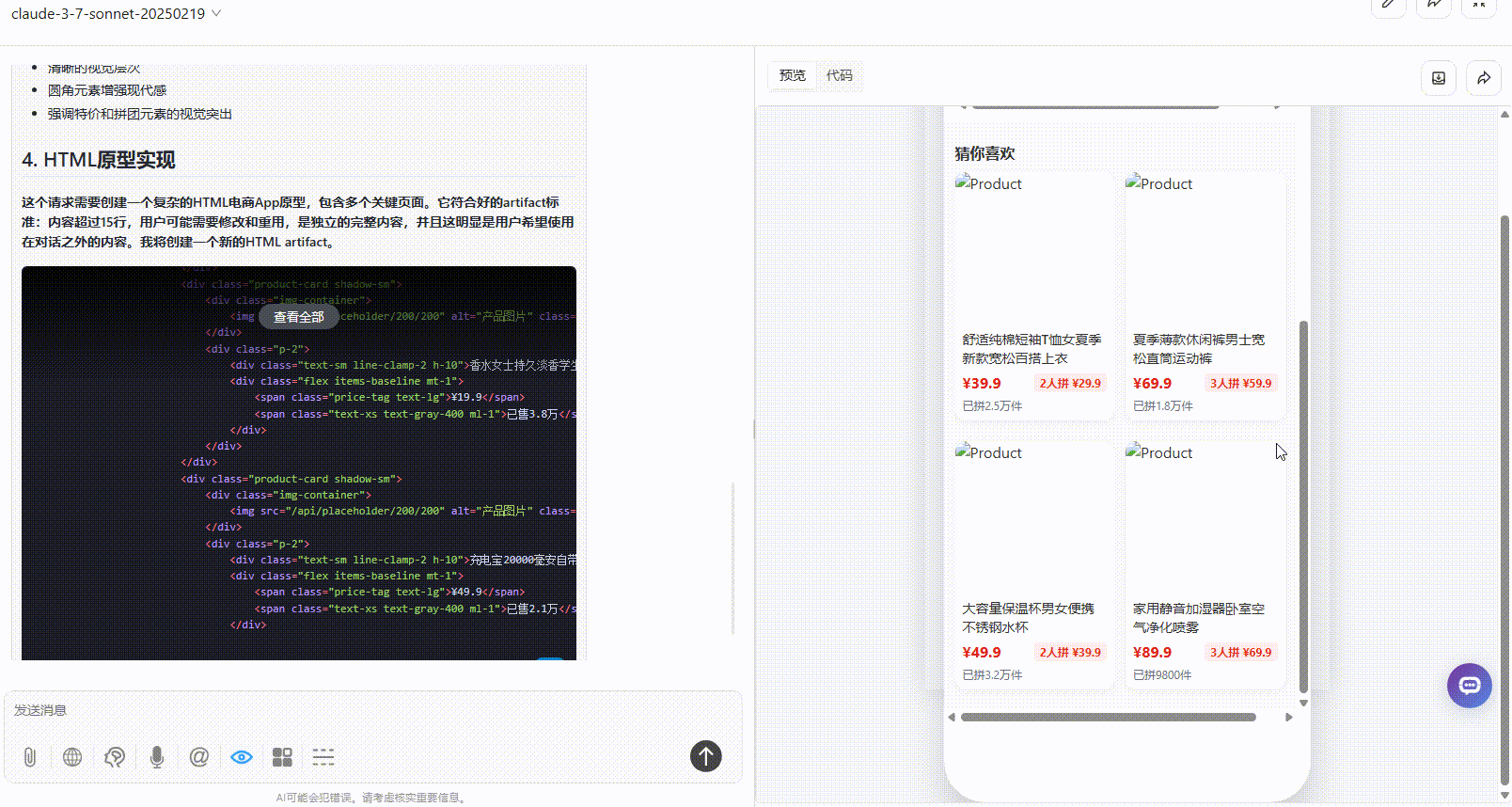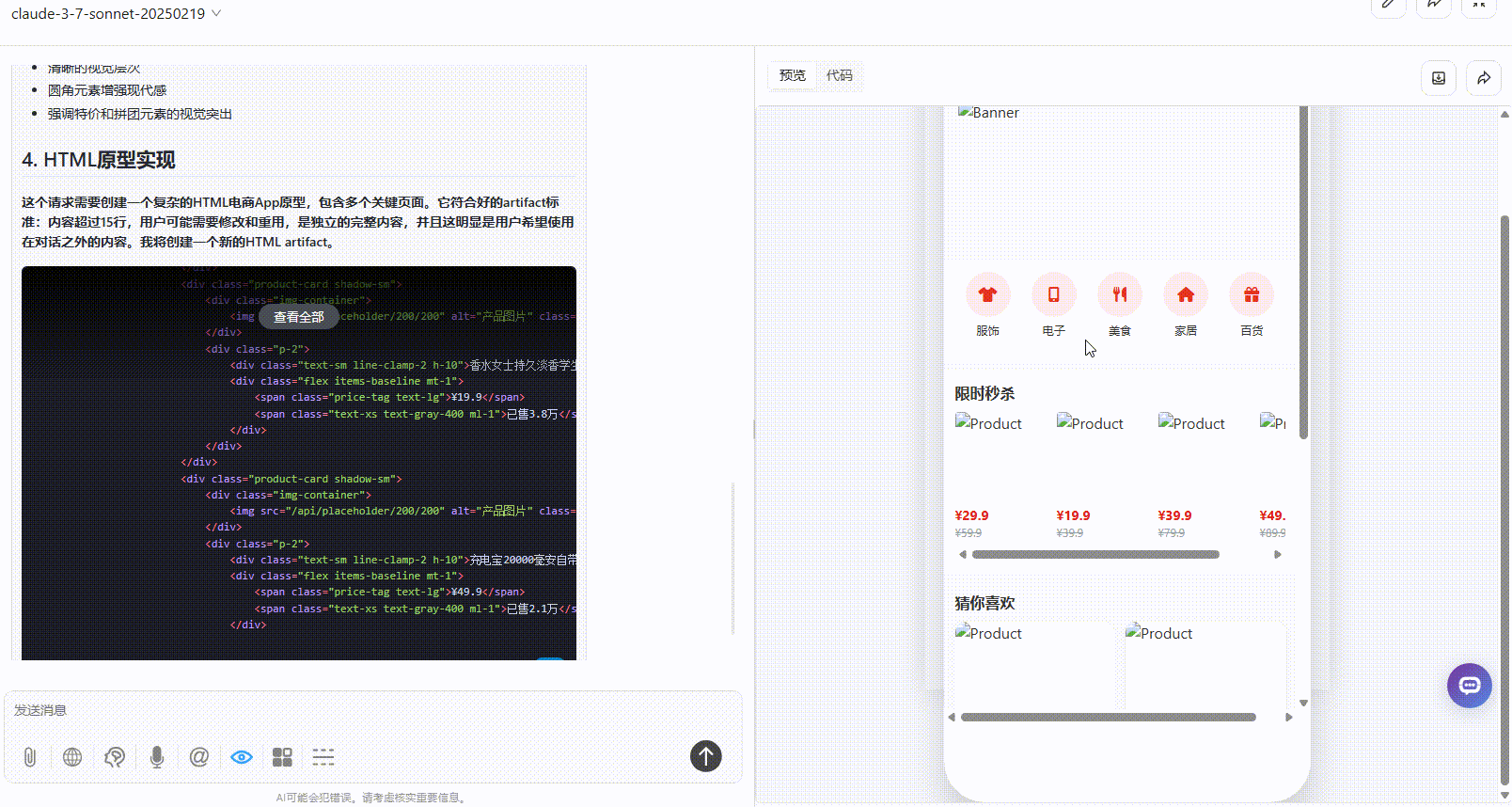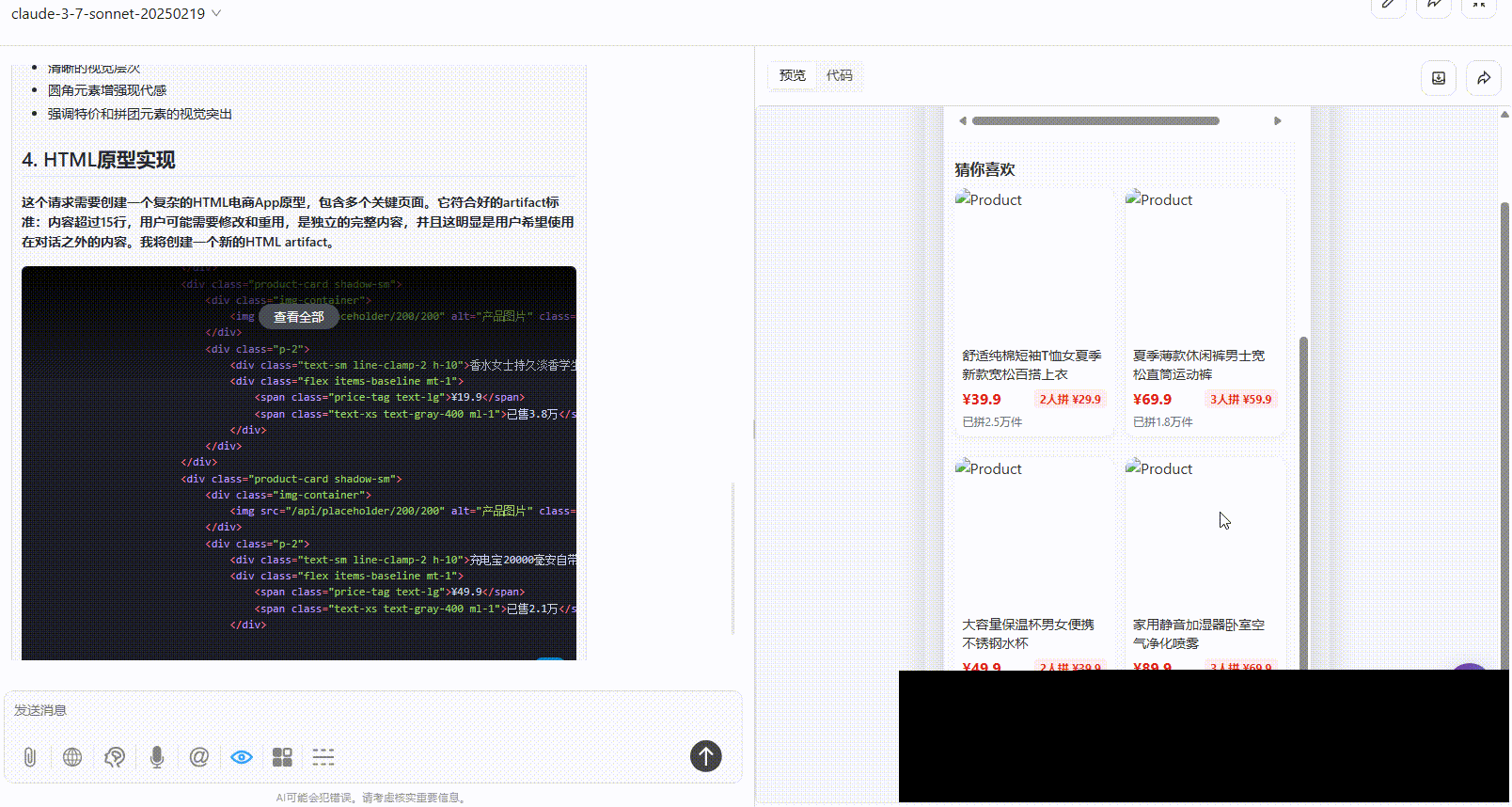
实测5:手机APP原型设计
