在上一篇文章中,我们给大家介绍了 Claude 3.7 Sonnet 模型,同时对Claude 3.7 Sonnet的标准模式(Normal)进行了实测对比。
而现在,我们将会对Claude 3.7 Sonnet 推理模式(Extended)进行深入探讨。通过与Claude 3.5 Sonnet、Claude 3.7 Sonnet(标准模式)的对比,更全面地了解Claude 3.7 Sonnet 推理模式在性能方面的提升和在应用场景方面的的拓展。
在实测前,我们收集了一些官方关于Claude 3.7 Sonnet推理模式的描述:
1、能引导模型更深入地思考更棘手的问题。
2、可见的思维过程,并反复检查答案。
3、显著提升了数学问题的准确率,其性能随着“思考令牌”数量的增加呈对数增长。
基于上述描述,我们将有针对性地选取案例进行验证。
模型实测
(下述将用Claude 3.7 Sonnet Thinking表示Claude 3.7 Sonnet推理模式)
实测1:信息推理
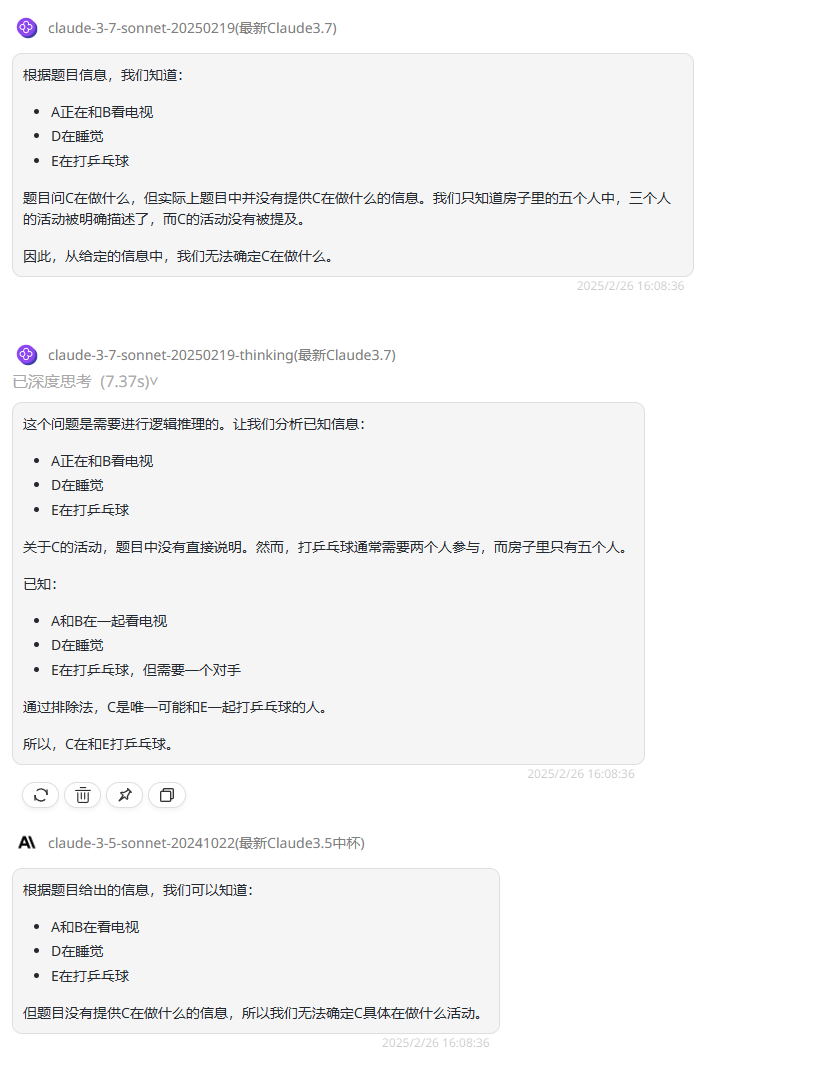
提示词:房子里有五个人,A、B、C、D和E,A正在和B看电视,D在睡觉,E在打乒乓球,请问C在做什么?
