
12月6日,Meta AI推出了新开源模型Llama 3.3 70B。Meta AI副总裁Ahmad Al-Dahle在社交媒体平台发布的一篇帖子中表示,这款仅支持文本的Llama 3.3 70B模型与Meta最大型模型Llama 3.1 405B的性能相当,但运行起来更简单、更经济高效。


据了解,Llama 3.3 70B上下文长度为128K,是一款自回归(auto-regressive)语言模型,使用优化的transformer架构,其调整版本使用了监督式微调(SFT)和基于人类反馈的强化学习(RLHF),以符合人类对有用性和安全性的偏好。
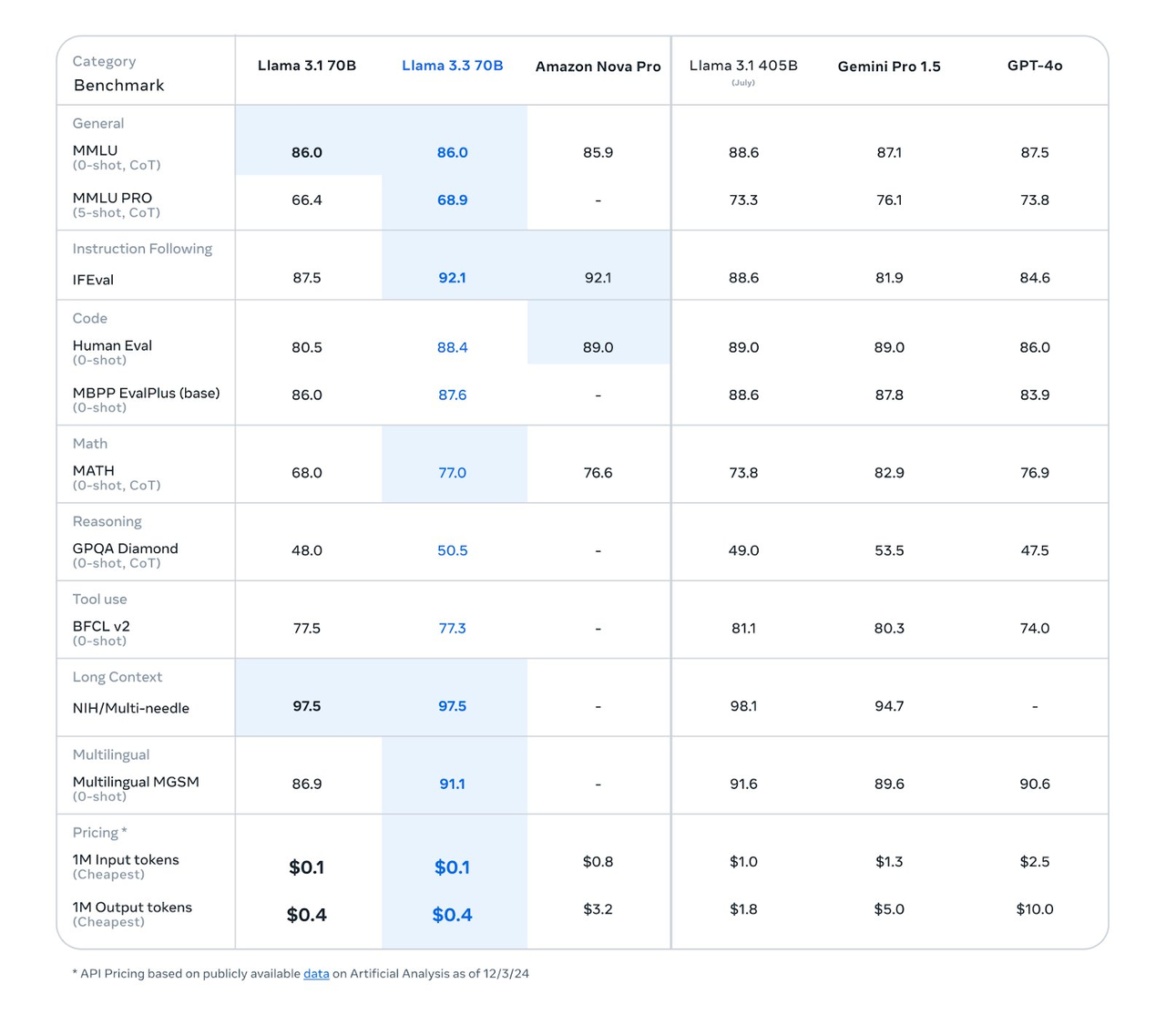
在针对大模型语言理解能力的一系列行业基准测试之中,Llama 3.3 70B的表现优于谷歌的Gemini 1.5 Pro、OpenAI的GPT-4o等模型。其中,在指令遵循(IFEval)、数学(MATH)、推理(GPQA Diamond)等领域,水平更是都超过了自家的大型模型Llama 3.1 405B。不仅如此,在语言(MMLU)、代码(HumanEval)、长文本和多语种能力上,成绩也和Llama 3.1 405B比较接近。
> 在302.AI上使用
按照惯例,302.AI第一时间上线了Llama 3.3 70B模型,用户可以在聊天机器人或者API超市获取该模型,而且302.AI提供按需付费的使用方式,无捆绑套餐和月费,更灵活便捷!以下是具体的步骤:
【聊天机器人】
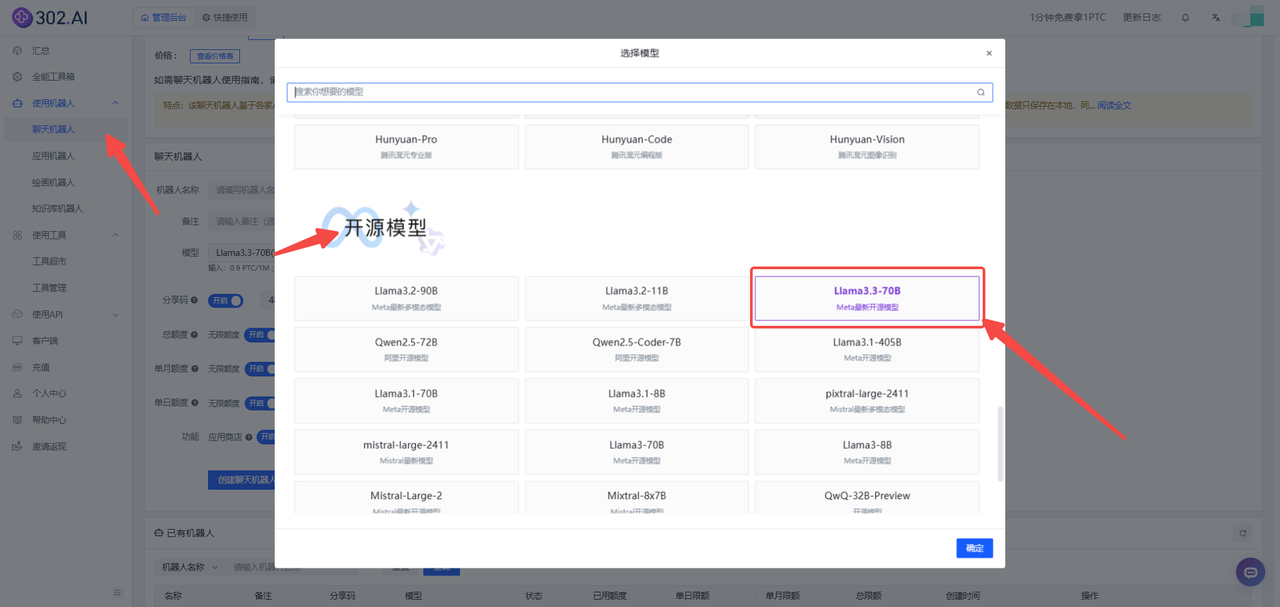
进入302.AI,在左侧菜单栏点击【使用机器人】——【聊天机器人】——选择【模型】——下滑至开源模型找到【Llama-3.3-70B】——点击【确定】按钮,最后创建聊天机器人即可。
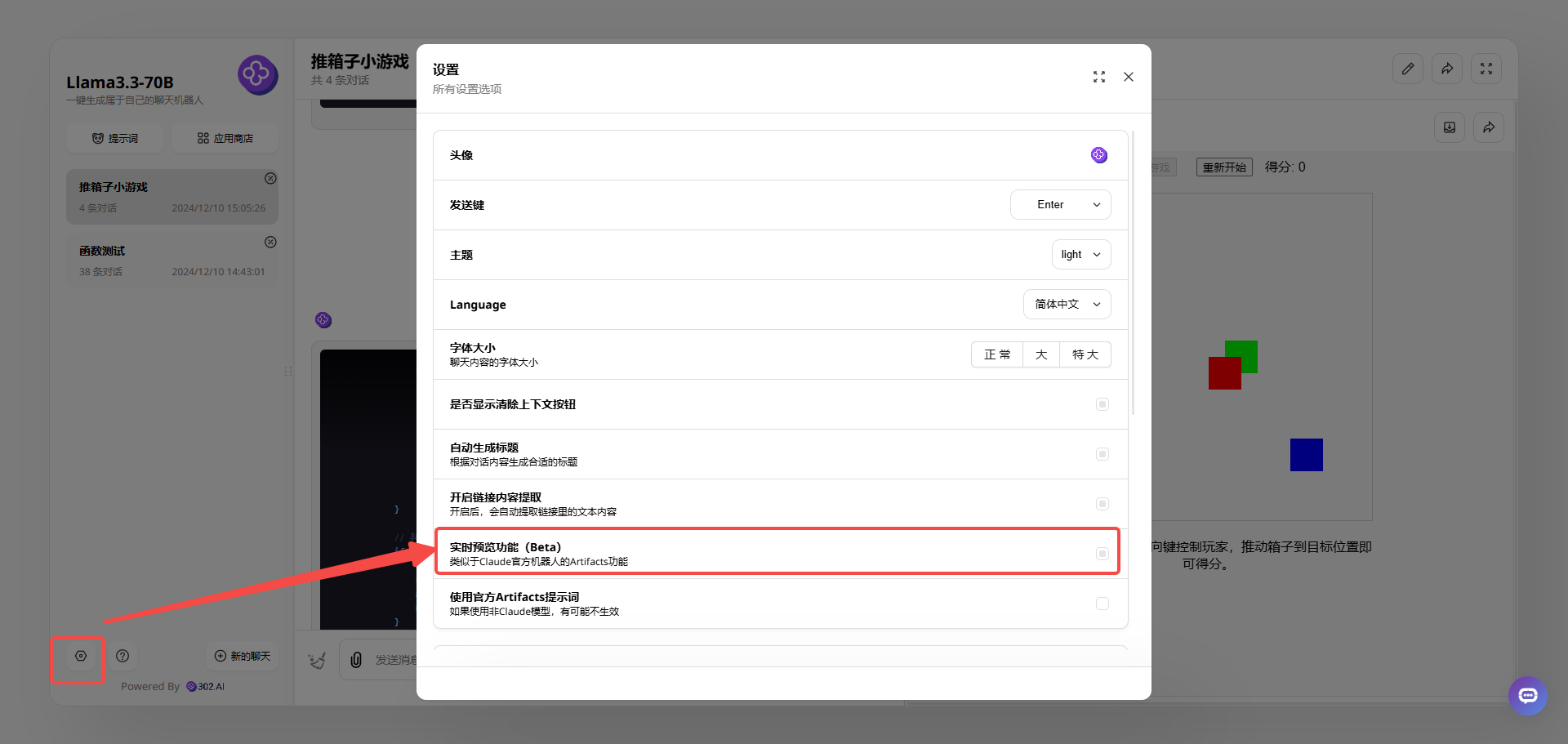
点击左下角的设置,即可打开Artifacts功能。
【API超市】
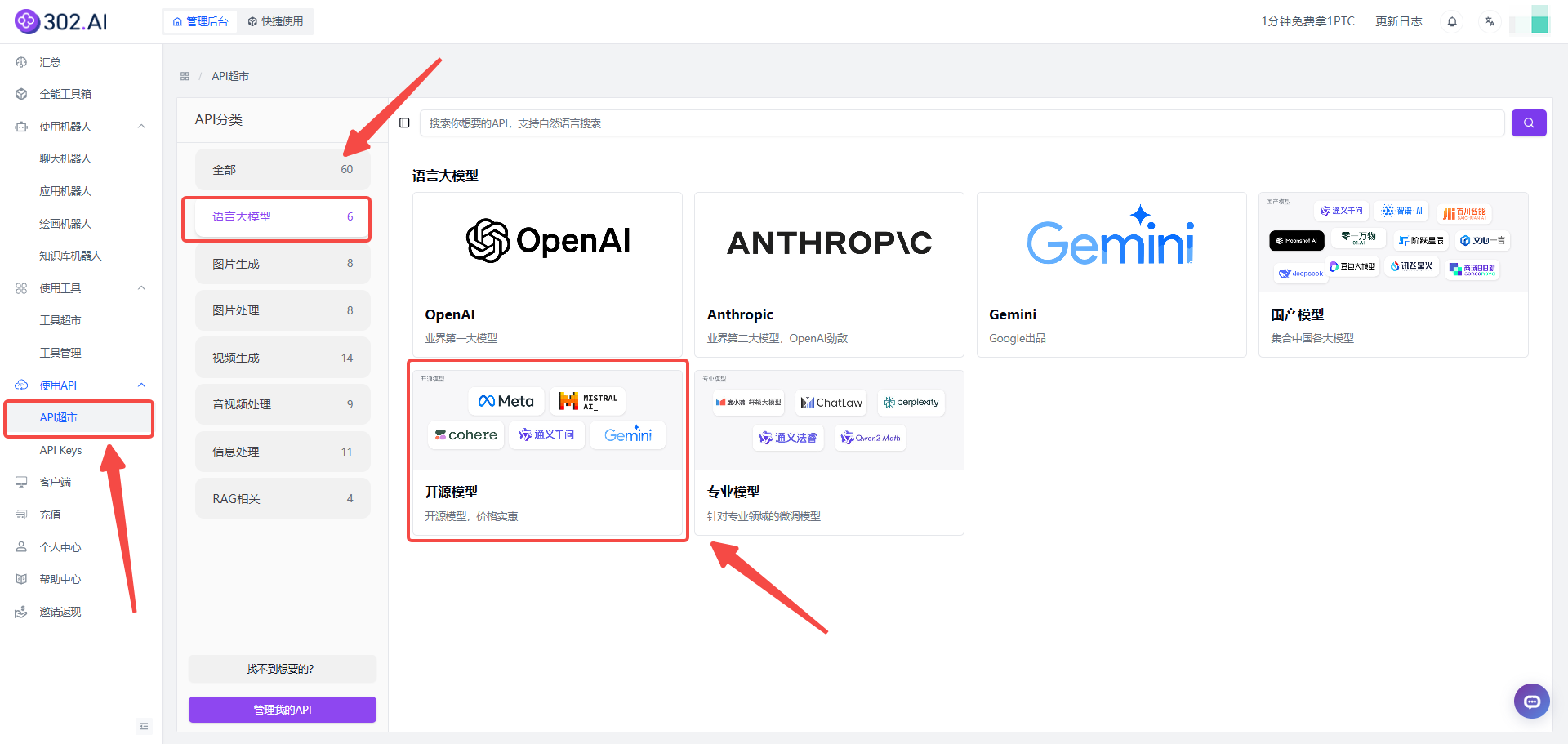
在左侧菜单栏点击【使用API】——【API超市】——分类中选择【语言大模型】——【开源模型】。
接下来可以选择【查看文档】或者【在线体验】功能。
【查看文档】:可帮助用户快速接入模型API;
【在线体验】:则可以更高效地对模型参数进行测试;
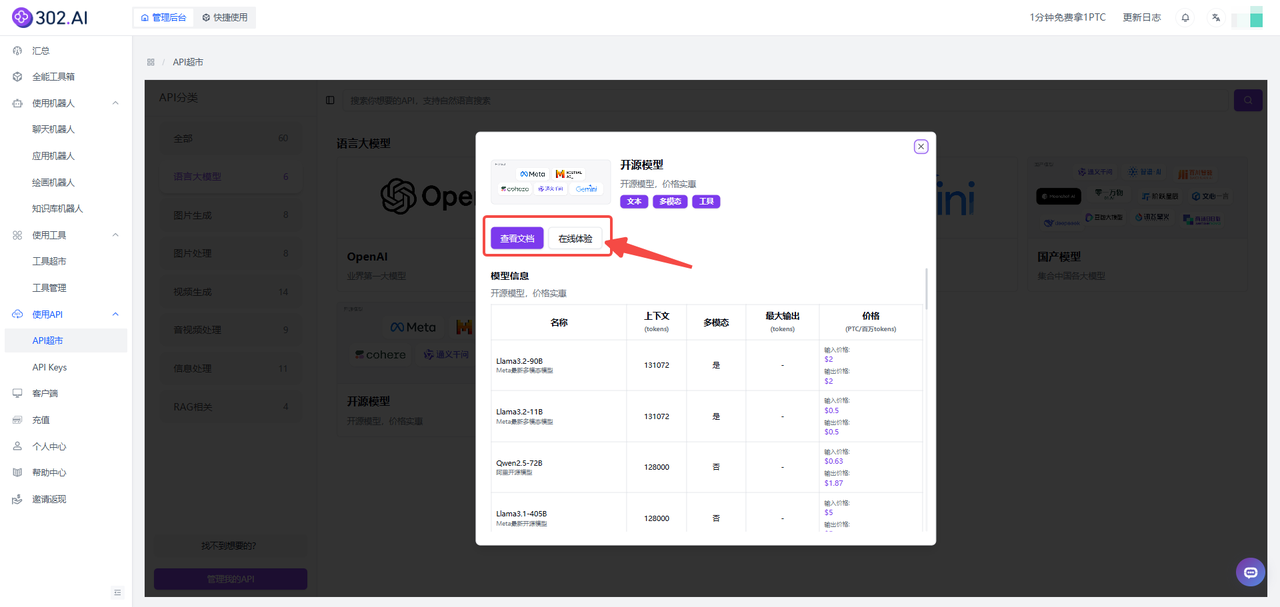
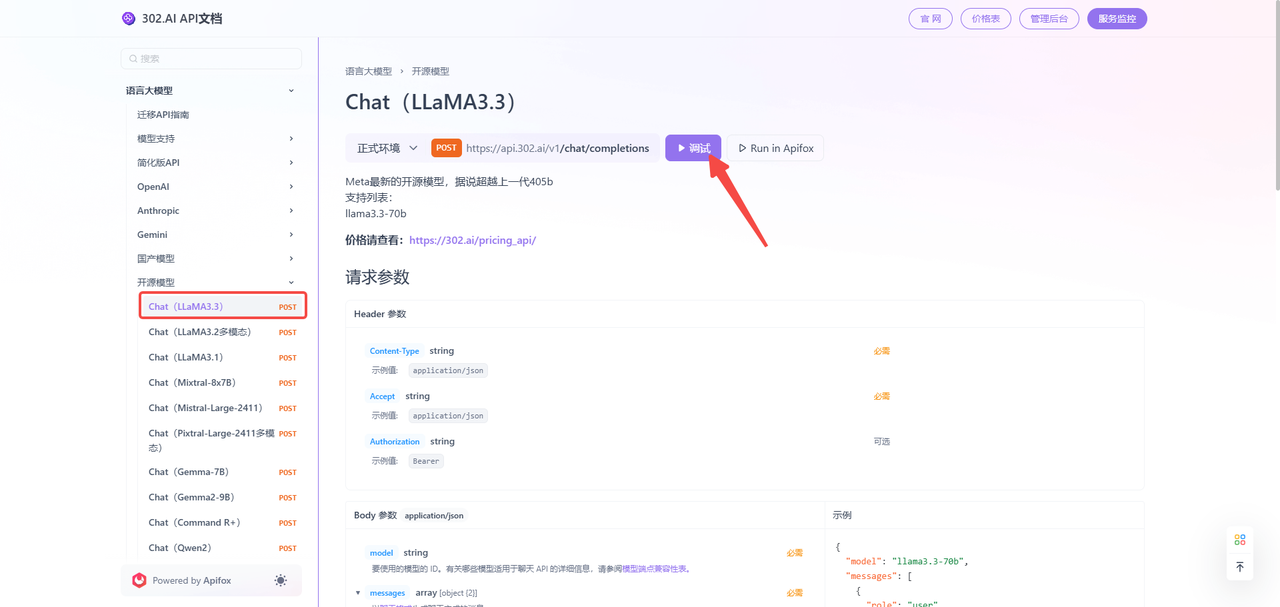
以【查看文档】为例,进入后点击左侧开源模型,然后选择Chat(LLaMA3.3)即可。
> 实测模型对比
对比模型:Llama 3.3 70B、Llama 3.1 405B、GPT-4o-2024-11-20
一、语言、推理逻辑测试