提示词:

优劣排名:DeepSeek-V3.1>Gemini-2.5-Pro>Claude-3.7-sonnet
DeepSeek-V3.1:真实感较强的原型设计图,与其他两个模型效果对比,交互性更强,不过在购物车页面稍有瑕疵。
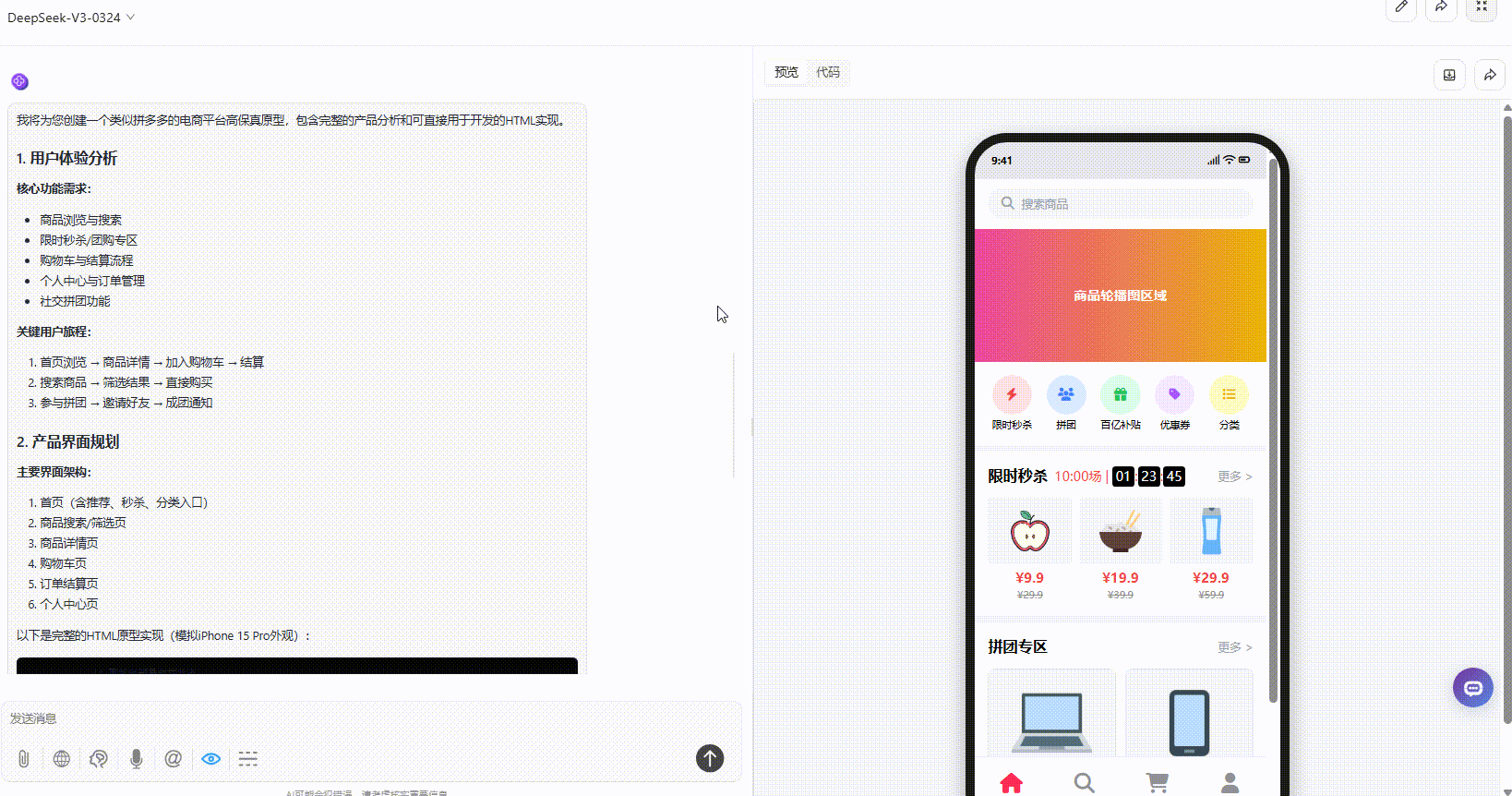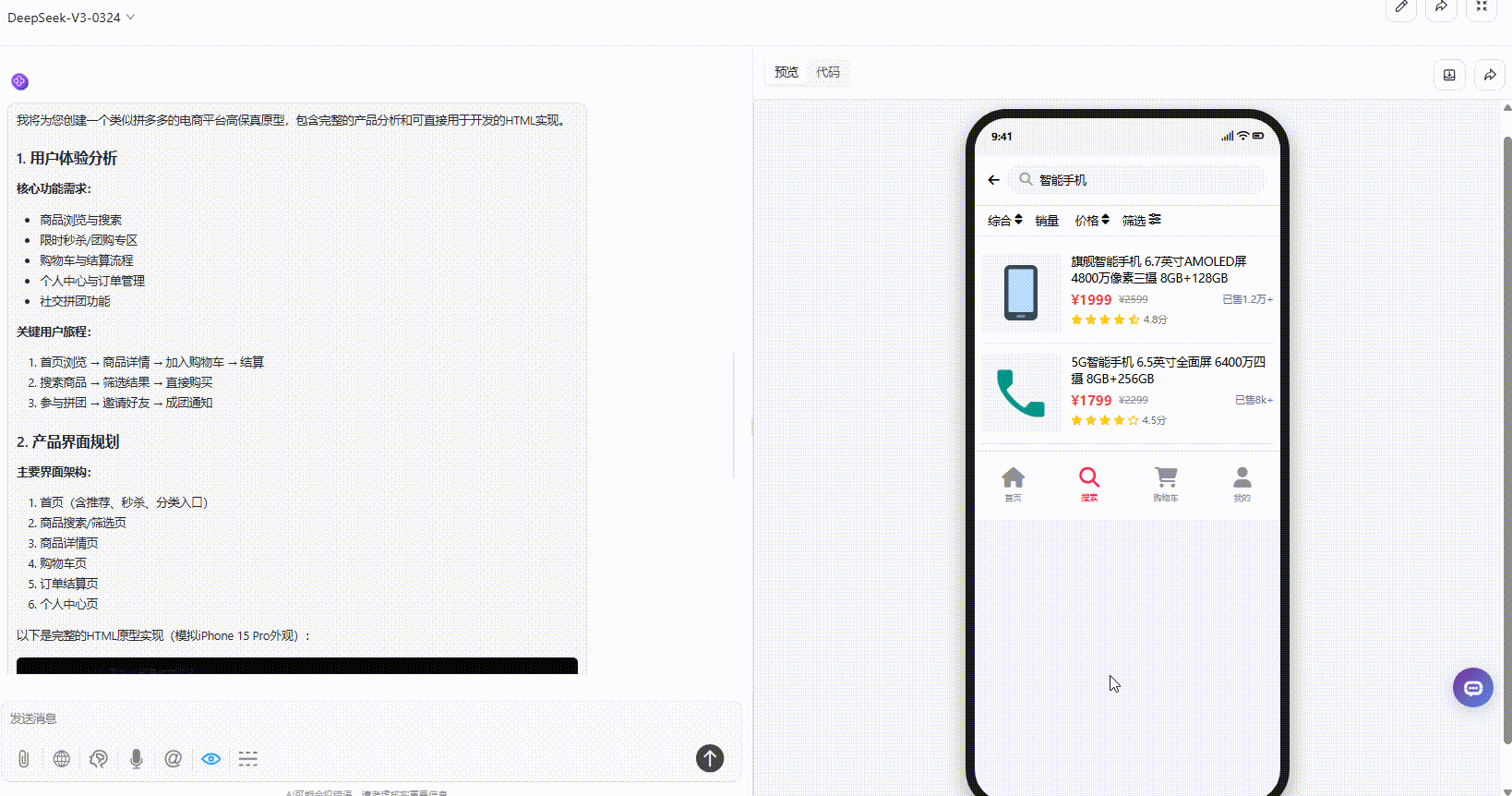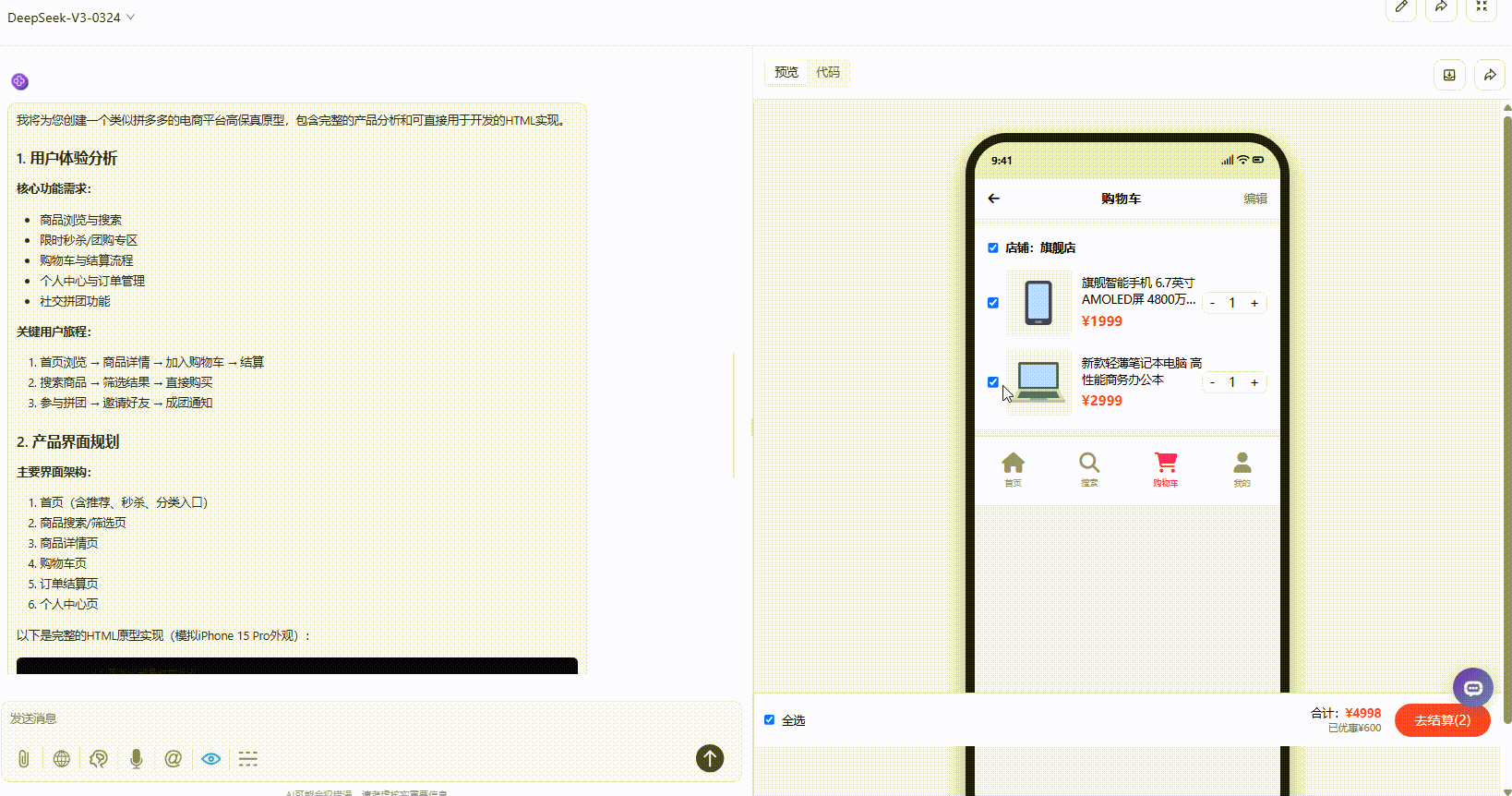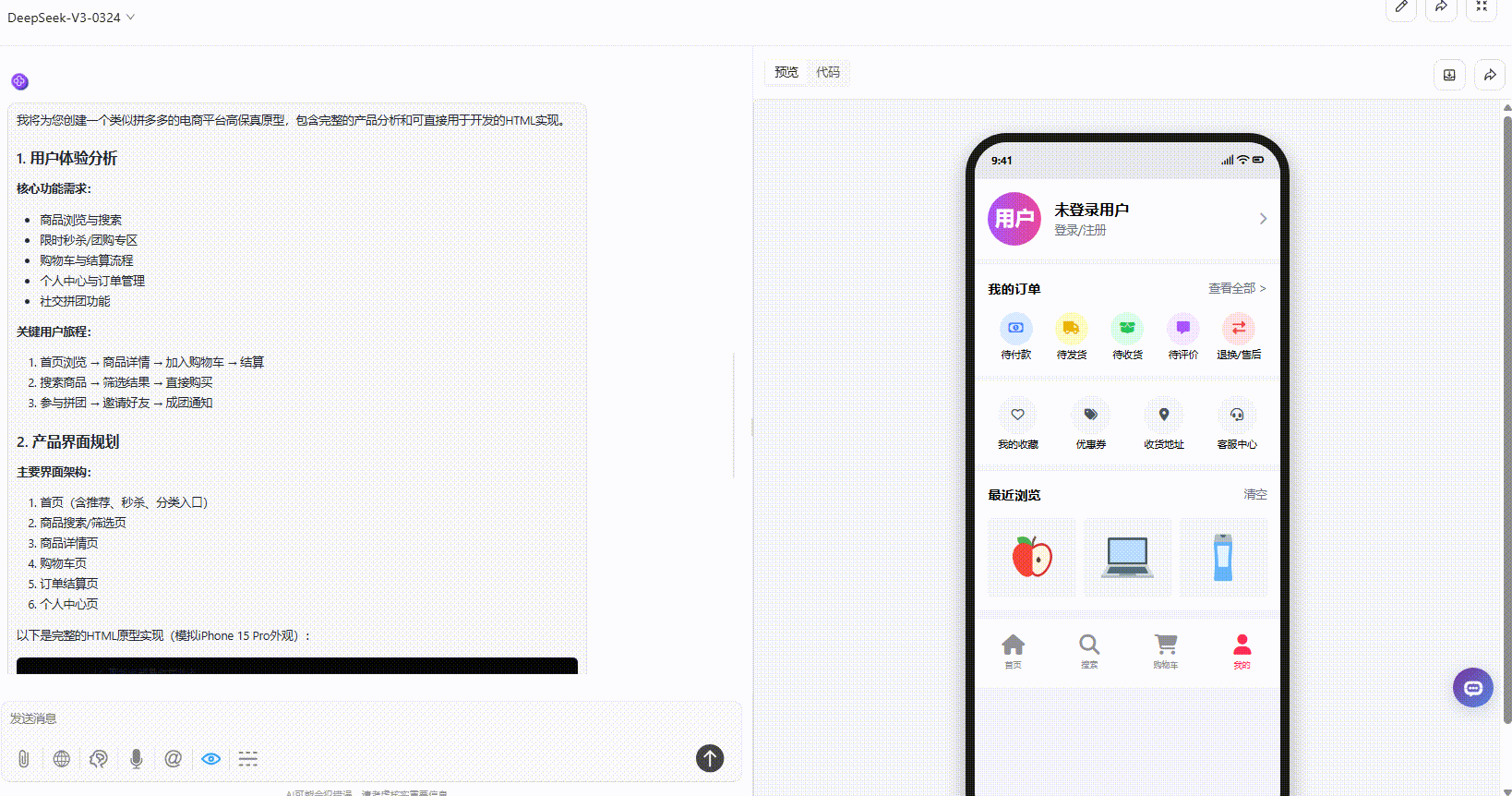
