
3月21日晚,腾讯宣布混元大模型系列的深度思考模型已成功升级为混元-T1正式版。据官方介绍,该模型基于腾讯3月初发布的业界首个超大规模 Hybrid-Transformer-Mamba MoE 大模型TurboS快思考基座,通过大规模训练显著扩展了推理能力,并进一步对齐人类偏好。
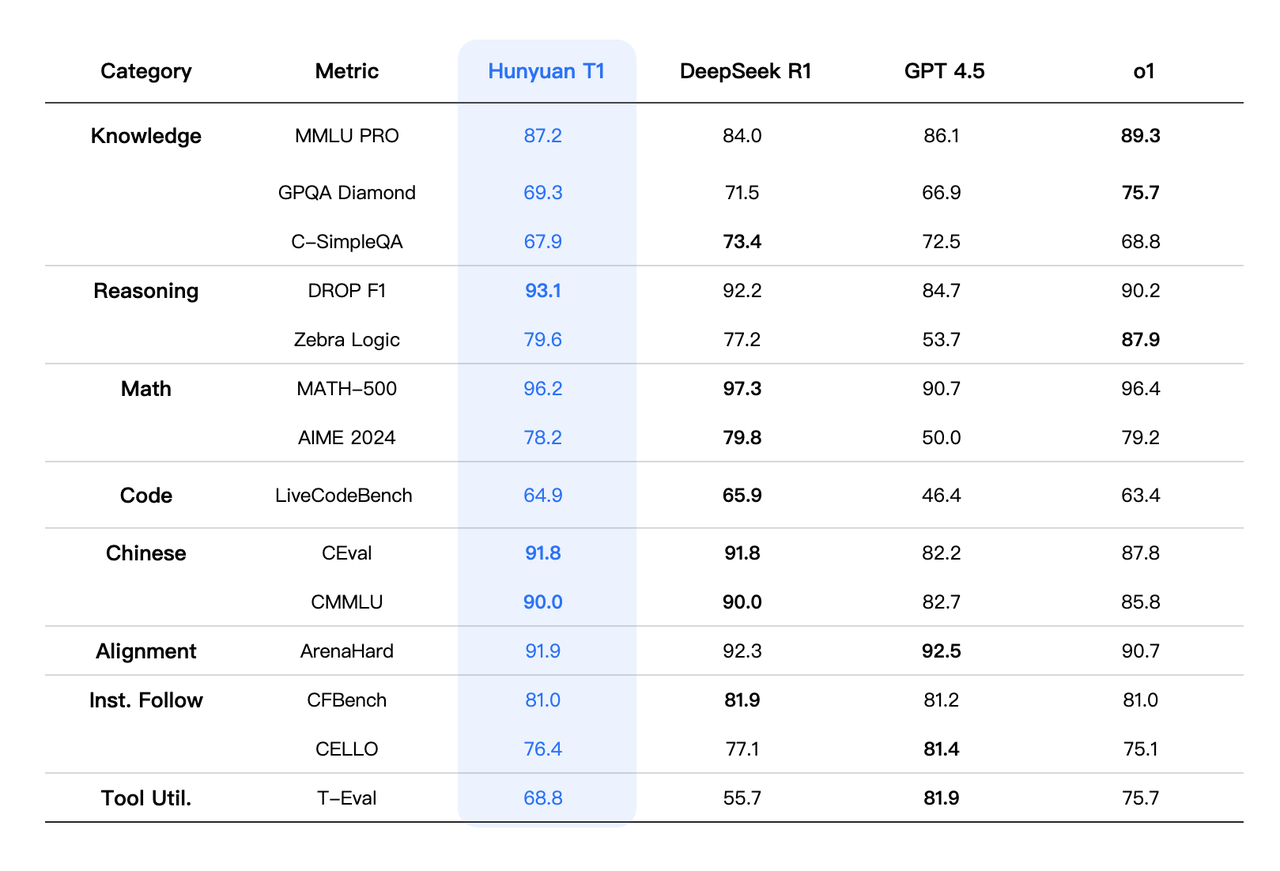
在MMLU-pro、CEval、AIME、Zebra Logic等中英文知识、竞赛级数学,以及逻辑推理公开基准测试中, Hunyuan-T1 均获得比肩 DeepSeek R1 和 OpenAI o1 的分数。

302.AI现已接入Hunyuan-T1正式版的最新版本: Hunyuan-T1-Latest 。这是官方推荐使用的版本。今天,我们把 Hunyuan-T1-Latest 与同样具备思考推理能力的 QwQ-32B 、DeepSeek-R1 模型进行对比,带大家更直观地了解 Hunyuan-T1-Latest 模型的优劣。
Hunyuan-T1-Latest vs. QwQ-32B vs. DeepSeek-R1 模型实测
实测1:空间问题
提示词:7米长的竹竿可以通过高3米宽3米的门吗?
考察点:测试模型的空间想象力以及几何推理能力。
总结:三个模型均未给出正确答案,未考虑竹竿可以与地面平行且与门垂直通过的可能。
QwQ-32B :回答错误。

DeepSeek-R1:DeepSeek也未能给出正确答案。

Hunyuan-T1-Latest:只考虑对角线通过的情况,回答错误。

实测2:中文理解
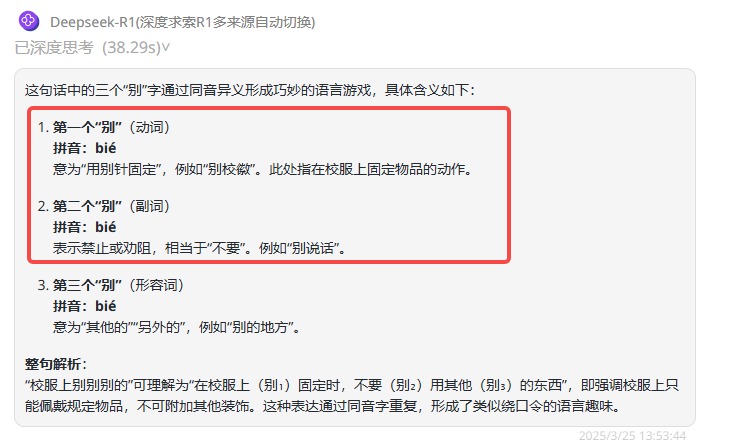
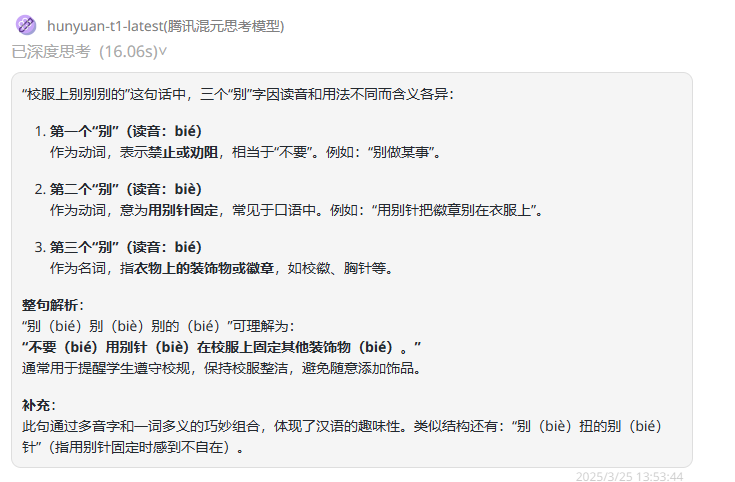
提示词:“校服上别别别的”里的三个“别”分别是什么意思?
考察点:这一题目主要测试模型在特定语境中的中文词语理解。
总结:QwQ-32B 和 DeepSeek-R1在前两个“别”字的理解上混淆了,只有Hunyuan-T1-Latest完全理解正确。
QwQ-32B :第一第二个“别”字意思有点混淆,不过完整的句子理解倒是正确的。
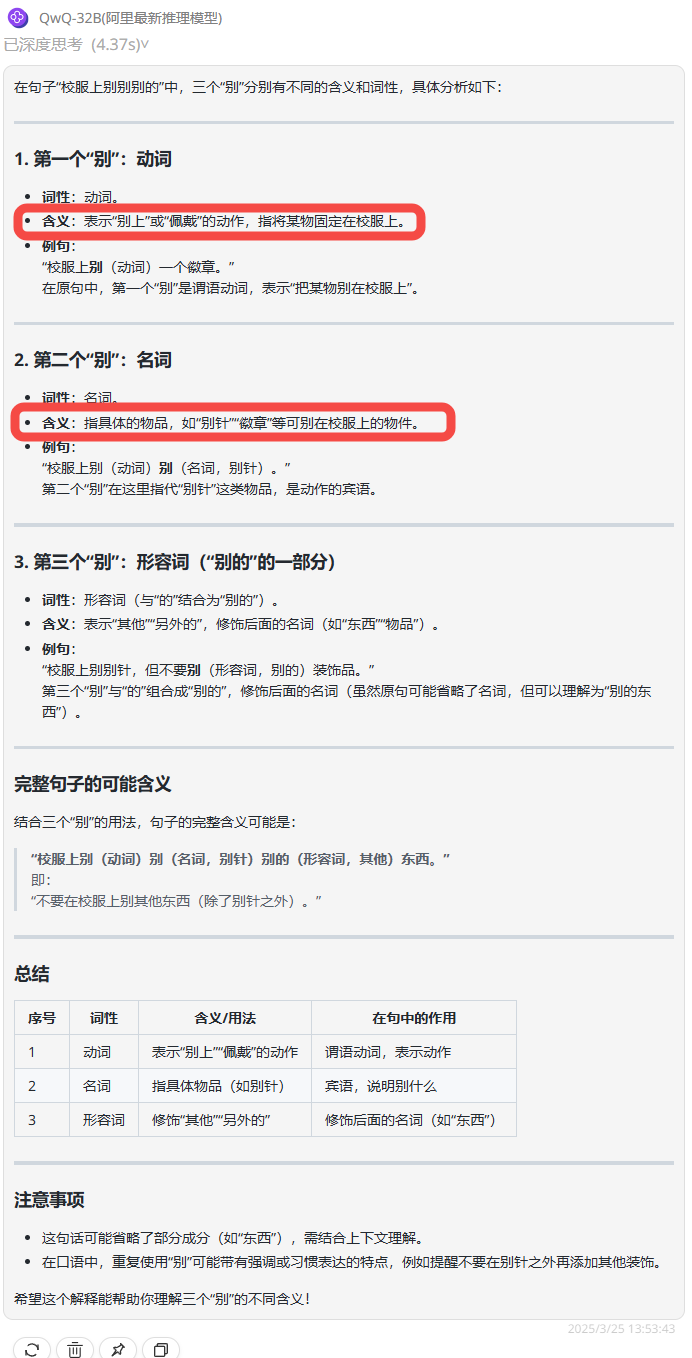
DeepSeek-R1:同样第一个字与第二个字的理解混淆了,整句理解也稍有偏差。
Hunyuan-T1-Latest:三个字理解完全正确!
