
12月20日凌晨,谷歌DeepMind首席科学家宣布推出全新模型——Gemini 2.0 Flash Thinking。
据了解,Gemini 2.0 Flash thinking是一个实验性模型,它以Gemini 2.0 Flash版本为基础,经过特别训练后,能够在回答问题时展示其“思考过程”,这与o1模型的慢思维思考方式相似,可以深度可视化展示整个思维链过程,尤其是在执行数学、编程等复杂问题方面,能持续输出全部推理过程,而不是直接给出答案。
根据官方文档显示,Gemini 2.0 Flash Thinking支持32k令牌输入,以及8k令牌输出限制,此外,该模型还具备处理文本和图片输入的能力。


> 在302.AI上使用
目前,302.AI的聊天机器人和API超市均上线了Gemini 2.0 Flash thinking模型,旨在满足不同用户群体的需求。
此外,302.AI提供按需付费的使用方式,用户无需担心有月费和捆绑套餐,成本更加灵活可控。以下是详细的获取步骤。
【聊天机器人】
想要直接使用模型的用户,可以通过302.AI的聊天机器人获得,聊天机器人提供了多种AI模型,且分类明晰,用户可以快速找到并使用所需的AI模型,省去了在不同平台之间切换和搜索的繁琐步骤和时间,更加便捷。
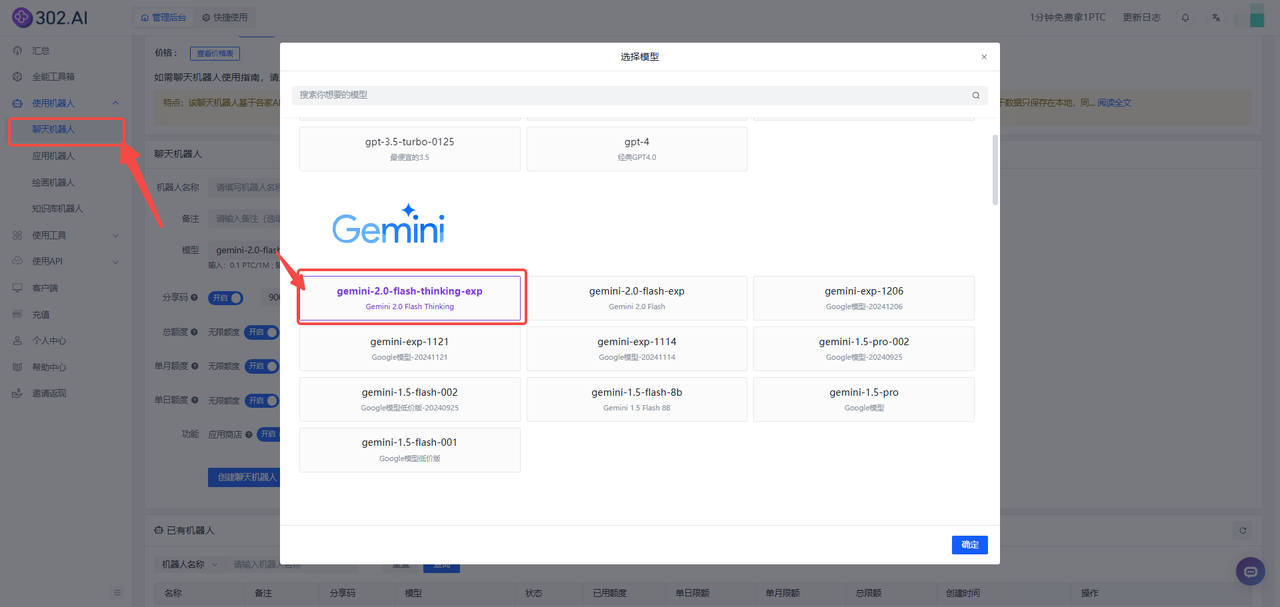
1、进入302.ai,登录后在左侧菜单栏点击使用机器人——选择聊天机器人——模型中选择gemini-2.0-flash-thinking-exp——最后点击确定即可。
【API超市】
企业用户可以通过302.AI提供的接口来调用大模型,并根据自身项目需求快速开发AI应用,大大加快开发和部署速度。以下是在API超市中获取Gemini 2.0 Flash thinking的详细步骤:
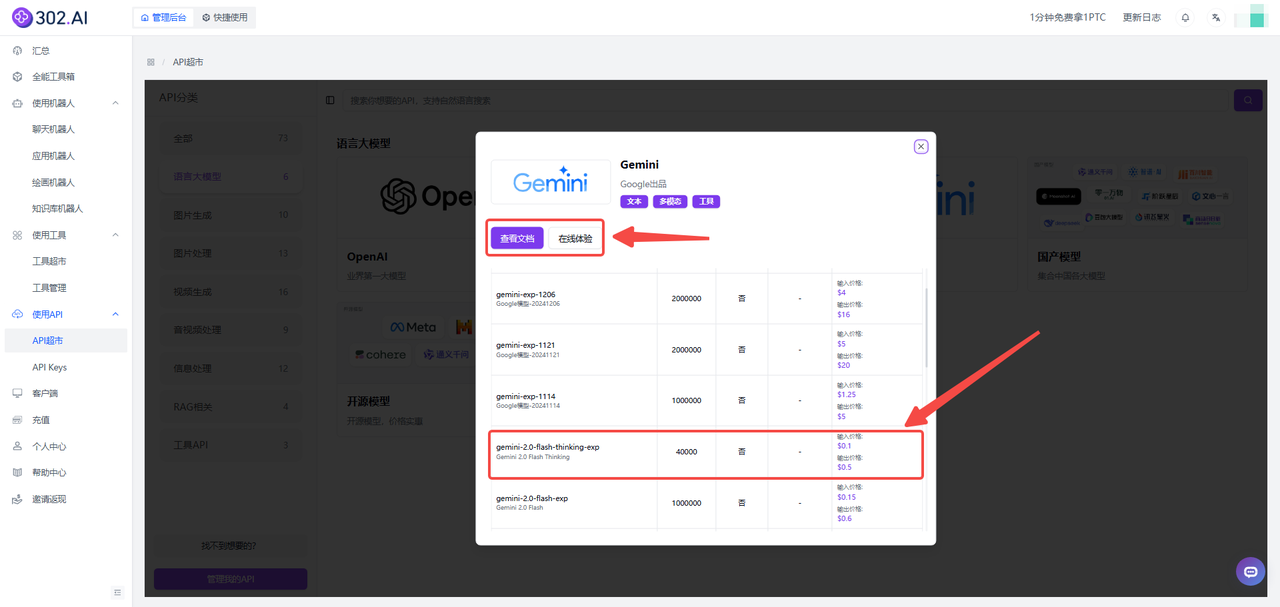
1、进入302.ai后——点击使用API——选择API超市——分类中点击语言大模型——然后选择Gemini。

