
就在刚刚,DeepSeek了更新V3版本!据了解,模型的速度有了明显提升。
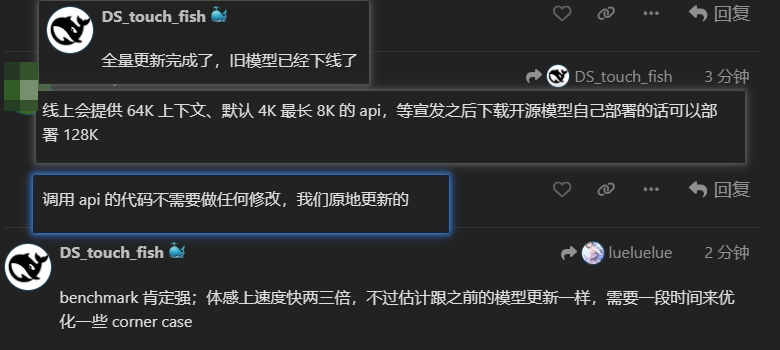

官方还没有来得及正式宣发,我们迫不及待尝试了下,的确更新了!
那今天就抢先带大家在302.AI实测了解一下DeepSeek-V3,看看其在文本处理、推理逻辑、编程等方面的表现如何!
> 在302.AI上使用
302.AI的聊天机器人和API超市都同步更新了DeepSeek-V3,而且提供按需付费的服务方式,无论是企业、个体开发者,还是不同的用户群体,都能够依据自身的实际需求来灵活选择使用模型,满足各自不同的需求。
【聊天机器人】
用户可以通过聊天机器人快速体验最新模型。302.AI的聊天机器人提供市场上多种先进模型,并持续进行实时更新,保持与市场的发展同步。以下是具体的获取步骤:
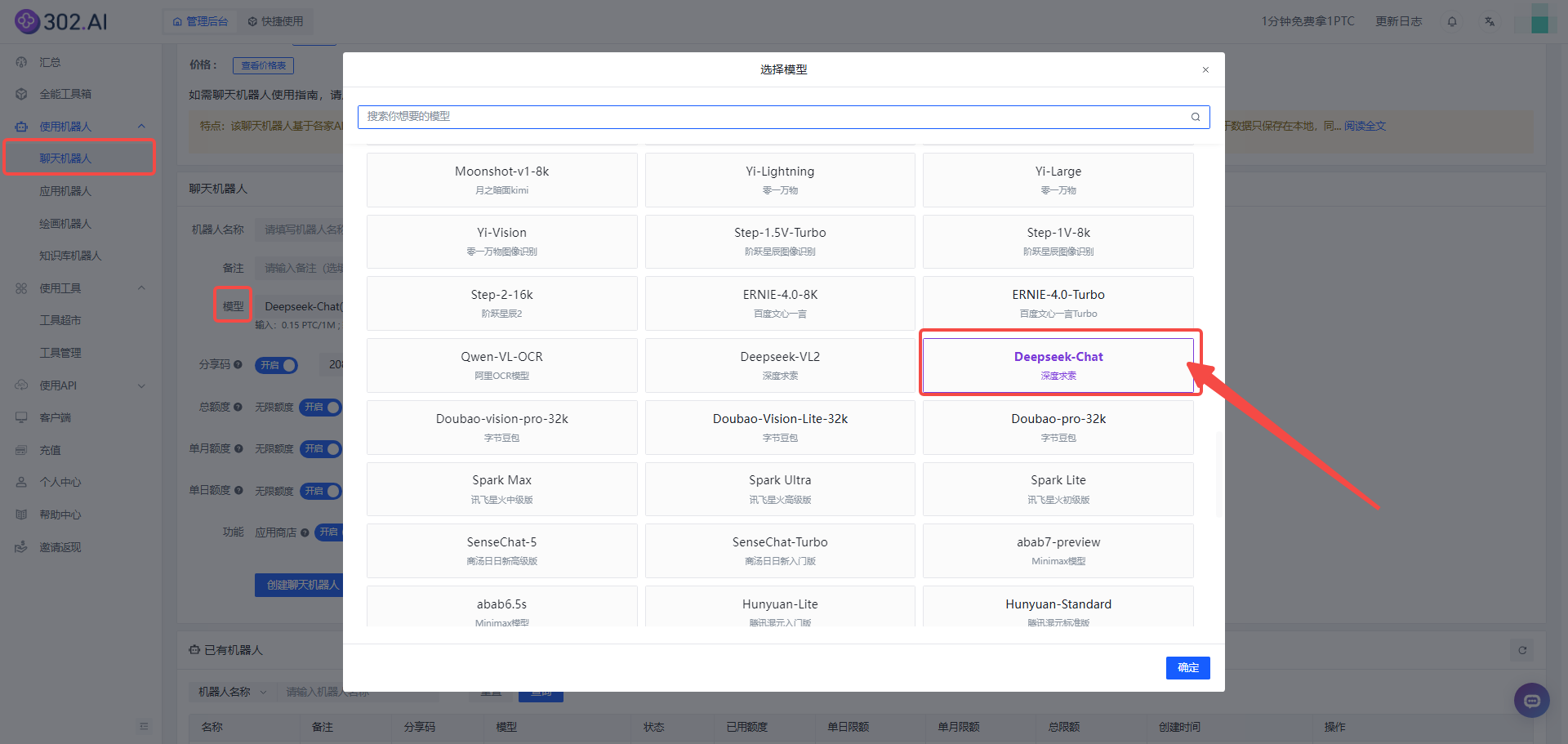
1、进入302.AI——点击左侧菜单栏使用机器人——选择聊天机器人——点击模型——选择Deepseek-Chat模型并确定,最后点击创建聊天机器人按钮;
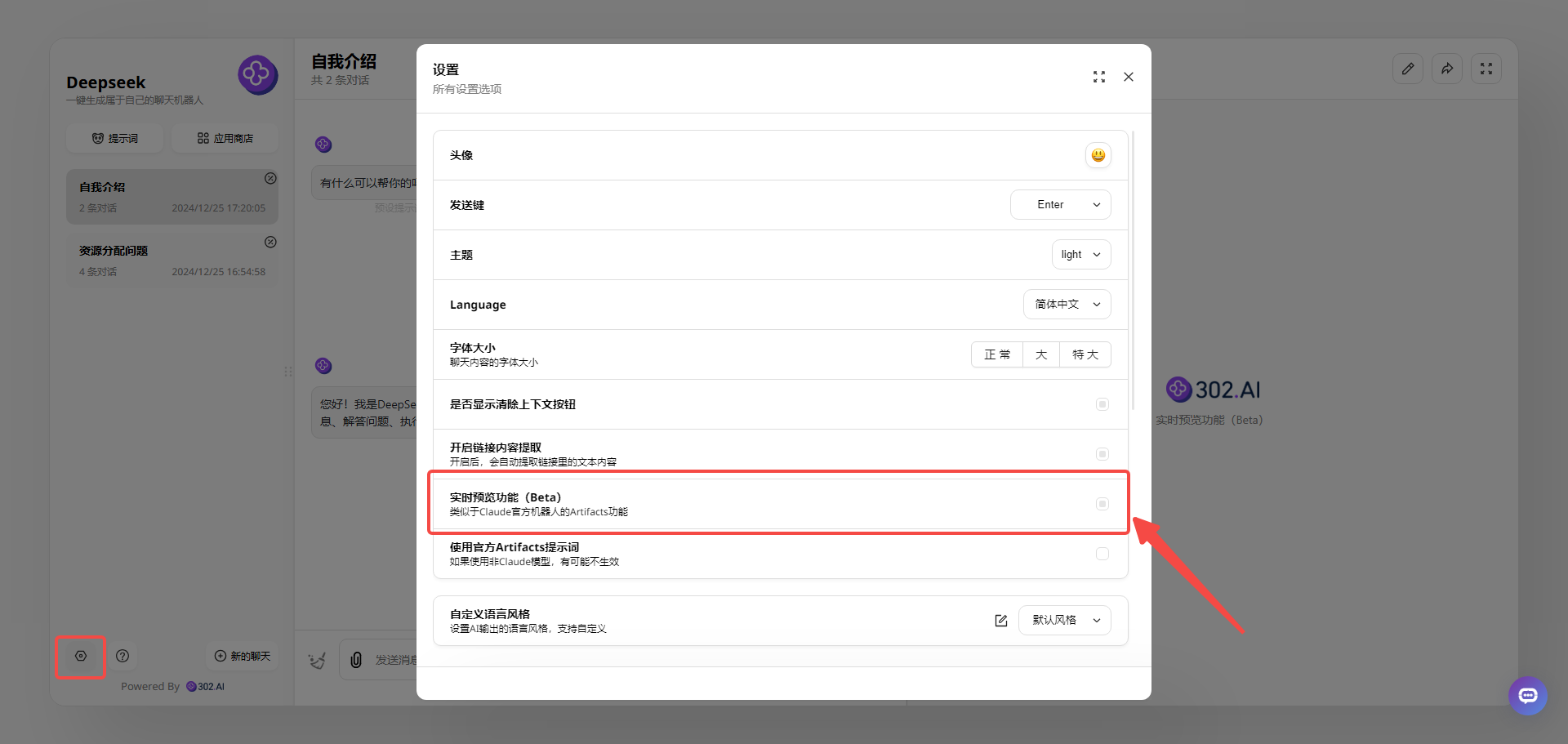