实测3:逻辑推理:
提示词:
老师发给甲、乙、丙三张扑克牌,老师说:“你们三个人拿到的数字和是14,并且没有鬼牌。其中,J、Q、K、A分别代表11、12、13、1。你们只能看自己的牌,能猜出其他两人拿到的是什么数字吗?”
甲:“我只知道乙丙两人的数字一定不同。”
乙:“其实一开始我就知道咱们三个人的数字一定不同。”
丙:“我知道你们俩拿到的数字了。”
请问,丙拿到什么数字了呢?
考察点:这个题目考察的是模型的问题解决能力和逻辑推理能力。
总结:QwQ-32B和DeepSeek-R1回答错误,只有 Hunyuan-T1-Latest 给出了清晰的解释和正确的答案。
QwQ-32B :答案错误,分析过程让人读起来云里雾里的,不够清晰。
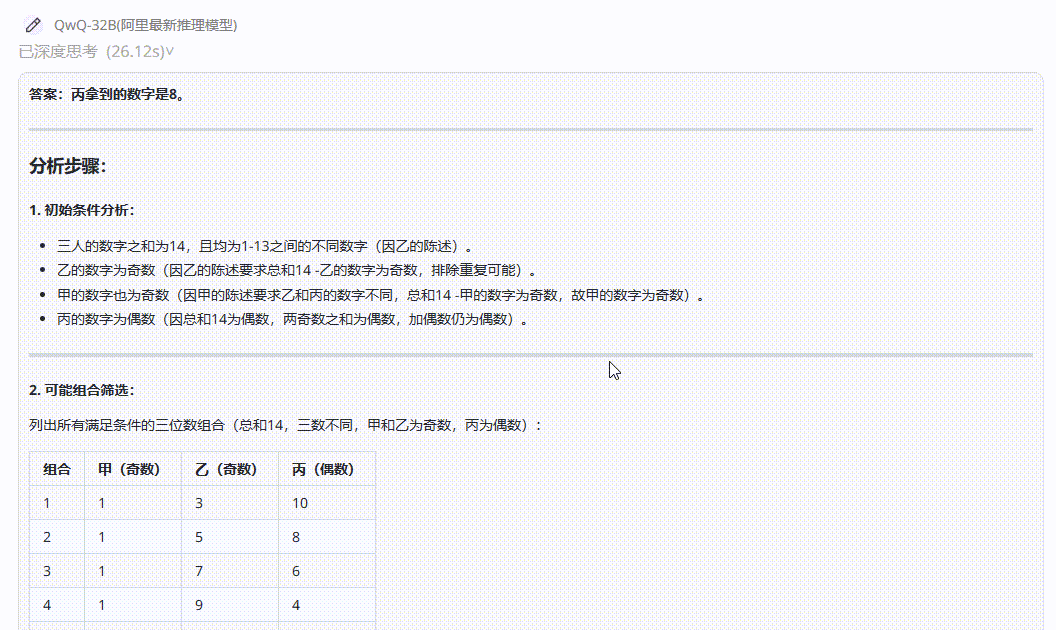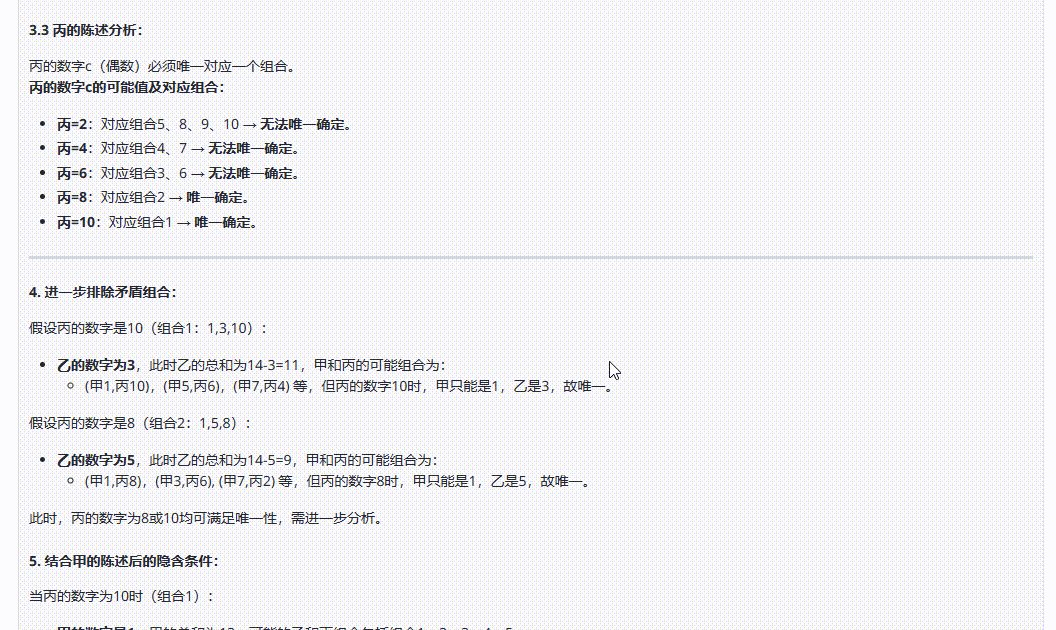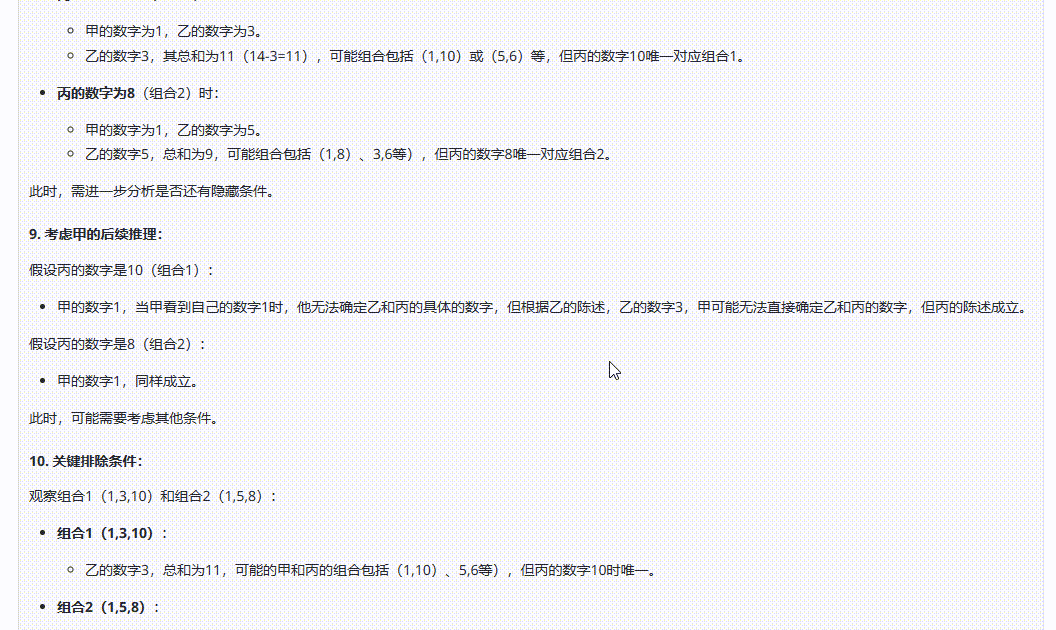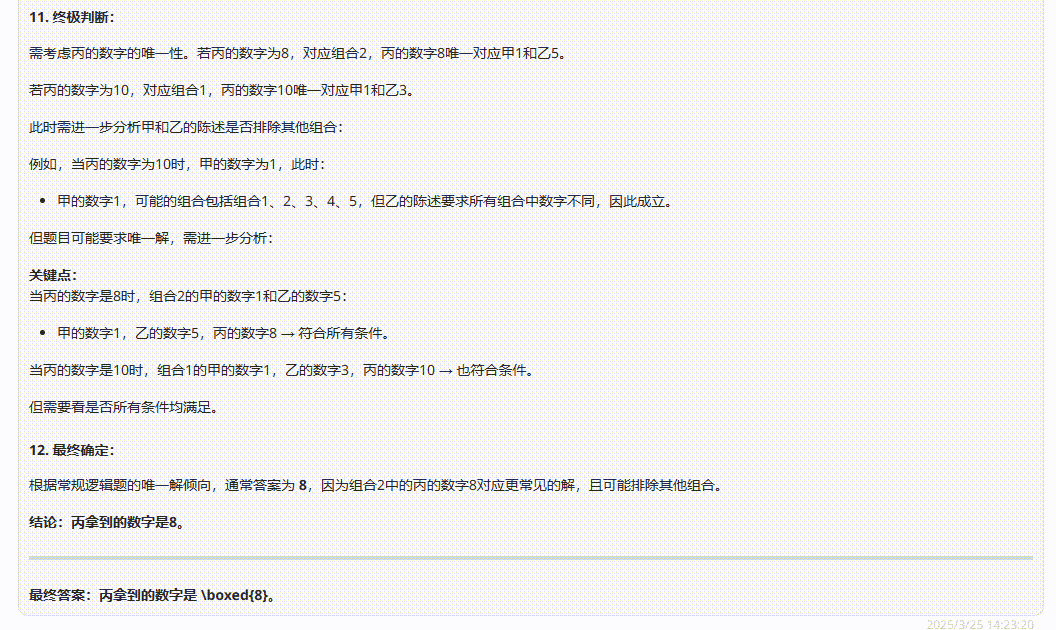
DeepSeek-R1:经过漫长等待后,最后输出的答案是错误的。
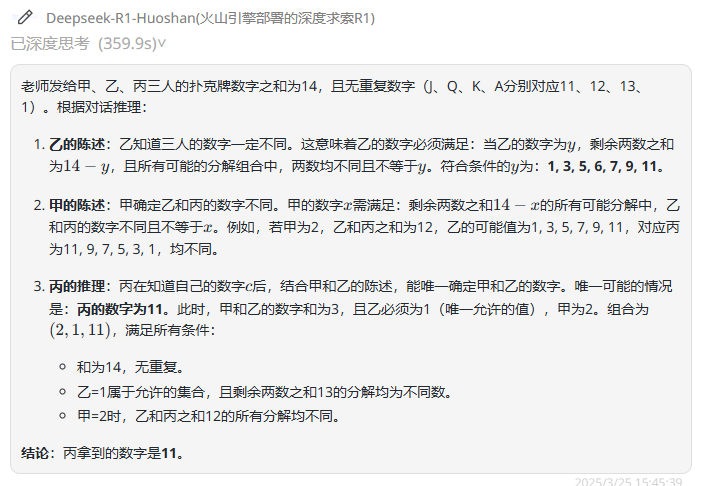
Hunyuan-T1-Latest:解析过程很清晰,答案正确。

实测4:编程效果
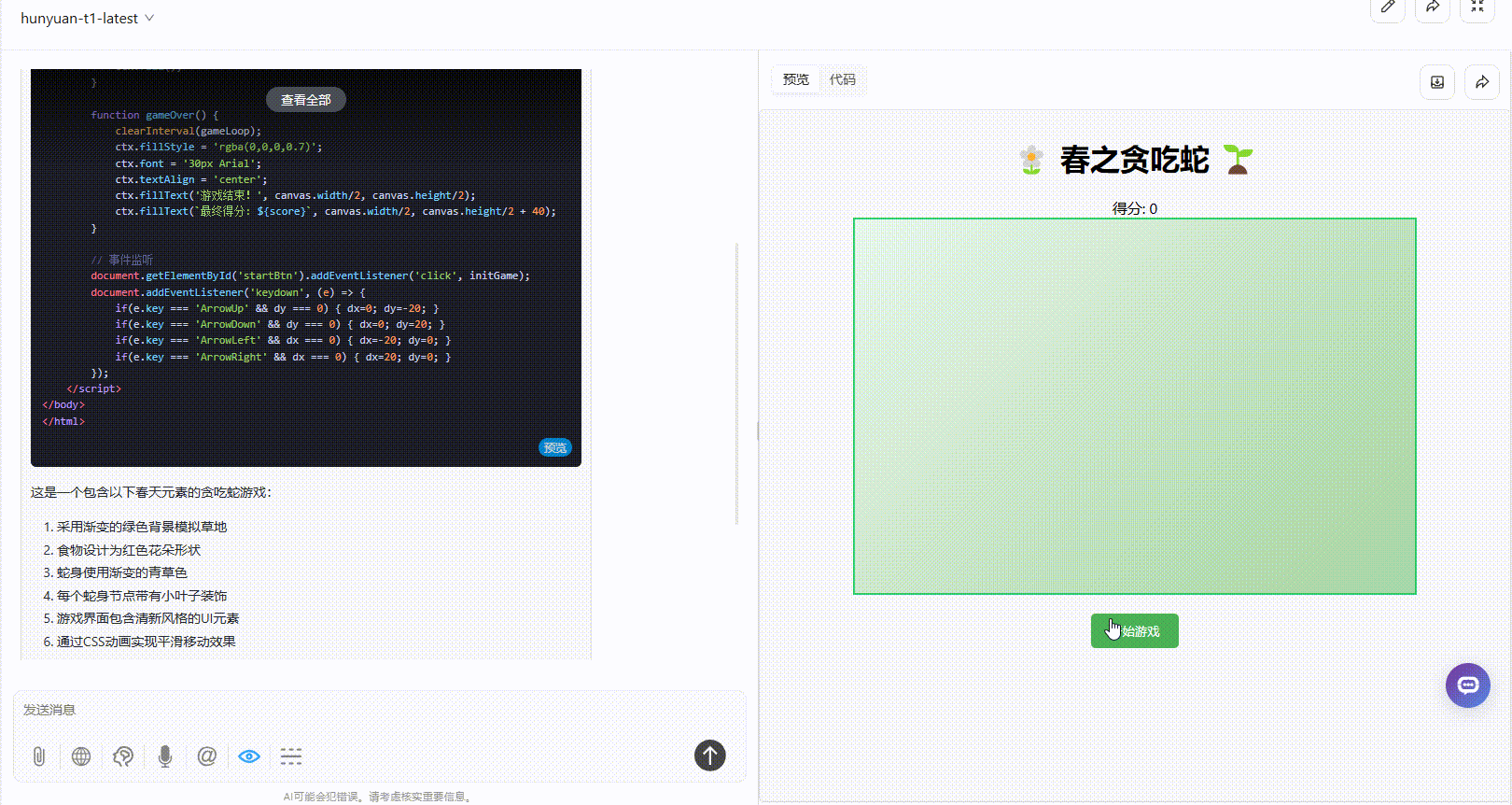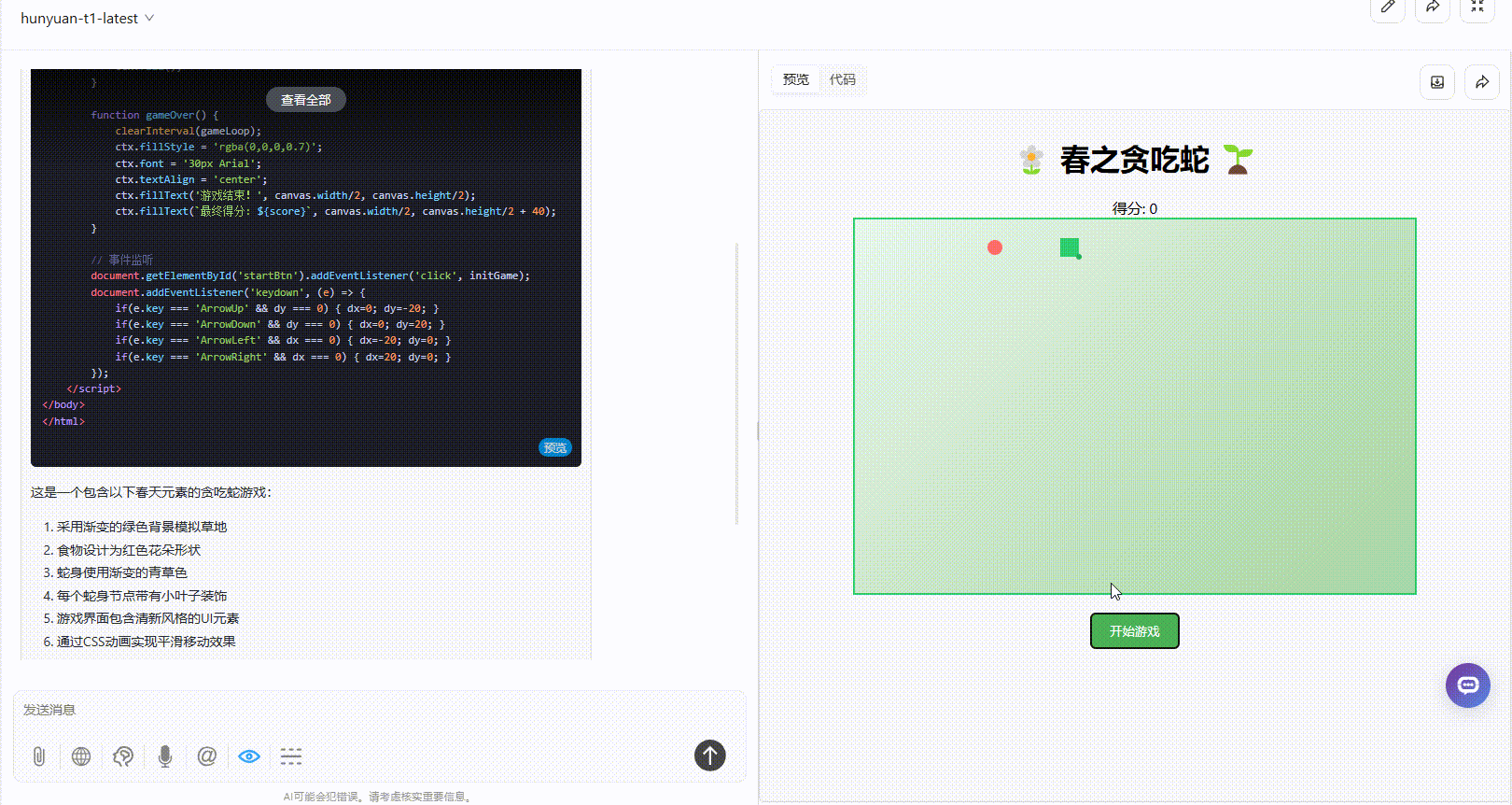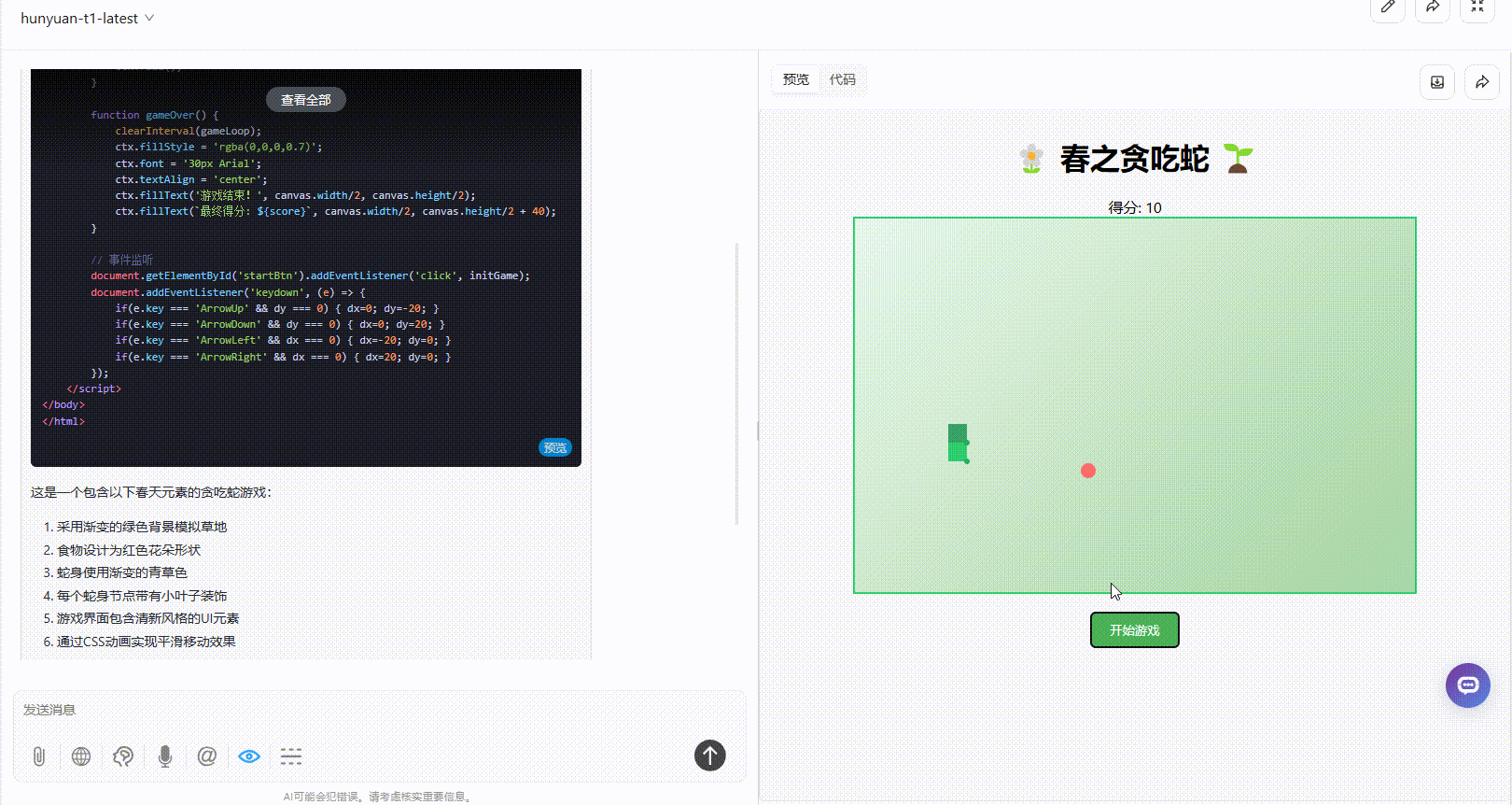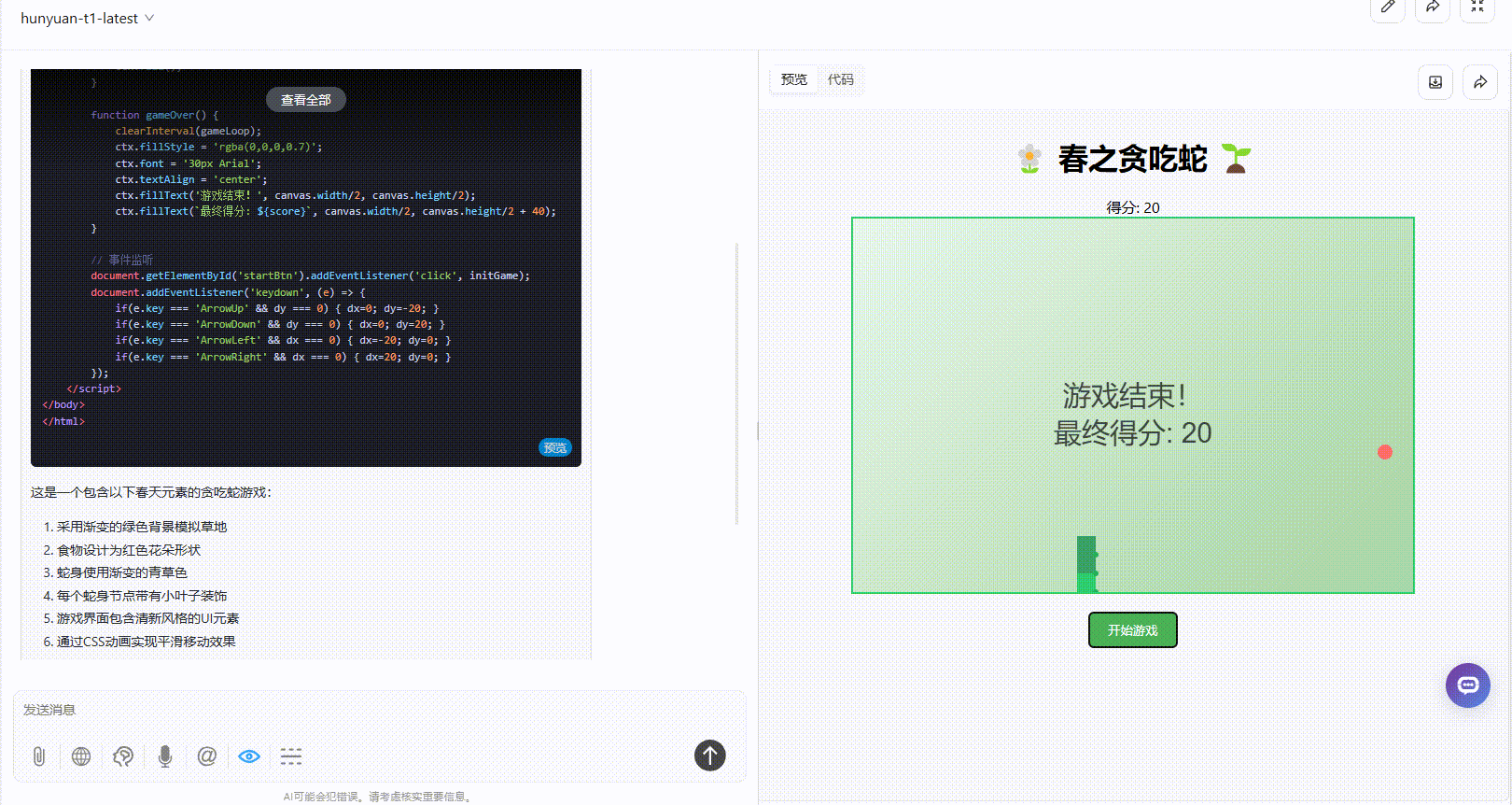