2、下滑可以看到已经提供了模型Gemini 2.0 Flash thinking的API,可以根据需求选择【查看文档】快速接入API或者选择【在线体验】测试模型的参数。
> 实测对比:
为了让大家更好了解Gemini 2.0 Flash thinking这一模型,下面会实测对比数学、推理、编程等方面的表现。
实测1-3使用的工具为302.AI的模型竞技场。
实测4使用的工具为302.AI聊天机器人的Artifacts功能。
实测1:数学测试
对比模型:o1-plus(完整版o1)、Gemini 2.0 Flash thinking
提示词:已知函数f(x,y)=x³+y³-(x+y)²+3,设T是曲面z=f(x,y)在点(1,1,1)处的切平面,D为T与坐标平面所围成的有界区域在xOy平面上的投影.
(1)求T的方程
(2)求f(x,y)在D上的最大值和最小值
参考答案:
(1)x+y+z=3
(2)最大值是21,最小值是17/27
分析:这一题目来自刚刚结束的2024全国考研数学一卷。此前,考研数学在社交媒体平台热搜榜引发了广泛的讨论和关注。而我们选择的这一题目难度适中,看下模型的回答:
(无论第一次答案是否正确,都会给出第二轮提示词让模型验算答案)
o1完整版:o1 完整版两次输出的答案均为正确的,下面附上第一次回答的答案。可以看到输出了答案先是给出思考链路,篇幅非常详细,非常完整。

Gemini 2.0 Flash thinking:即使经过验算,Gemini 2.0 Flash thinking第二小问中的“最小值”还是没有给出正确答案。下面附上第一次输出的答案,可以看到输出的答案同样先是展示了思考链路,再回答问题,但是整体的输出整洁度不如o1 完整版。

实测2:图片理解测试
模型对比:Gemini 2.0 Flash thinking、Gemini 2.0 Flash、
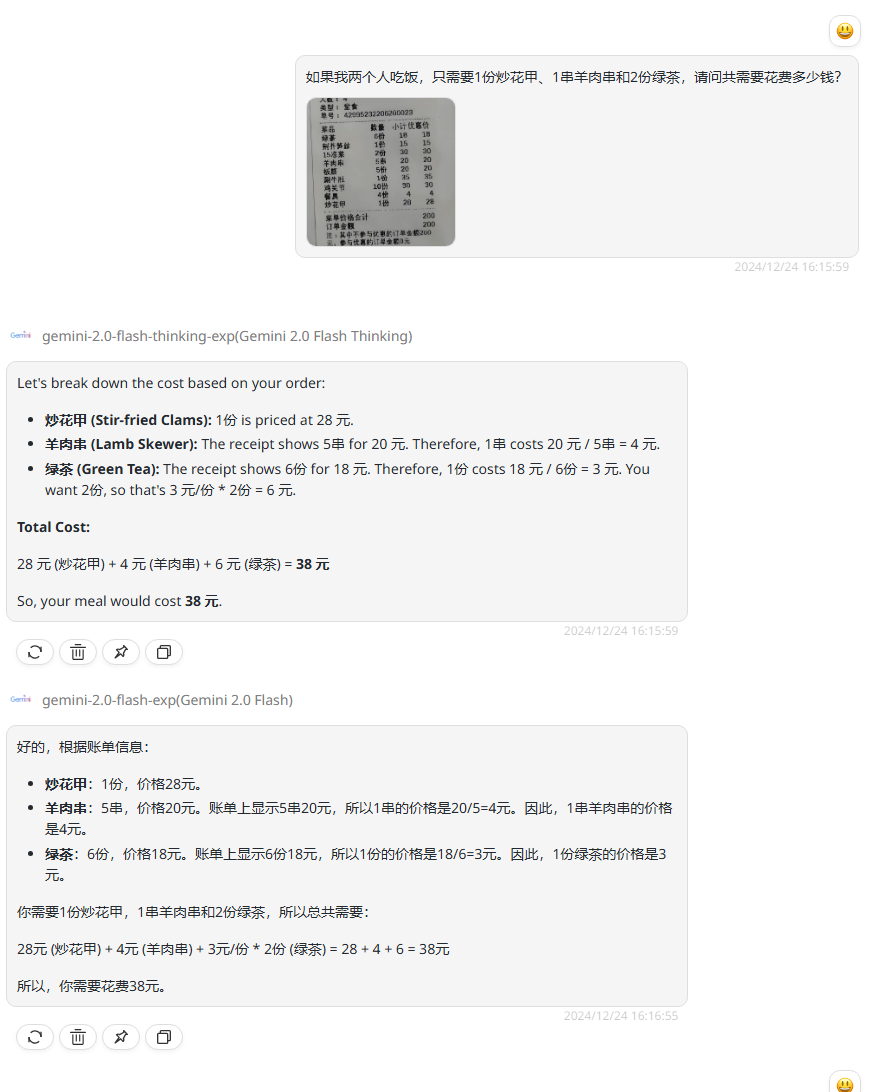
提示词:如果我两个人吃饭,只需要1份炒花甲、1串羊肉串和2份绿茶,共需要花费多少钱?