考察点:测试模型在信息有限情境下的合理推断能力
结论:Claude 3.7 Sonnet Thinking在逻辑完备性校验和常识规则调用方面较其他模型有提升,这种能力在解决开放性推理问题时具有显著优势。
模型输出结果如下:
Claude 3.7 Sonnet:仅解析题目中直接陈述的事实,因未提及C而得出”无法确定“的结论。与Claude 3.5 sonnet输出的回答相似。
Claude 3.7 Sonnet Thinking:分析已知信息,并推理出未明示的第二参与者,最后结合排除法得出正确答案。
Claude 3.5 Sonnet:仅解析题目中已知的信息,未实现进一步思考和推理。

实测2:AIME数学测试
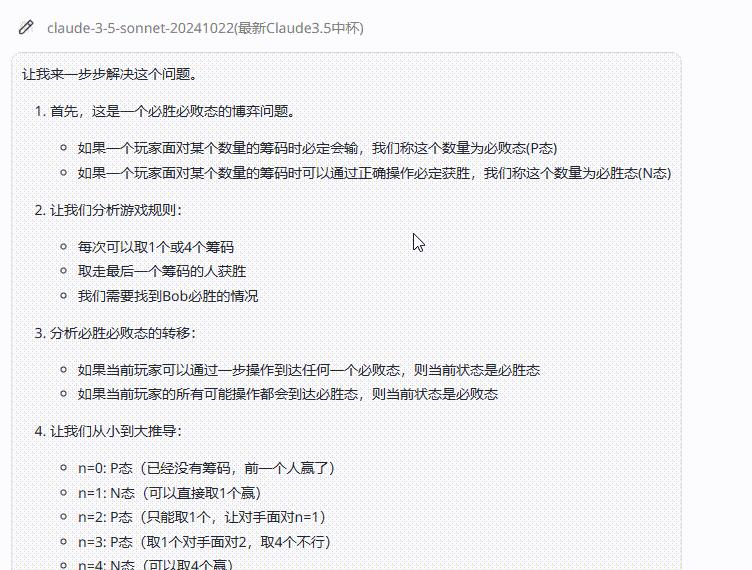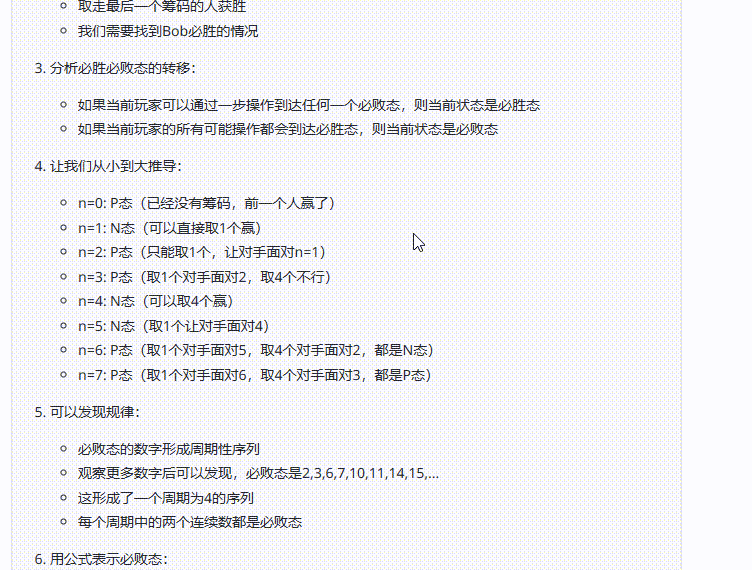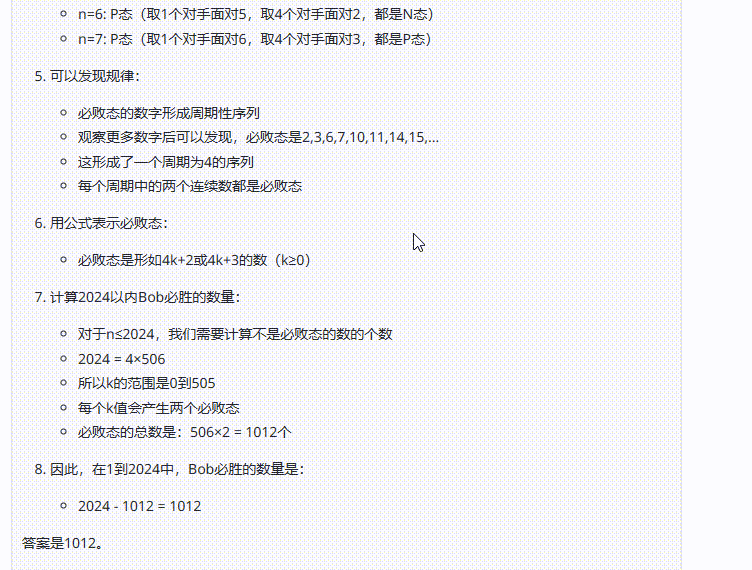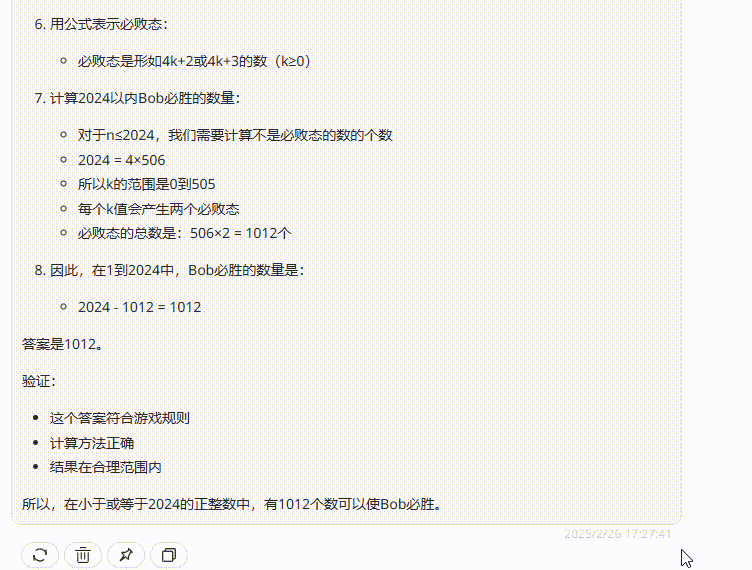