除了聊天机器人和API超市,用户还可以通过302.AI的模型竞技场直观对比不同模型的效果。
第一部分实测将会通过302.AI的模型竞技场对比模型中文支持、推理逻辑方面的表现。
实测1:中英文提示词对比测试:
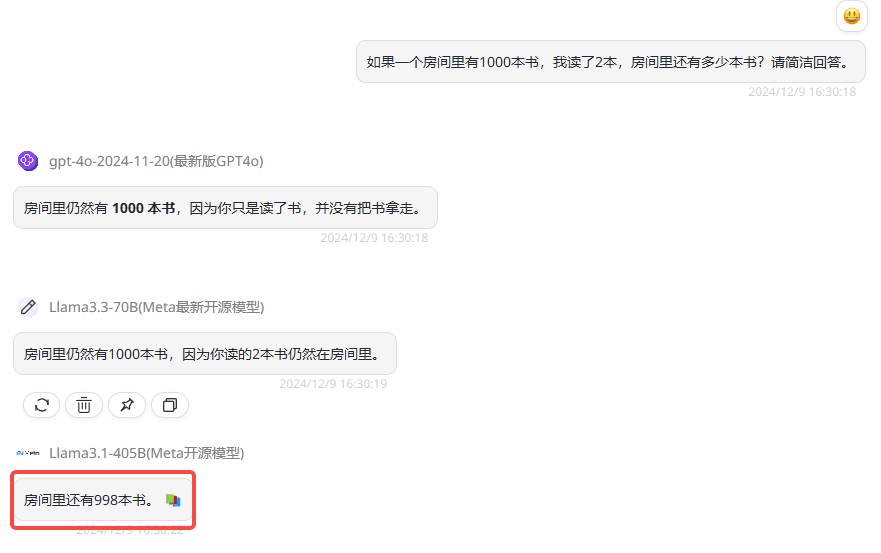
提示词:如果一个房间里有1000本书,我读了2本,房间里还有多少本书?请简洁回答。
分析:这是前段时间在国外比较火的逻辑测试题目,题目本身非常简单,但这个“简单”是相对于我们人类来说的,对于大语言模型来说,这属于一个“陷阱型”题目,非常容易答错。下面看下三个模型的回答:
GPT-4o-2024-11-20:解释正确,回答正确。
Llama 3.3 70B:即使使用中文提示词提问,也没有出现模型幻觉,回答正确。
Llama 3.1 405B:回答错误,405B模型存在一个明显的问题,当使用中文提示词提问,模型更容易出现幻觉。
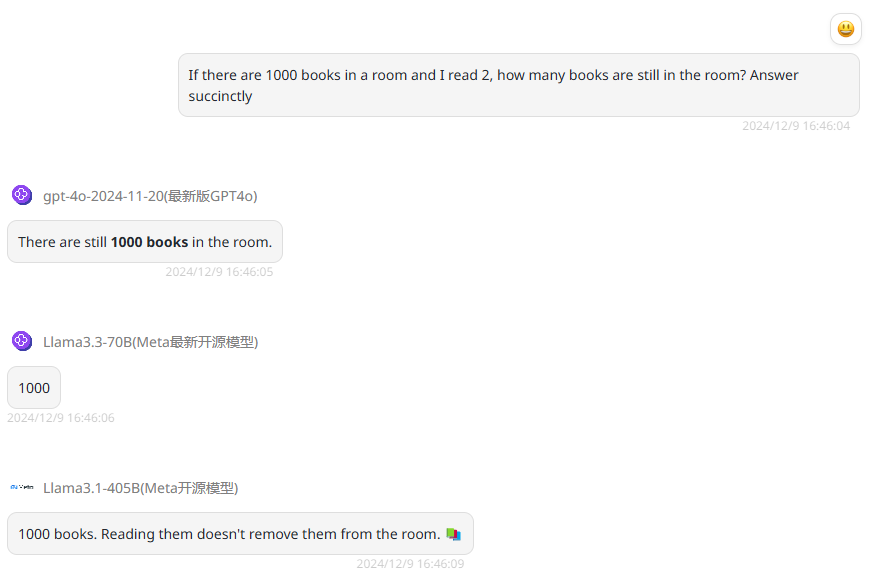
英文提示词提问结果如下,三个模型都是回答正确的:
实测2:中文繁体支持测试:
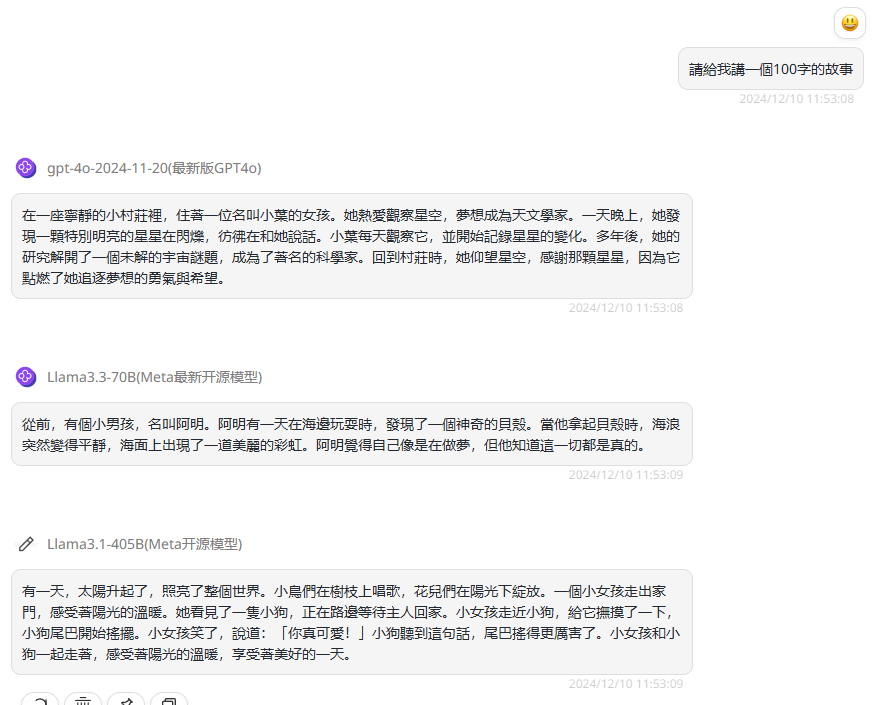
提示词:請給我講一個100字的故事
分析:在面对中文繁体提示词提问的情景下,三个模型都能够转换成中文繁体回答。
GPT-4o-2024-11-20:中文繁体支持。