Gemini-2.5-Pro:页面内容很丰富,采用平铺式展示交互性相对不够。
Claude-3.7-sonnet:丰富度上不及另两个模型,仅有一个页面,且没有交互跳转。
实测总结:
综合以上是实测,可初步得出以下效果:
(1)总体而言,综合能力较强的是DeepSeek-V3.1,无论是公众号封面生成、还是网页设计任务,都能够提供更高质量的输出。
(2)Gemini-2.5-Pro视觉设计和内容丰富度方面显得略为单薄,例如在赛博朋克贪吃蛇游戏和模拟太阳系行星运动中丰富度不及另两个模型。
(3)Claude-3.7-sonnet则在某些特定任务中表现突出,如公众号封面生成、网页设计等,但在前端任务上仍未能与 DeepSeek-V3.1 相媲美。
在302.AI上使用DeepSeek-V3-0324和Gemini-2.5-Pro模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
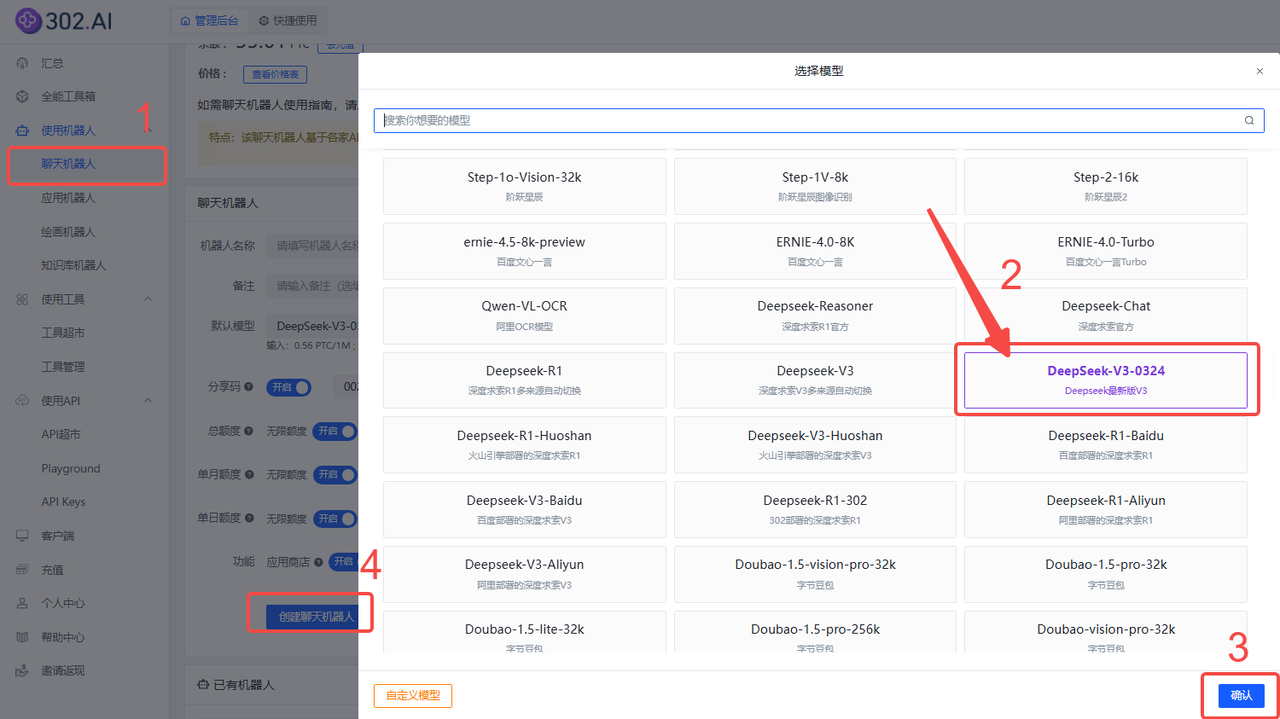
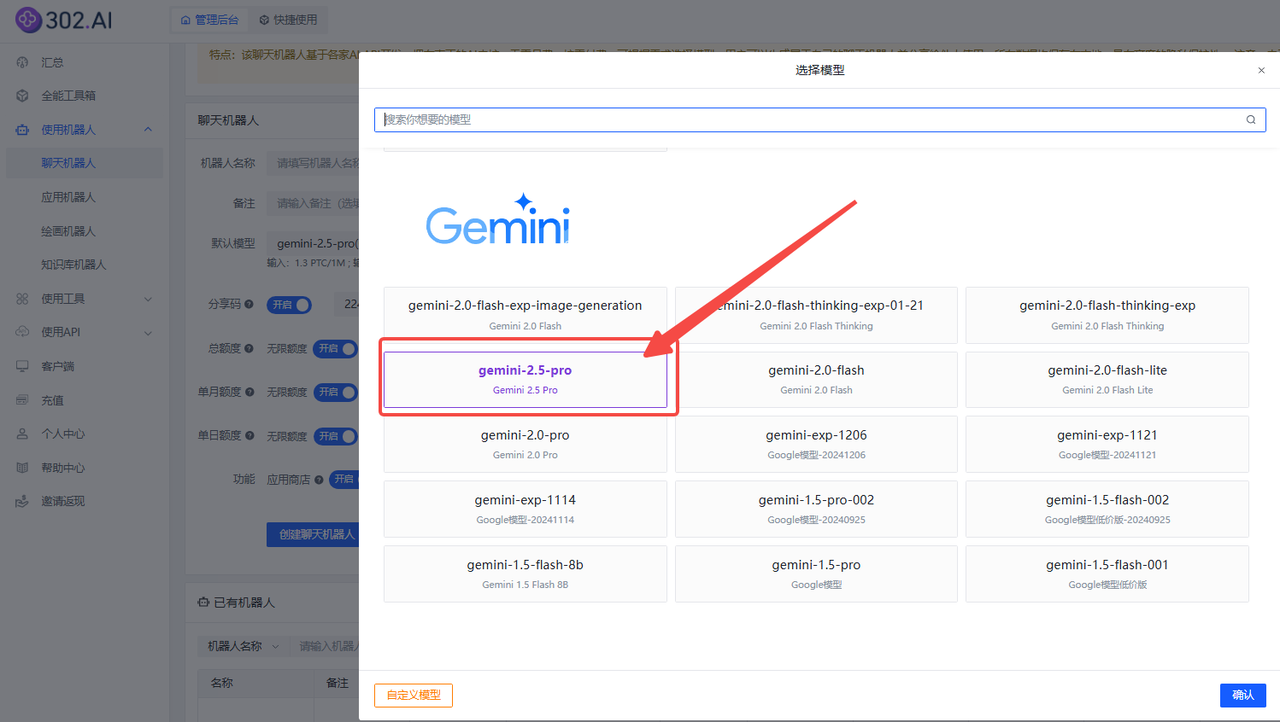
1、使用模型对话
依次点击使用机器人→聊天机器人→ 找到国产模型/Gemini分类 → 选择模型→创建聊天机器人;
DeepSeek-V3-0324:
Gemini-2.5-Pro:
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→国产模型/Gemini→查看文档;