提示词:制作一个含有春天元素的贪吃蛇小游戏,需要包含“开始游戏”按钮以及游戏说明
总结:结合界面美观度、运行效果、提示词遵循等方面综合比较,表现最好的是DeepSeek-R1,其次则是Hunyuan-T1-Latest。
QwQ-32B :游戏说明虽表明是用键盘操作游戏,但是尝试使用键盘后游戏动画随即停止,这一逻辑存在问题,呈现效果欠佳 。
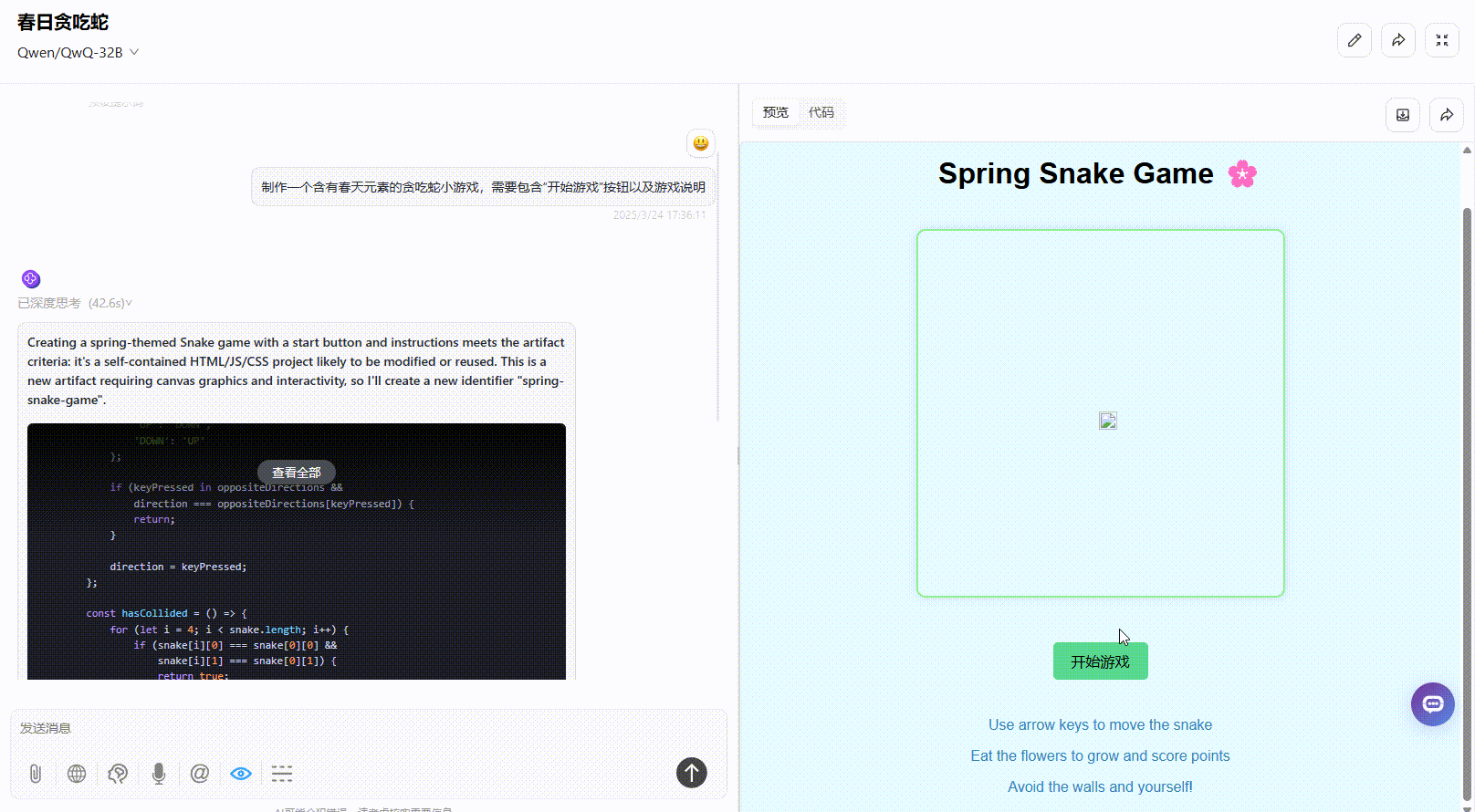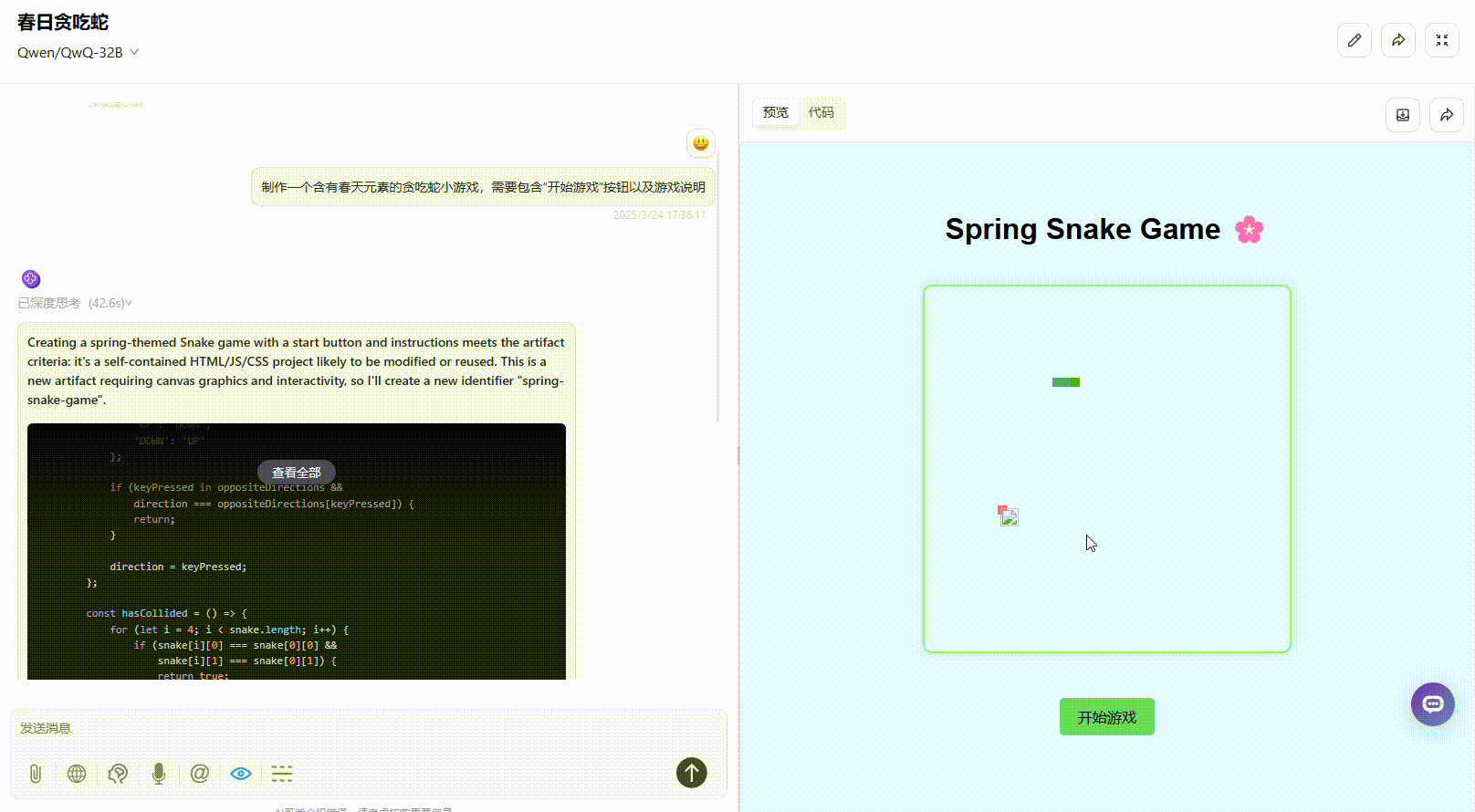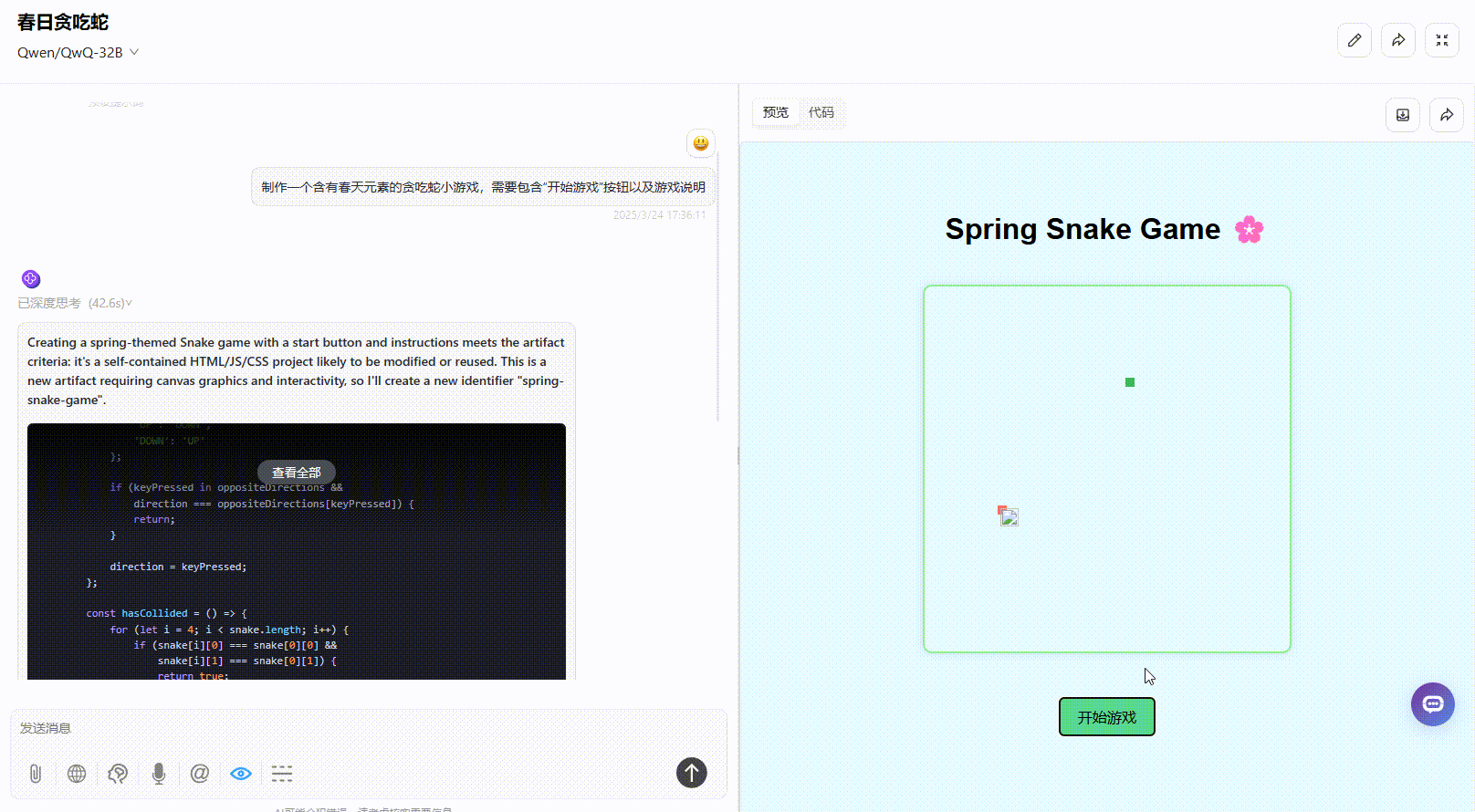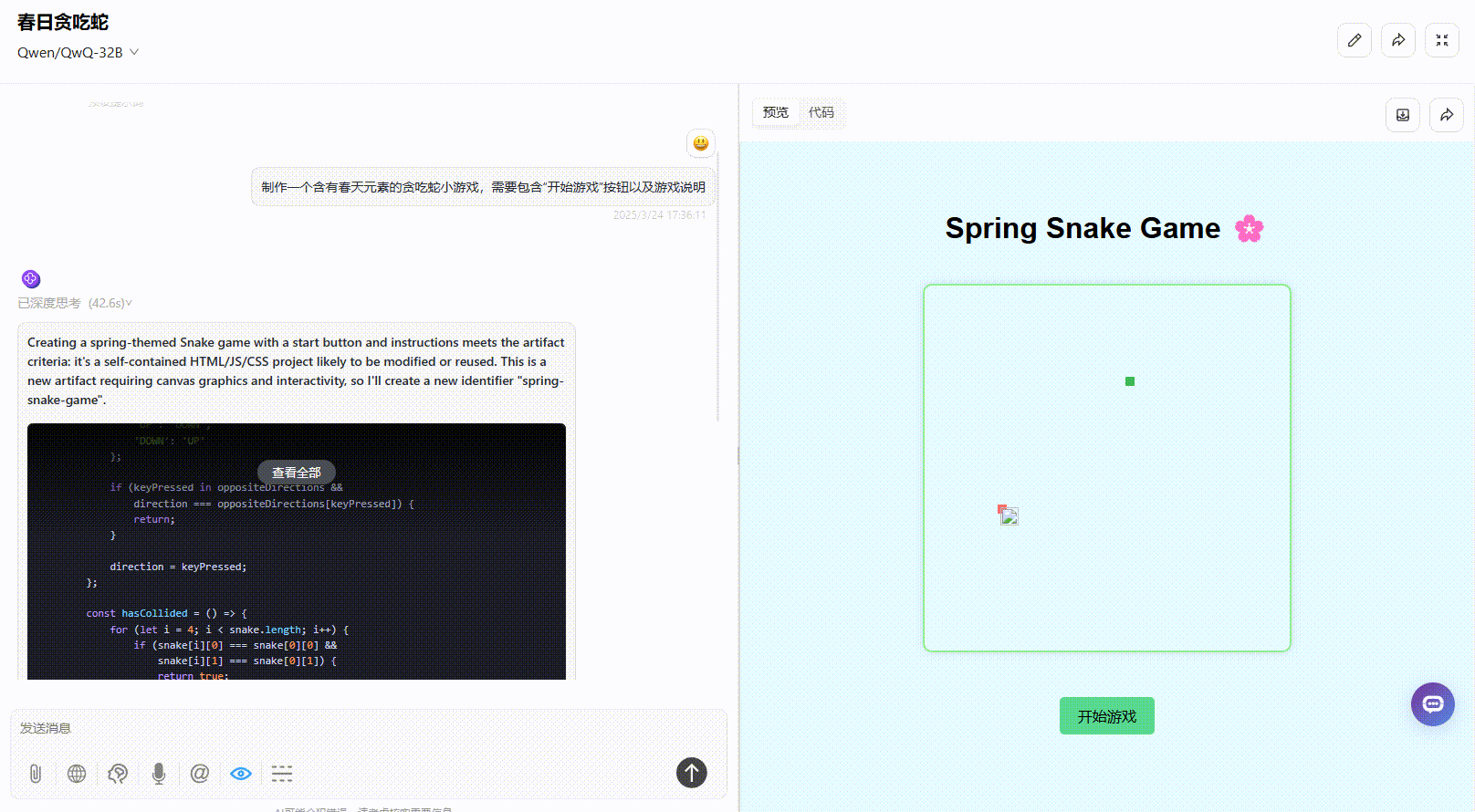
