
12月25日圣诞节当天,阿里通义千问Qwen团队发文宣布推出首个开源视觉推理模型——QVQ-72B-Preview。该模型展现出优秀的视觉理解和推理能力,在解决数学、物理、科学等领域的复杂推理问题上表现尤为突出。


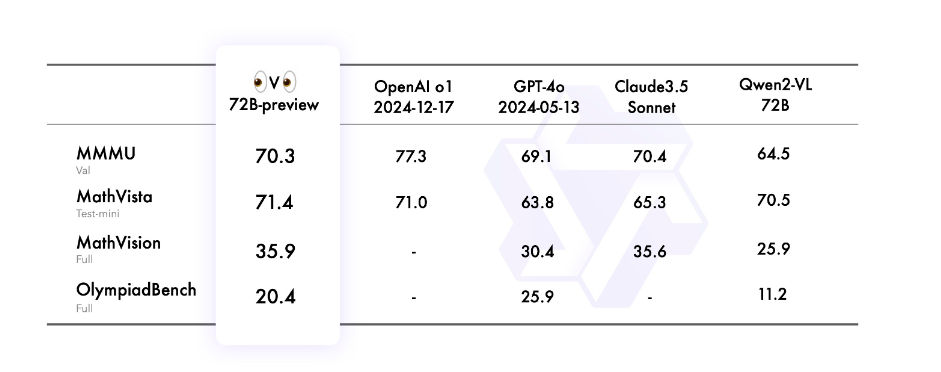
Qwen团队在 4 个数据集上评估了QVQ-72B-Preview,包括MMMU、MathVista、MathVision 、OlympiadBench。其中在MMMU 基准测试中取得了 70.3 的分数,超越了 Qwen2-VL-72B-Instruct。此外,在剩下的三个专注于数学和科学问题的基准测试中,QVQ-72B-Preview表现出色,有效缩小了与领先的最先进的 o1 模型之间的差距。
> 在302.AI上使用
当前302.AI的聊天机器人和API超市均上线了QVQ-72B-Preview模型。