提示词:Alice 和Bob 玩下述的游戏。他们面前有摆成一堆的n个筹码。玩家轮流操作,Alice 先开始。每一次,玩家可以从堆中取走1个或4个筹码。取走最后一个筹码的人获胜。在小于或等于2024的正整数中,有多少个数可以作为n,使得Bob存在一种策略,无论Alice 如何行动,都能确保自己获胜?(正确答案:809)
考察点:测试模型在数学问题上的准确性,并观察模型在面对复杂问题时是否能进行更深入的思考
结论:三个模型均回答错误,但是Claude 3.7 Sonnet Thinking可视化的思考过程在一定程度能够帮助用户从中获取解题思路。
模型输出结果如下:
Claude 3.7 Sonnet:答案错误。

Claude 3.7 Sonnet Thinking:虽然反复检查,但最终还是回答错误。

Claude 3.5 Sonnet:答案错误。
实测3:多模态思维测试
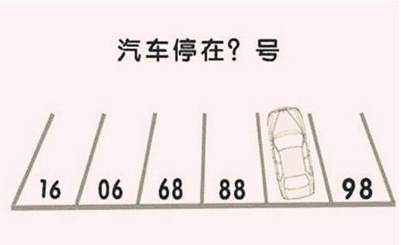
考察点:测试模型在多模态方面的空间逻辑思维能力。
结论:三个模型的回答中,由于模型的过度联想,导致Claude 3.7 Sonnet Thinking的答案是错误的,在多模态方面,Claude 3.7 Sonnet(标准版)优于 Claude 3.7 Sonnet Thinking。
模型输出结果如下:
Claude 3.7 Sonnet:回答正确。