2、进入聊天机器人后,还可以点击左下角的设置,打开Artifacts功能。
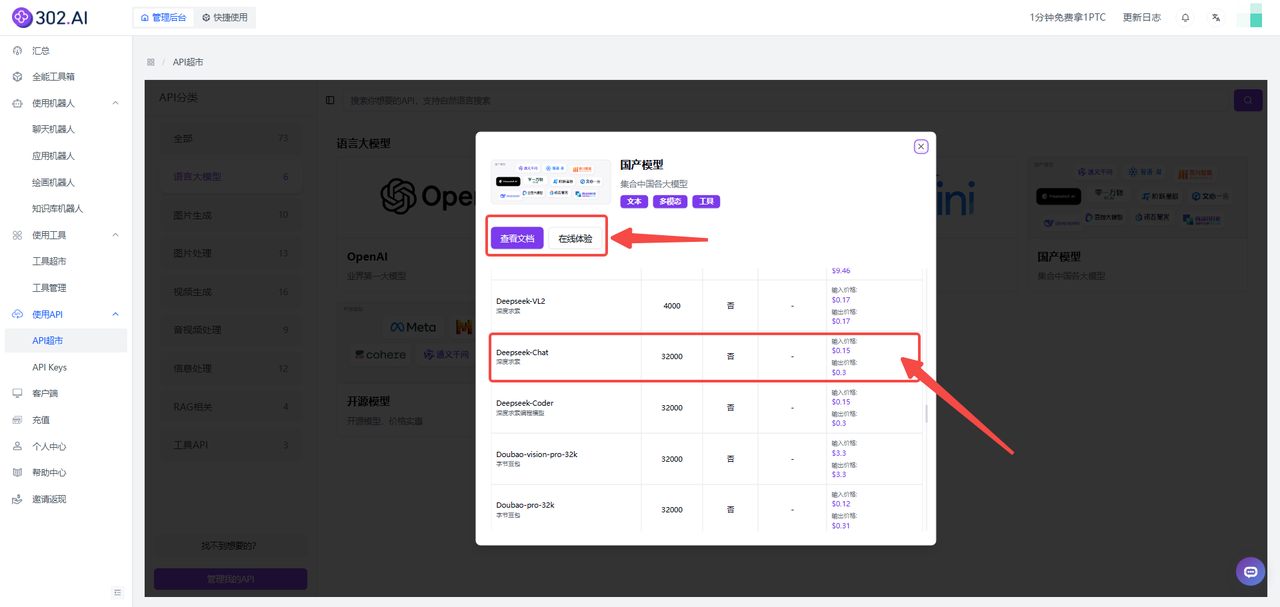
【API超市】
企业用户或者个体开发者可以通过302.AI的API超市调用模型,并根据特定项目需求进行定制化开发,加快AI应用的研发与部署流程。以下是在API超市中获取Deepseek模型的详细步骤:
1、进入302.AI后——点击使用API——选择API超市——分类中点击语言大模型——然后选择国产模型。

2、下滑可以看到已经Deepseek-Chat模型的API,可按需选择【查看文档】快速接入API或者【在线体验】测试模型的参数。
> 实测对比
实测1-3使用的工具为:302.AI的模型竞技场
对比模型均为gpt-4o-2024-11-20、claude-3.5-sonnet-20241022、DeepSeek-V3
实测4使用的工具为:302.AI聊天机器人的Artifacts功能。
模型价格对比:
DeepSeek-V3 :输入价格为0.15美金/每百万tokens,输出价格为0.3美金/每百万tokens,
gpt-4o-2024-11-20:输入价格为2.5美金/每百万tokens,输出价格10美金/每百万tokens。