Llama 3.3 70B:中文繁体支持。
Llama 3.1 405B:中文繁体支持。
实测3:逻辑推理测试
提示词:

分析:这是经典的逻辑分析题,正确答案是选项B。
GPT-4o-2024-11-20:答案非常长,最终的结果是正确的。

Llama 3.3 70B:分析错误,回答错误。
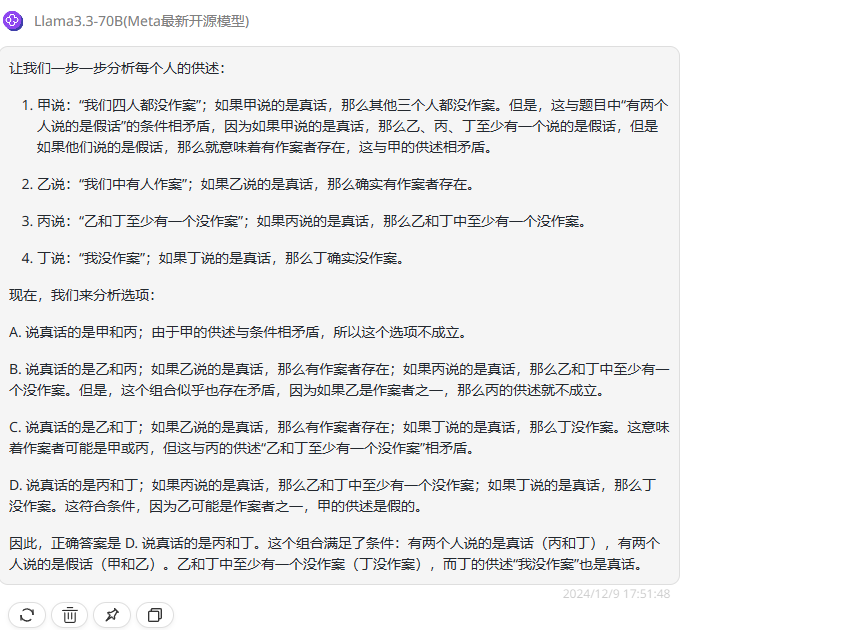
Llama 3.1 405B:分析错误,回答错误。

二、编程测试
第二部分为编程测试,分为编程正确性检验和编程效果对比两部分内容。
实测1、2会借助编程学习平台,从平台中找到简单-困难两种级别的编程题目提问模型,模型生成代码后,会粘贴到平台上检验对比结果。
实测3则是通过使用302.AI聊天机器人的Artifacts功能预览各模型的代码实现效果,并进行对比。
实测1:编程正确性检验-简单级别
提示词:

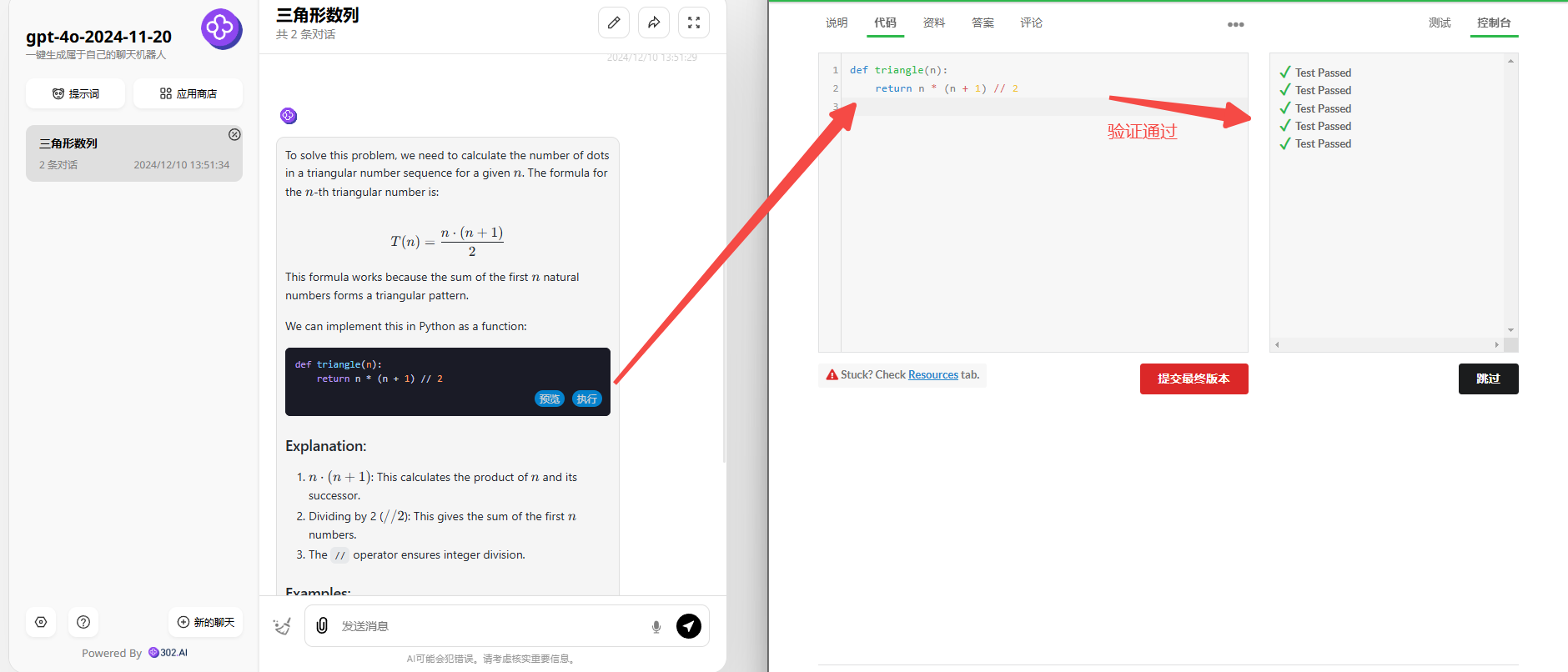
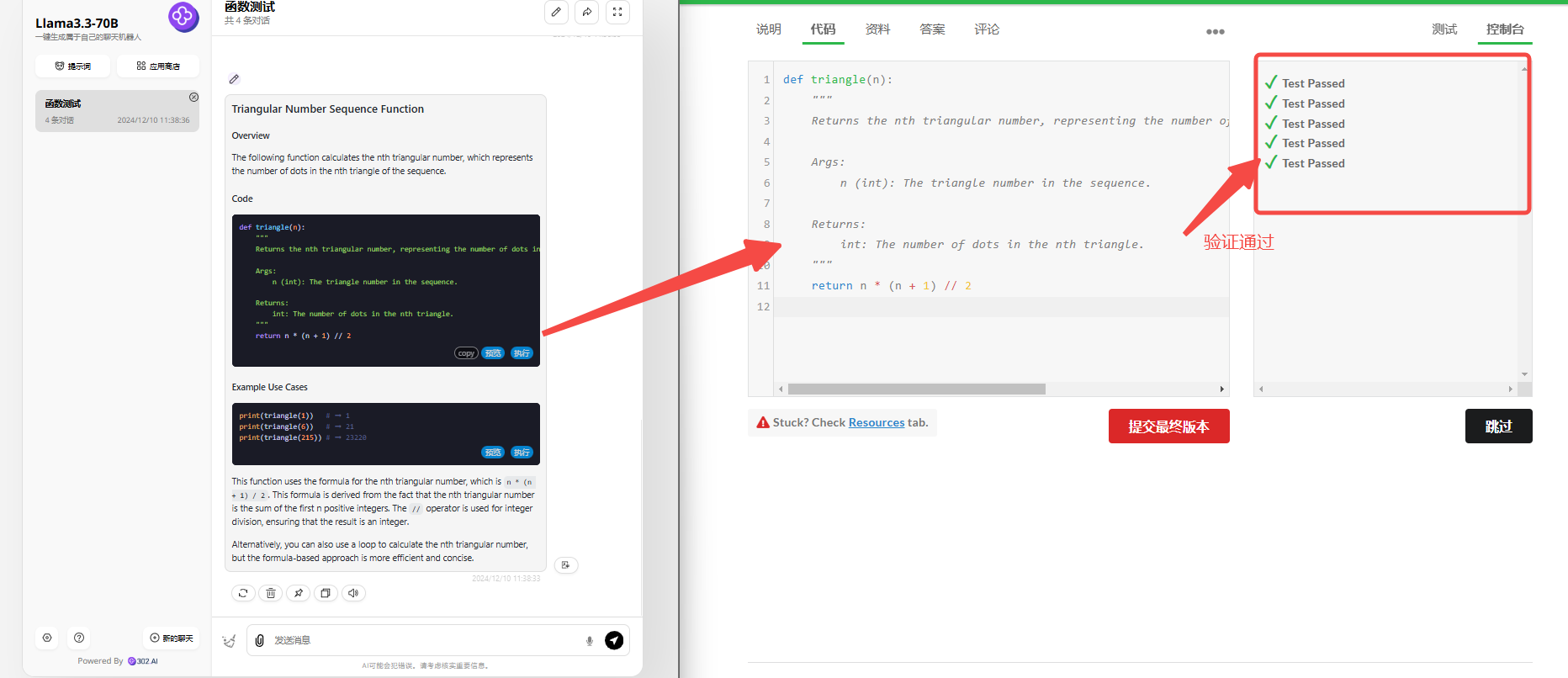
分析:题目一属于简单级别的算法编程题目,需要模型根据要求编写一个函数,当给定序列中对应的三角形数时,返回点的个数。
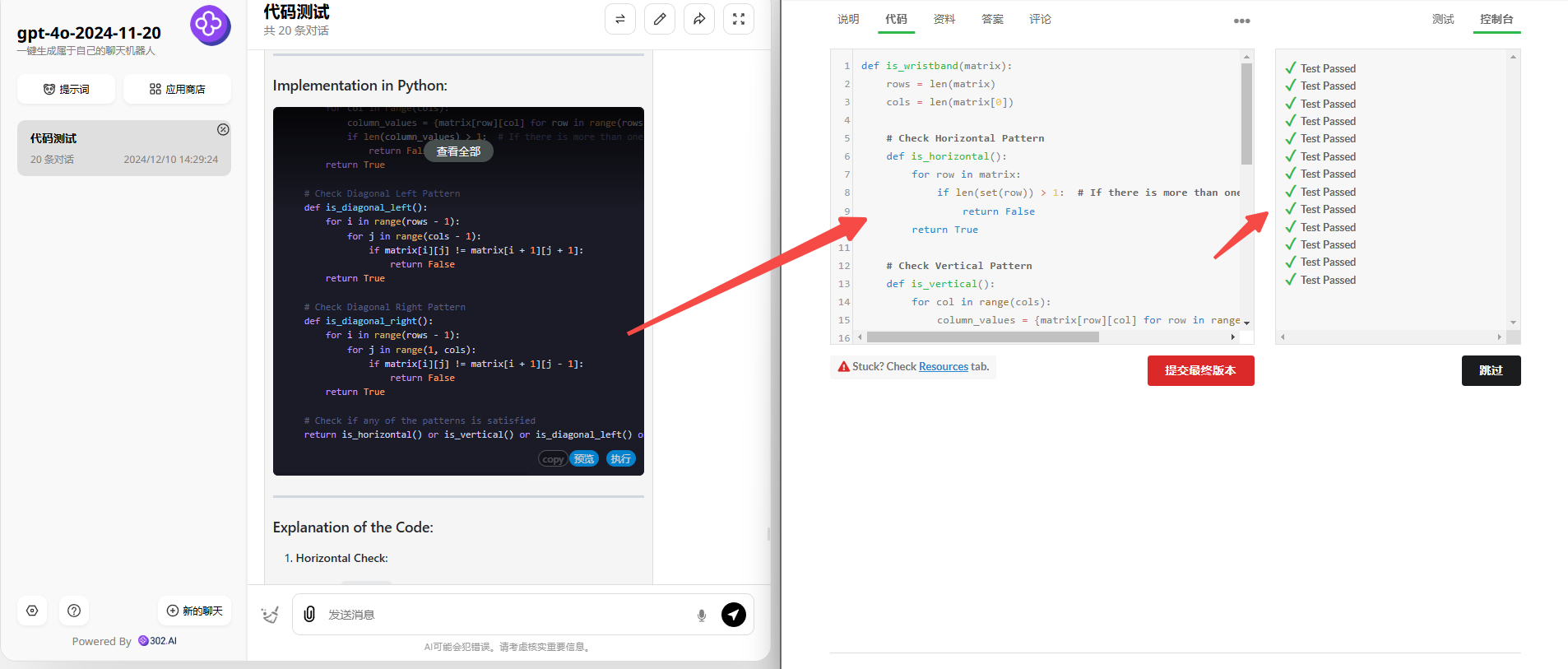
GPT-4o-2024-11-20:代码非常简洁,验证通过!