302.AI提供按需付费的服务方式,无论是企业还是个人用户,都能够依据实际需求灵活选择使用模型,从而满足自身需求。
【聊天机器人】
用户可以通过聊天机器人快速体验最新模型。302.AI的聊天机器人提供市场上多种先进模型,并持续进行更新,保持与市场的发展同步。以下是在聊天机器人中获取QVQ-72B-Preview模型 的步骤:
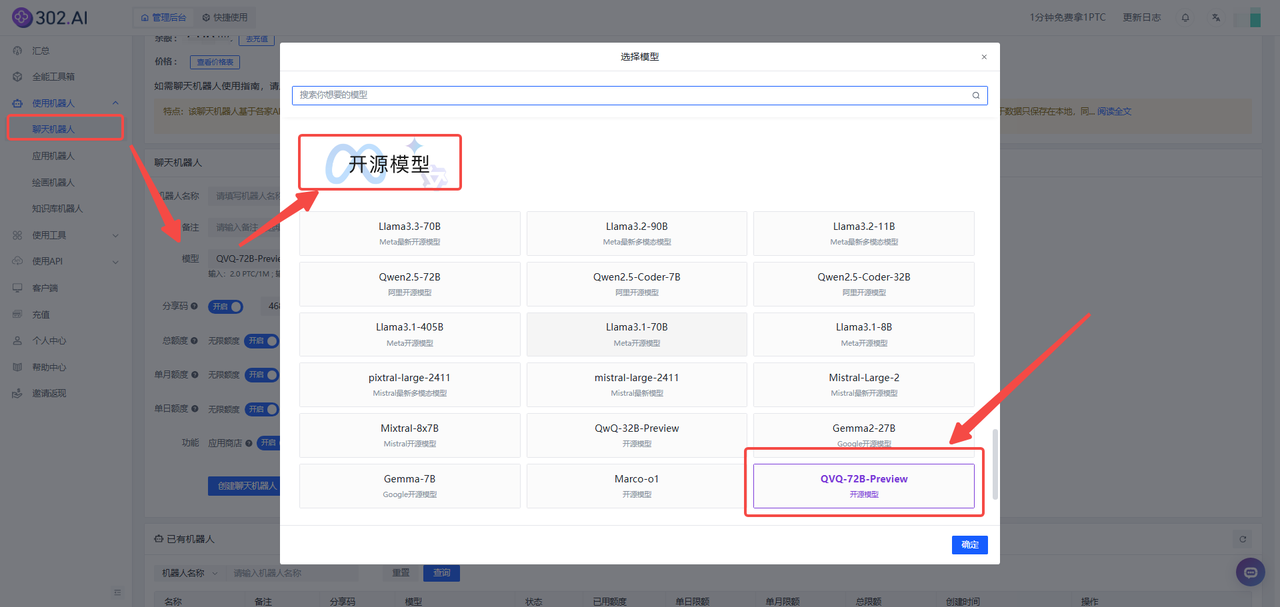
1、进入302.AI——点击左侧菜单栏使用机器人——选择聊天机器人——点击模型——选择QVQ-72B-Preview模型并确定,最后点击创建聊天机器人按钮;
【API超市】
302.AI的API超市涵盖了多种API,且分类明晰。企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发,加快AI应用的研发与部署流程。以下是在API超市中获取QVQ-72B-Preview的详细步骤:
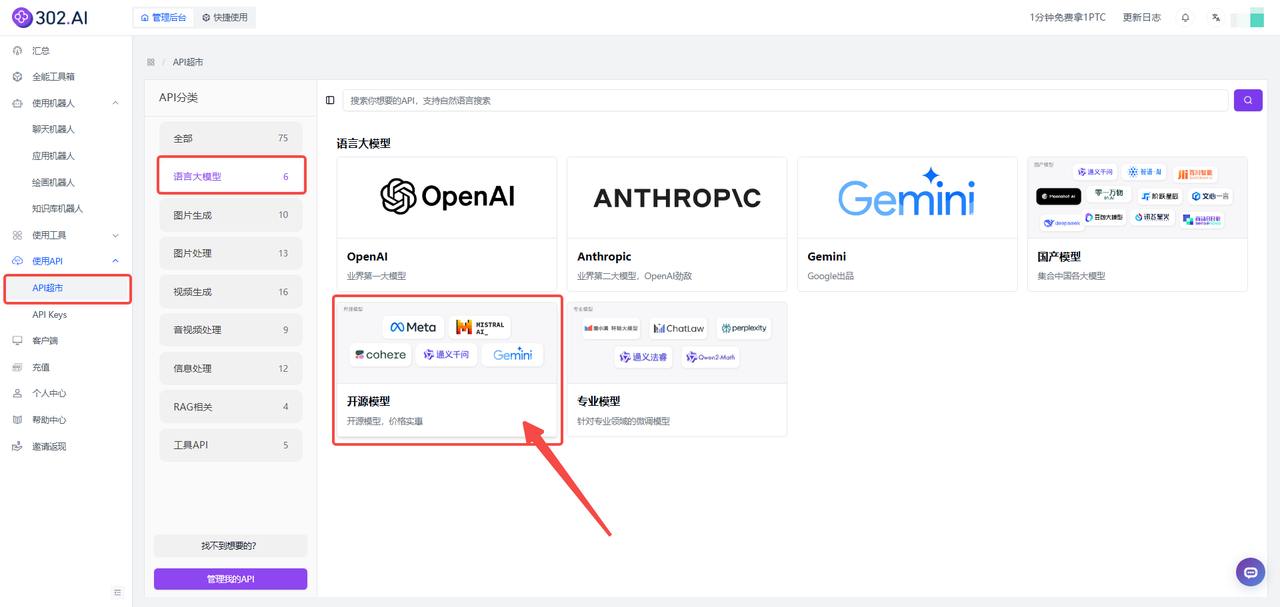
1、进入302.AI后——点击使用API——选择API超市——分类中点击语言大模型——选择开源模型。
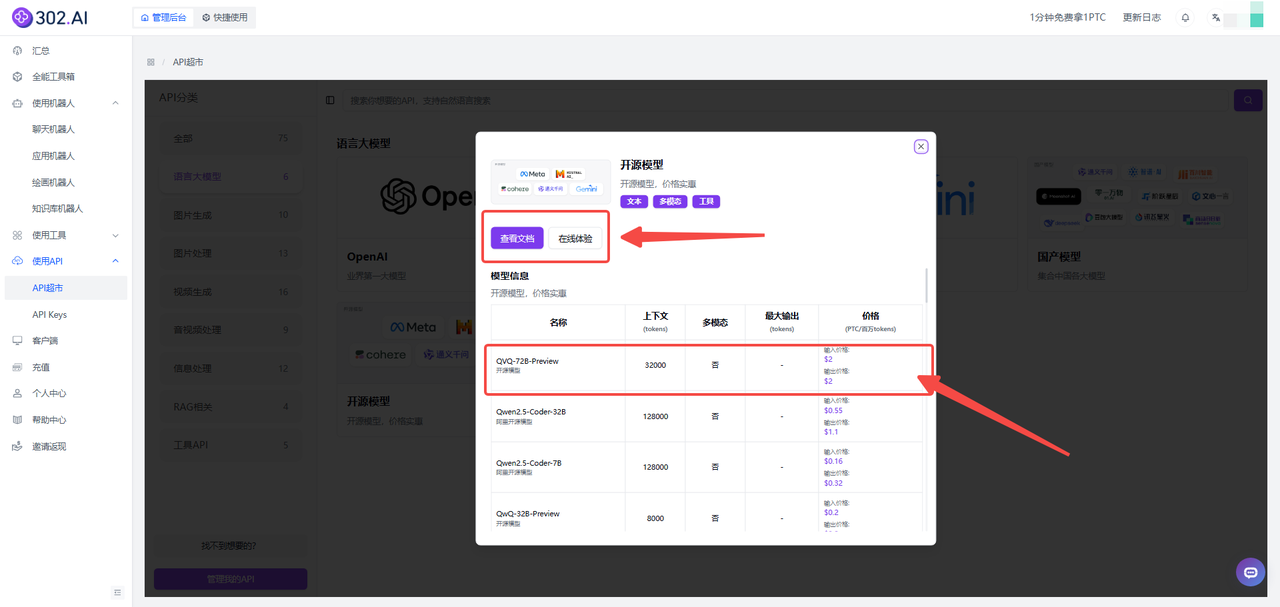
2、下滑可以看到已经提供了模型QVQ-72B-Preview的API,可按需选择【查看文档】快速接入API或者【在线体验】测试模型的参数。
> 实测对比
为了更直观了解模型,下面会使用302.AI的模型竞技场进行模型对比。
对比模型:QVQ-72B-Preview、Doubao-vision-pro-32k、grok-2-vision-1212;
对比模型均是多模态模型,且价格较为接近。
实测1:图像内容识别
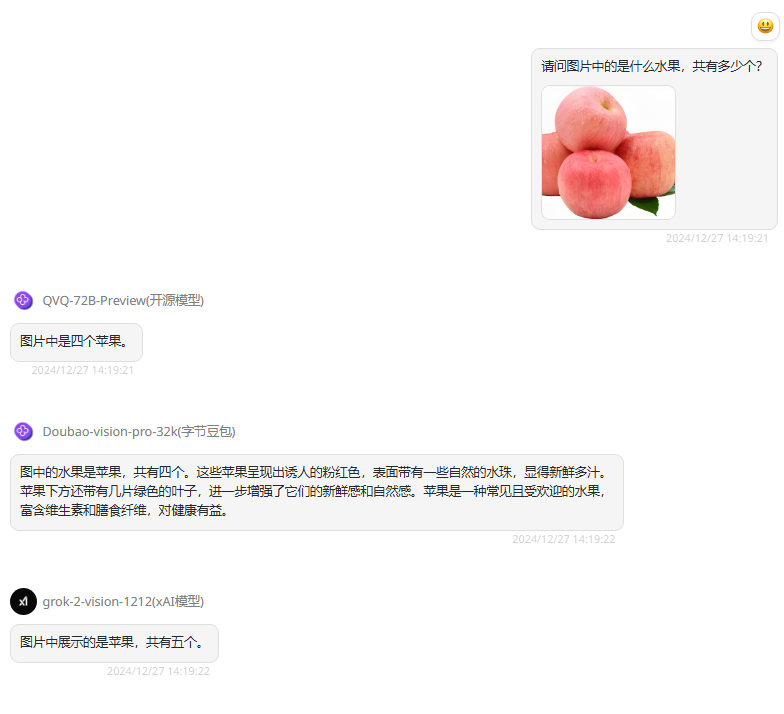