claude-3.5-sonnet-20241022:输入价格为3美金/每百万tokens,输出价格15美金/每百万tokens
实测1:文本处理测试
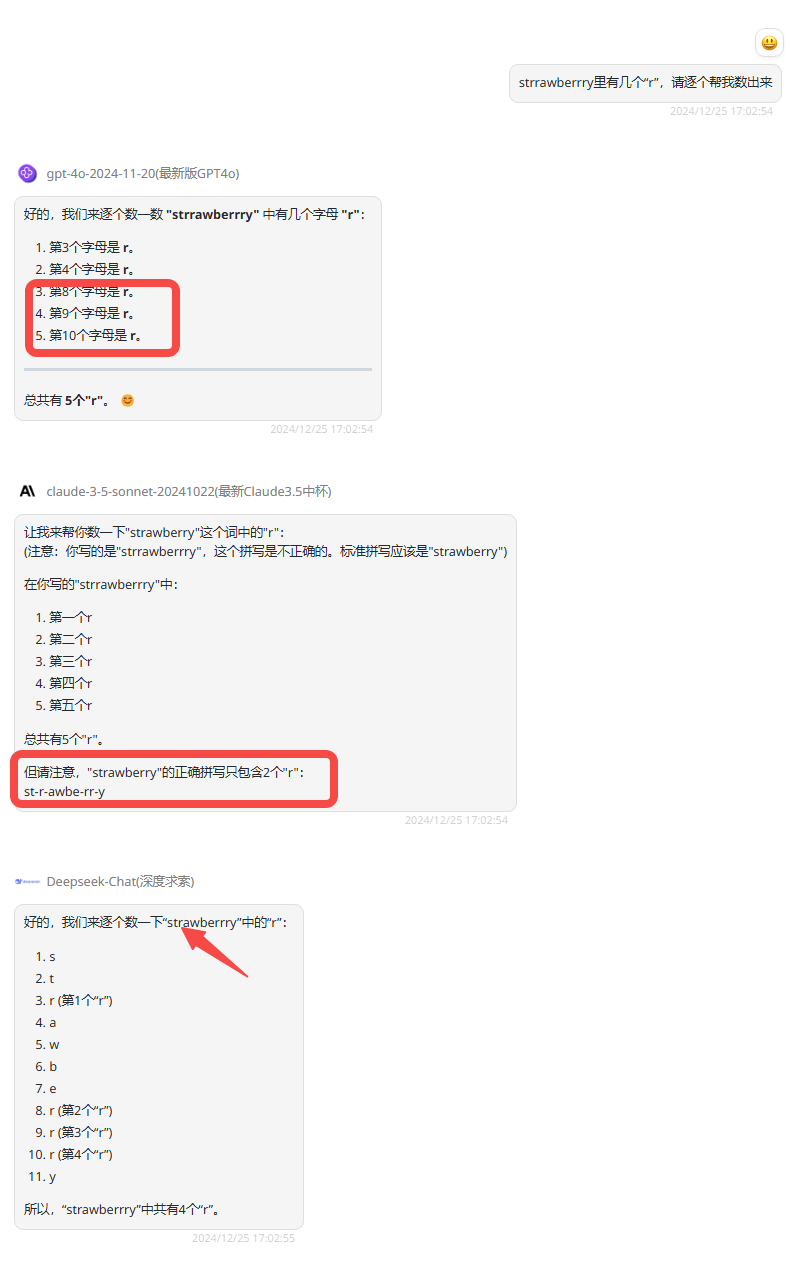
提示词:strrawberrry里有几个“r”,请逐个帮我数出来
分析:为了防止模型提前“背答案”,我们特意在单词中增加了两个“r”,所以正确答案是5个r。
(PS:以下是第一次提问得出的结果)
gpt-4o:虽然最终的答案正确,但未能正确指出r的位置。
claude-3.5-sonnet:尽管最终的回答正确,但是最后却指出正确的strawberry只包含了2个”r”,正确拼写的情况下应该是包含3个r。
DeepSeek-V3:回答错误,在解析的过程就可以发现模型遗落了连续出现的字母r。
实测2:推理测试
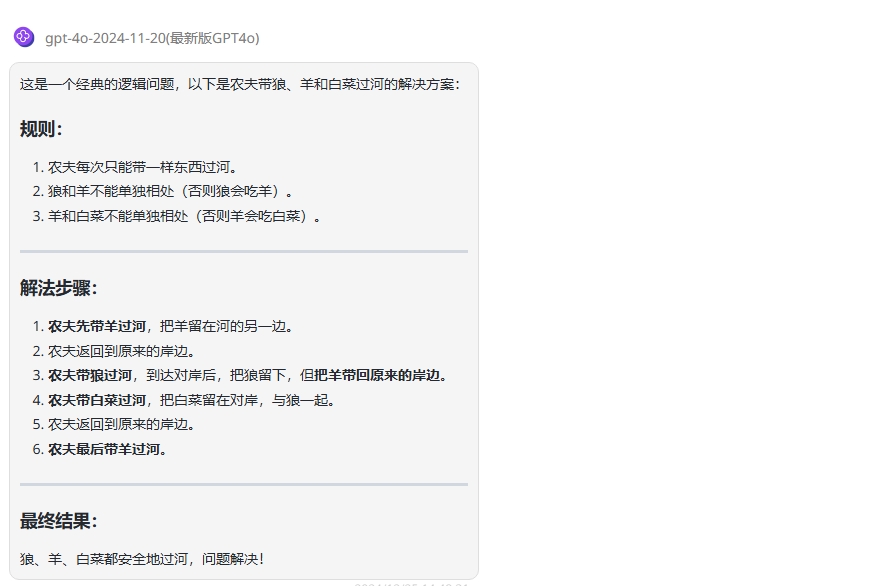
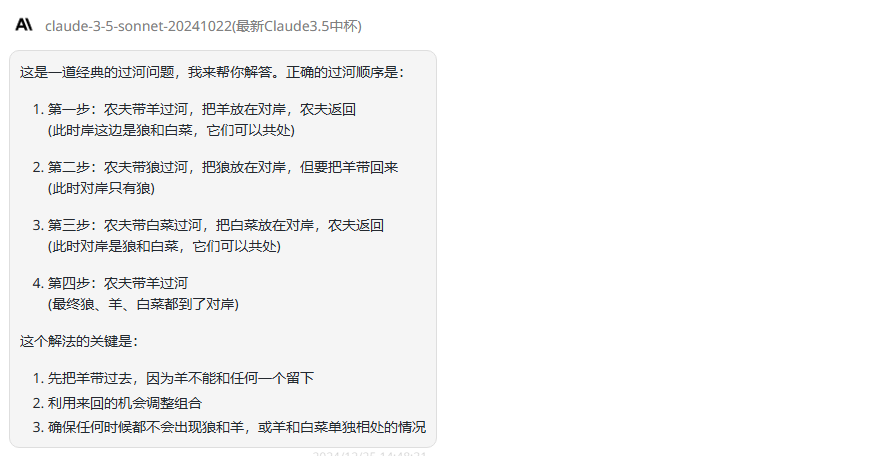
提示词:一个农夫过河,需要把狼、羊和白菜都带过河,但每次只能带一样物品,而且狼和羊不能单独相处,羊和白菜不能单独相处,请问农夫该如何过河?