Llama 3.3 70B:可以看到,Llama会给出两个版本的代码,一个是详细版本,另一个是简洁版本,经过验证都是正确。
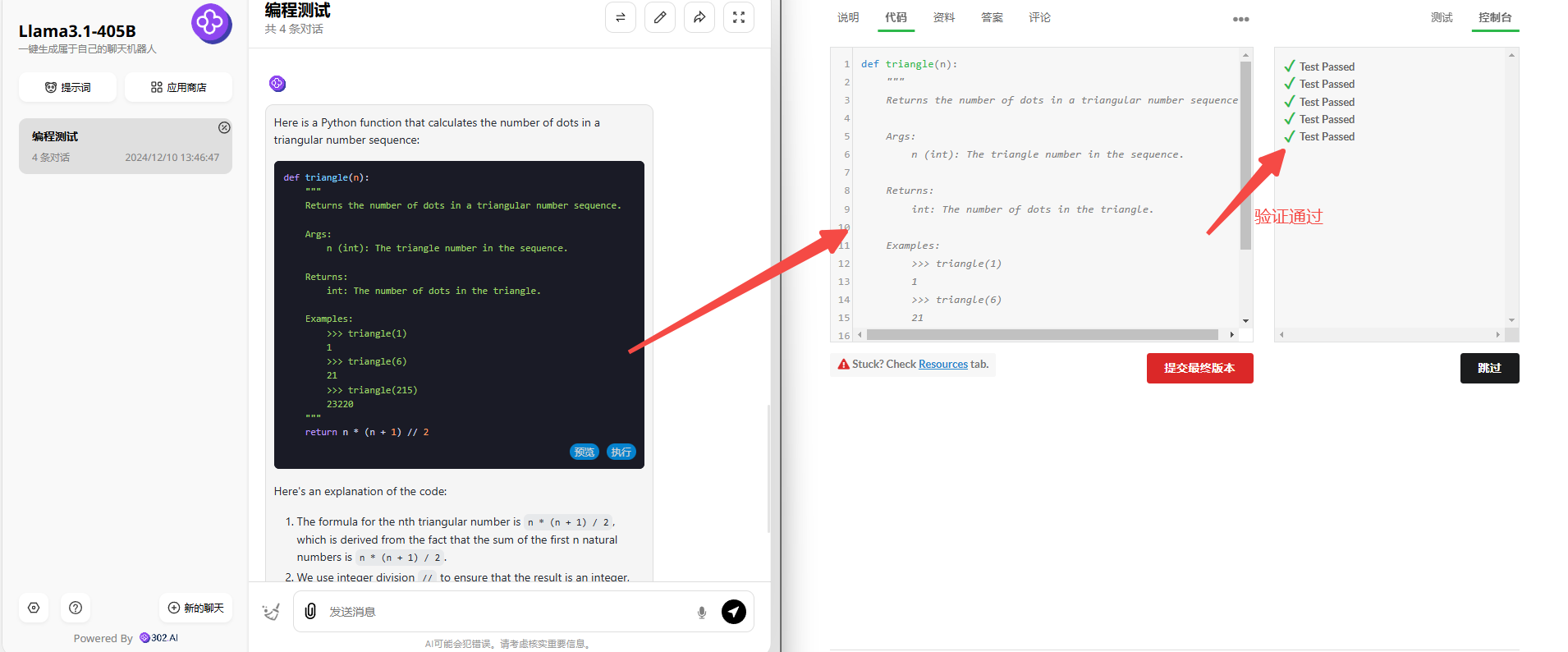
Llama 3.1 405B:Llama 3.1 405B生成的代码也没问题,验证通过。
实测2:编程正确性检验-困难级别
提示词:

分析:编程检验第二题为非常困难级别,如下三个模型的答案:
GPT-4o-2024-11-20:非常困难级别也没有难倒最新版GPT-4o,验证通过。
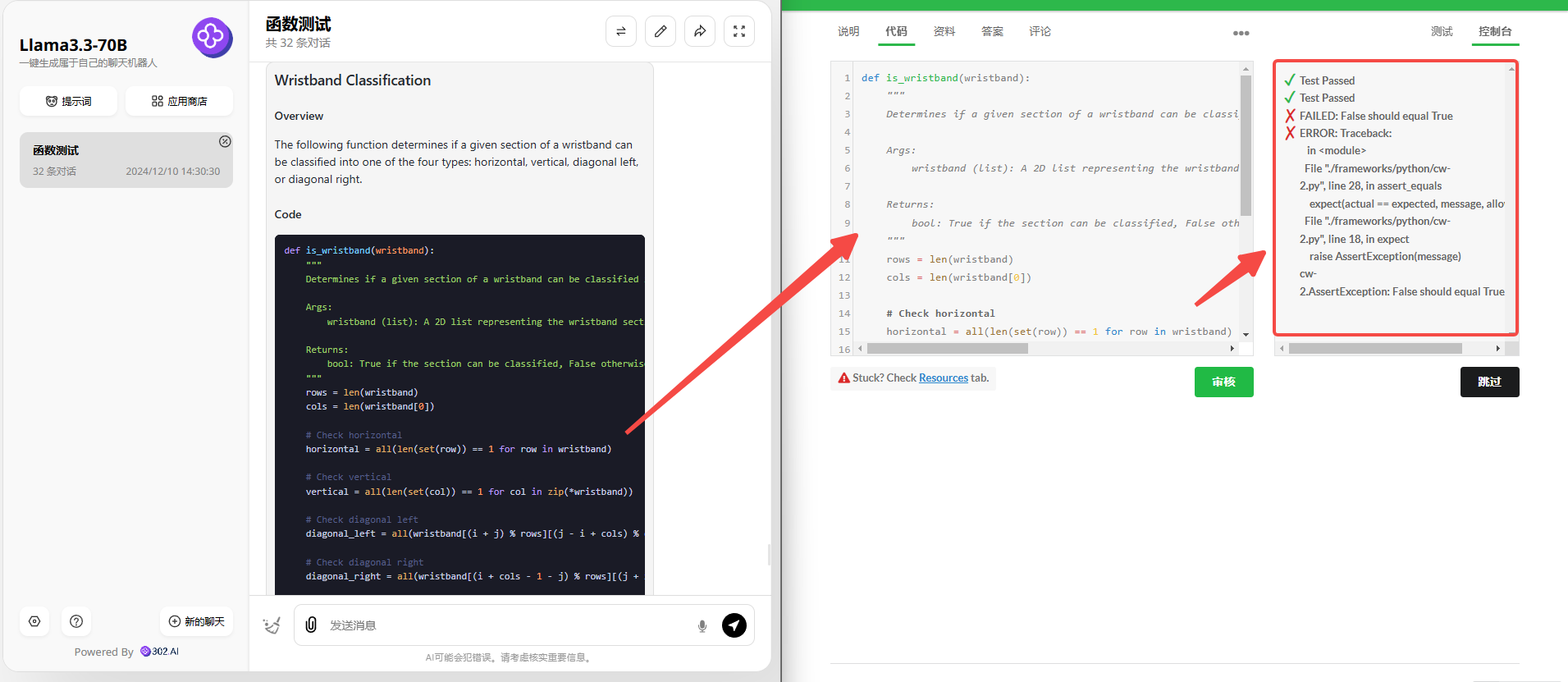
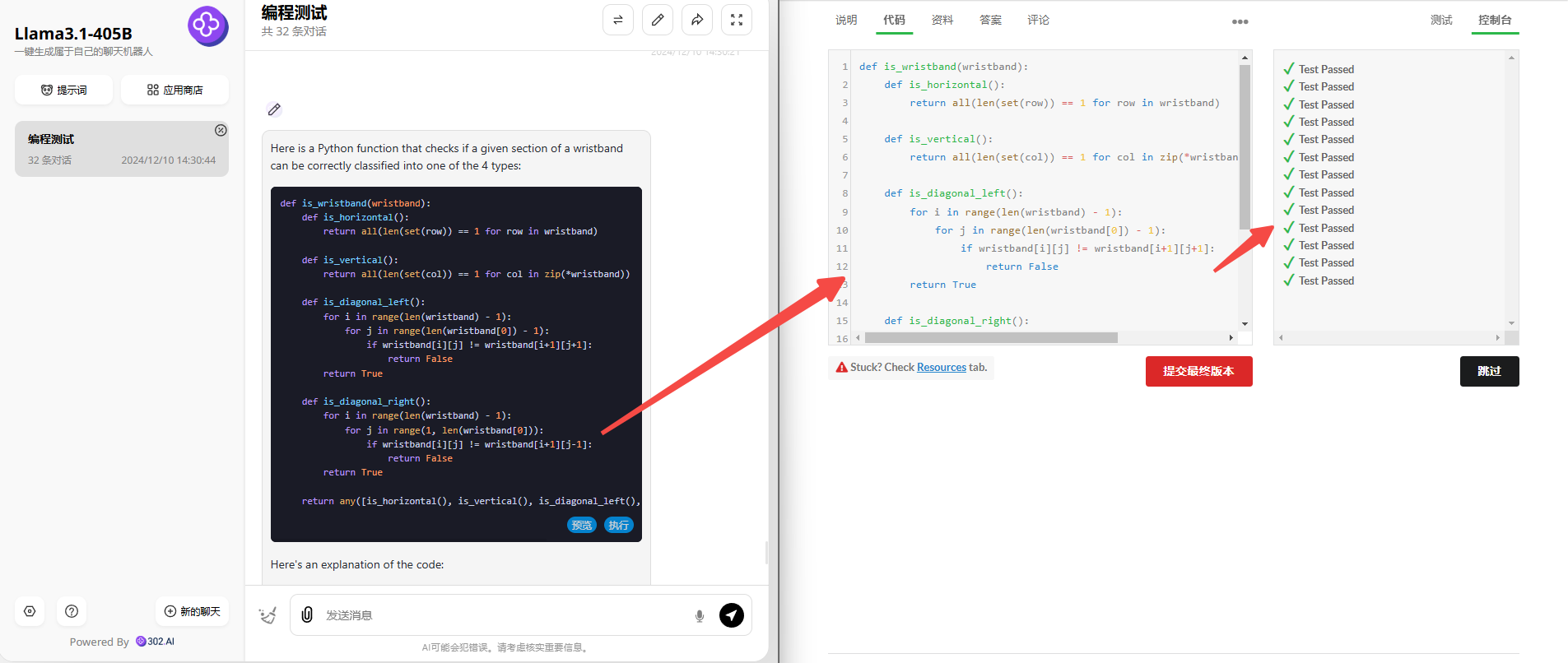
Llama 3.3 70B:虽然第二题也生成了两种版本的代码,但可惜生成的代码均有错误。
Llama 3.1 405B:令人意外的是,Llama 3.1 405B也是没有问题,代码验证通过!