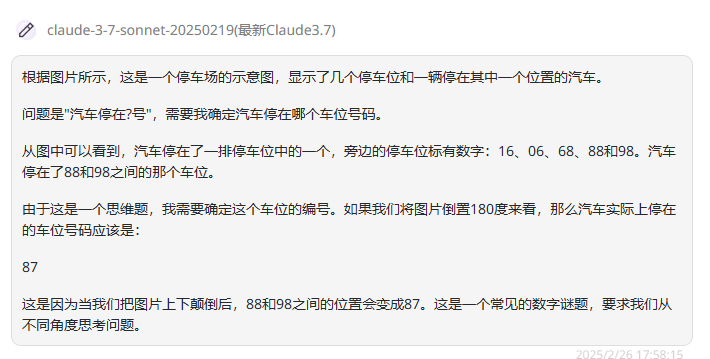
Claude 3.7 Sonnet Thinking:从思考过程中可以看出,模型过度联想导致找到的规律有误,最终回答错误。
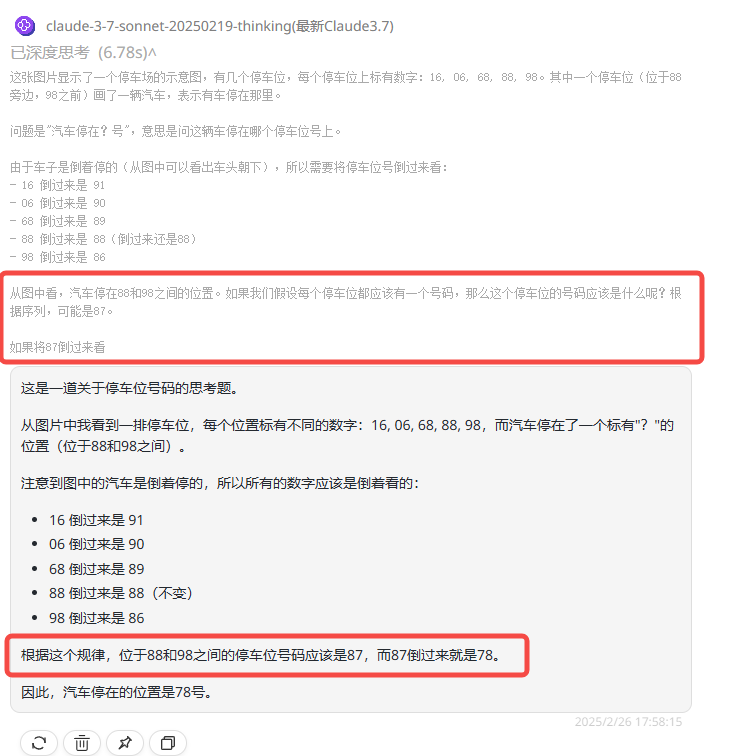
Claude 3.5 Sonnet:回答正确。

实测4:编程检验
提示词:

考察点:检验模型应对专家难度编程题目的编程能力水平。
结论:三个模型中,仅Claude 3.7 Sonnet生成的代码未完全通过验证,侧面证明Claude 3.7 Sonnet(标准版)较前一版本模型Claude 3.5 Sonnet在编程方面准确性有一些下降。
模型输出结果如下:
Claude 3.7 Sonnet:代码未完全通过检验。
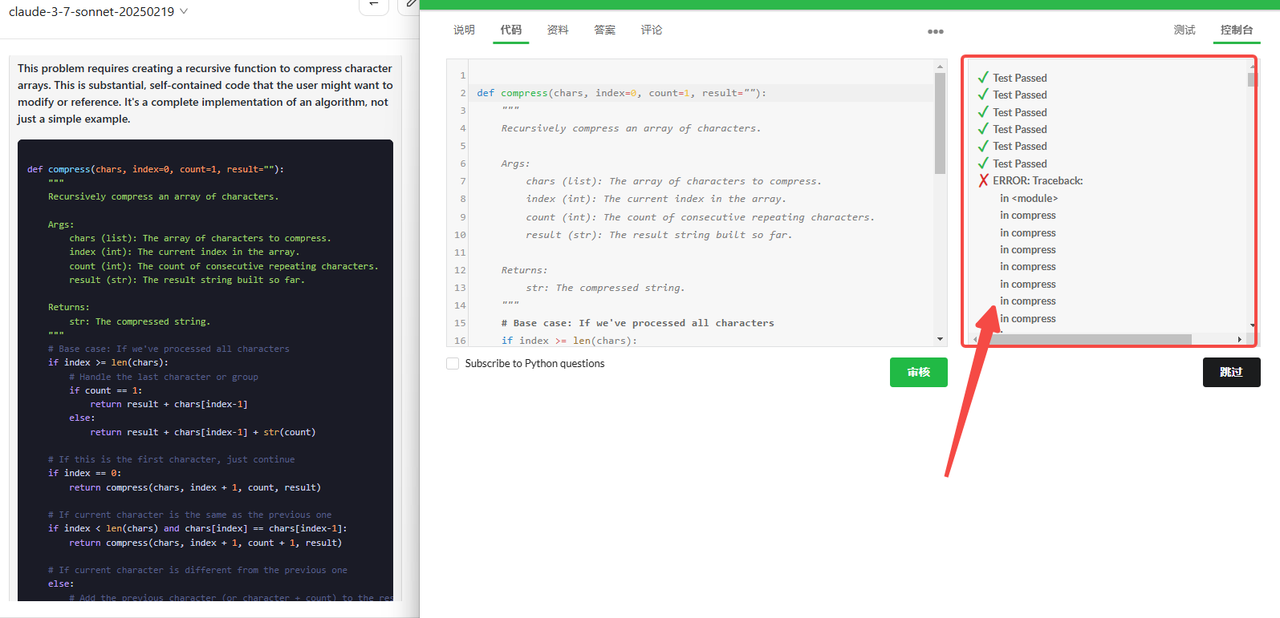
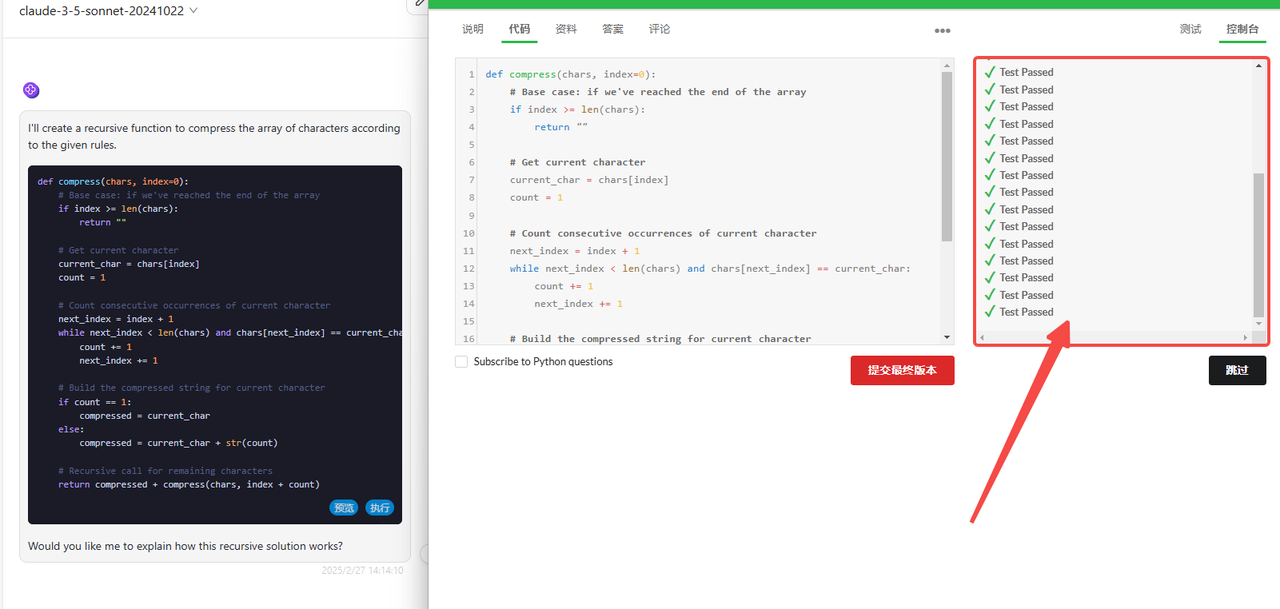
Claude 3.7 Sonnet Thinking:代码检验通过。
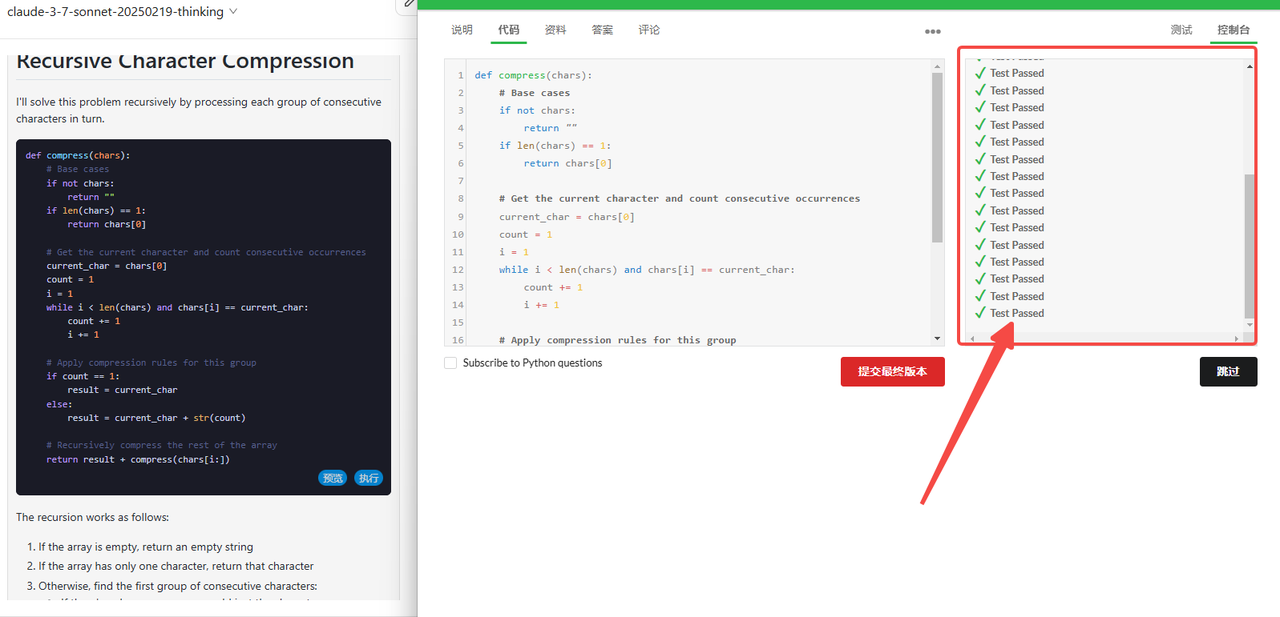
Claude 3.5 Sonnet:代码检验通过。