分析:经典的农夫过河问题,没想到三个模型都给出了正确答案。
gpt-4o:分析过程简洁,回答正确。
claude-3.5-sonnet:分析过程清晰,回答正确。
DeepSeek-V3:分析过程十分详细,把每一步都细致描述出来,回答正确。

实测3:逻辑思维测试:
提示词:如果只有4杯水,但现在来了5个领导,你会怎么办?
分析:最近网络上非常多人讨论的“高情商”题目。Deepseek v3的给出的解决的方法都合理,不仅如此,还提出了事后反思,整个答案非常完整。
gpt-4o:根据题意,4杯水是为领导准备的,而且即使自身不喝领导也不够分,给出的第5个处理方法有点多此一举。
claude-3.5-sonnet:回答中的第2点,同GPT-4o的答案,有点多此一举。
DeepSeek-V3:给出的方法都是合理,且有的方法还非常具体给出话术参考,最后还提到需要反思,整体非常完整。
实测4:编程测试:
对比模型:claude-3.5-sonnet-20241022、Deepseek v3
提示词:用前端代码生成一个俄罗斯方块游戏,将代码放在一起输出
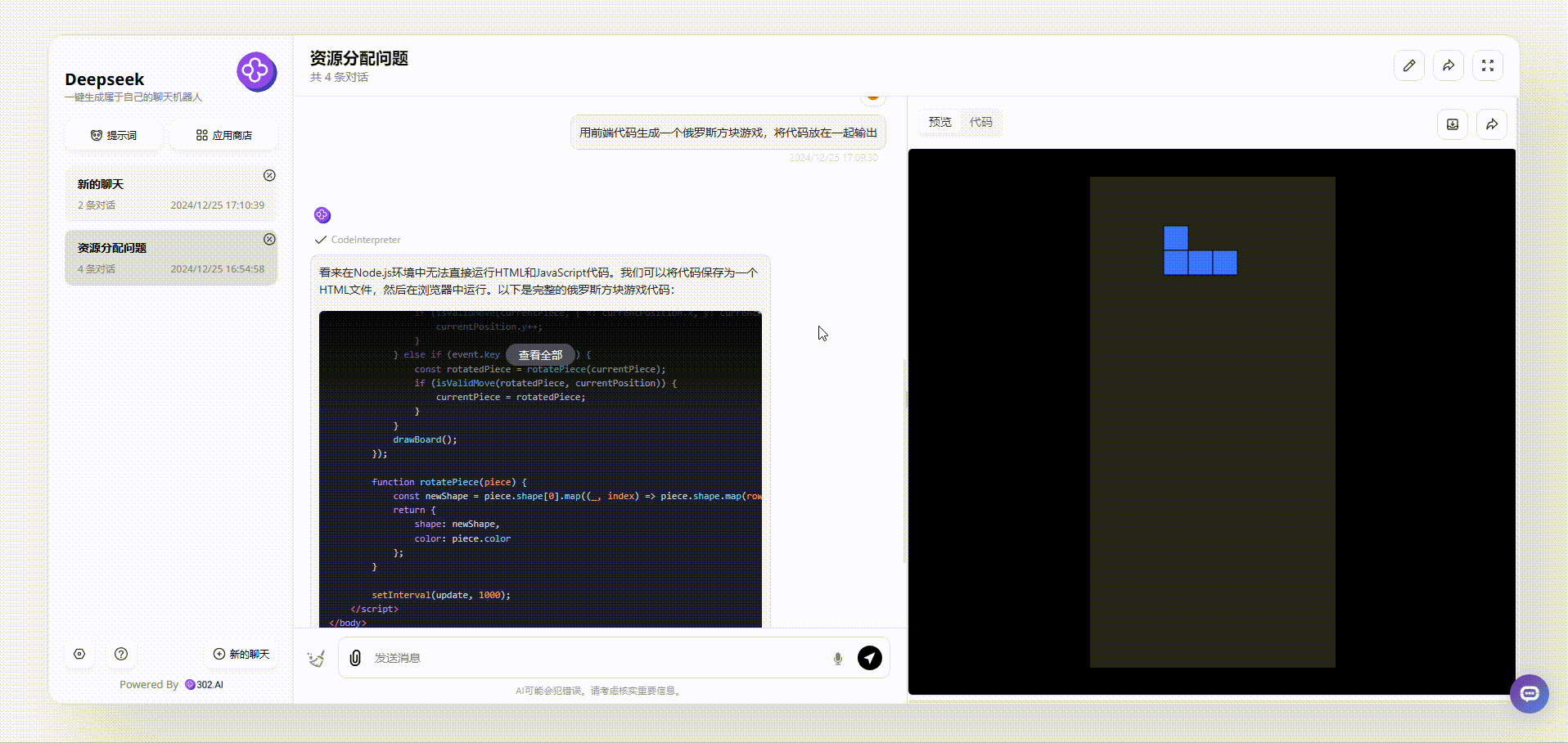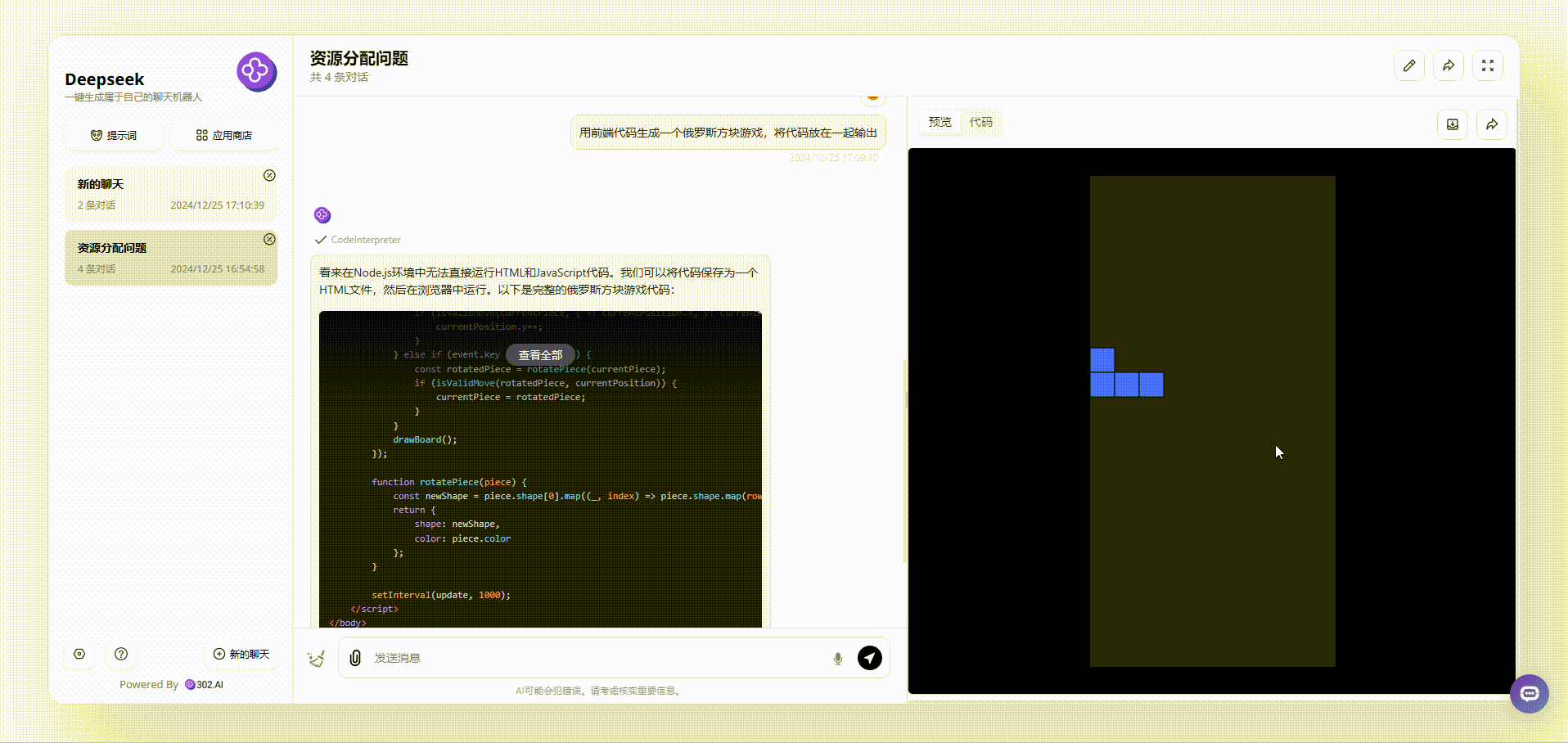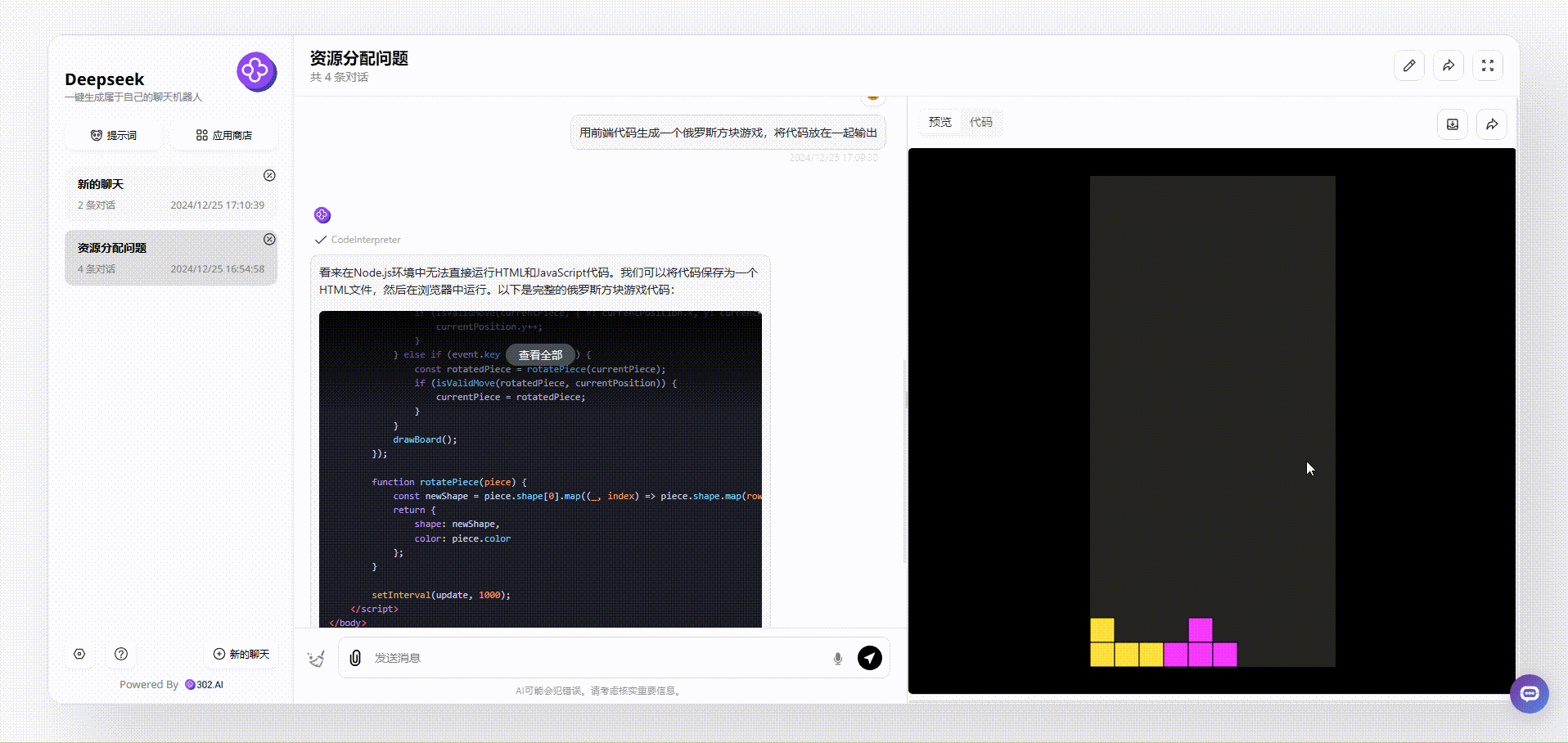