实测3:编程效果对比
提示词:请用前端代码实现推箱子游戏,将所有代码放在一起输出。
分析:每个模型会在初始效果出来后,再统一给一次机会 优化,以下为优化后输出的最终效果。
GPT-4o-2024-11-20:界面设计很好看,最终输出的效果涵盖了游戏说明、开始游戏按钮等板块。游戏能通过键盘方向键直接开玩,游戏结束后会有得分提示,非常完整。
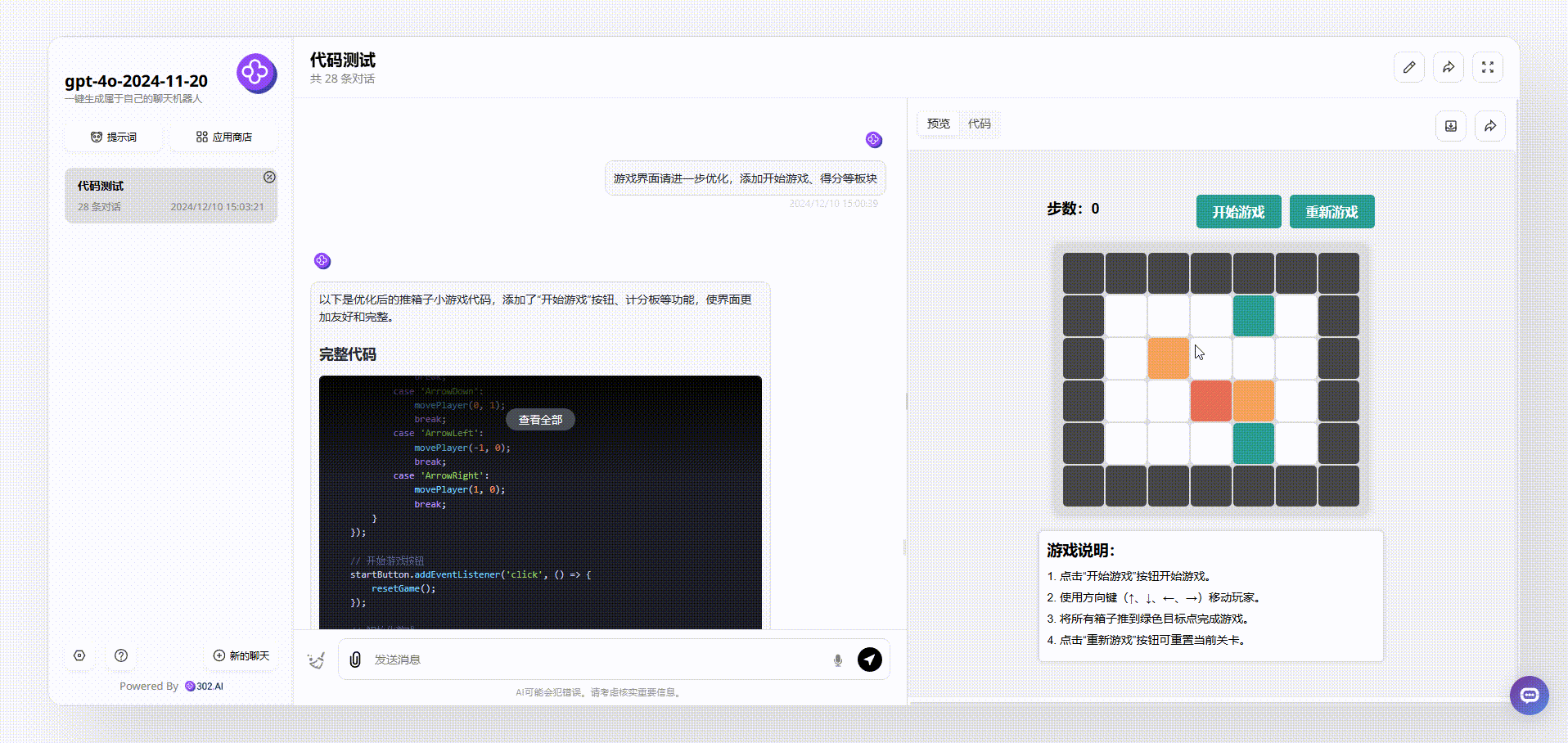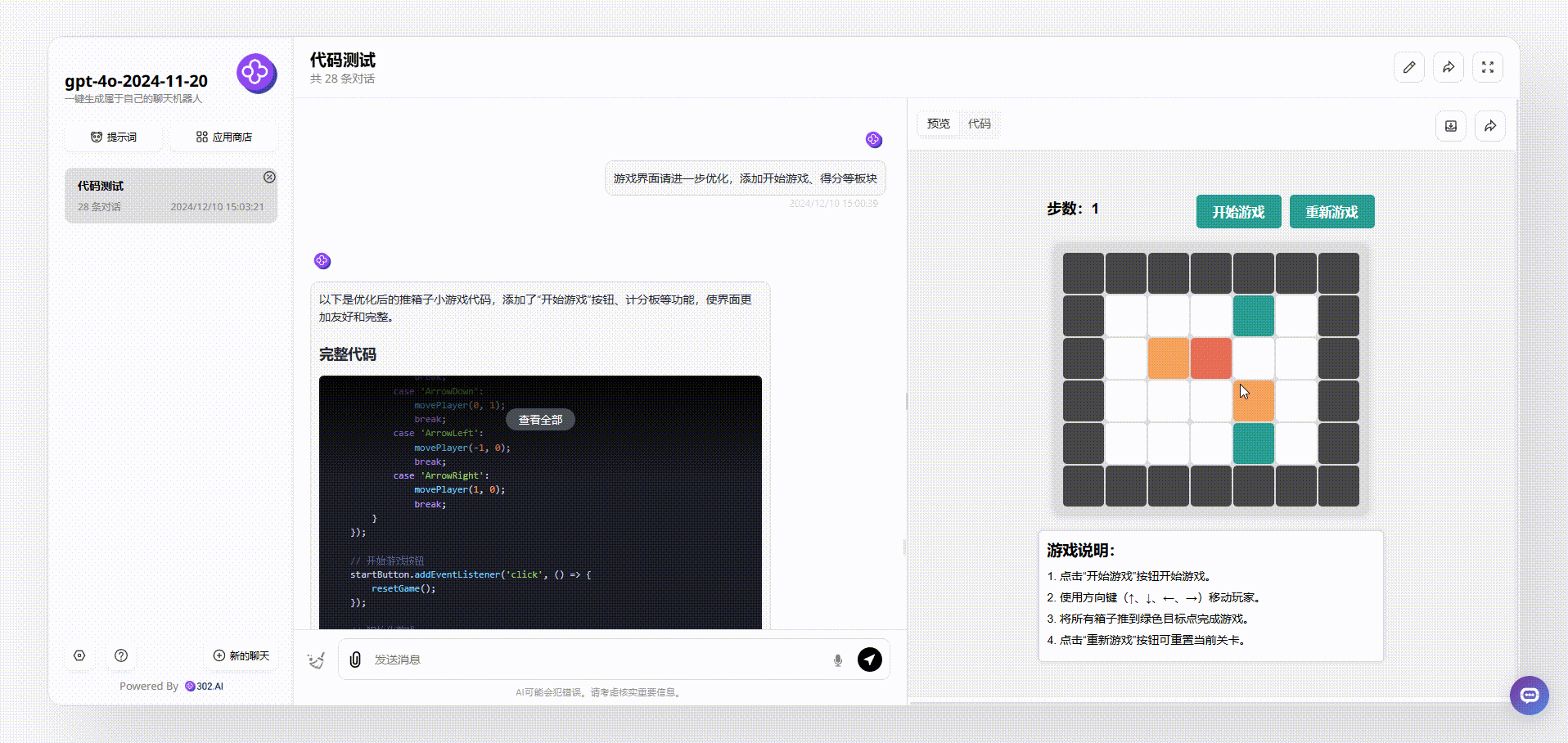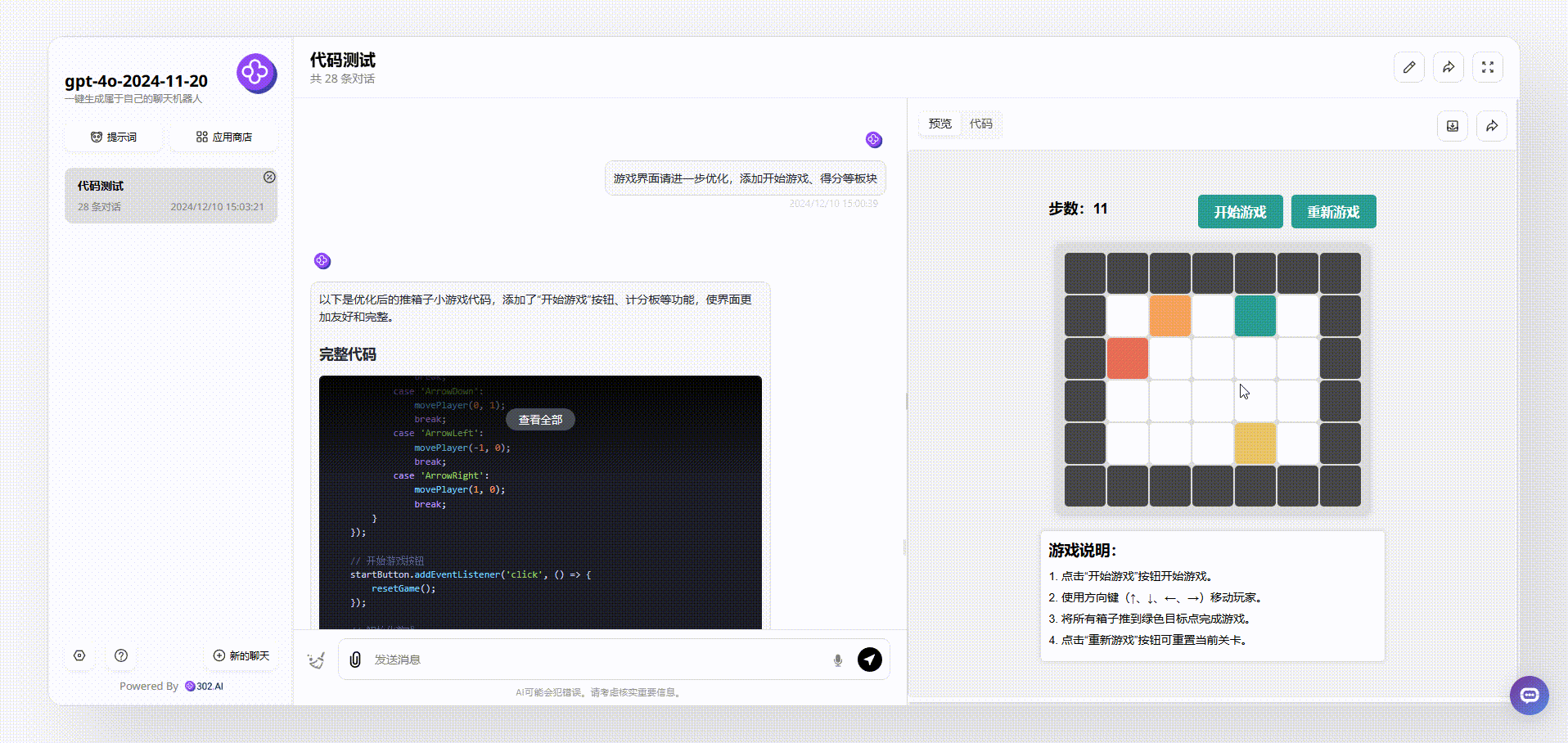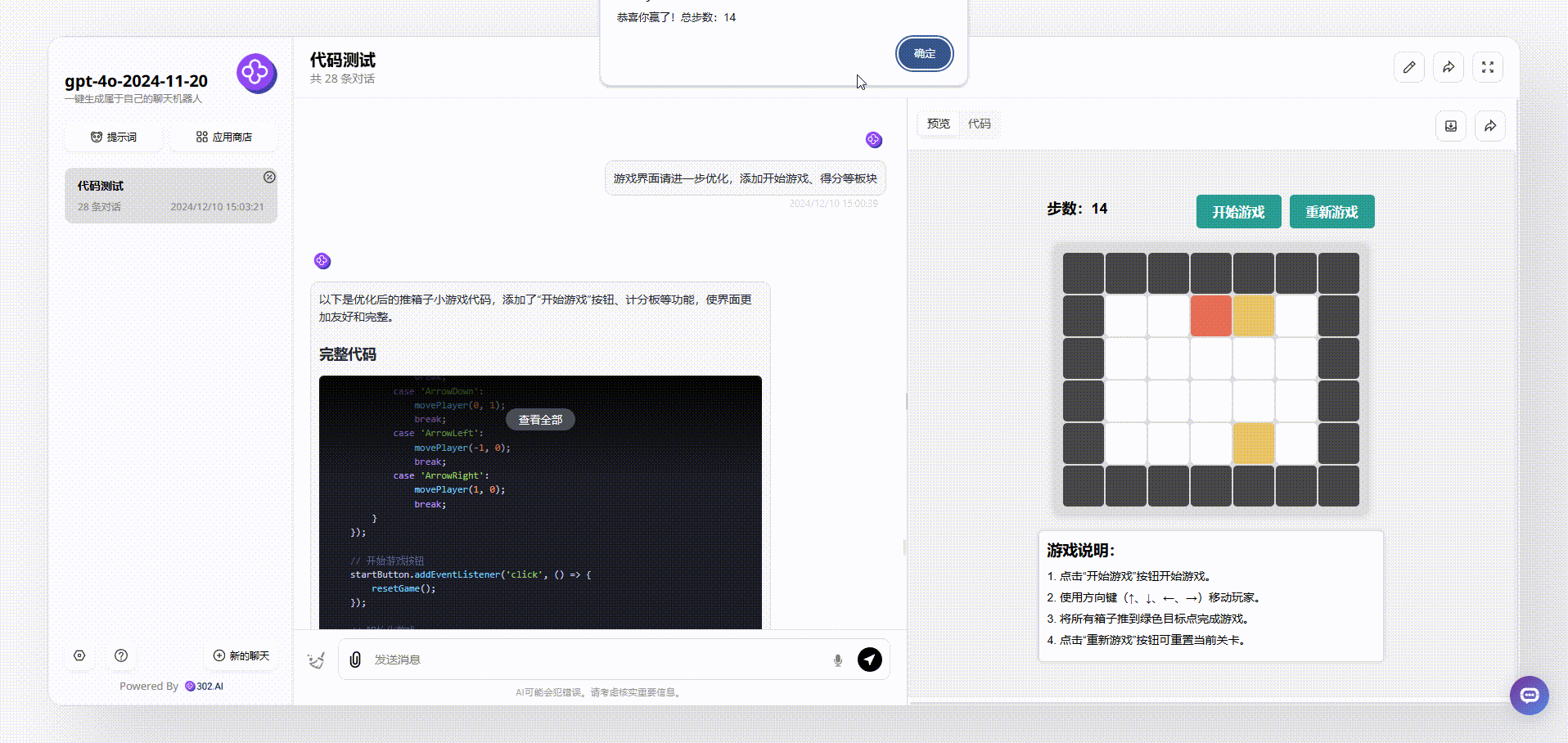
Llama 3.3 70B:从游戏界面来看,Llama 3.3 70B最终输出的效果比较简洁清晰,基本的元素虽然涵盖了,但是游戏存在bug。如下图,我们在操作的时候发现,绿色箱子通过操作移动到红、蓝箱子旁边,按理会得分,但是并没有看到分数有变化。