实测5:编程效果
提示词:创建一个包含CSS和JavaScript的HTML文件来生成一个动画天气卡。这张卡片应该在视觉上表现以下天气情况,并具有不同的动画:风:(例如,移动的云,摇曳的树,或风线)雨(例如,落下的雨滴,形成的水坑)太阳(例如,闪亮的光线,明亮的背景)雪(例如,飘落的雪花,积雪)并排显示所有天气卡片,卡片应该有一个黑暗的背景。在这个文件中提供所有的HTML、CSS和JavaScript代码。JavaScript应该包含一种在不同天气条件之间切换的方法(例如,一个函数或一组按钮),以演示每种天气条件的动画。
考察点:测试模型编程效果,对比动画和交互的实现。
结论:Claude 3.7 Sonnet Thinking效果最佳。在自动化编程效果方面,标准版与前一版本Claude 3.5 Sonnet效果相差不大。
模型输出结果如下:
Claude 3.7 Sonnet:界面符合提示词要求,动画美观度高,但没有实现提示词要求的按钮切换。
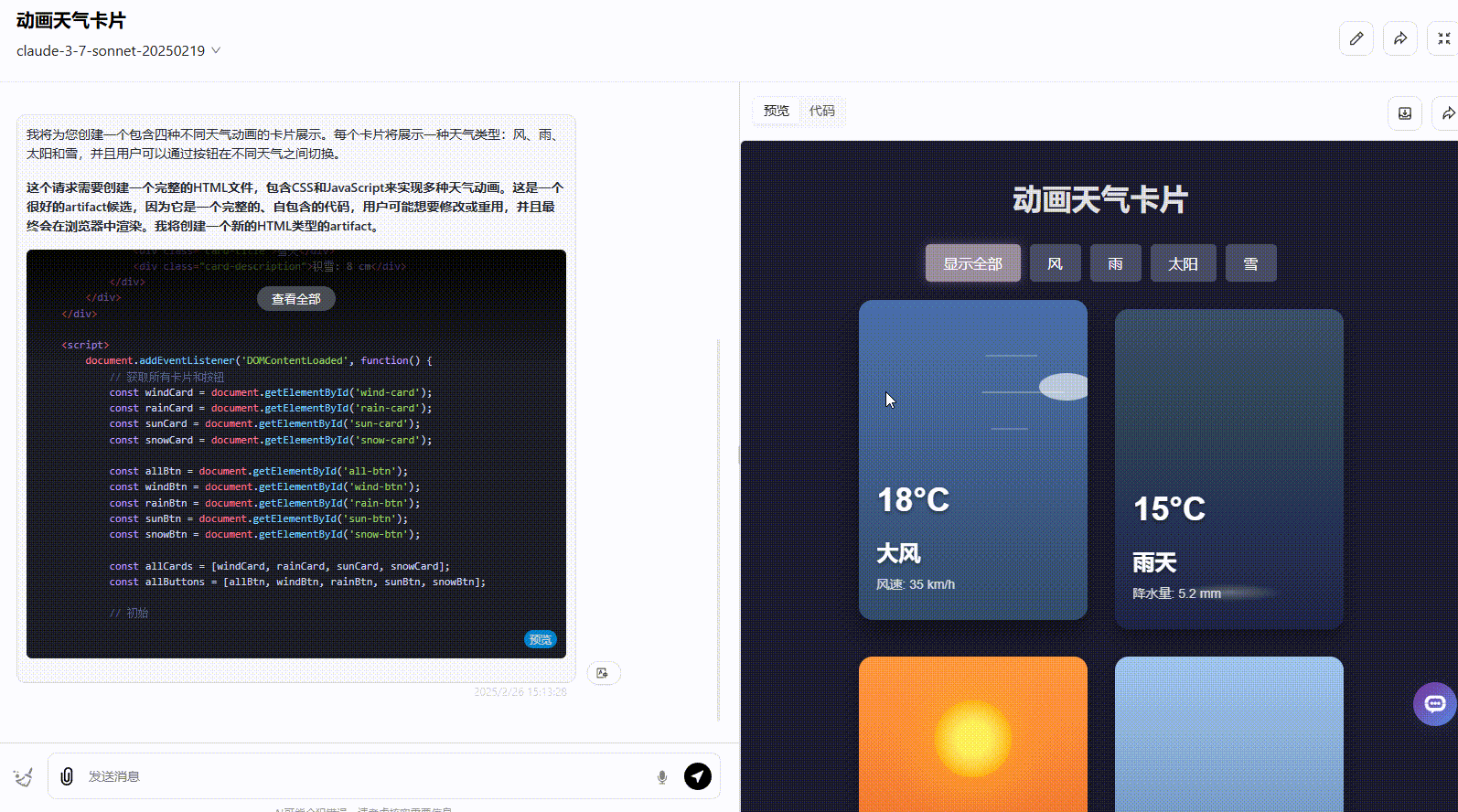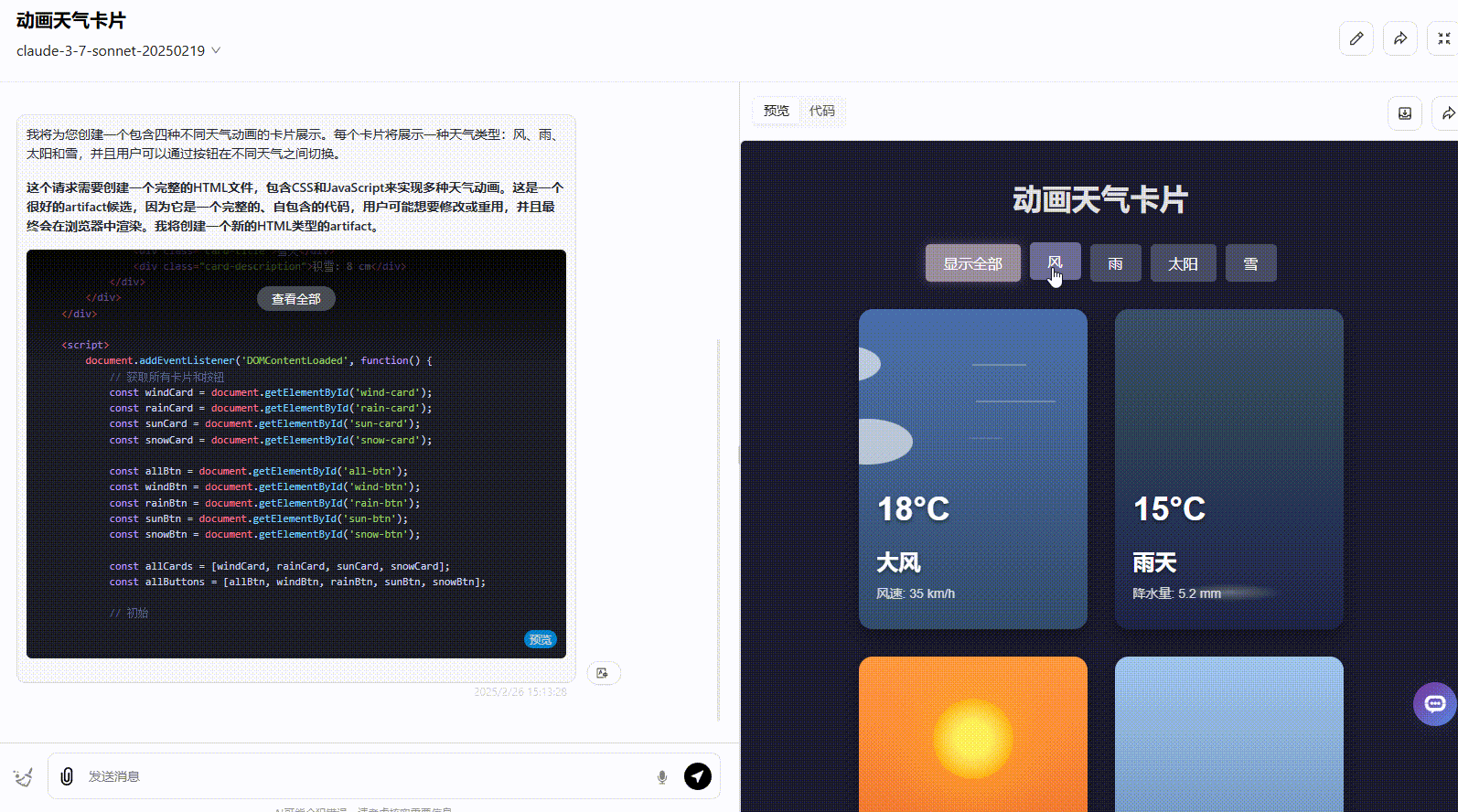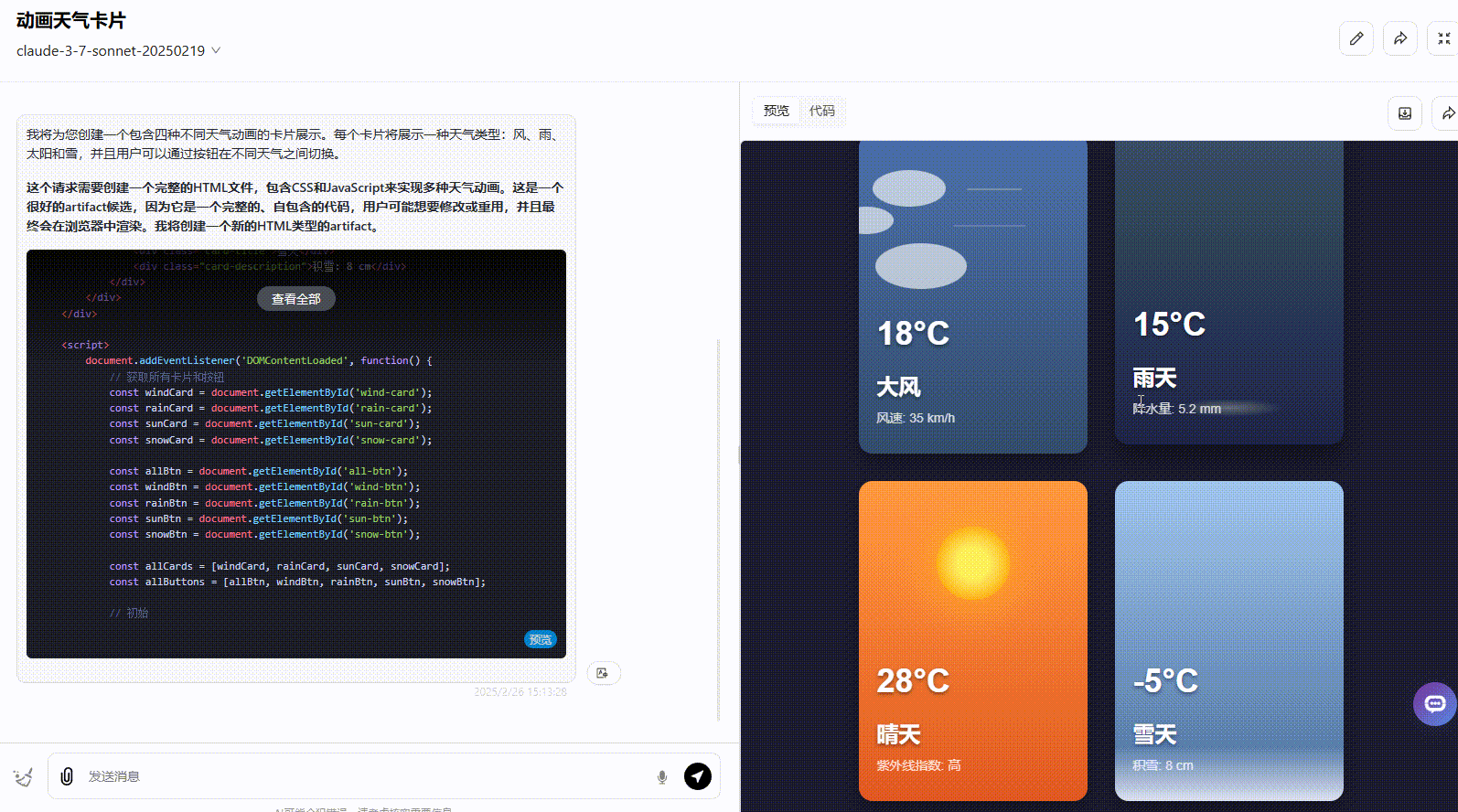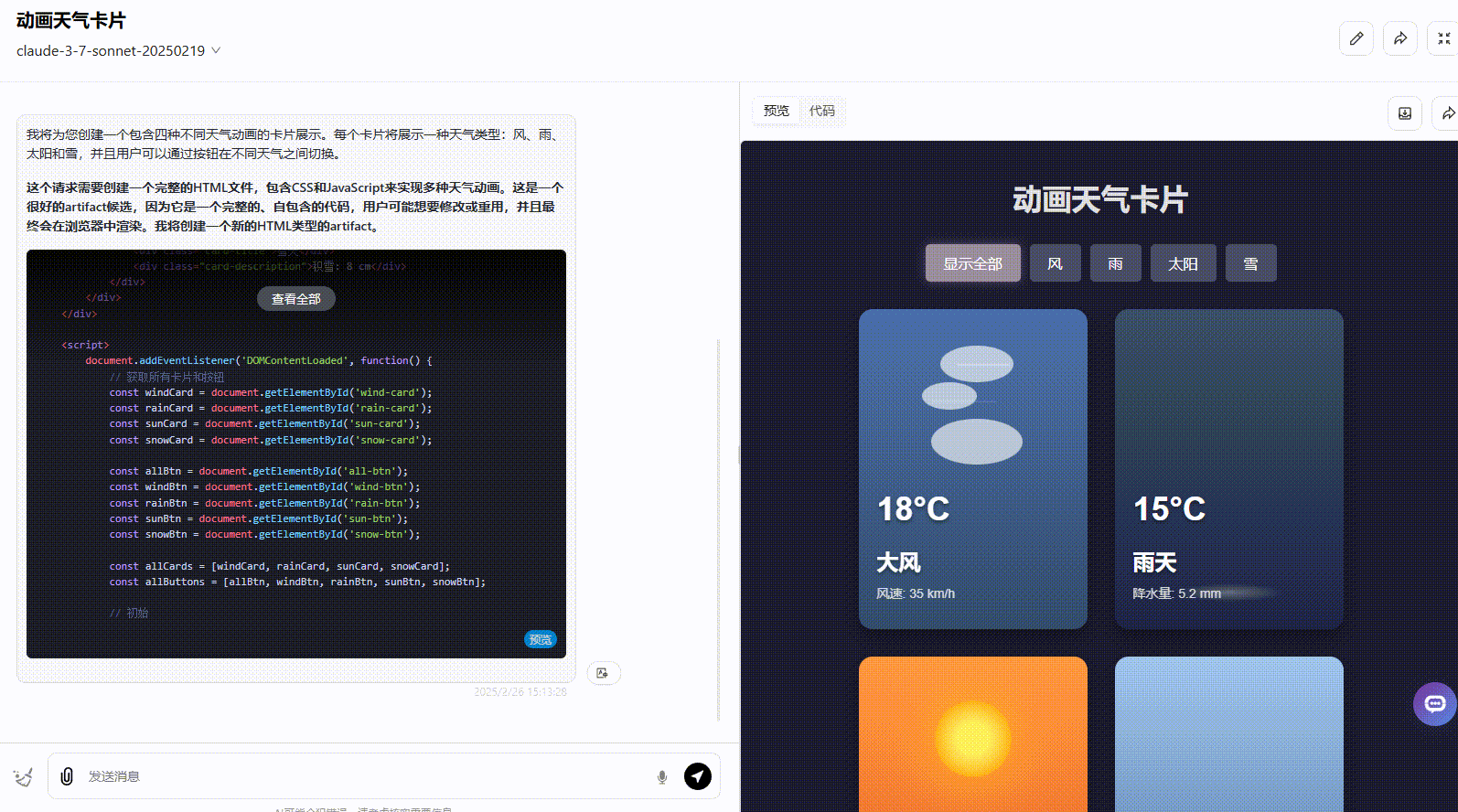