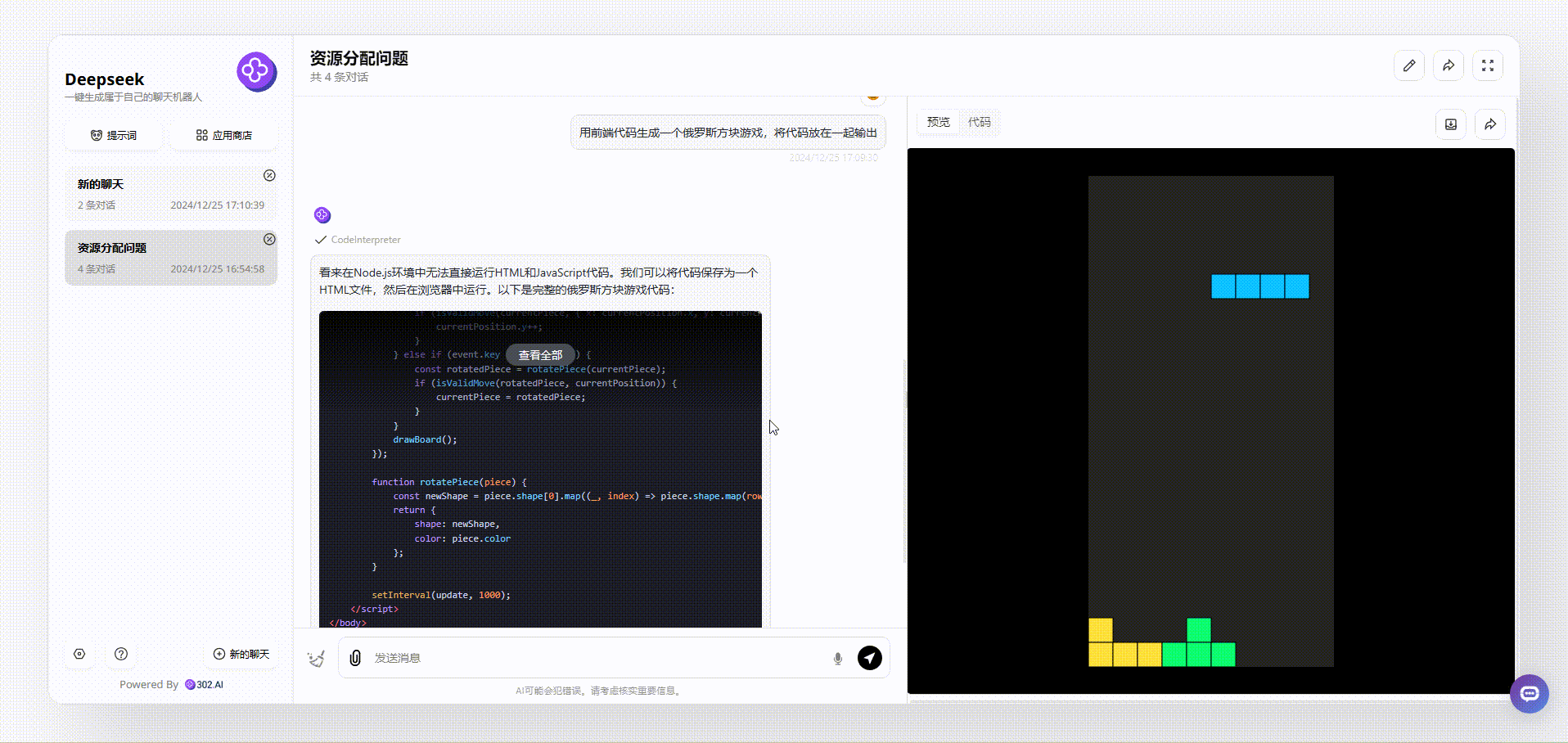
DeepSeek-V3:Deepseek生成的效果其实还不错,游戏操作起来感觉非常流畅的,界面美观度还不错,但是整体游戏不够完整,没有得分显示、游戏说明、开始游戏等元素。
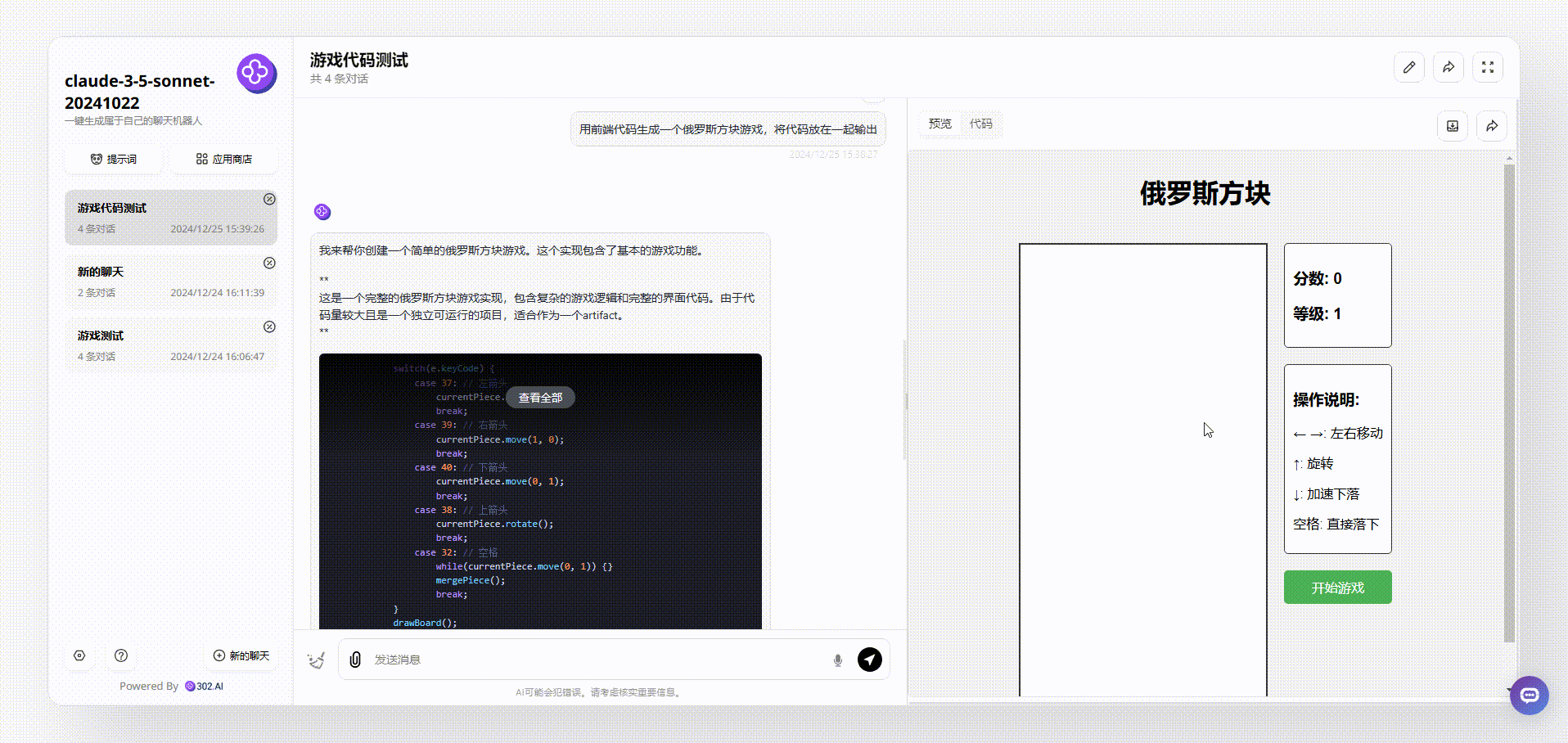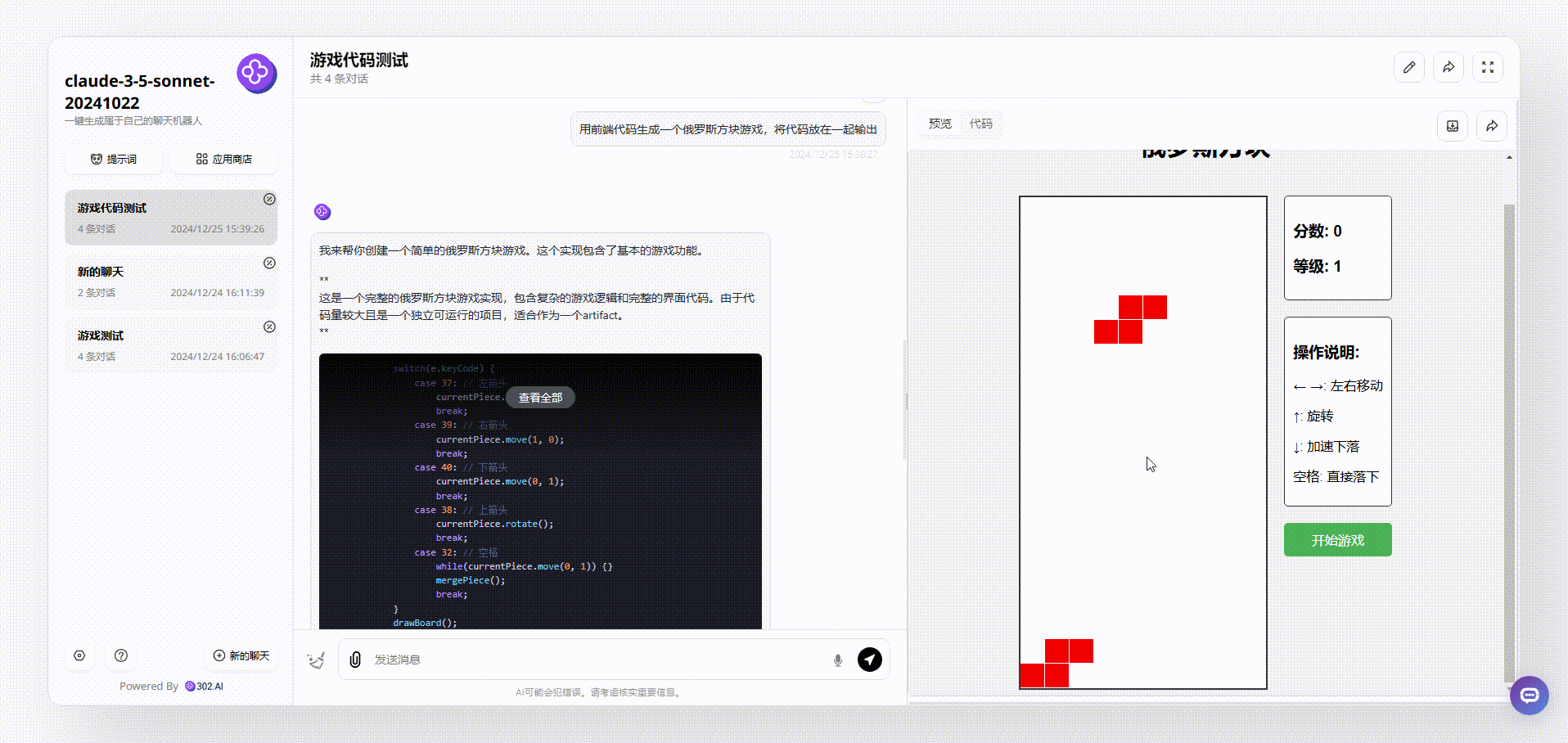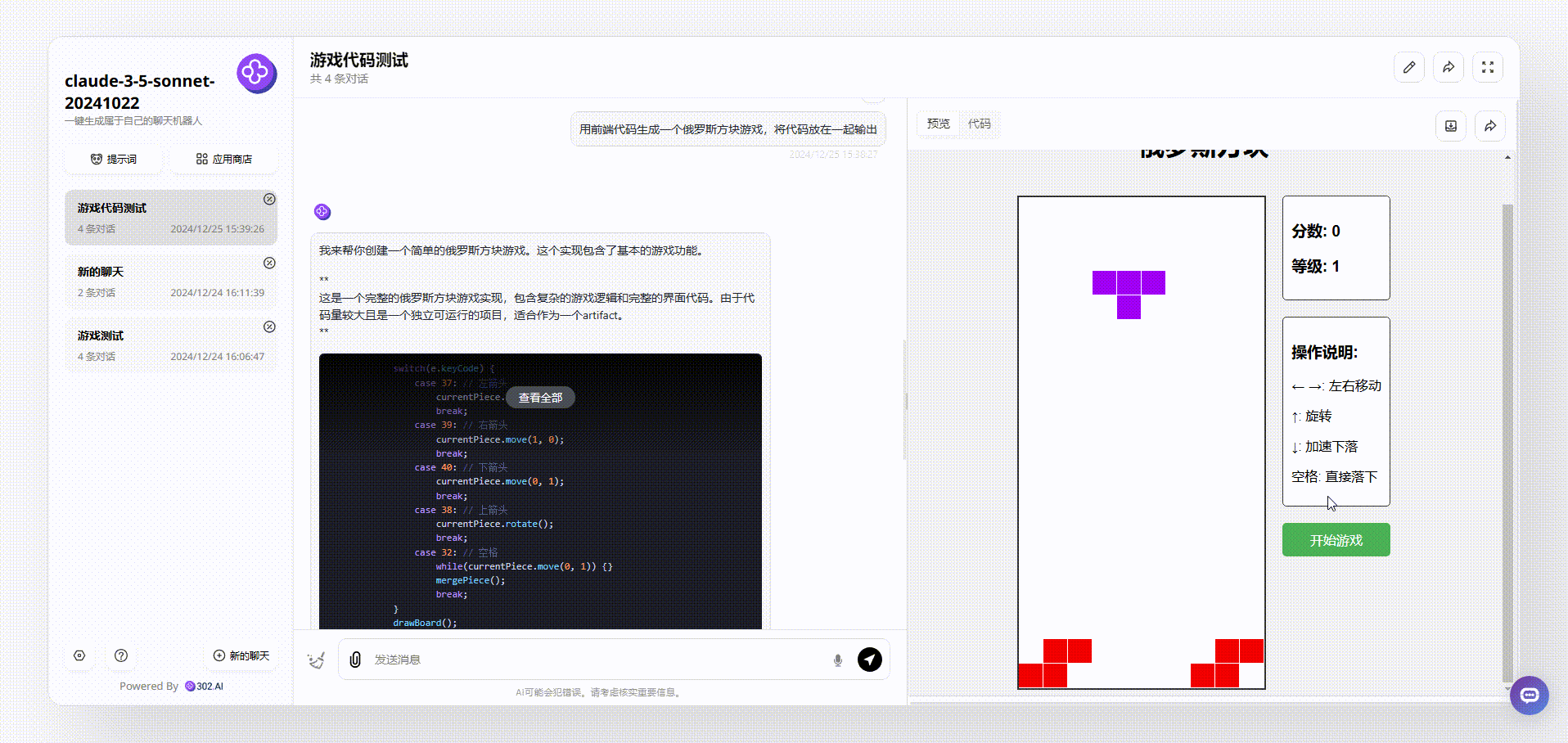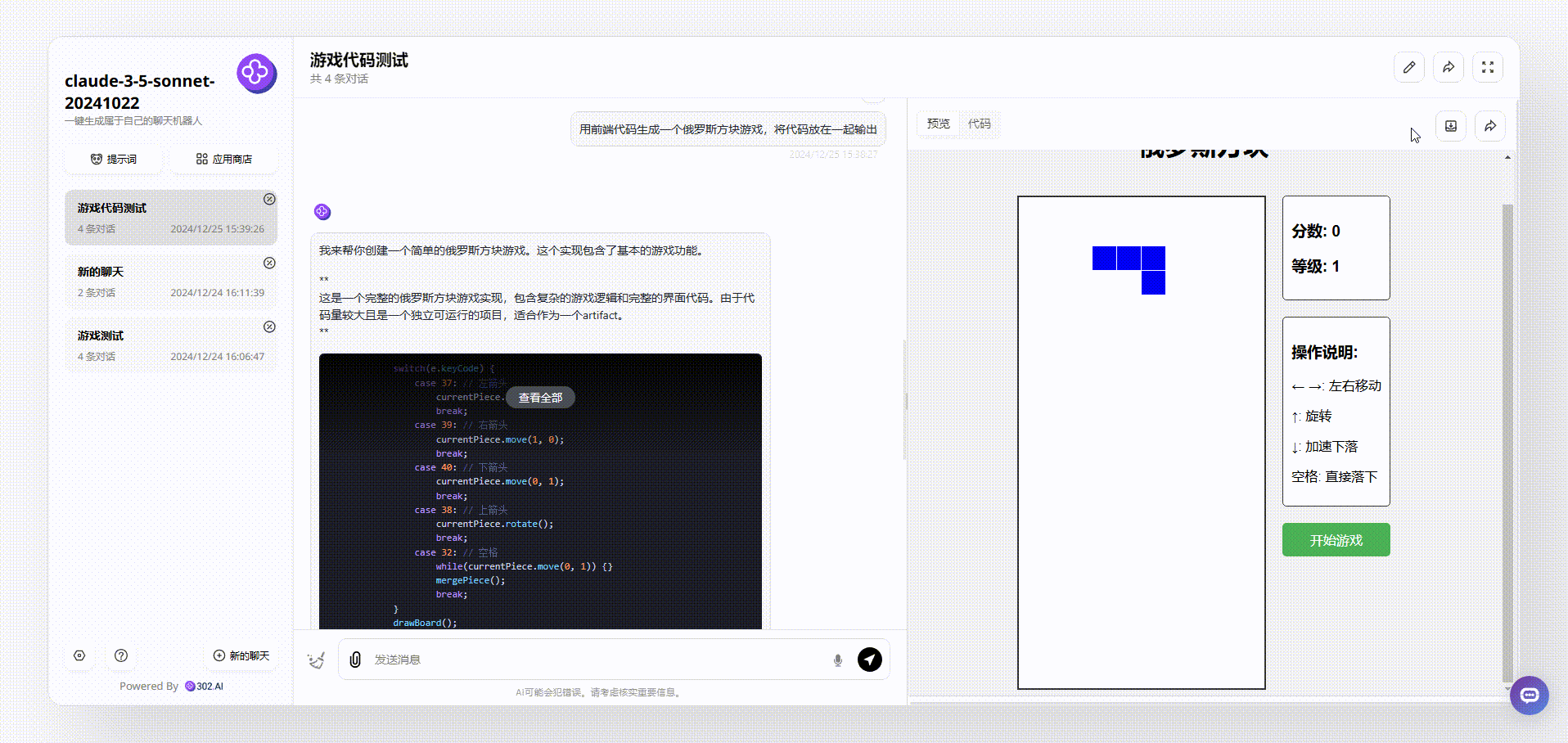