DeepSeek-R1:提示词遵循准确,界面涵盖了“开始游戏”按钮以及游戏说明,界面美观度高,实操未出现bug,整体表现很好。
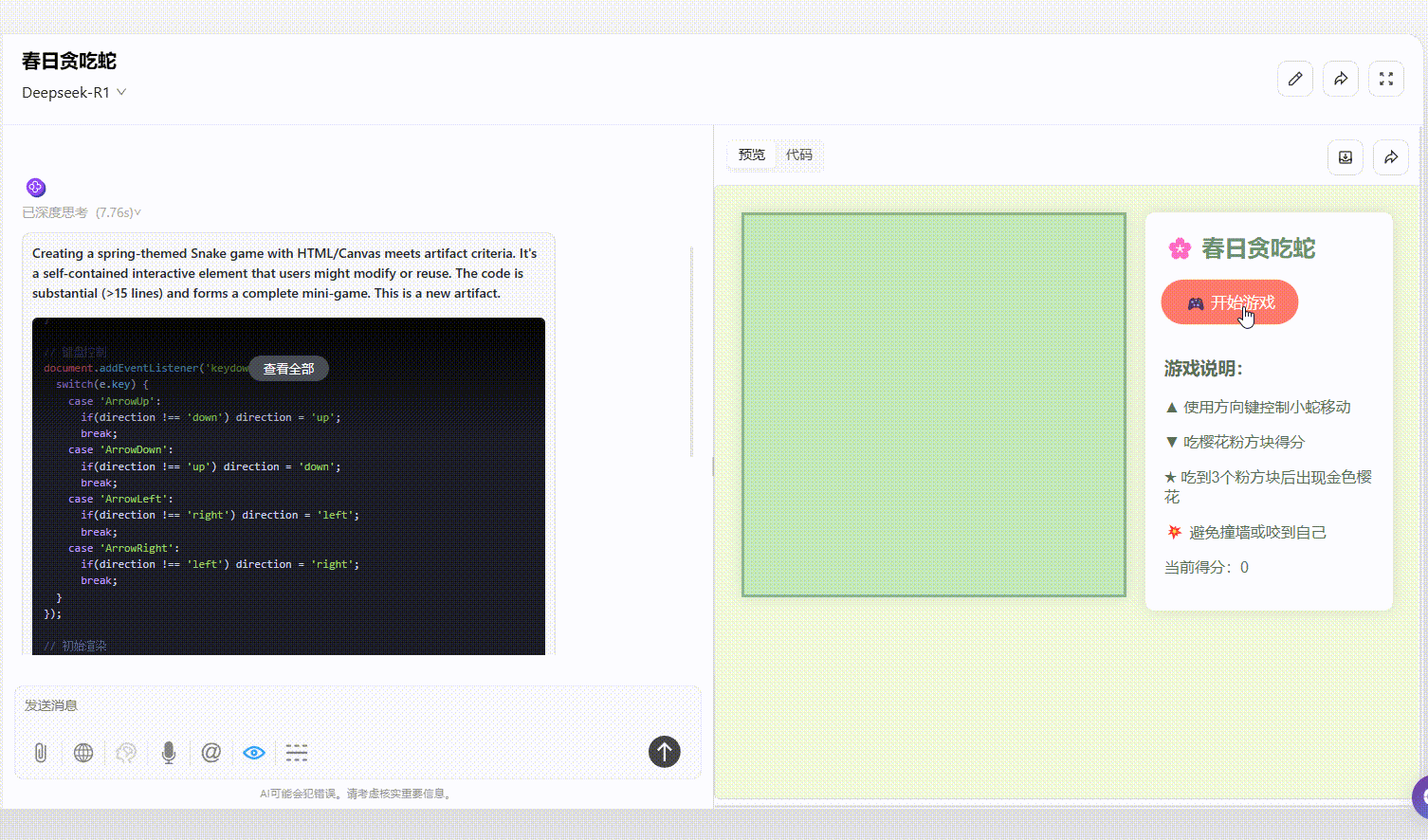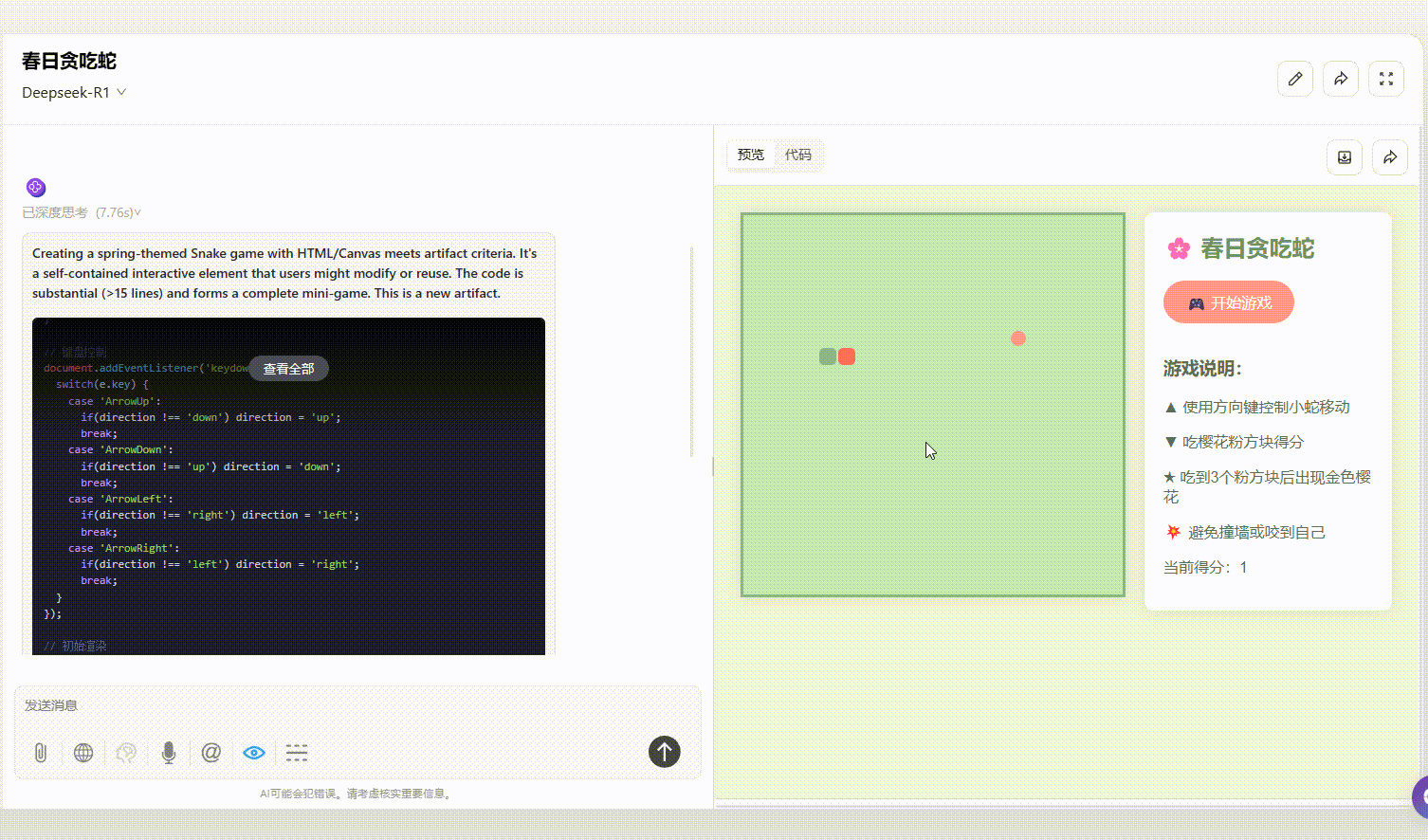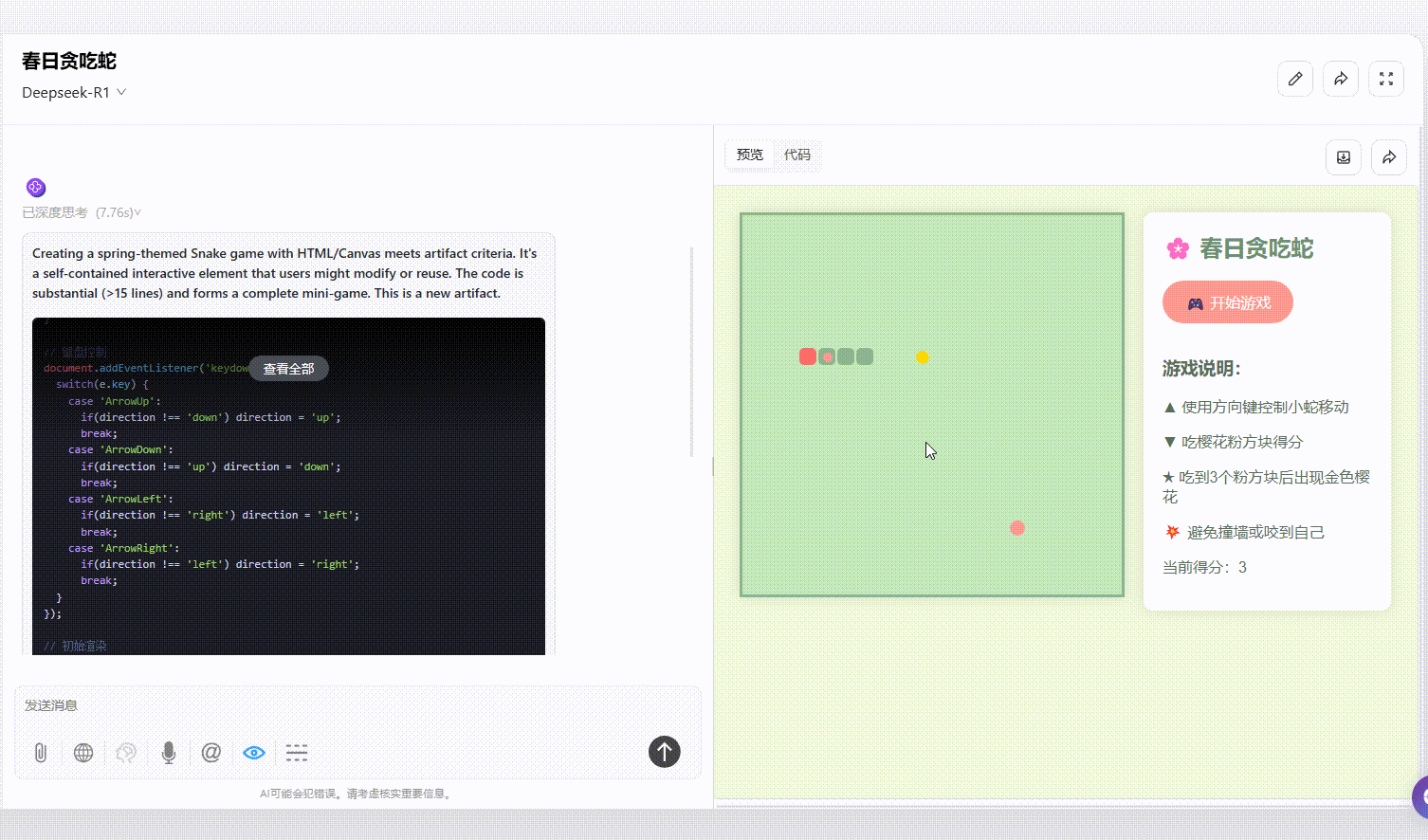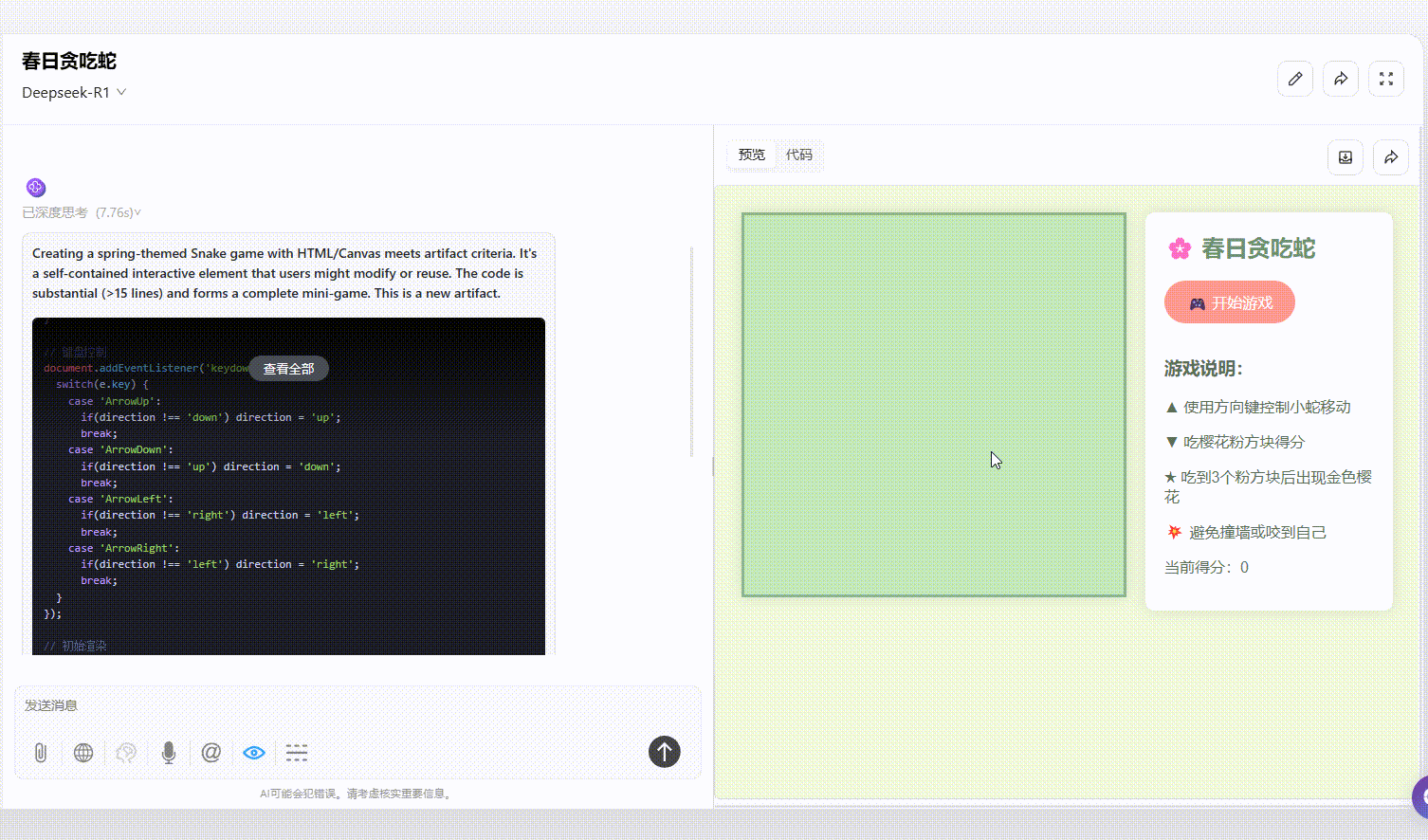
Hunyuan-T1-Latest:提示词中提到的“游戏说明”未在效果中展示,但界面美观度和可操作性方面表现不错。
实测总结:
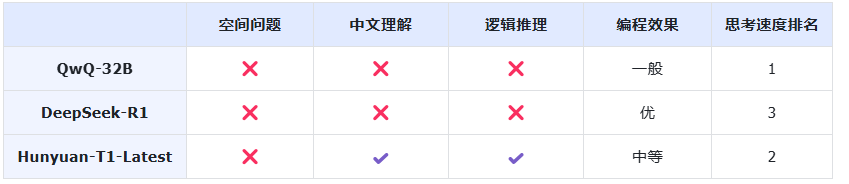
(实测结果整理)