分析:在初次提问回答的答案中,两个模型的回答都遗漏了餐具费。
Gemini 2.0 Flash thinking:回答错误。
Gemini 2.0 Flash:回答错误。
经过提醒后:
Gemini 2.0 Flash thinking:虽然同样给出了思考过程,但没有修正答案,最后回答错误。
Gemini 2.0 Flash:修正了答案,回答正确。

实测3:推理测试
对比模型:Gemini 2.0 Flash thinking、Claude-3.5-sonnet20241022
提示词:

分析:
Gemini 2.0 Flash thinking:回答正确,但这里通过对比发现,Gemini虽然展示了非常详细的思考链路,但是整体回答篇幅非常长。

Claude-3.5-sonnet:整体回答简洁易读,回答正确。

实测4:编程测试:
对比模型:Gemini 2.0 Flash thinking、Claude-3.5-sonnet20241022
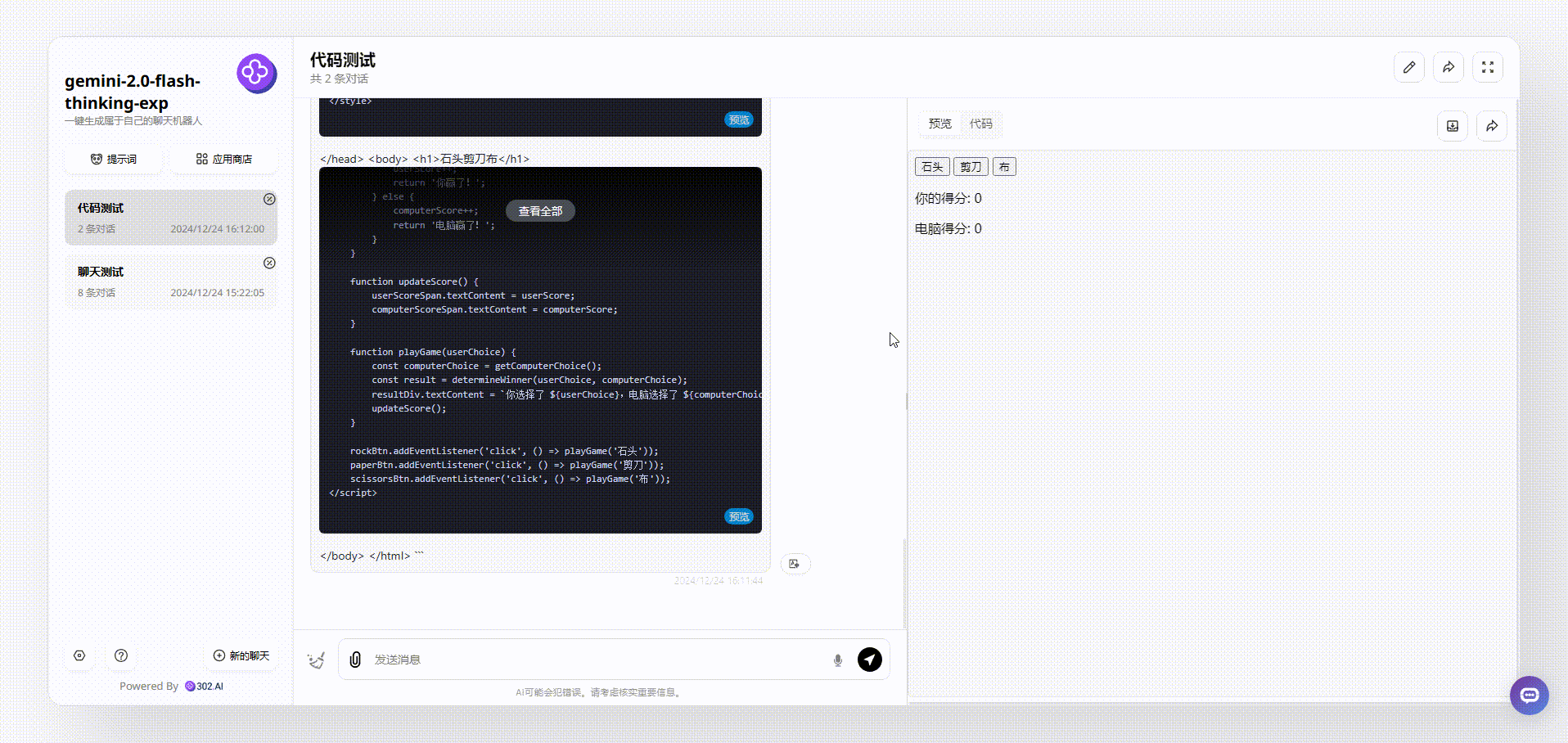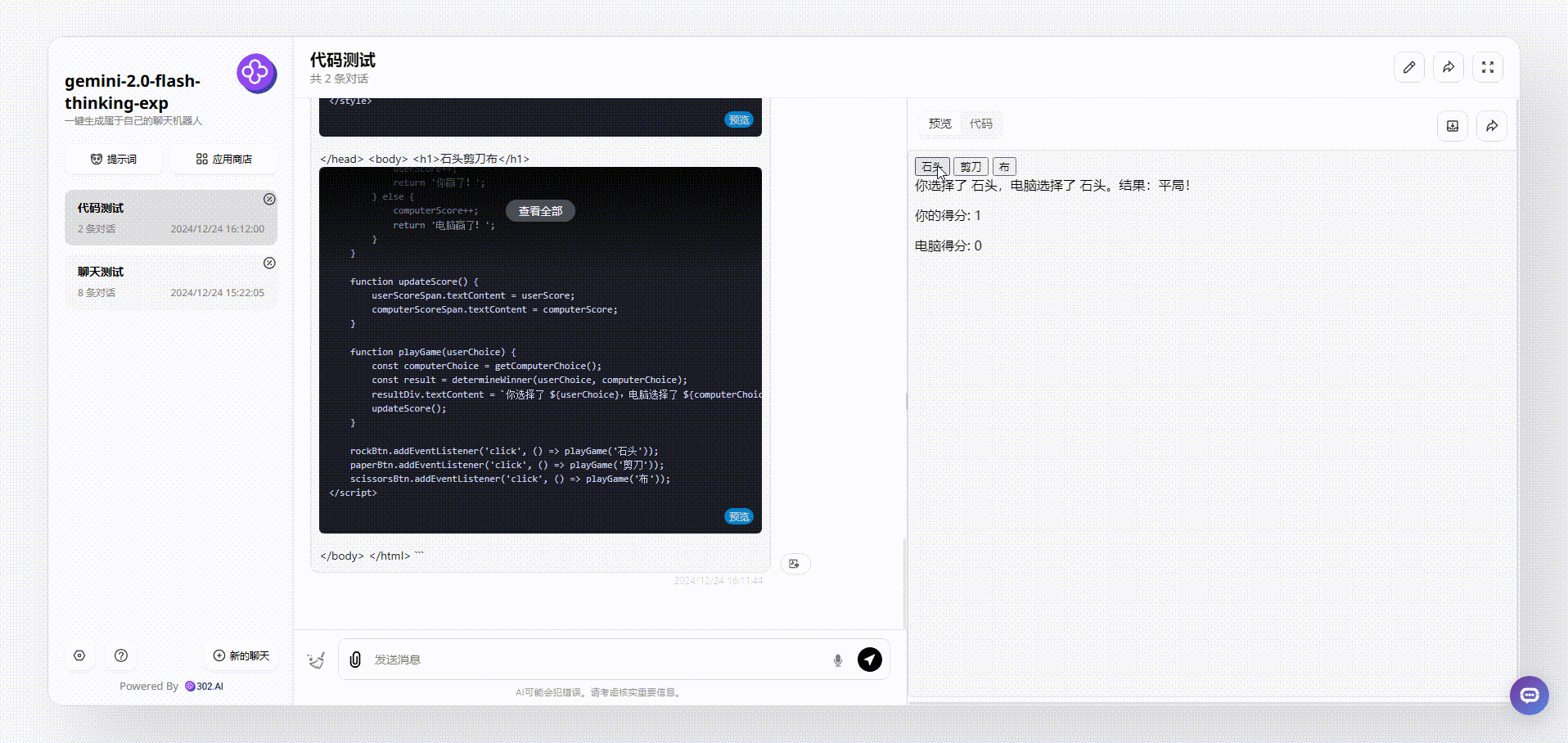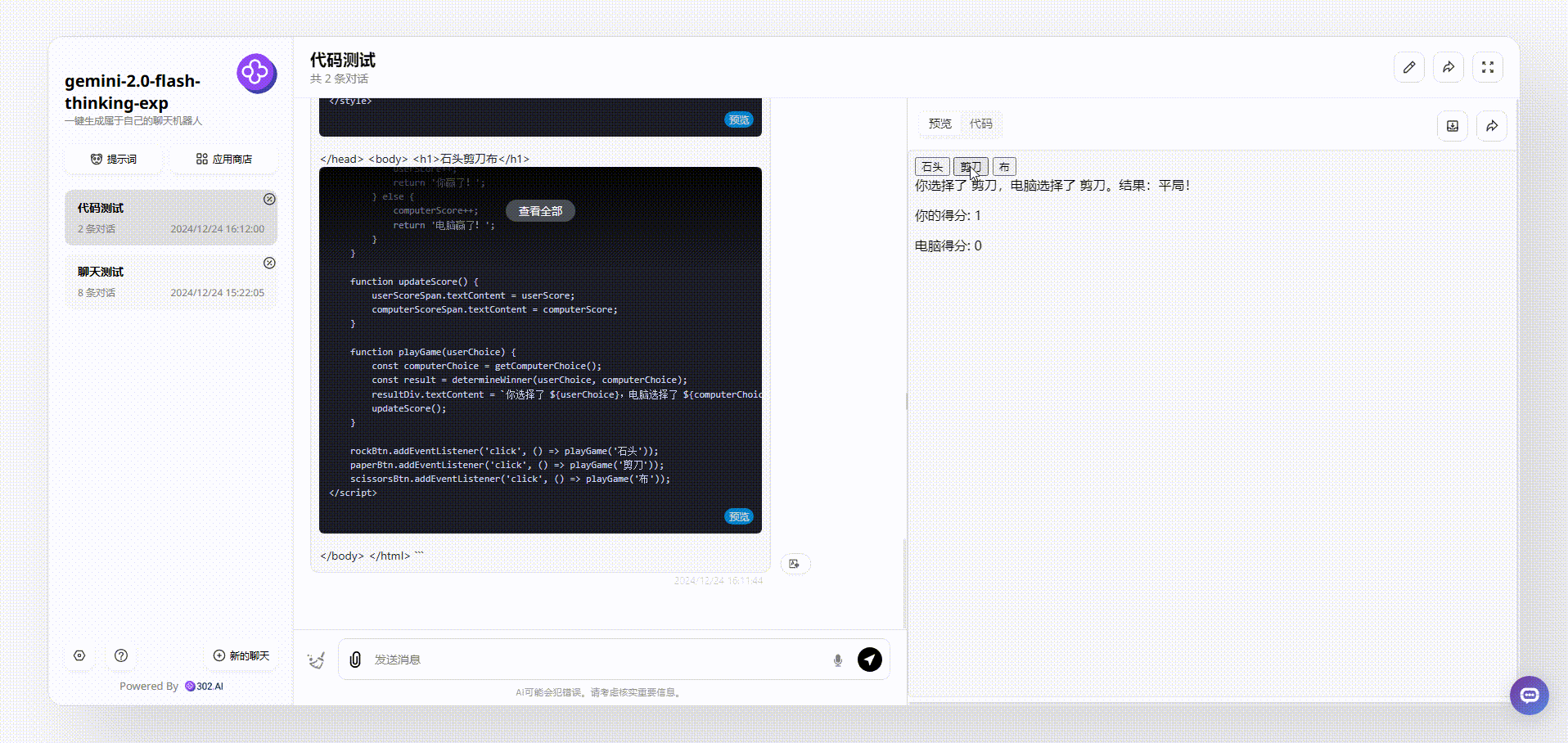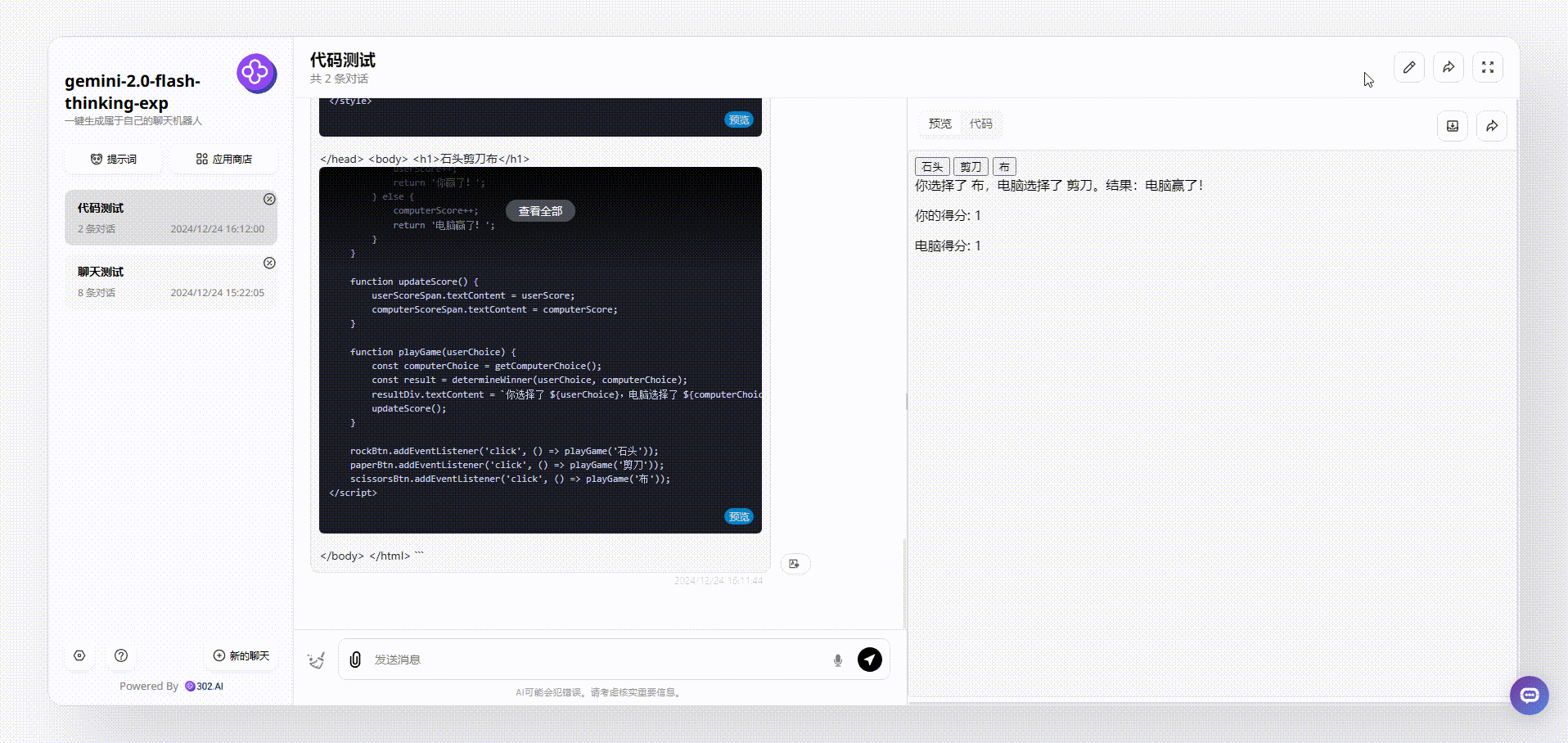
提示词:请用前端代码实现石头剪刀布游戏,将所有代码放在一起输出。
分析:
Gemini 2.0 Flash thinking:整体效果没有看出有任何界面设计,但是游戏能够操作交互,不过给人的感觉还是比较粗糙。