Claude 3.7 Sonnet Thinking:实现了所有要求功能,且界面动态美观度高。
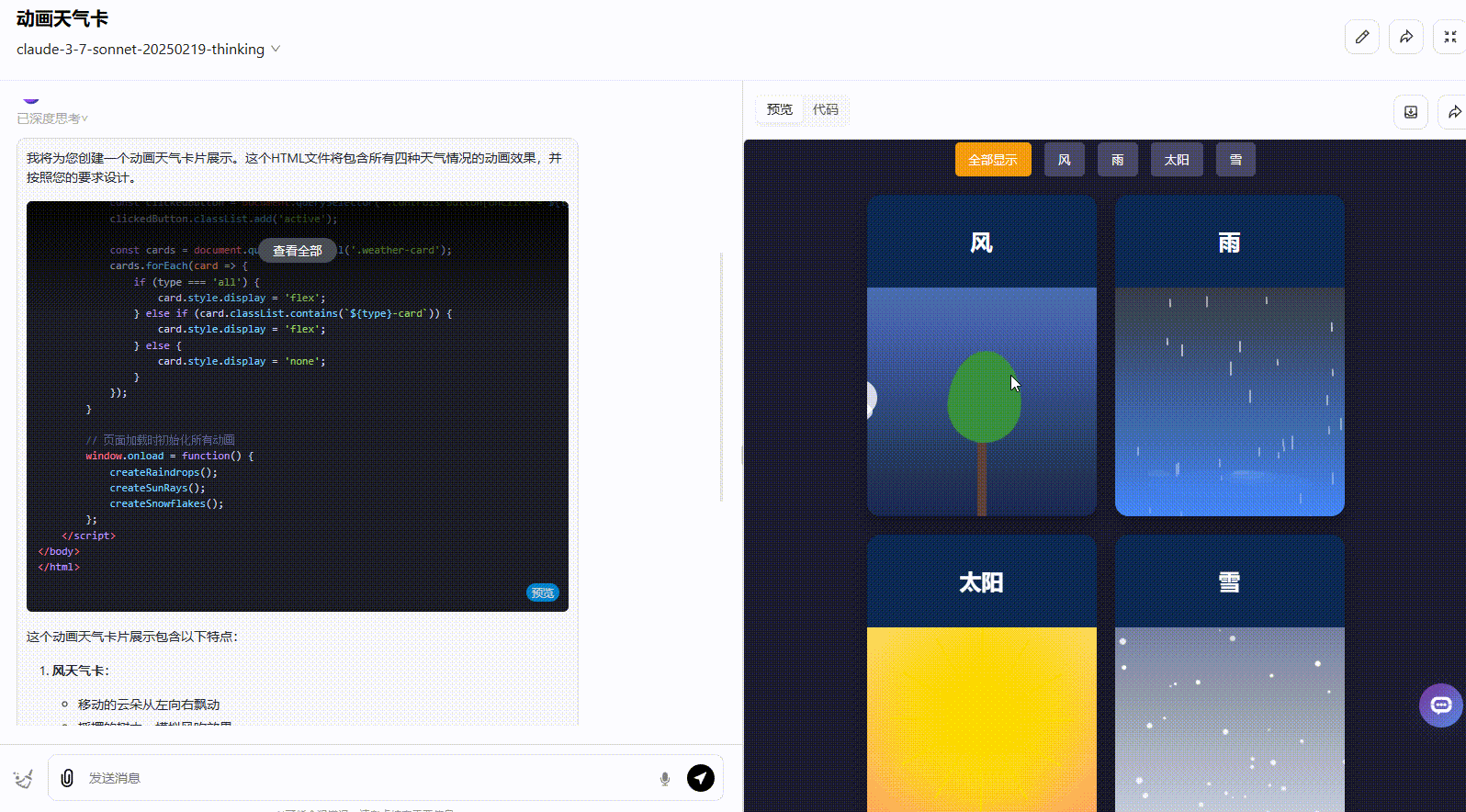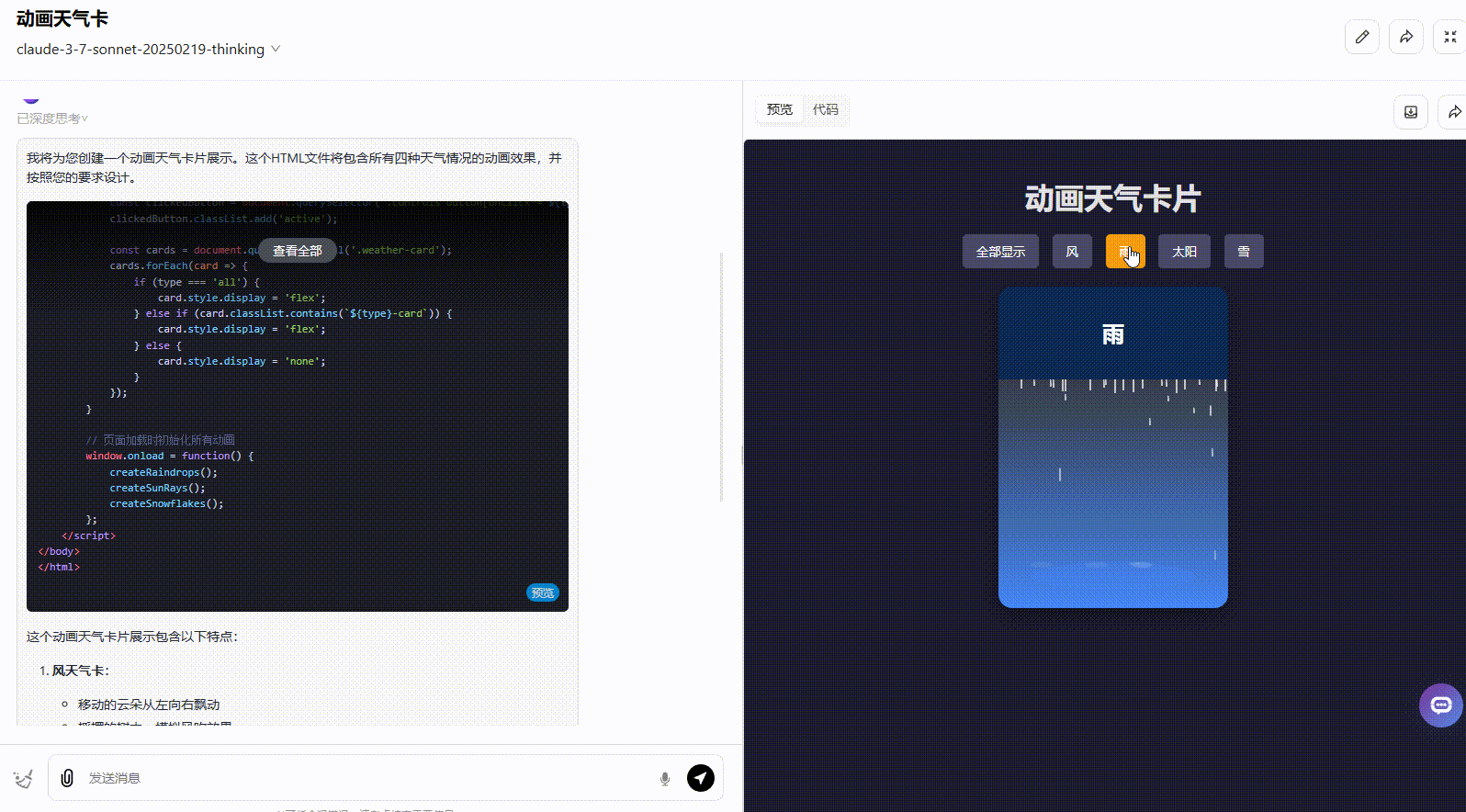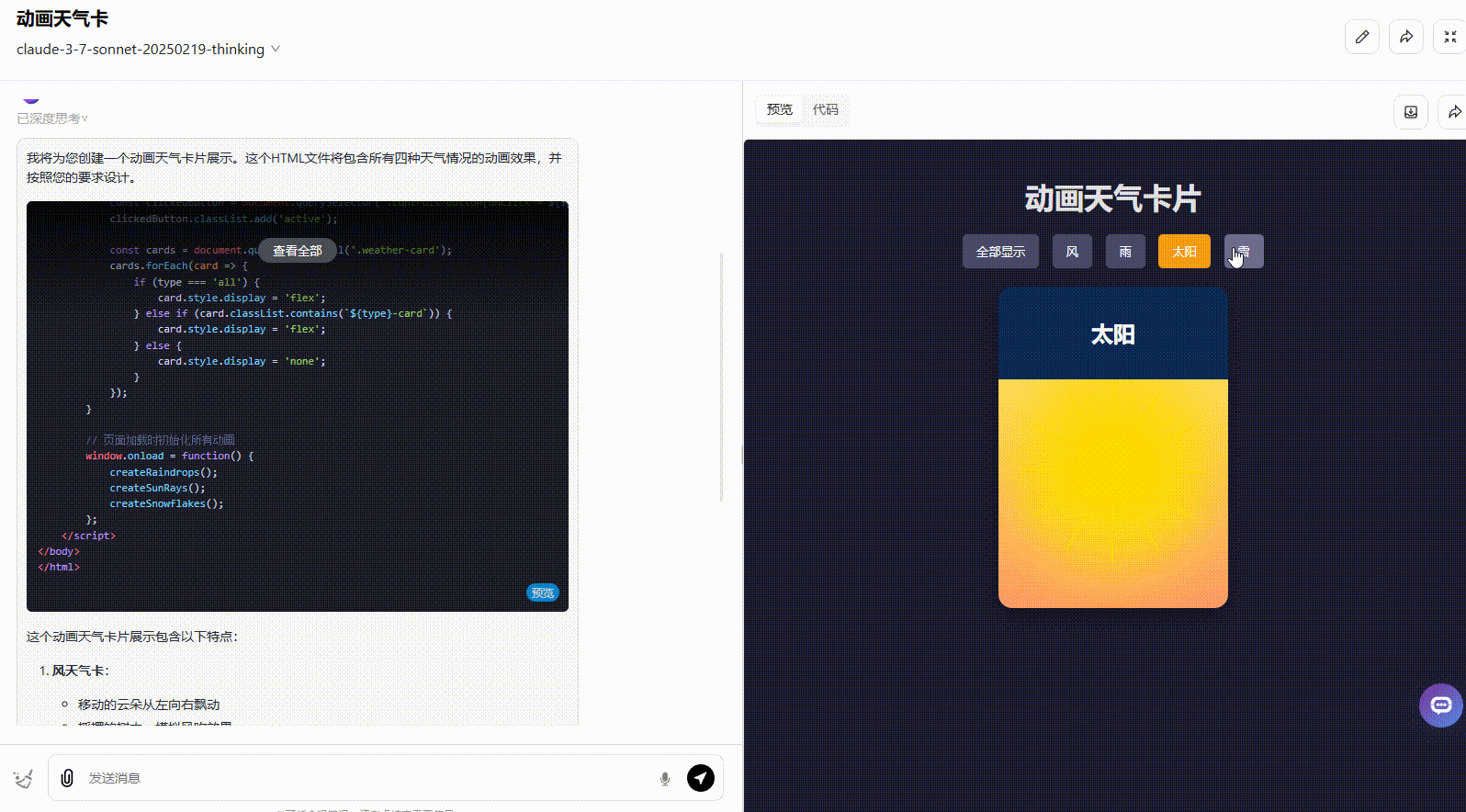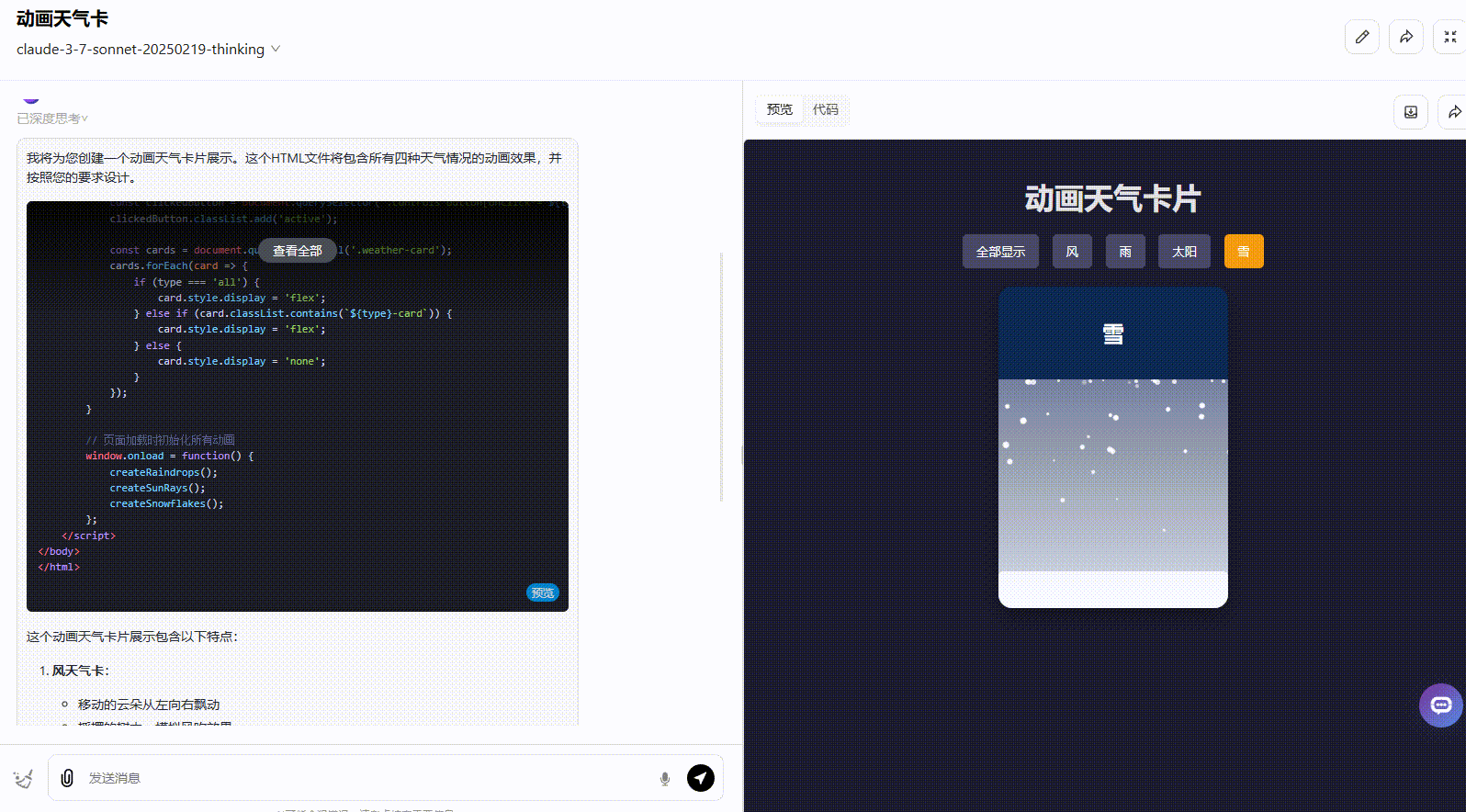
Claude 3.5 Sonnet:动态效果一般,按钮切换效果不够准确,应该实现在不同天气条件之间切换效果。
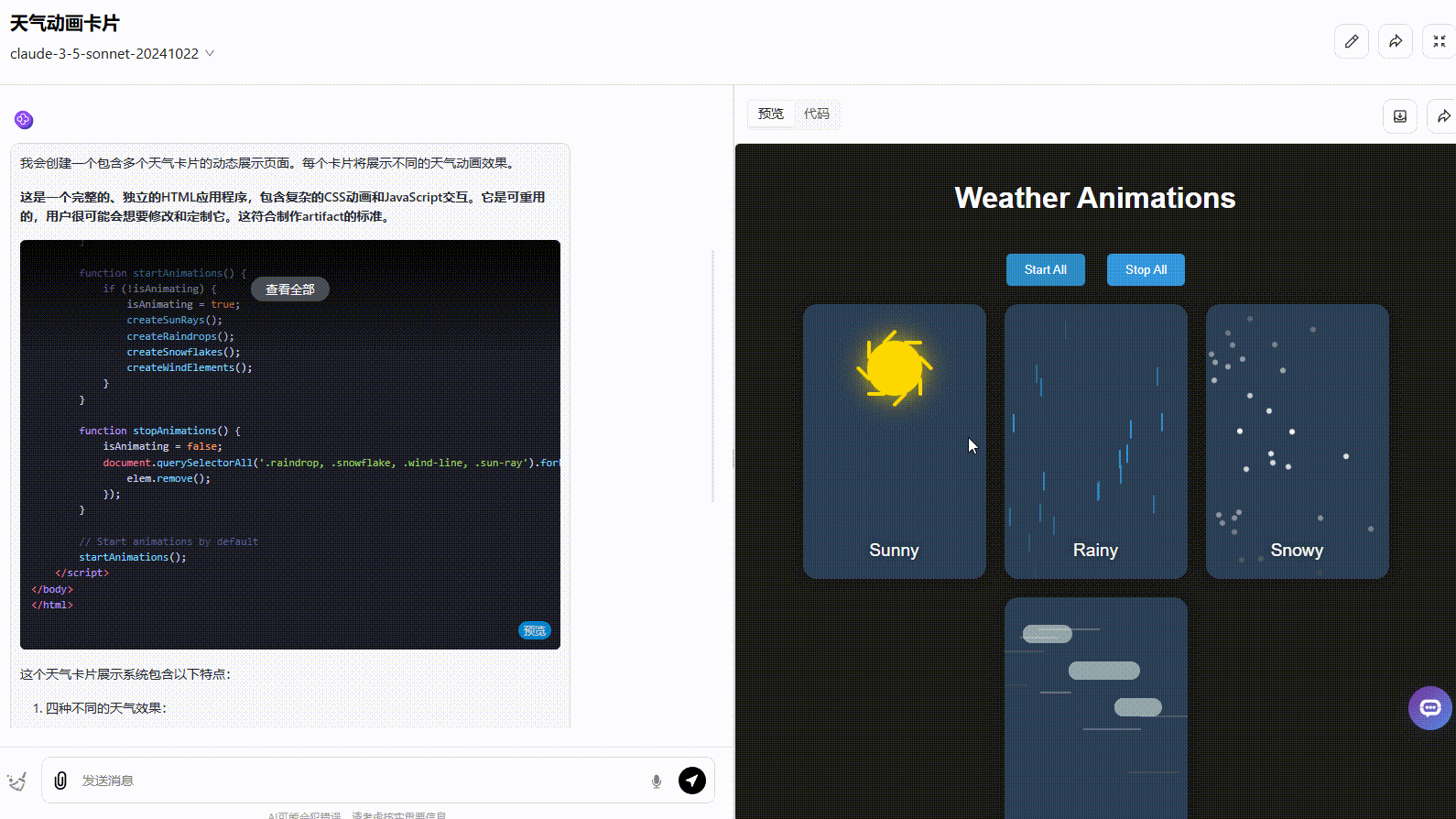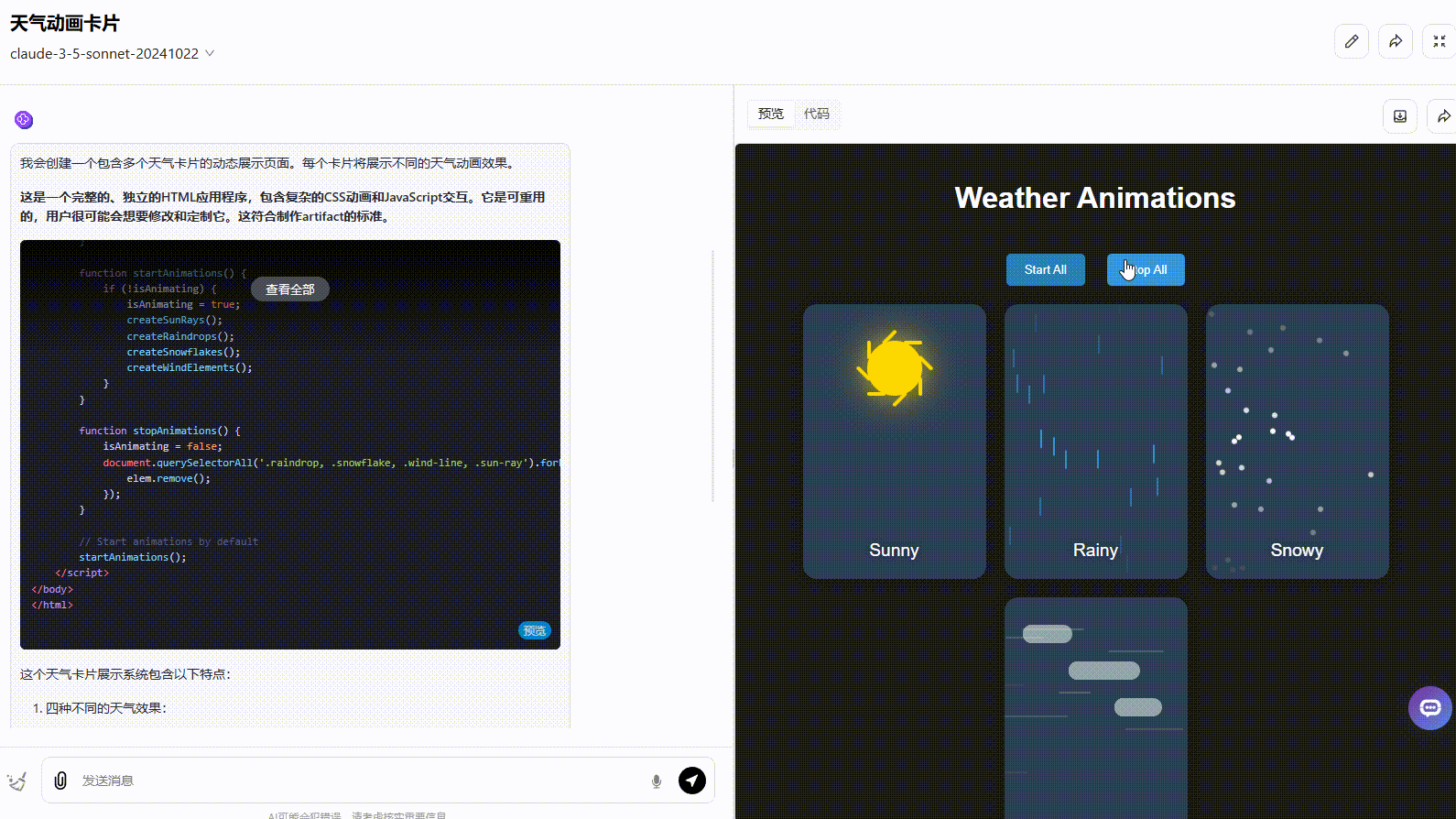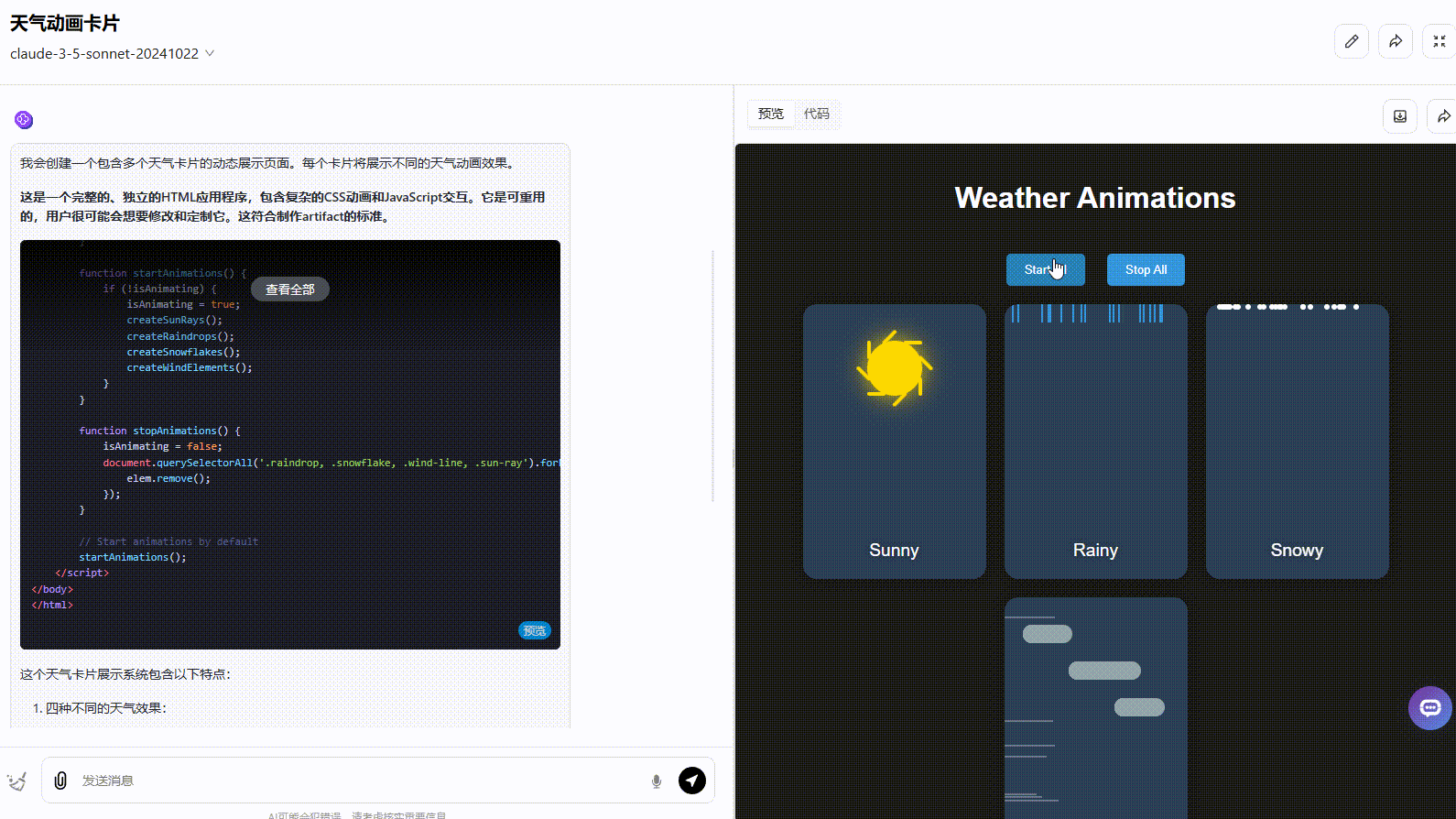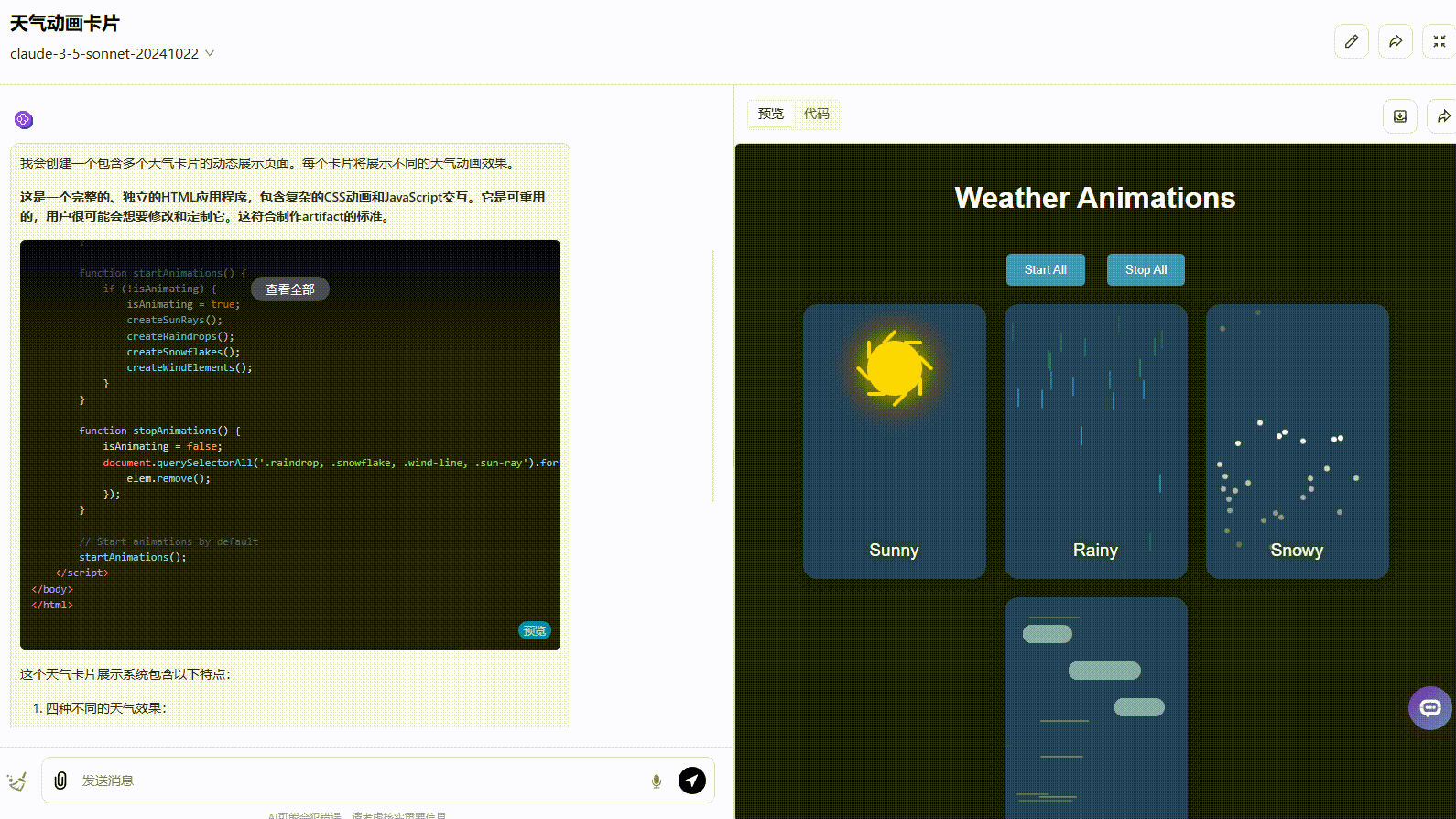
实测总结:
根据以上实测,可以初步得出以下结论:
(1)推理模式对开放性推理问题的积极影响