综合以上实测,我们可以初步得出以下结论:
(1)推理模型显“人机感”
从实测1空间问题测试中可以得出:尽管这三个模型均属于可进行思考推理的模型,但在应对这类涉及人生活常识的问题时,它们的回答还是不够灵活,具有一定的“人机感”。
(2)Hunyuan-T1-Latest在中文语境理解上强于其他实测模型
在中文理解的测试中,Hunyuan-T1-Latest表现突出,能够准确理解语境中的“别”字含义,而其他两个模型则存在混淆。这表明Hunyuan-T1-Latest较其他两个模型在中文语境理解上理解能力更强。
(3)Hunyuan-T1-Latest表现惊艳,QwQ-32B和DeepSeek-R1 较为逊色
在逻辑推理的测试中,Hunyuan-T1-Latest提供了清晰的分析过程并给出了正确答案。相较之下,QwQ-32B 和DeepSeek-R1 的表现则显得较为逊色,未能推理出正确答案。
(4)DeepSeek-R1 编程综合表现最佳
在编程效果的实测中,DeepSeek-R1综合表现上略胜一筹,展示了出色的界面美观度和操作性,Hunyuan-T1-Latest虽然表现不错,但在游戏说明的展示上有所欠缺。QwQ-32B的表现相对较差,存在逻辑问题和用户体验不佳的情况。
(5)Hunyuan-T1-Latest 推理速度领先R1
综合各轮实测的思考时间,我们意外发现 Hunyuan-T1-Latest 在推理速度上优势明显,比 DeepSeek-R1 更快,不过与小参数模型 QwQ-32B 对比还是有一定的差距。
在302.AI上使用Hunyuan-T1-Latest模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