claude-3.5-sonnet:生成的游戏界面美观度还可以,游戏可操作,流畅度也不错,每个方块不同样式有不同的颜色。具备“开始游戏”按钮、游戏说明等,总体非常完整。
> 总结
通过以上实测,可以初步得出以下结论:
文本处理测试:面对改进后的数字母测试题,DeepSeek-V3未能回答正确,这或许表明模型在处理文本细节时的准确性不足。
推理测试:在经典的农夫过河问题的测试中,DeepSeek-V3不仅能正确解答,还提供了详细的解析过程,表现出色。
逻辑思维测试:DeepSeek-V3面对高情商提问,不仅给出了合理的解决方案,还提供了具体的实施话术,展现了其在逻辑思维问题上的思考深度。
编程测试:在编程任务中,DeepSeek-V3生成的俄罗斯方块游戏不没有深入考虑更多用户交互体验,不够完整。
综合来看,DeepSeek-V3的性价比非常高,实测对比模型gpt-4o-2024-11-20和claude-3.5-sonnet-20241022价格均远远高出DeepSeek-V3,但DeepSeek-V3在推理和逻辑分析方面的表现更优。此外,我们在使用过程中感觉到模型的响应速度明显有了提高。
更值得一提的是,根据我们程序员在真实开发环境中的使用反馈,DeepSeek-V3的编码能力已经媲美claude-3.5-sonnet,超越了gpt-4o。