提示词:请问图片中的是什么水果,共有多少个?

分析:第一轮是图像内容识别测试,旨在评估模型在视觉感知和理解方面的能力。根据图片,正确答案为5个苹果,有一个苹果隐藏在后侧只微微露出一点。
QVQ-72B-Preview:物体识别正确,但数量回答错误。
Doubao-vision-pro-32k:物体识别正确,虽然在输出的答案中非常详细地描述了苹果的外型,但是数量没答对。
grok-2-vision-1212:物体与数量都回答正确。
实测2:物理测试
提示词:请根据图片回答问题
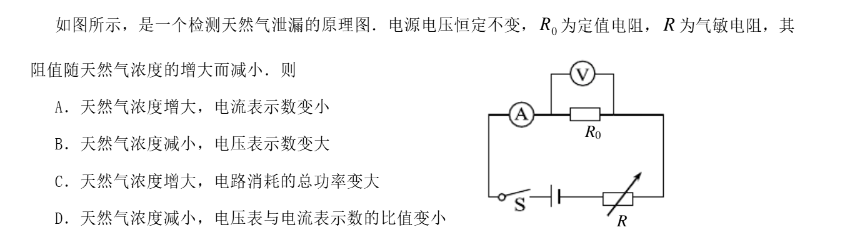
分析:根据介绍Qwen团队介绍,QVQ-72B-Preview模型非常擅长物理方面的问题。因此,第二轮实测为一道中考物理题。
QVQ-72B-Preview:回答正确,但是输出的回答先是分析题目得出答案,再对答案进行验算,对比其他模型的答案,整体篇幅较长。