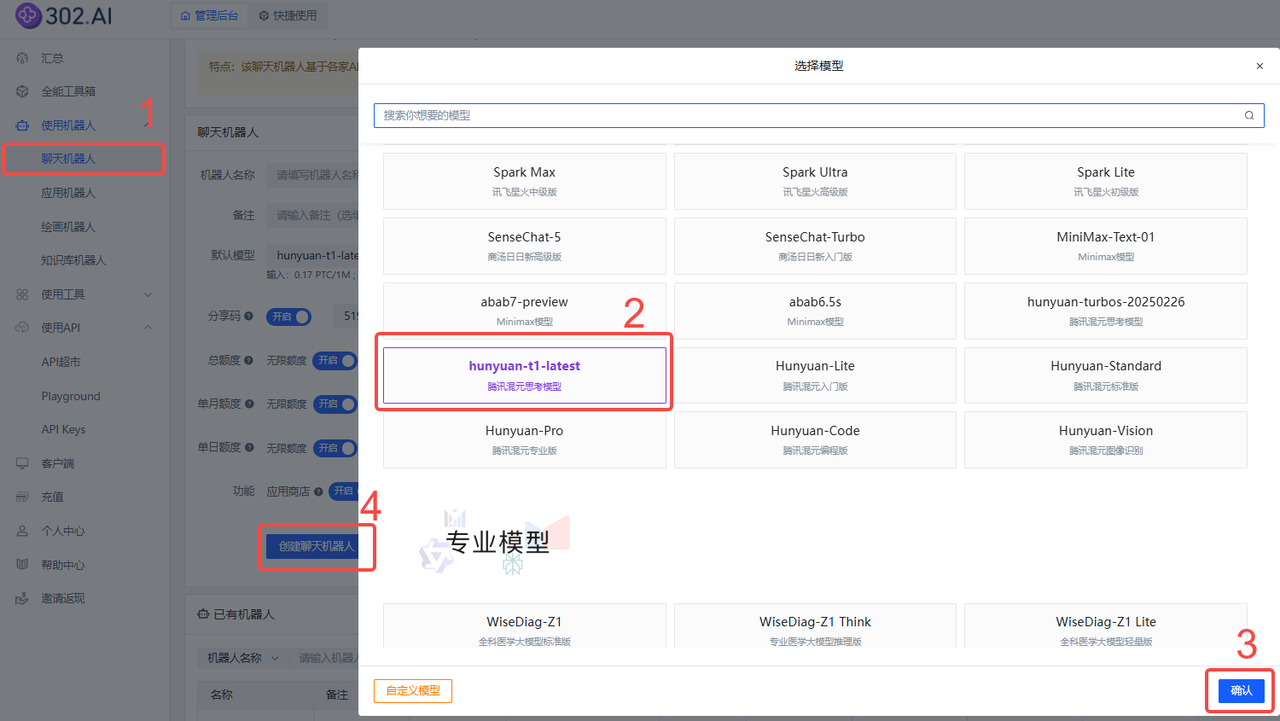
1、使用模型对话
依次点击使用机器人→聊天机器人→ 模型→ 选择模型hunyuan-t1-latest→创建聊天机器人;
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→国产模型→查看文档;
API名称:hunyuan-t1-latest

👉立即注册免费试用302.AI,开启你的AI之旅!👈
为什么选择302.AI?
● 灵活付费:无需月费,按需付费,成本可控
● 丰富功能:从文字、图片到视频,应有尽有,满足多种场景需求
● 开源生态:支持开发者深度定制,打造专属AI应用
● 易用性:界面友好,操作简单,快速上手