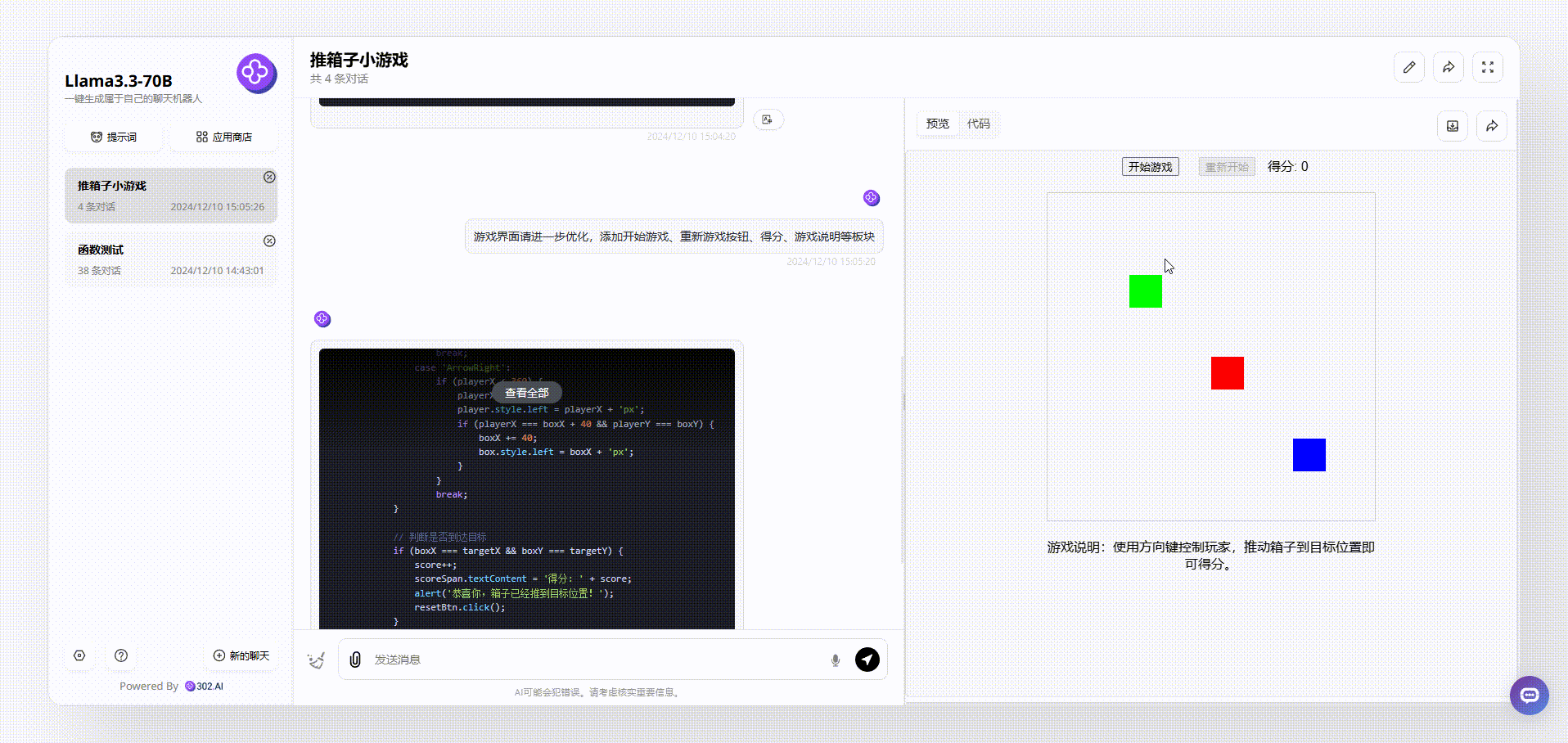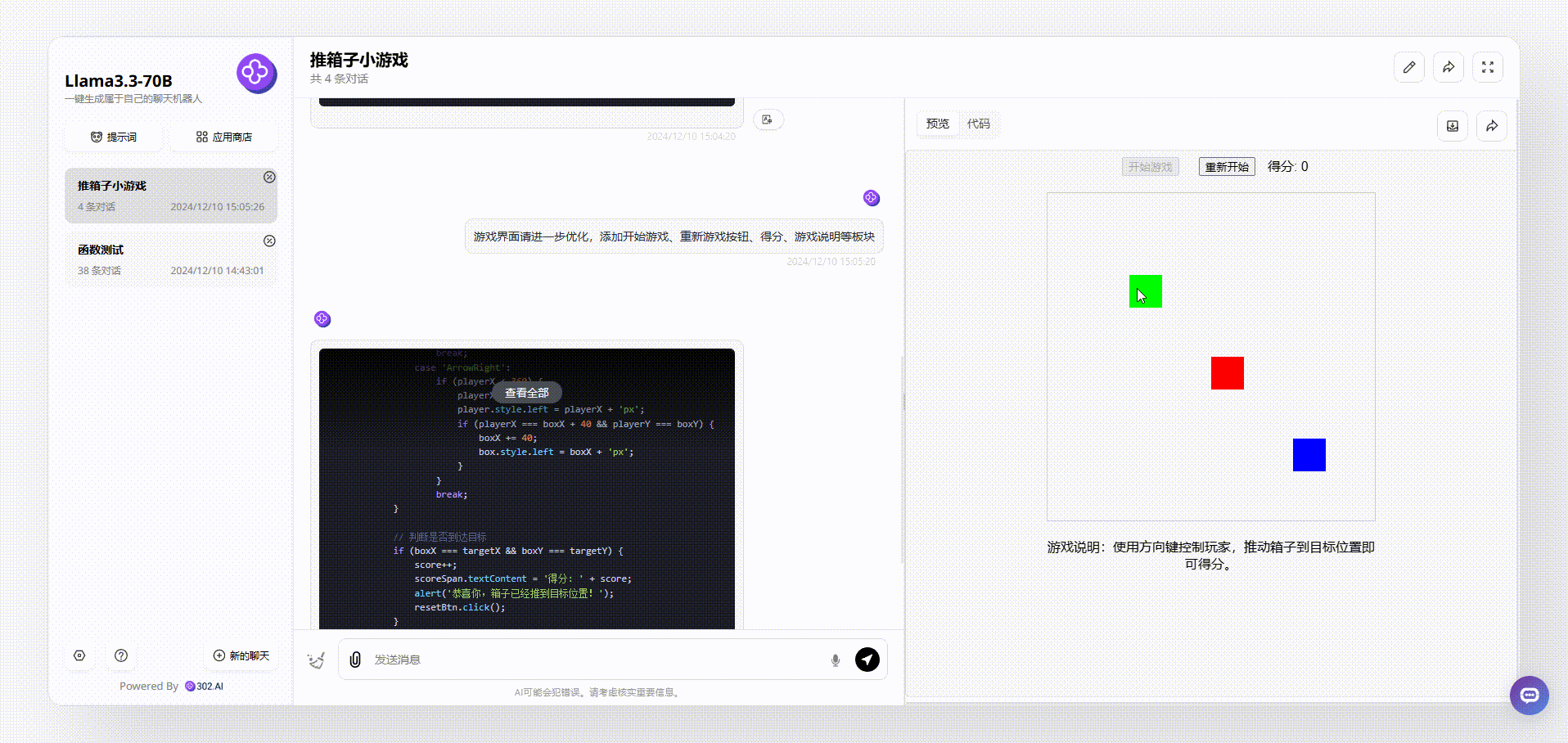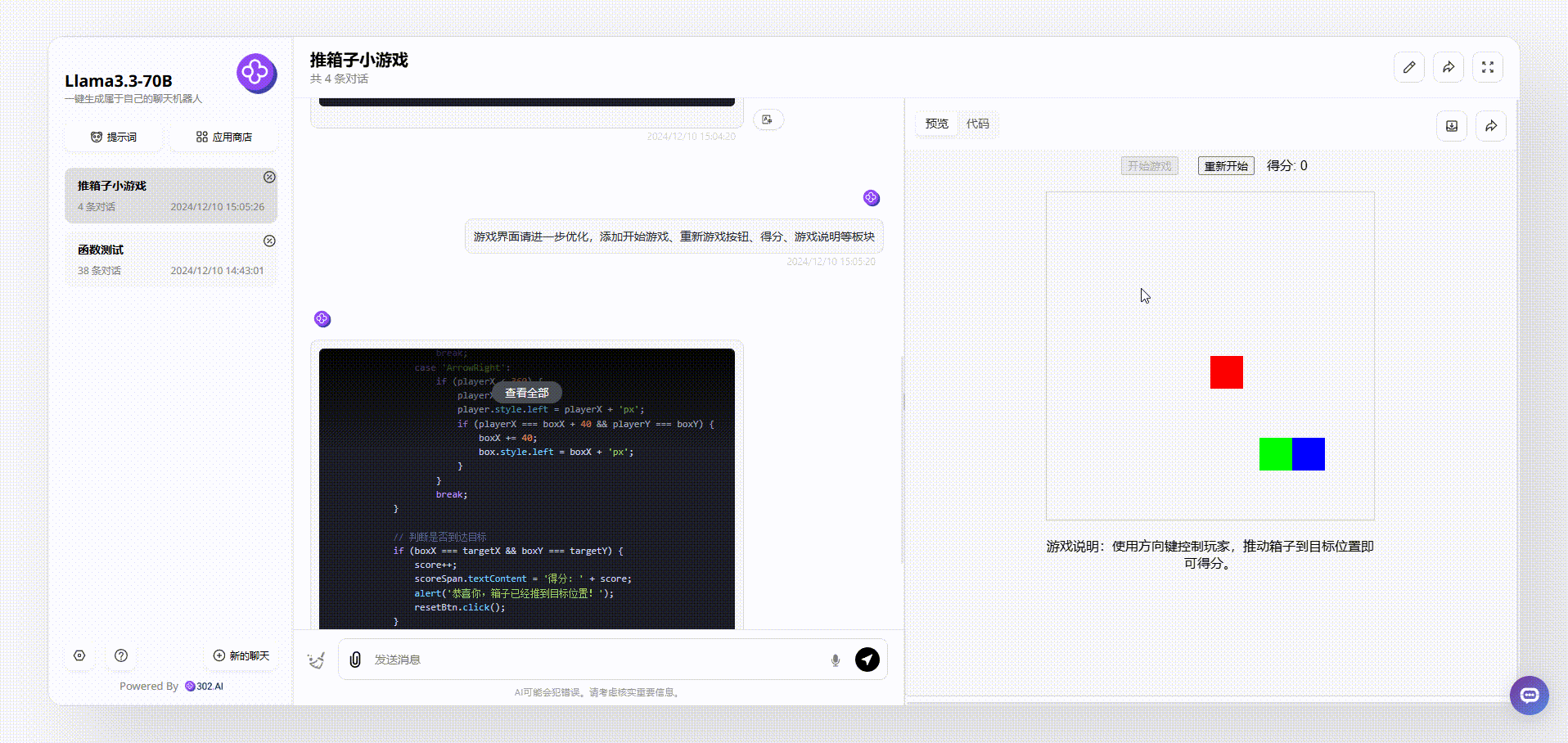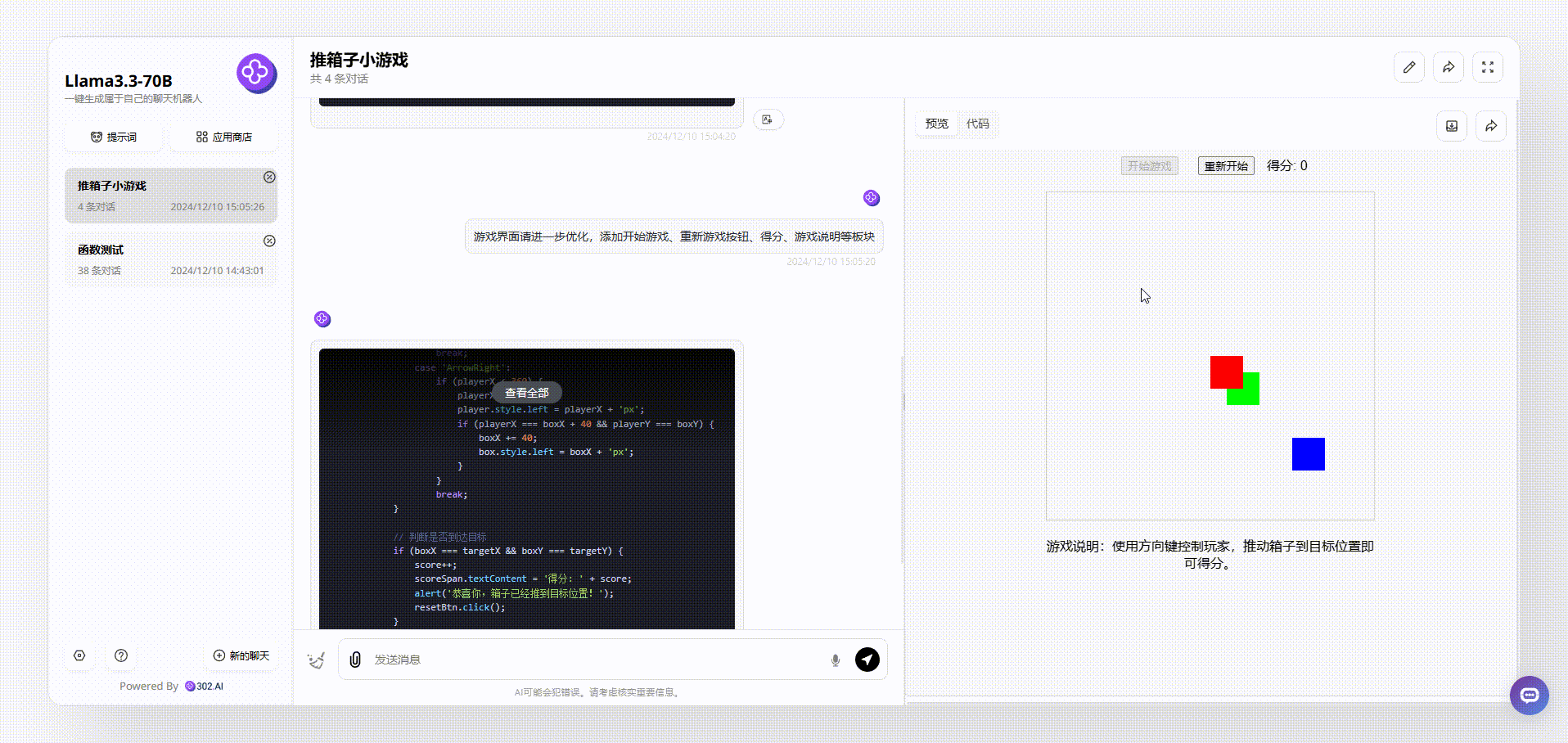
Llama 3.1 405B:最终实现的效果界面比较乱,看起来像没有经过排版的半成品,游戏操作和Llama 3.3 70B一样存在bug,如下图,即使红色块箱子移动到目标灰色块中,也没有实现被推动的效果。

> 总结
根据以上实测,可以初步得出以下结论:
语言、推理逻辑测试中:
1、在中文简体提示词下,Llama 3.3 70B的表现对比Llama 3.1 405B更优,能够更好地保持模型的稳定性,避免产生幻觉现象。
2、同时通过实测2可以清楚看到,Llama 3.3 70B对于中文繁体的效果是不错的。
3、在复杂的逻辑推理问题上,无论是Llama 3.3 70B还是Llama 3.1 405B,表现都不如最新版的GPT-4o。
编程测试:
1、在简单的编程测试中,Llama 3.3 70B能够生成正确且多样化的代码版本,显示出其在代码生成方面的灵活性。
2、对于困难级别的代码编程题目,表现仍显不足。
3、从编程效果对比来看,虽然Llama 3.3 70B的界面设计比Llama 3.1 405B简洁清晰,但代码实现中出现了bug。相比之下,GPT-4o在界面设计和功能实现上都表现出色,提供了更为完整的用户体验。
总的来说,Llama 3.3 70B在处理中文提示词的稳定性及对繁体中文的支持上,展现了一定的的优势。此外,Llama 3.3 70B虽然在编程上能够生成多样化的代码版本,但面对复杂任务上,局限性还是比较明显。
据说,这是Meta AI今年最后一次AI大模型更新,明年或许我们会迎来Llama 4?可以一起期待下!