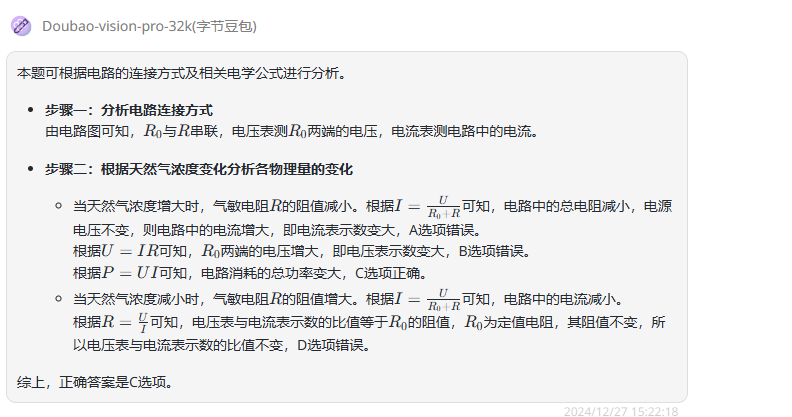
Doubao-vision-pro-32k:回答较为简洁清晰且答案正确。
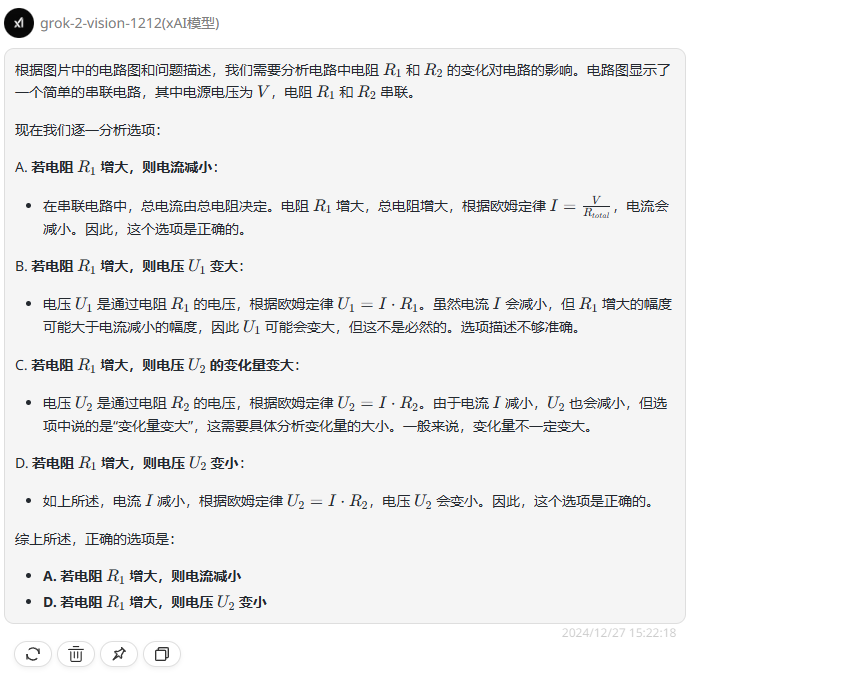
grok-2-vision-1212:虽然输出的格式很规整,但可惜回答错误。
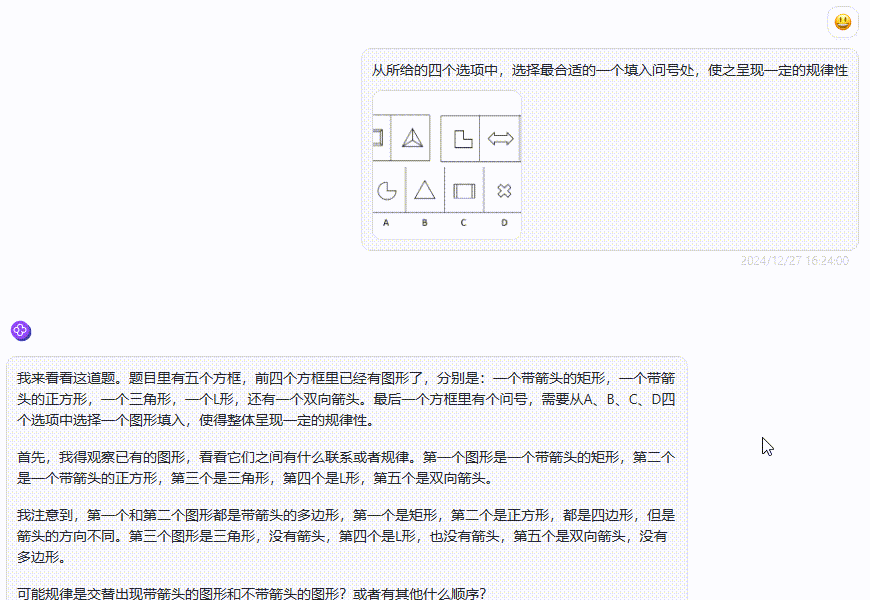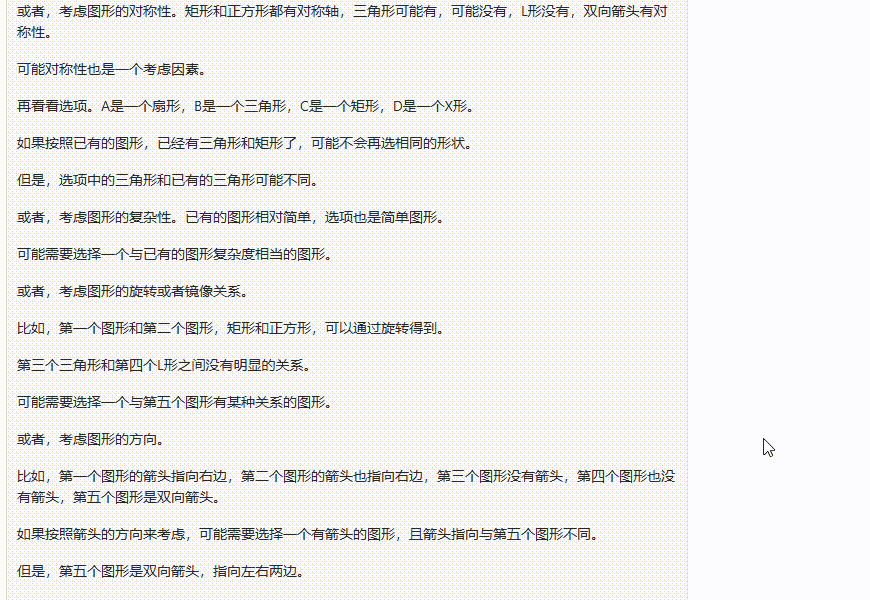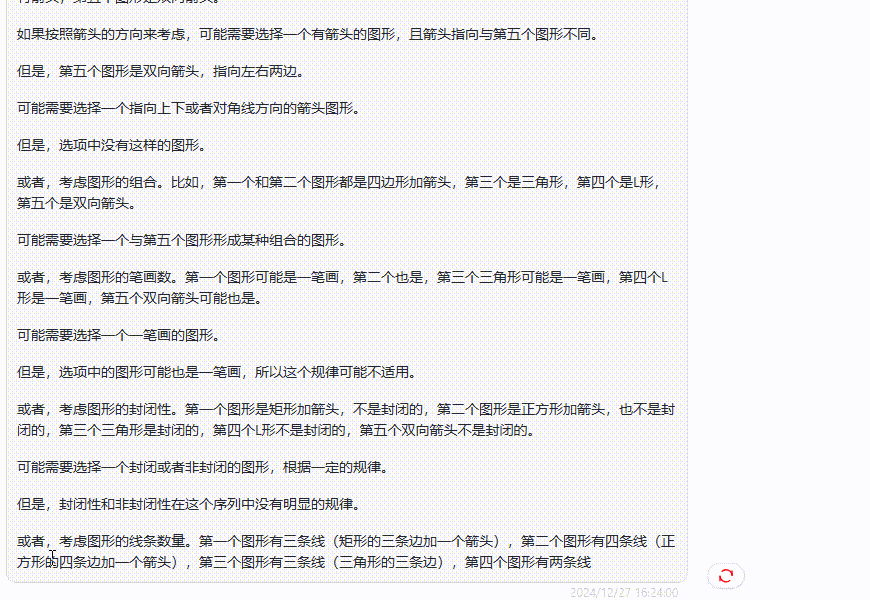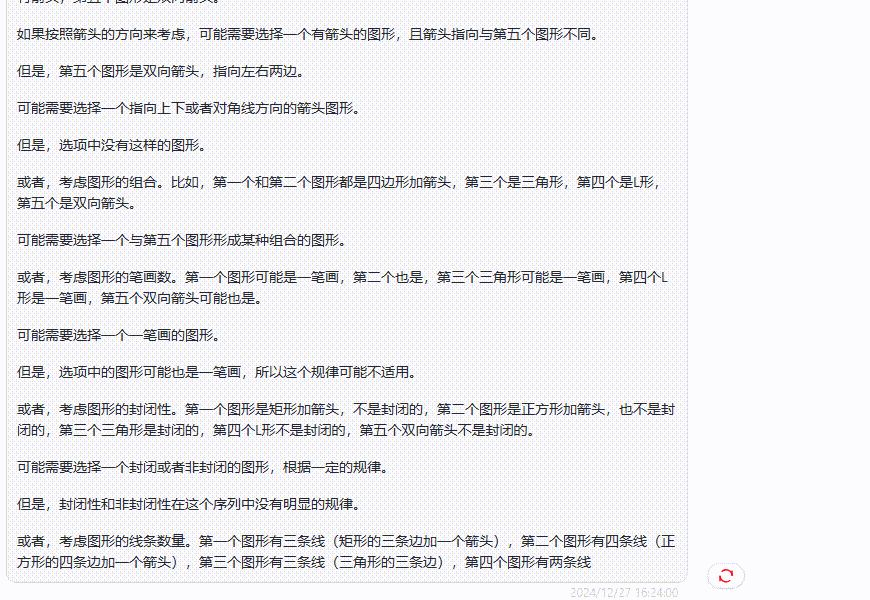
实测3:图形推理测试
提示词:请问图片中问号处应该填什么?
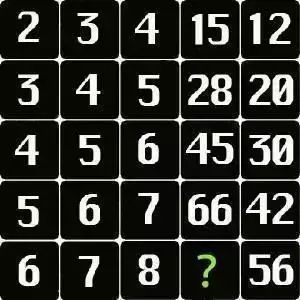
分析:这是一个逻辑推理,需要模型找出正确的规律。
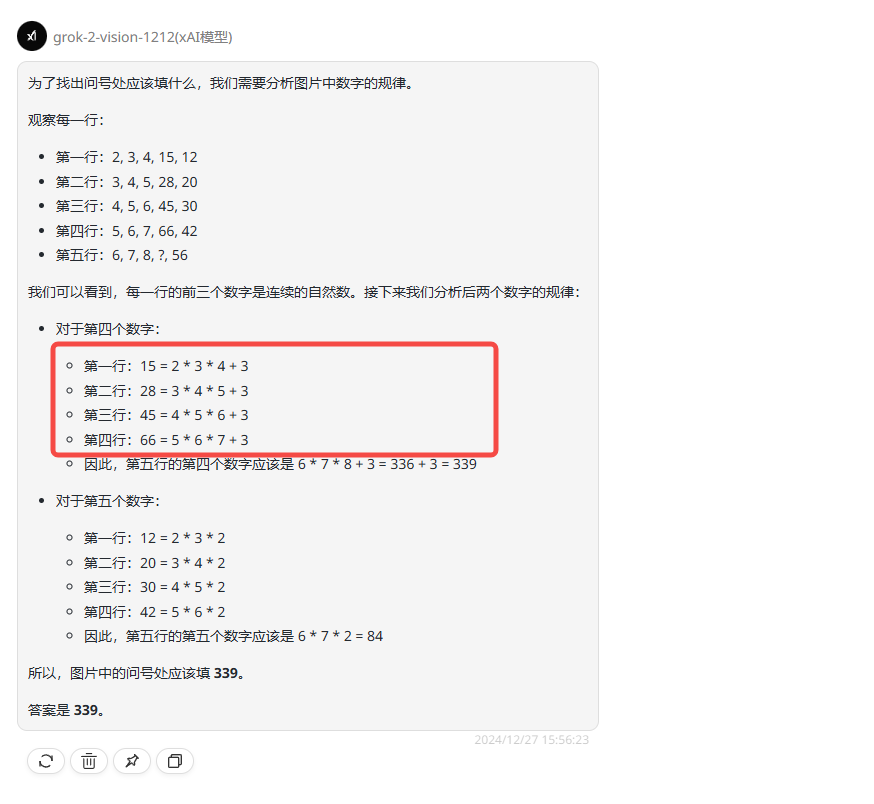
答案分析:问号处为第四列数字,根据图片上的数字,可以得出规律:第四列的数字=(第一列的数字+第二列的数字)x(第二列的数字)。例如第一行:(2+3)x3=15,第二行:(3+4)x4=28,以此类推,所以问号处的数字是:(6+7)x7=91。
QVQ-72B-Preview:首先QVQ最后的答案是正确的,但是这次输出的答案篇幅更长。在得出答案后,还一直寻找其他规律,然后开启反复验算、否定的思路过程。
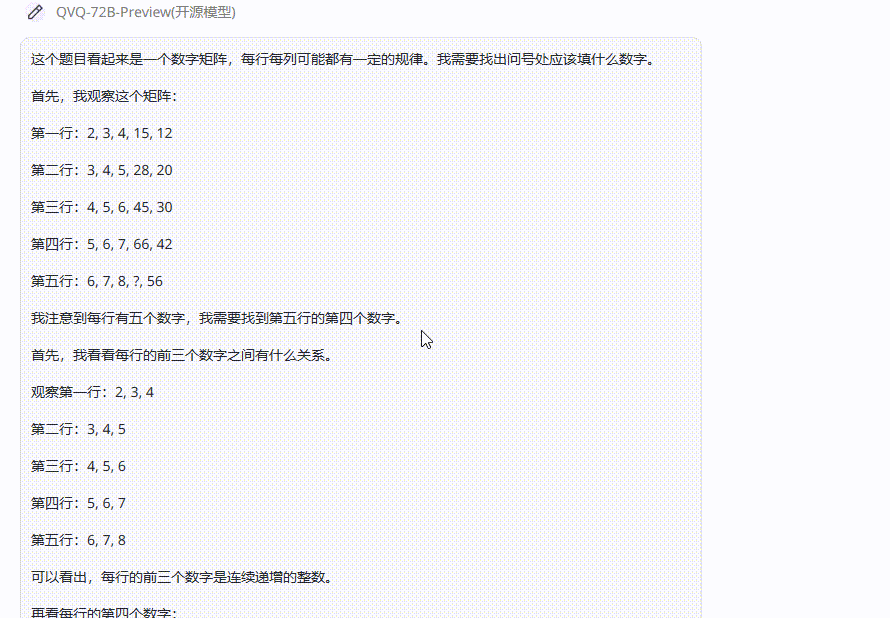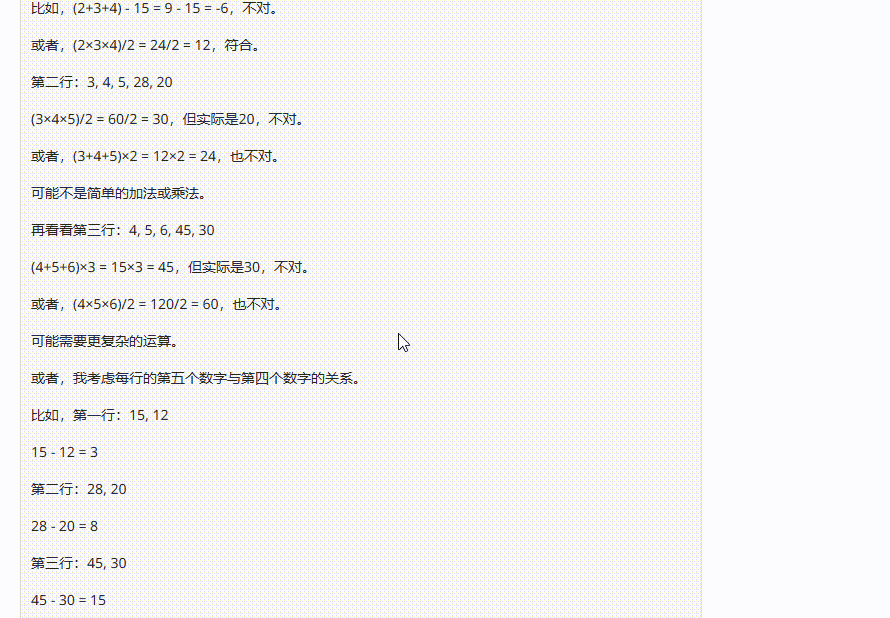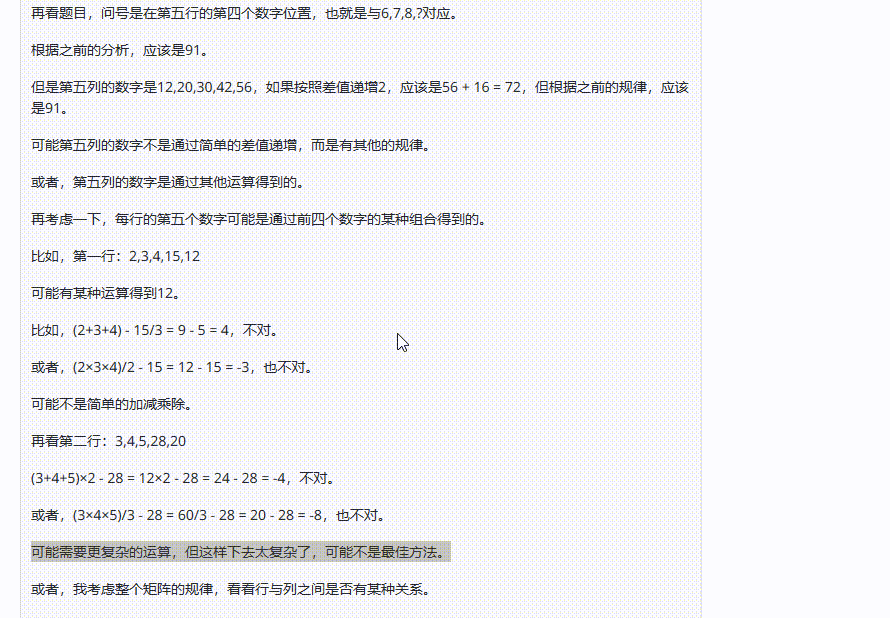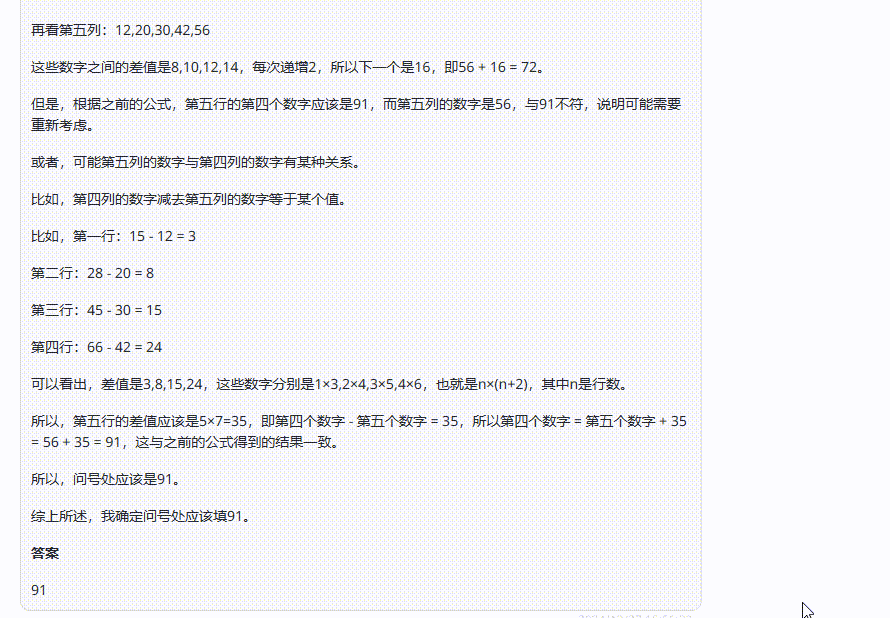
Doubao-vision-pro-32k:分析错误,寻找的规律一开始就并不成立,最后回答错误,

grok-2-vision-1212:分析错误,答案错误。
实测中存在的问题:
实测过程中,我们发现模型在面对较为复杂的题目容易陷入无限循环思考,久久无法给出答案,最终只能手动暂停输出。我们尝试在提示词中加入限制“得到答案后不需要进行反复验算”,也无法避免。比如:
面对复杂的数学题目时:
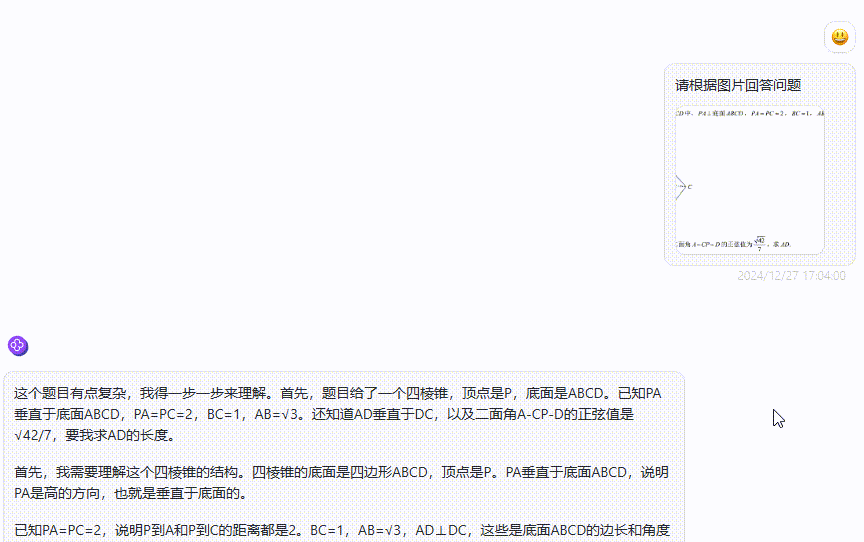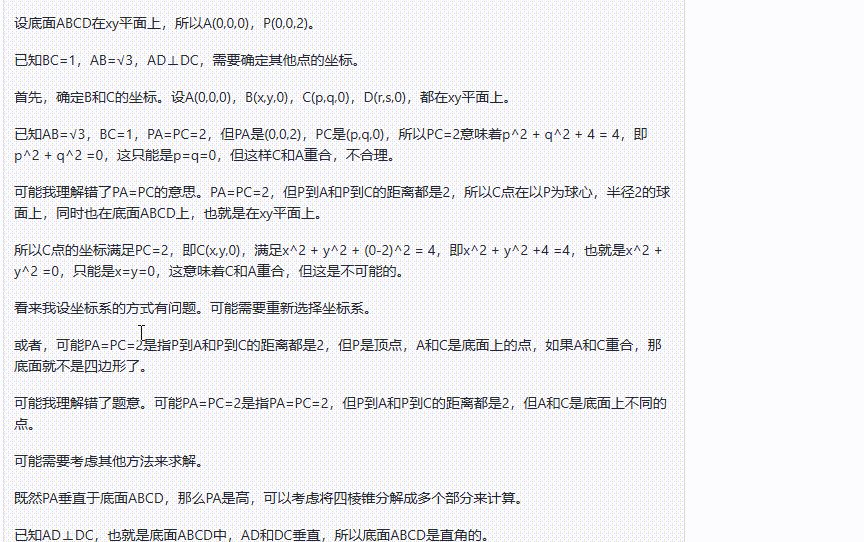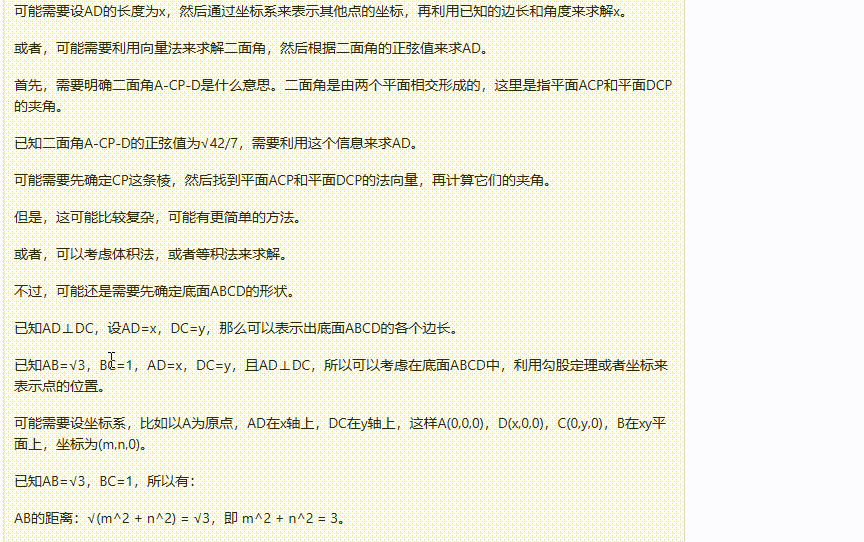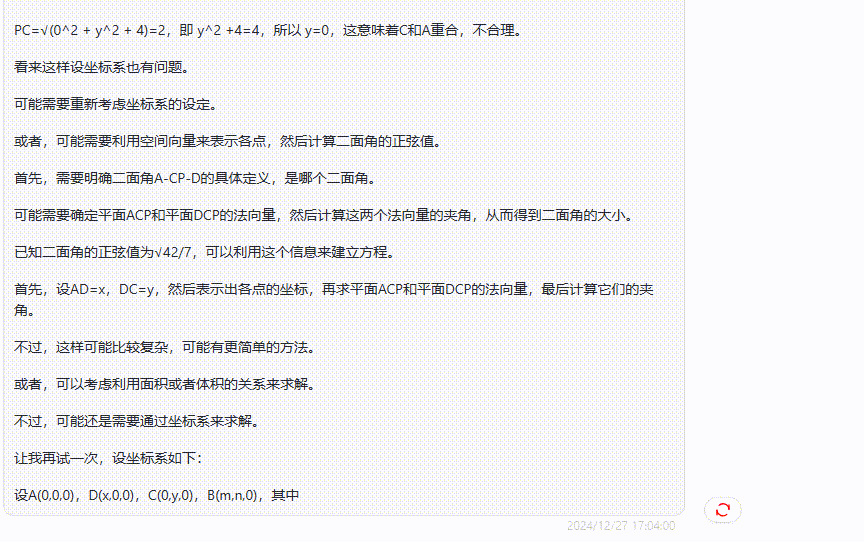
面对复杂的图形推理题时:
> 总结:
通过以上实测,可以初步得出以下结论:
内容识别测试:在内容测试中未能给出正确答案,这表明在视觉感知能力方面还存在不足。
物理测试:在物理测试中给出了正确答案,展现了出色的物理解题能力。
图形推理测试:QVQ-72B-Preview的输出在逻辑推理题上相对冗长,虽然最终得出的答案是正确的,但其推理过程显得有些繁琐。
总体来看,QVQ-72B-Preview展现了一定的视觉理解和推理能力,但输出答案过长,用户在使用过程中无法快速获取答案,且过长的答案输出可能包含模型生成的错误或无关信息,从而增加幻觉风险。
此外,Qwen团队还指出,QVQ-72B-Preview模型目前存在“会意外地混合语言或在语言之间切换,从而影响响应的清晰度”的问题,但在实测中我们未遇得到这样的情况。
随着进一步的优化和迭代,期待Qwen团队在未来能够克服现有的不足,带来更优质的多模态模型。