根据实测1可得:Claude 3.7 Sonnet Thinking能够促使模型更为深入地思考问题,进而获取正确答案,在处理开放性推理问题时,这种优势尤为突出。
(2)可视化思维过程与答案纠错能力未提高数学解题能力
根据实测2中可得:模型展示了可视化的思维过程,并具备反复检查答案的能力。然而,在面对较为复杂的数学问题时,这一能力并未能够提升答案的准确性,但这可以为用户的解题提供一定的思路启发。
(3)多模态能力标准版更优
根据实测3所示:Claude 3.7 Sonnet Thinking在多模态方面的表现一般,未及相标准版和前代模型。
(4)编程能力的比较与分析
综合实测4、5可得:在编程方面,Claude 3.7 Sonnet Thinking的能力较为出色,而Claude 3.7 Sonnet与Claude 3.5 Sonnet未呈现出显著的差异。
(5)不同场景下两种模式的表现差异
在实测过程中,我们发现标准模式和推理模式在很多案例中输出的答案几乎相似,不太具有参考意义。这也表明,在一些简单或直接的问题场景中,标准模式和推理模式的输出差异较小,难以体现出推理模式的深度思考能力。
通过深入实测Claude 3.7 Sonnet两种模式,可以发现两种模式各有优劣,希望用户可以结合个人需求选择使用。