Claude-3.5-sonnet:对比后,可以看到界面简洁清晰,游戏能操作,整体效果不错。
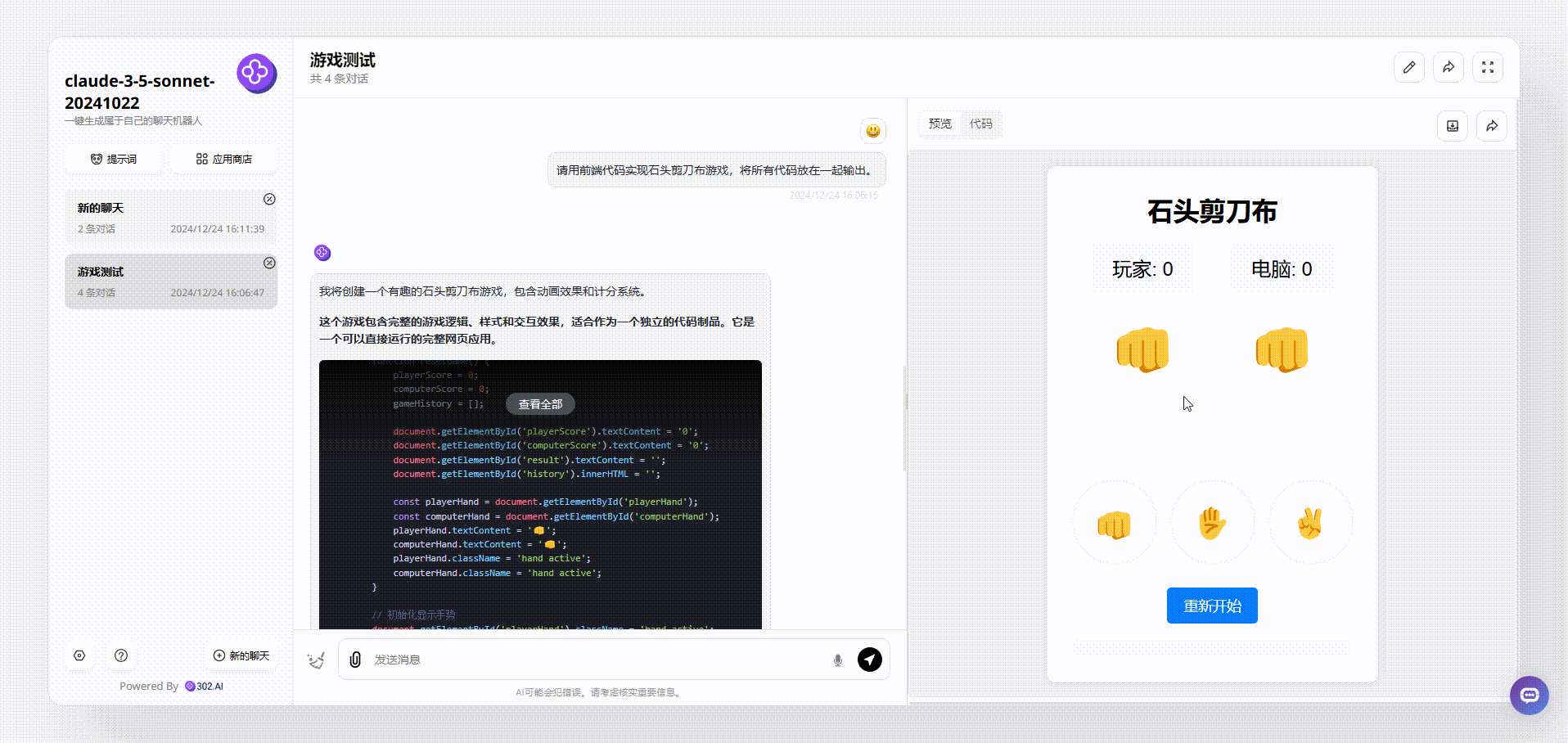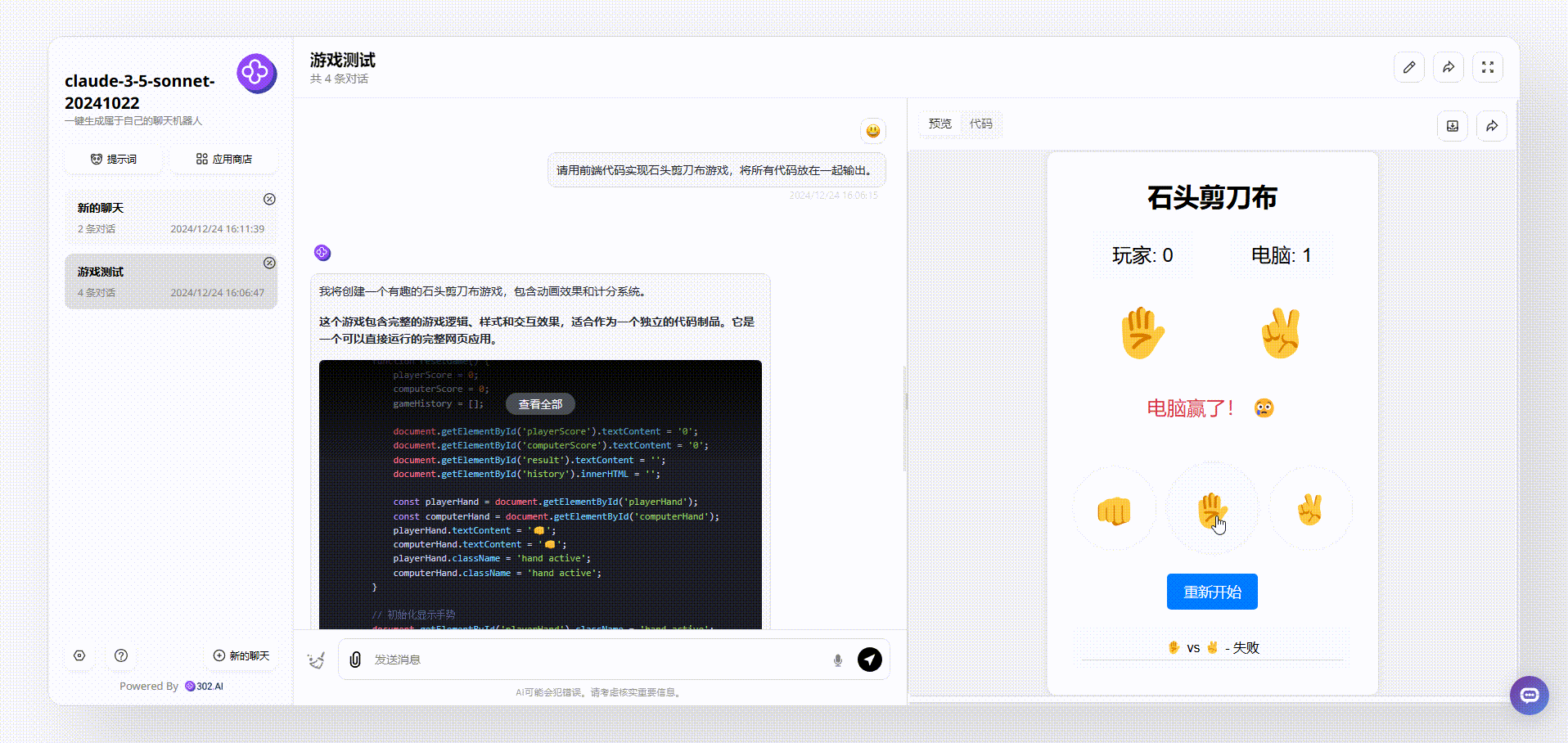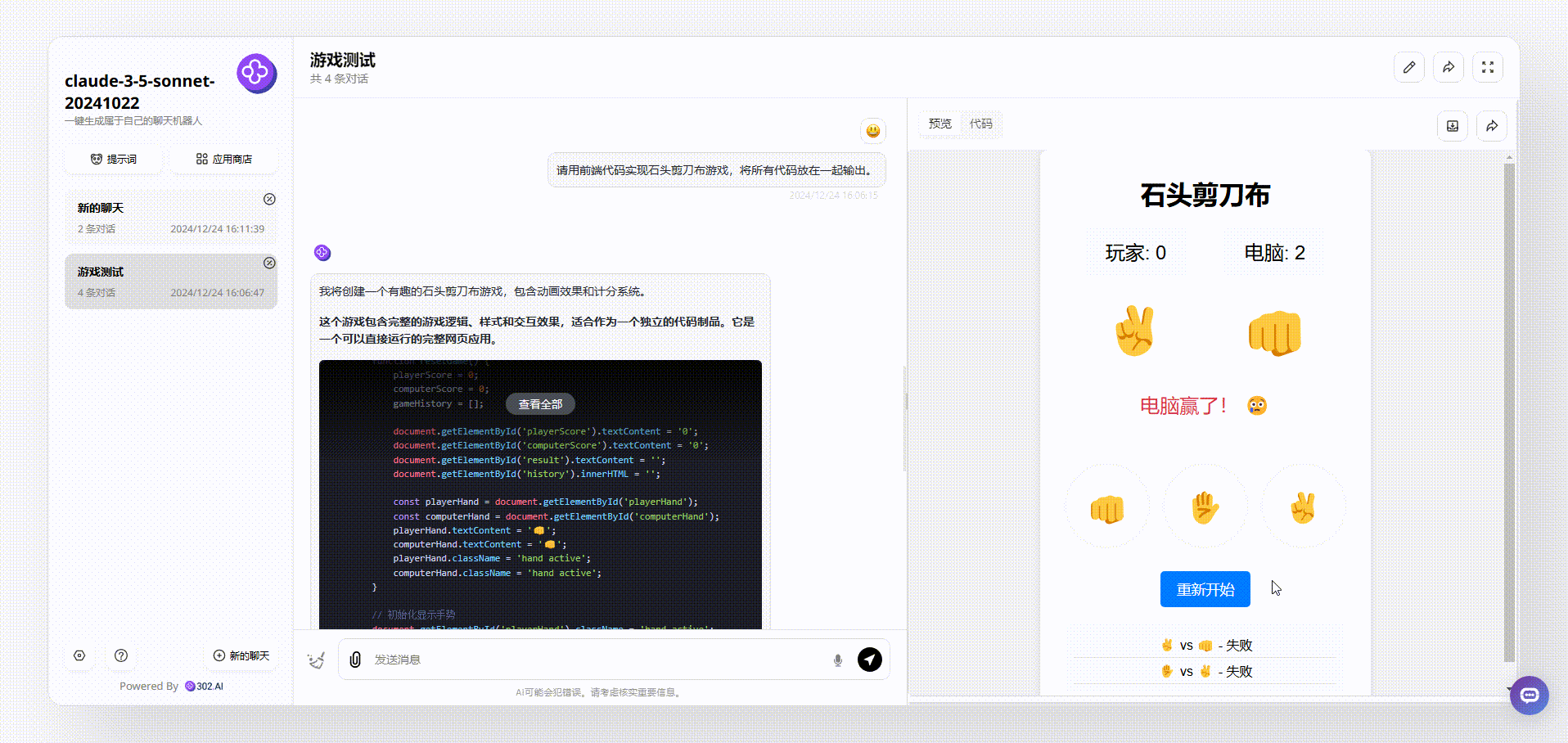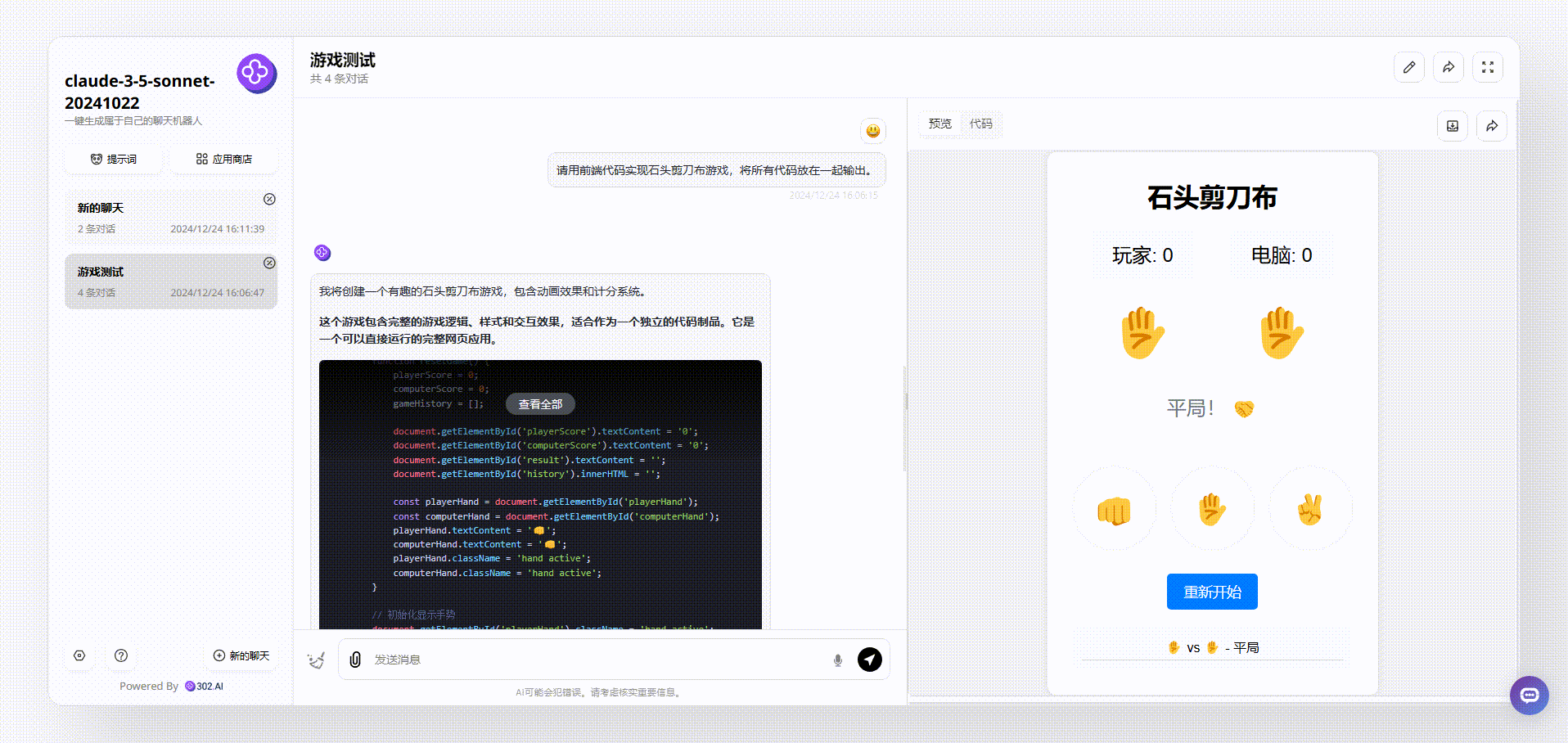
> 总结
通过多轮实测,可以初步得出以下结论:
数学测试:两个模型的训练集中可能都未曾出现过的考研数学题目,虽然Gemini 2.0 Flash thinking提供了详细的推理过程,但可惜最终的答案并未完全正确。
图片理解:两个模型初次输出的答案均未正确,但是Gemini 2.0 Flash经过提醒后能够检查出错误并纠正答案,而Gemini 2.0 Flash thinking经过提醒依然回答错误。
推理测试:Gemini 2.0 Flash thinking虽然能够展示思考链条,但其回答的篇幅较长,可能影响用户的理解和使用体验。
编程测试:Gemini 2.0 Flash thinking的整体效果较为粗糙,并且缺乏良好的界面设计。
虽然Gemini 2.0 Flash thinking在展示思考过程方面的创新值得肯定,但从用户的角度出发,模型回答问题时答案篇幅过长,很大程度会影响用户阅读。通过以上实测认为,Gemini 2.0 Flash thinking在实际应用中仍需进一步优化其输出的准确性和用户体验。