在302.AI上使用Claude 3.7 Sonnet/Claude 3.7 Sonnet Thinking模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
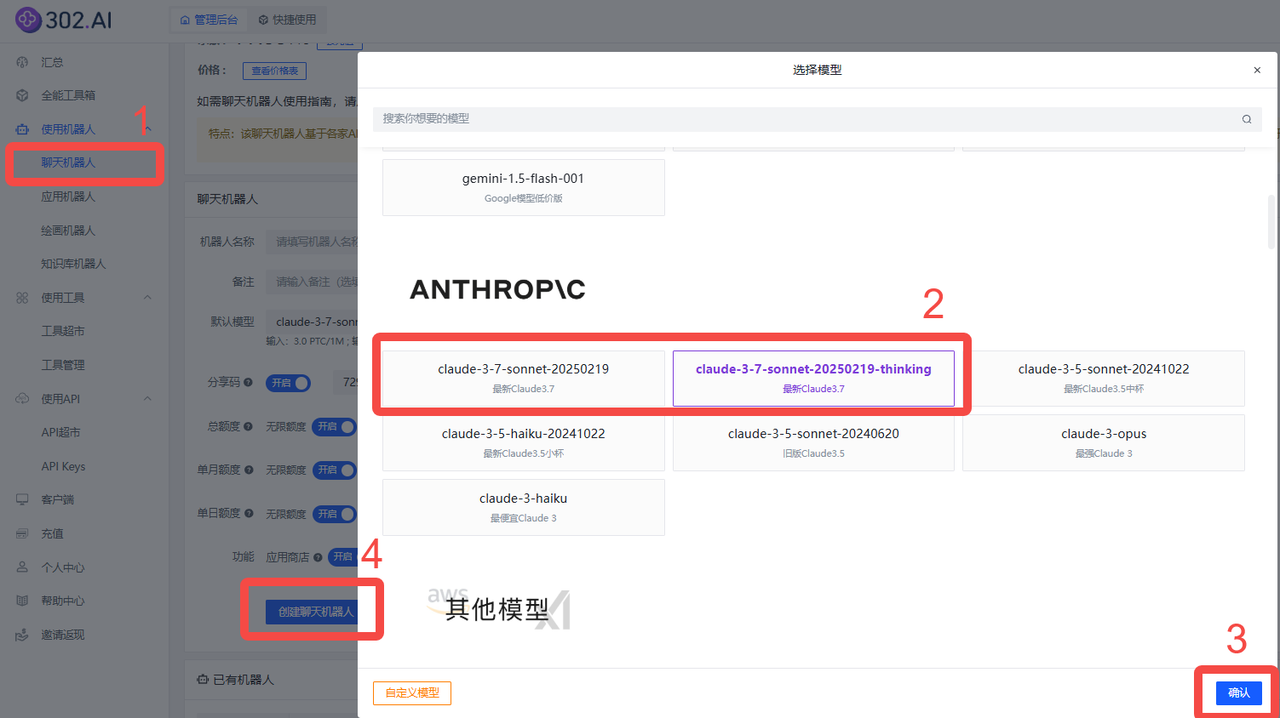
1、使用模型对话
依次点击使用机器人→聊天机器人→ 模型→按需选择如claude-3-7-sonnet-20250219-thinking→ 创建聊天机器人;
【claude-3-7-sonnet-20250219-thinking即官方的claude 3.7 sonnet推理模式(Extended),我们将思考过程改造成了DeepSeek-R1的返回格式】
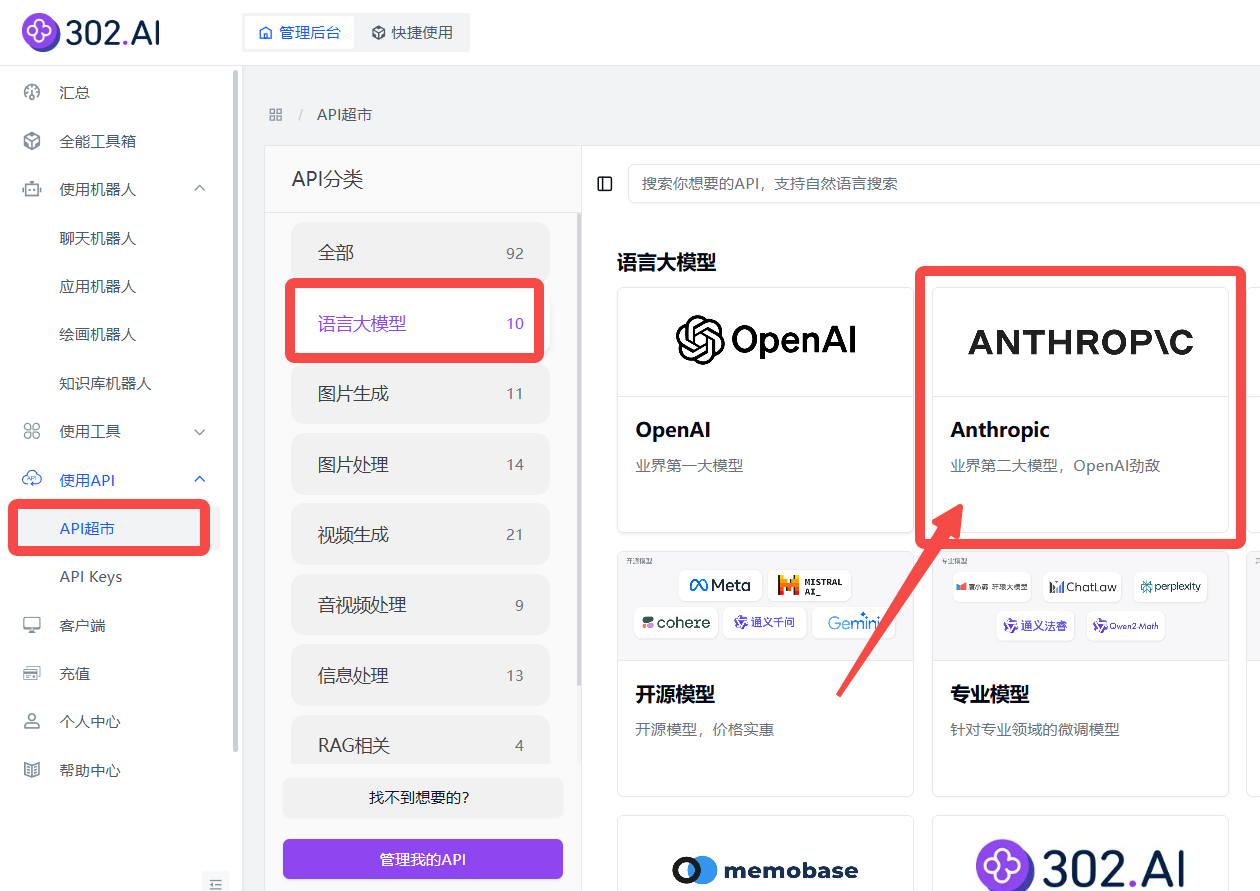
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
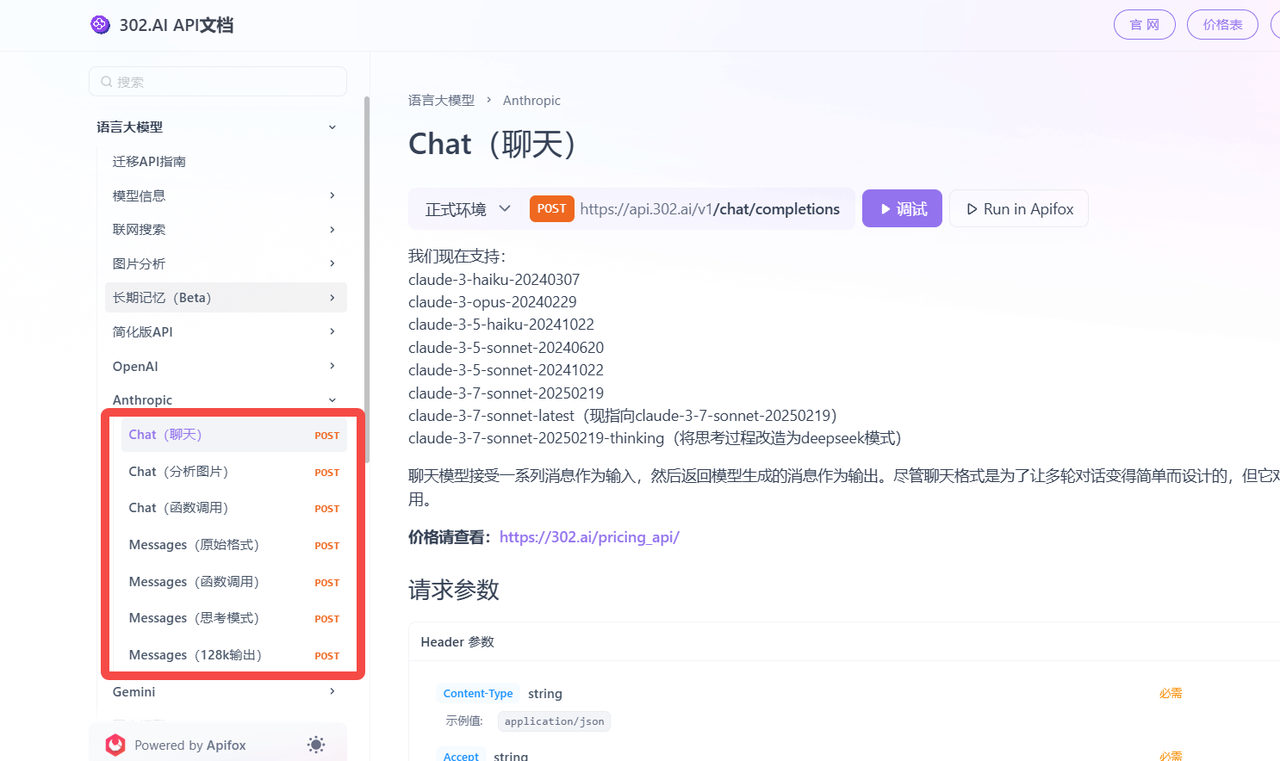
相关文档:使用API→API超市→语言大模型→Anthropic→查看文档;
进入文档后可按需选择使用: