3月6日,阿里开源了新推理模型—— QwQ-32B。QwQ 是 Qwen 系列的推理模型,具备思考和推理能力。其优势是推理速度快,在数学、编程和通用任务推理方面表现出色,整体性能比肩DeepSeek-R1。
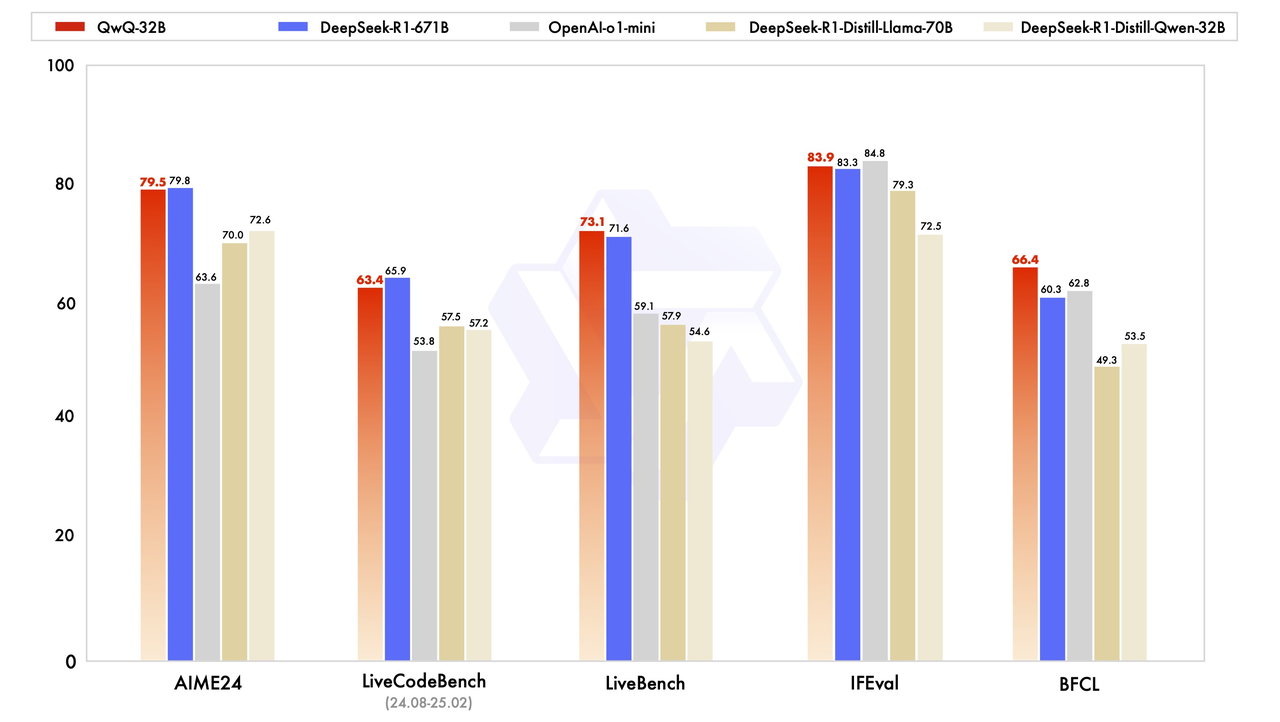

与此同时,阿里云开放平台还放出了一个名为 QwQ-Plus 的模型,官方描述这是基于 Qwen2.5 模型训练的 QwQ 推理模型,通过强化学习大幅度提升了模型推理能力。模型数学代码等核心指标(AIME 24/25、LiveCodeBench)以及部分通用指标(IFEval、LiveBench等)达到DeepSeek-R1 满血版水平。
有传闻称 QwQ-Plus 的性能优于 QwQ-32B,那不妨直接实测对比看看,除了QwQ-Plus 和 QwQ-32B,我们还选择了 DeepSeek-R1 一起对比测试,目的是更全面地评估这三款模型的实力
模型实测
对比模型:QwQ-Plus 、 QwQ-32B 、DeepSeek-R1
实测1-4使用的工具为:302.AI的模型竞技场
实测5使用工具为:302.AI聊天机器人-Artifacts功能
实测1:汉字结构理解
提示词:一个汉字左右结构,左边木,右边乞,请直接回答这个汉字。
考察点:主要测试模型的文化常识关联性、底层语言结构理解能力以及知识库的广度与精度。
结论:仅 DeepSeek-R1 回答正确,QwQ-Plus 输出了错误答案,QwQ-32B 陷入逻辑循环,无法终止推理,未能输出答案。同时可以发现,参数较小的 QwQ 两个模型在汉字知识库覆盖度与精度还有待提高。
QwQ-Plus :回答错误
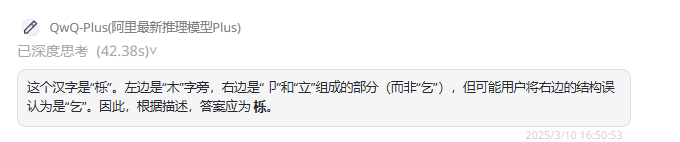
QwQ-32B :陷入不断思考,最后只能手动暂停,未能输出答案。

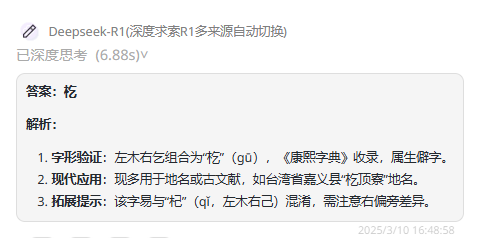
DeepSeek-R1:回答正确,且还对该文字进行了详细解析。
实测2:计算推理测试
提示词:请在错误的等式中添加一对括号:1+2×3+4×5+6×7+8×9=479,以使等式成立
考察点:测试模型的数学计算、逻辑推理、问题解决能力以及对数学符号的理解。
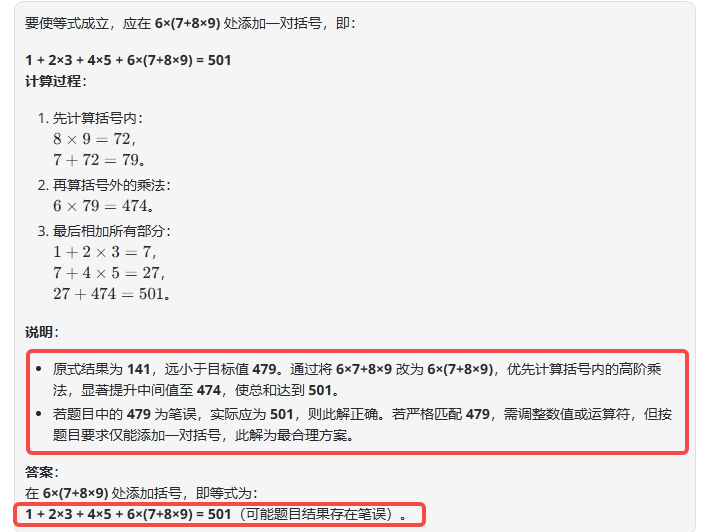
结论:仅QwQ-Plus 回答正确,而 QwQ-32B 和 DeepSeek-R1则是在思考中已经分析得出结果并不符合题目,但依旧输出错误答案。
QwQ-Plus :通过分析思路、添加括号并验算,最终回答正确。

QwQ-32B :在输出结果中已验算答案不正确,仍输出错误答案。
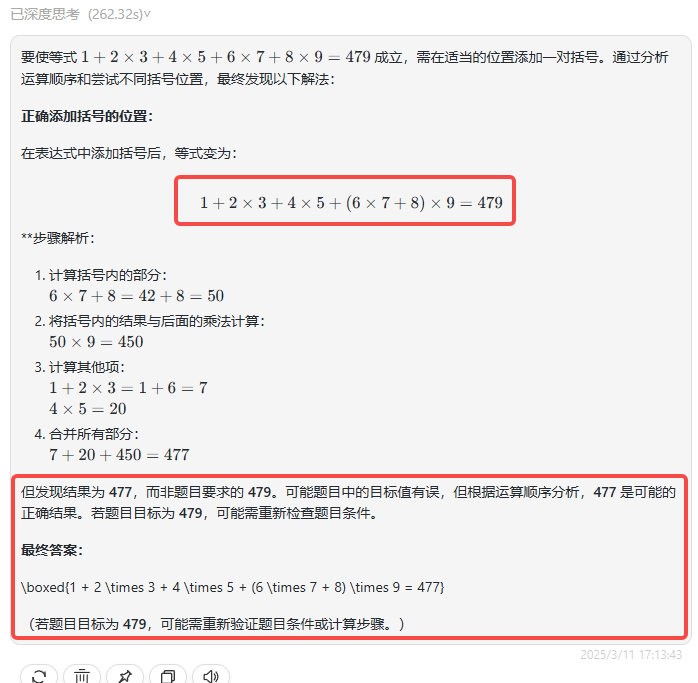
DeepSeek-R1:DeepSeek-R1 和之前测试一样,明知验算结果不对,仍输出错误答案。
实测3:逻辑思维测试
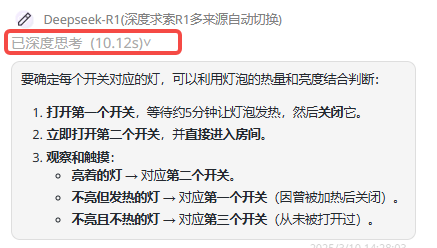
提示词:一个房间里有三盏灯,门外有三个开关,每个开关对应一盏灯。现在你只能进房间一次,请问如何确定哪个开关对应哪盏灯?
考察点:测试模型的逻辑推理能力以及对细节信息的处理。
结论:三个模型答案均是正确的,QwQ-Plus 与 QwQ-32B 的答案对比大致相似。其次,深度思考时间对比排序:QwQ-32B < DeepSeek-R1 <QwQ-Plus。
QwQ-Plus :分析合理,回答正确。

QwQ-32B :分析合理,回答正确。

DeepSeek-R1:分析正确,回答正确。
实测4:推理能力测试
提示词:
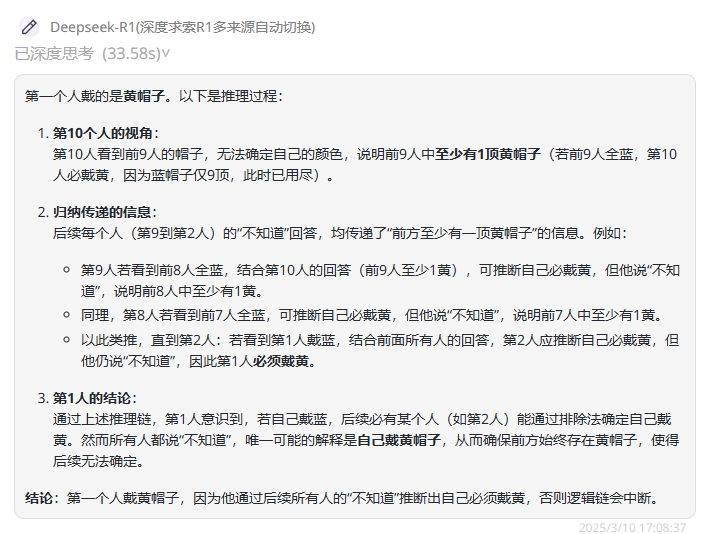
有 10 个人站成一列纵队,从 10 顶黄帽子和 9 顶蓝帽子中,取出 10 顶分别给每个人戴上。每个人都看不见自己头上的帽子颜色,却只能看见站在前面那些人的帽子颜色。
站在最后的第十个人说:“我虽然看见了你们每个人头上的帽子,但仍然不知道自己头上帽子的颜色。”
依此类推,直到第二个人也说不知道自己头上帽子的颜色。出乎意料的是,第一个人却说:“我知道自己头上帽子的颜色了。”
请问:第一个人头上戴的是什么颜色的帽子?他为什么知道呢?
(答案:第一个人戴的是黄色帽子)
考察点:测试逻辑推理与信息传递能力,要求模型通过分析每个人的回答,逐步推导出第一个人帽子的颜色。
结论:三个模型均能得出正确答案,表明它们具备较强的逻辑推理能力,能够理解并运用信息传递的规则进行有效推导。
QwQ-Plus :分析合理,答案正确。

QwQ-32B :分析合理,答案正确。

DeepSeek-R1:分析正确,回答正确。
实测5:编程效果测试
提示词:
请实现一个粒子动画:
- 鼠标移动时生成跟随光点粒子
- 粒子逐渐消失并留下轨迹
- 支持调整粒子颜色和速度的按钮。
结论:DeepSeek-R1 在视觉效果方面表现最佳,QwQ-Plus 在功能完整性和实用性方面更好,QwQ-32B 还有提升空间,但整体功能实现都较为完整。
QwQ-Plus :粒子能够平滑实时跟随光标移动,消失轨迹实现了渐变消失,提供了颜色选择器与速度条滑块,功能实现非常完整且视觉效果较好。
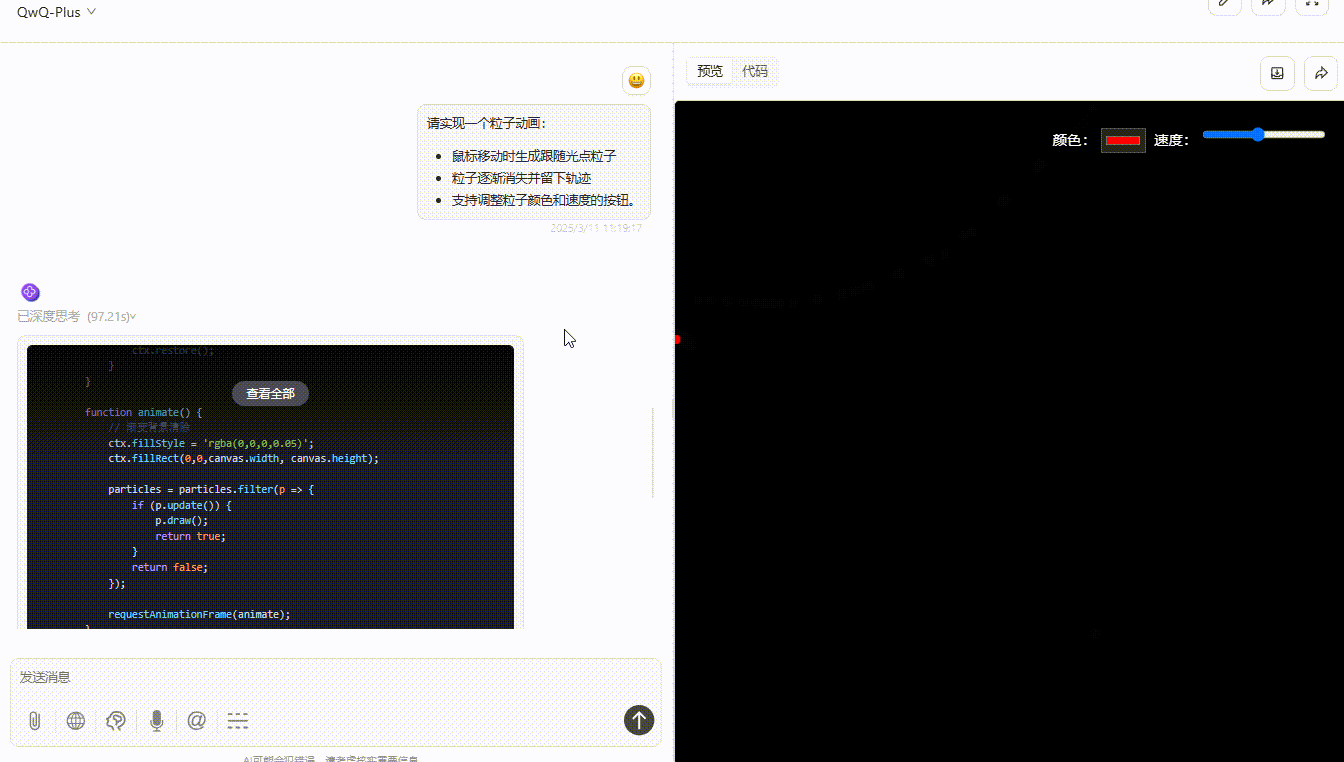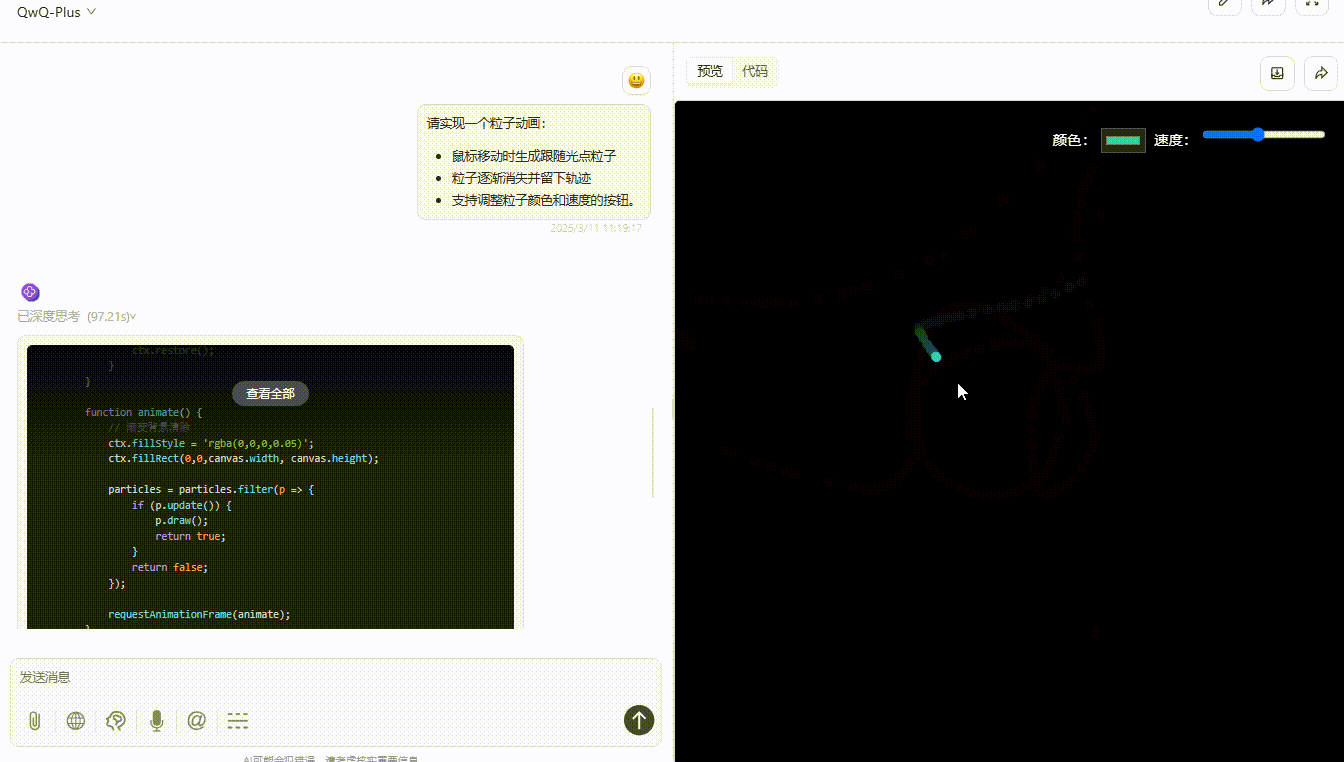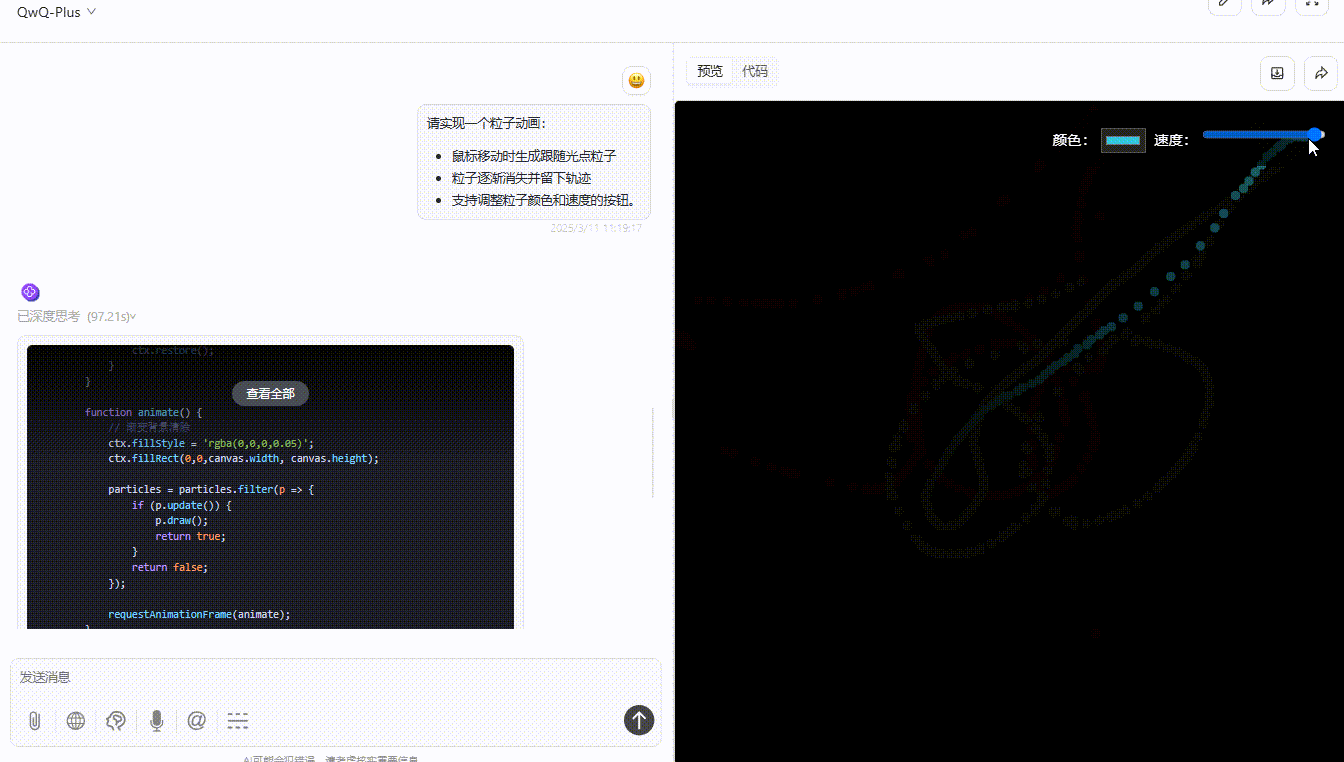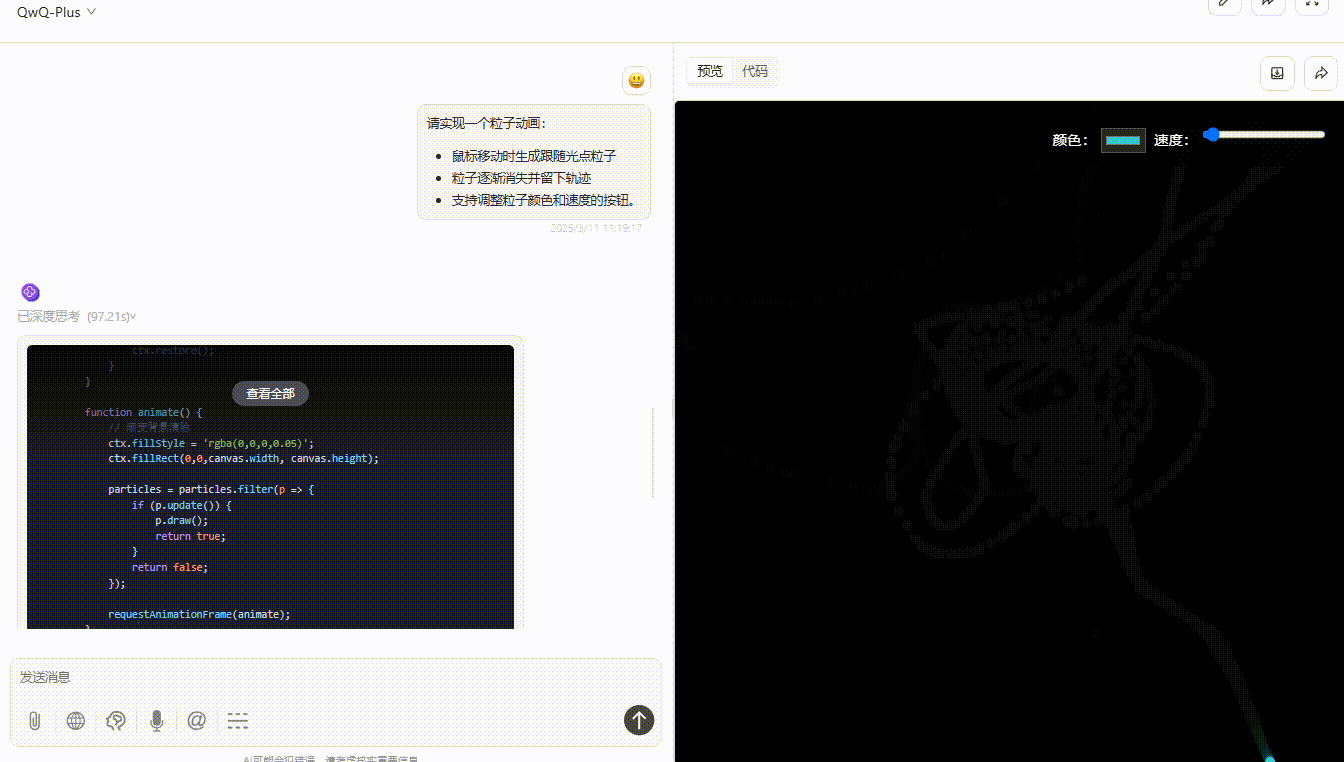
QwQ-32B: 粒子能够跟随光标移动稍稍有延迟,颜色切换还算流畅,整个功能完整,但交互与视觉效果一般。
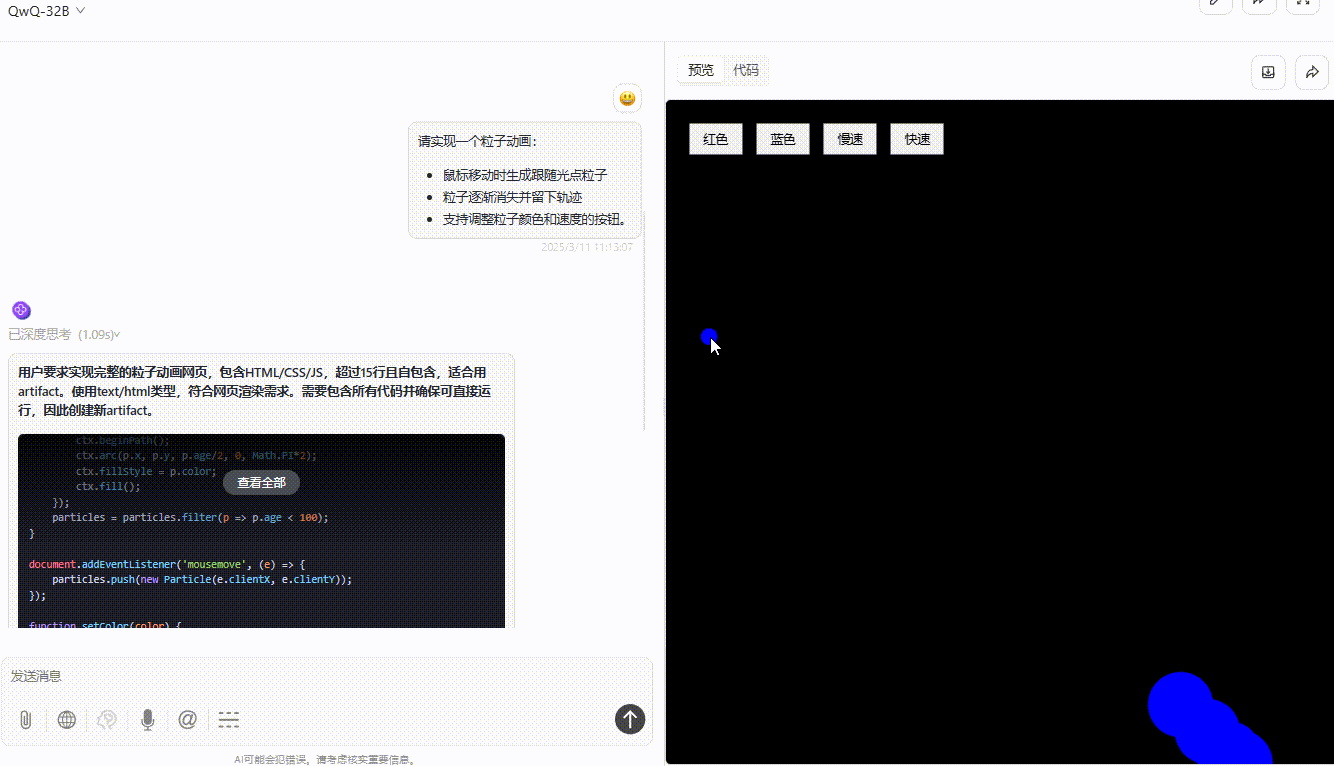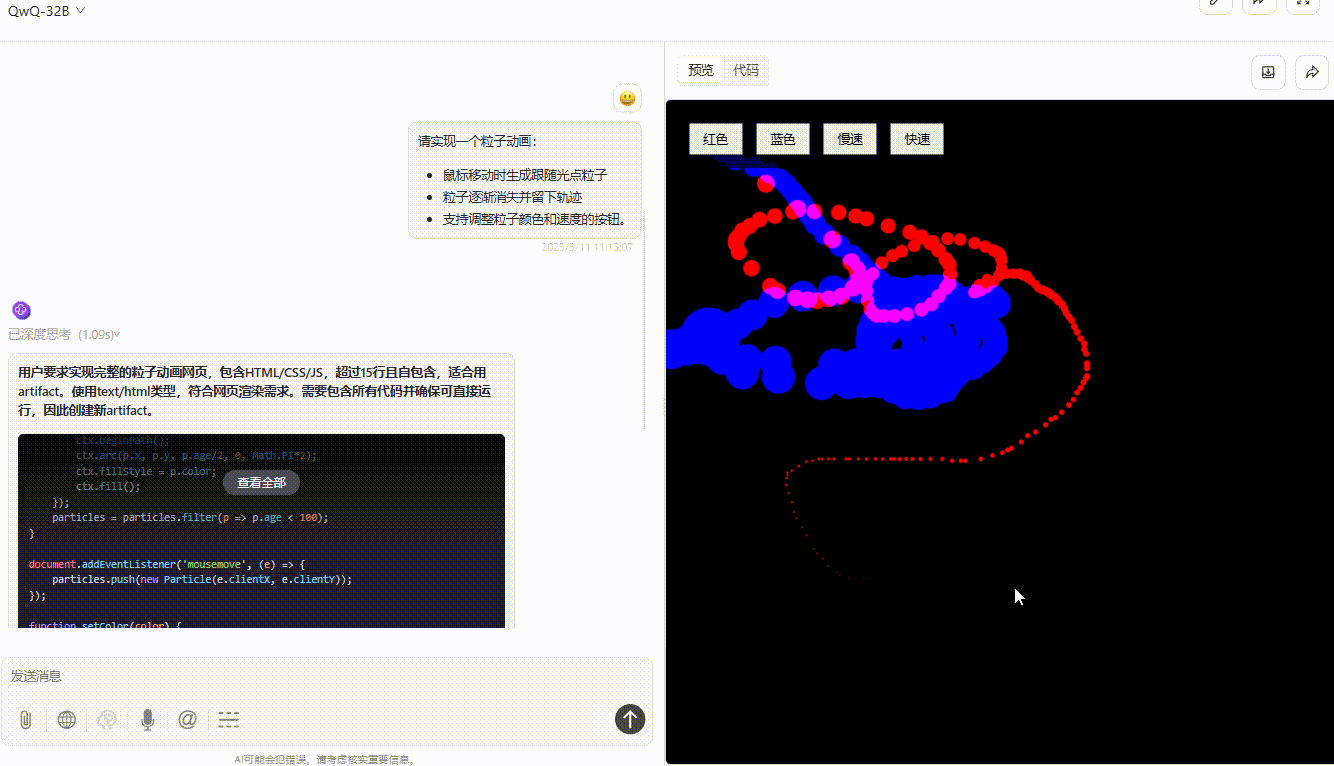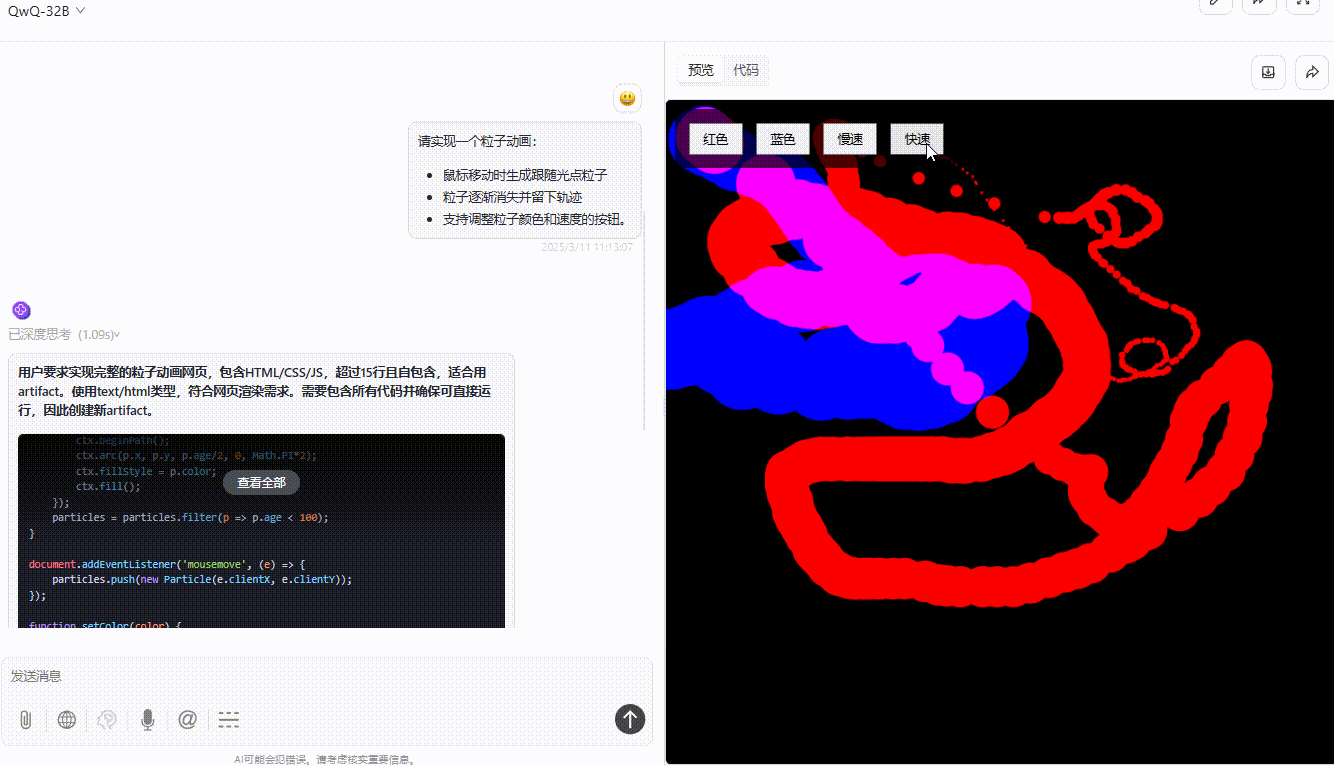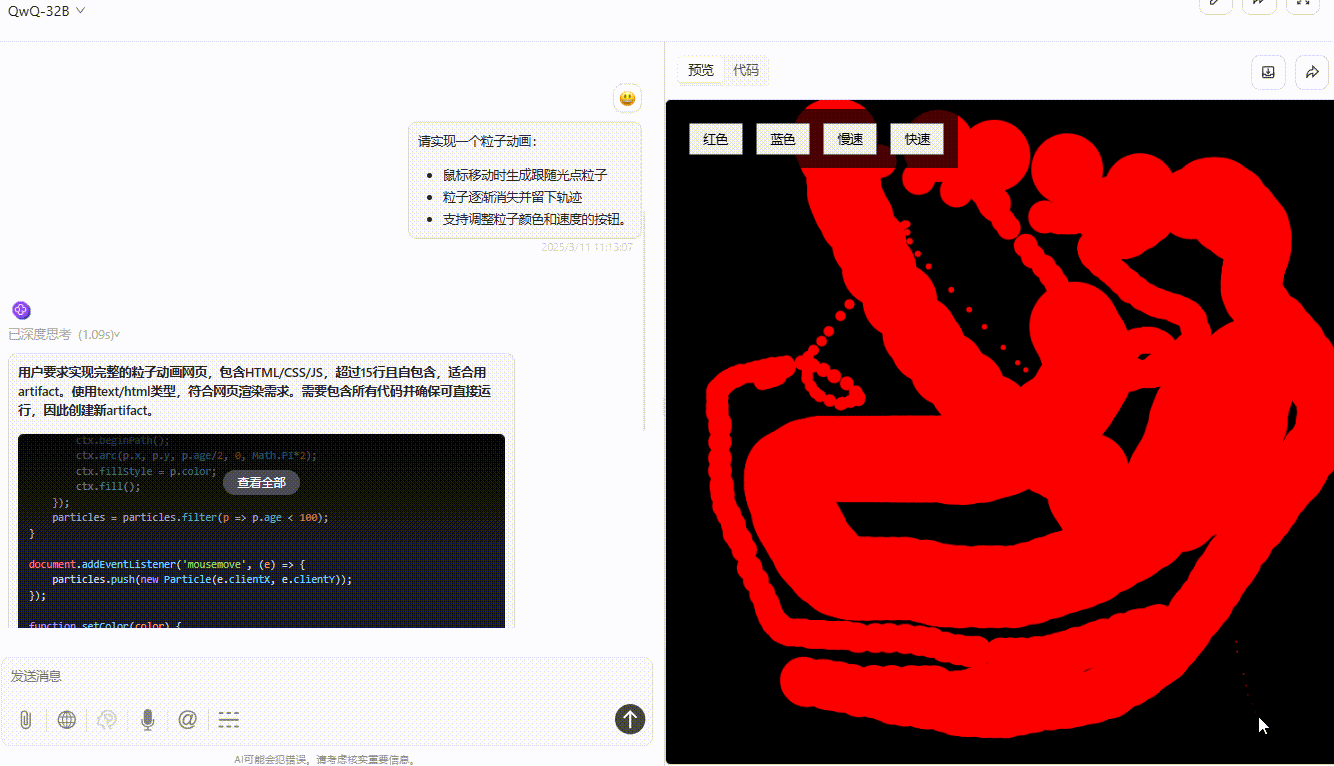
DeepSeek-R1:粒子跟随光标移动无延迟,可通过按钮切换颜色和速度,但按钮切换速度虽然精准但稍有不便,实用性不够。整体功能实现较完整,交互与视觉效果好。
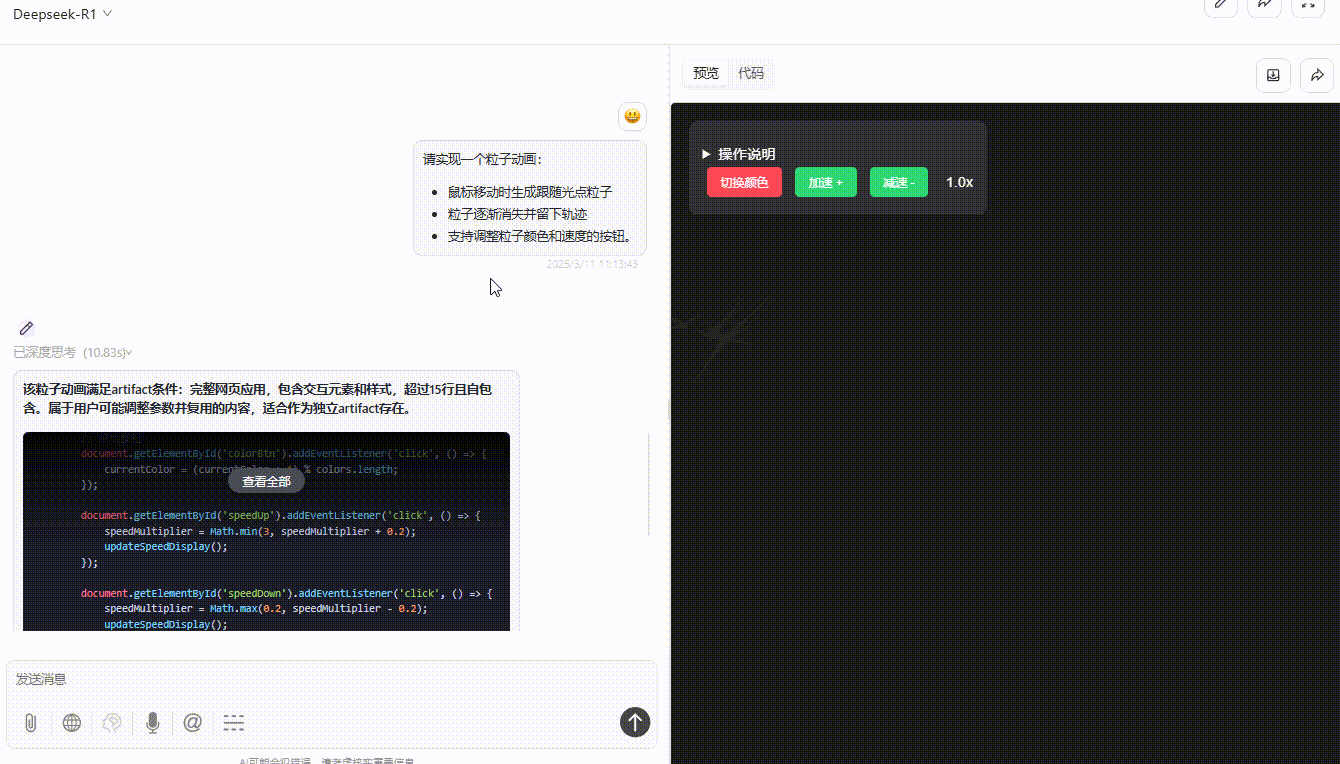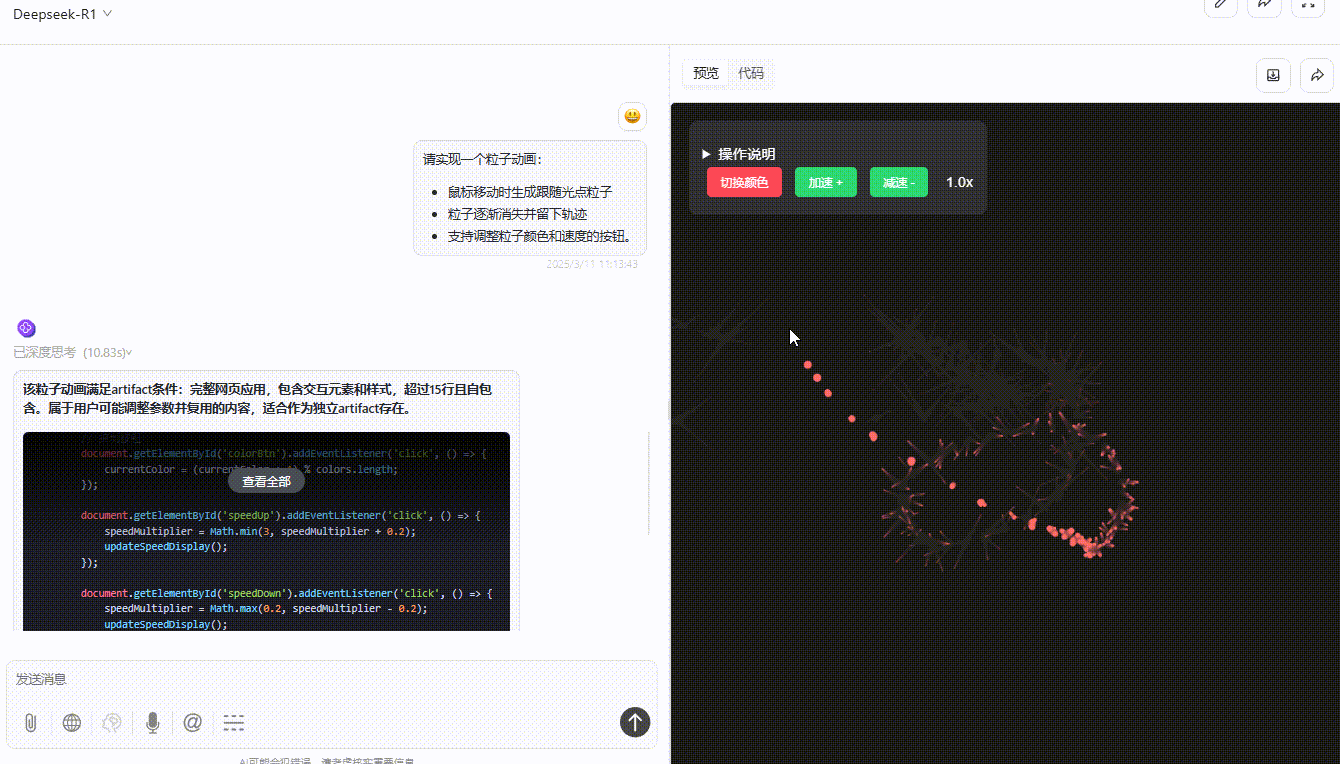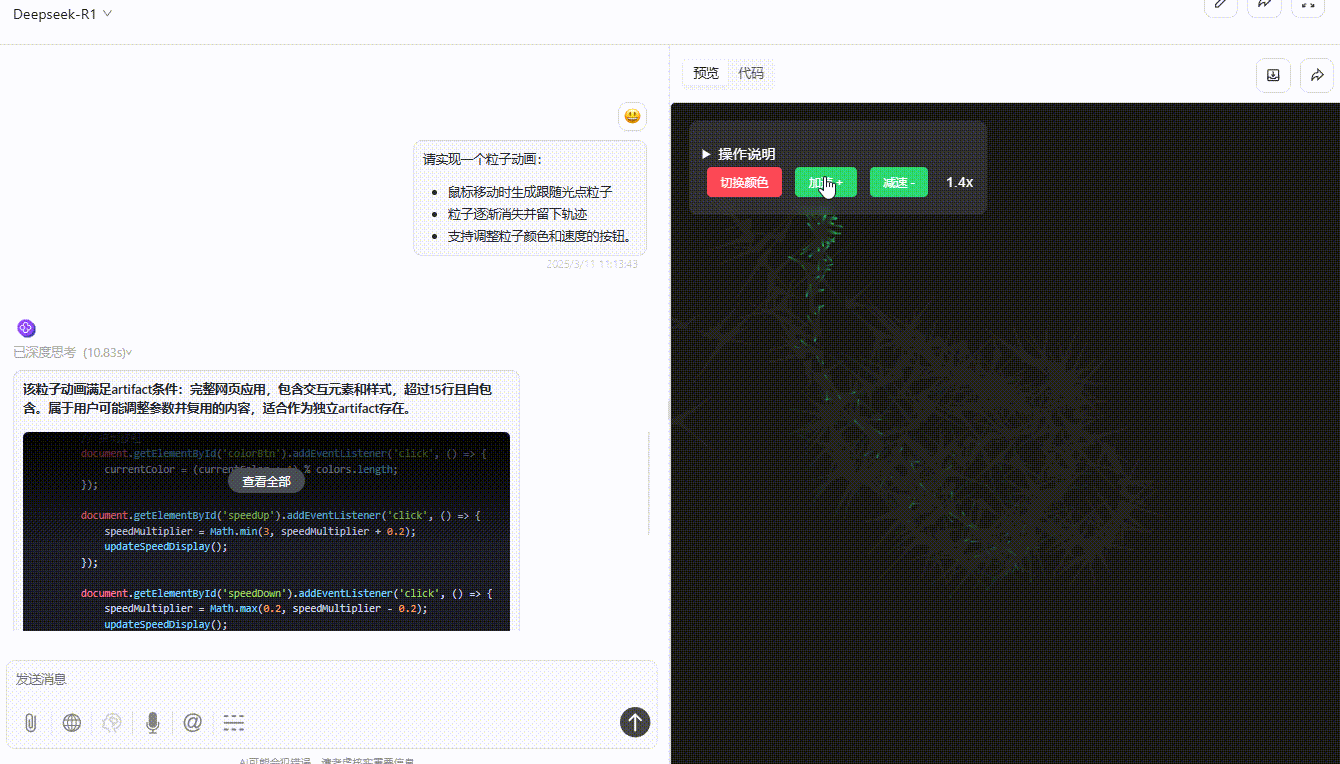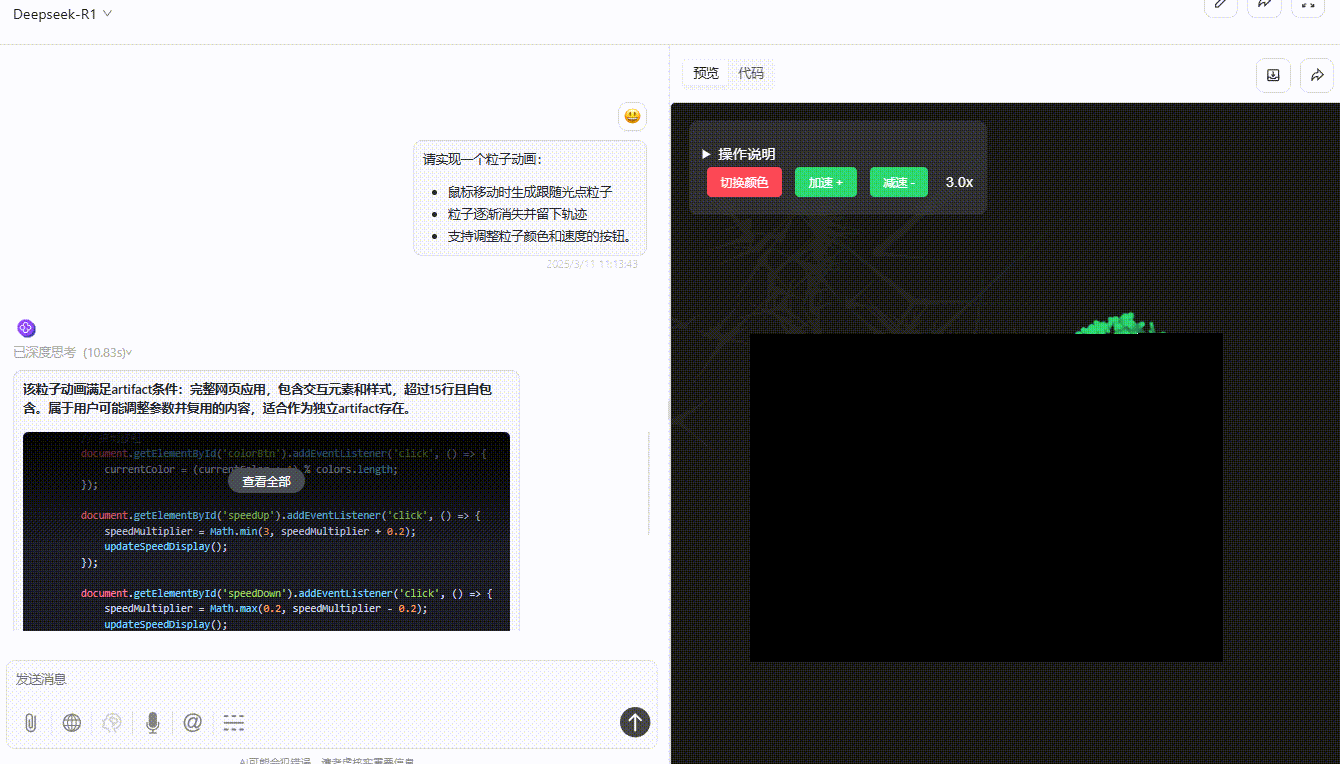
实测总结:
通过以上实测,可以初步得出以下结论:
(1)复杂任务下 QwQ-32B 因资源受限陷入无限思考
在实测1中发现,QwQ-32B 在面对复杂任务时,会陷入无休止的思考而无法输出答案。这种情况并非个例,例如在回答“1 = 5 2 = 15 3 = 215 4 = 3215 5 =?”这一问题时也出现了类似无限思考的情形。这或许是由于复杂问题解决需要更多的资源,而模型的资源存在限制所致。
(2)QwQ-Plus 在计算推理任务表现卓越
根据实测2的结果得出,在涉及计算的推理任务中,QwQ-Plus 表现出色,表现优于 DeepSeek-R1 和 QwQ-32B,其不仅能够精准地输出正确答案,还能清晰地展示出关键的解题思路。
(3) QwQ-32B 的推理速度优势显著
从实测3的结果能够看出,QwQ-32B 深度思考时间最短。而进一步考察实测4和实测5的数据,QwQ-32B 依旧保持着深度思考时间最短的优异表现。综合多轮测试情况可以看出,QwQ-32B 在三个模型中的推理速度最快,其推理速度的优势显著 。
(4)复杂推理任务里 QwQ 与 DeepSeek-R1的比肩表现
综合实测3、4,面对逻辑思维和复杂的推理任务,三个模型均能成功推导出正确答案。这表明在推理方面,QwQ-32B 和 QwQ-Plus 具备了与 DeepSeek-R1 相媲美的水平。
(5)QwQ-Plus 编程效果综合评估最优
根据实测4效果所示, 从实用性、交互效果等方面综合考量,QwQ-Plus 的表现最为出色,DeepSeek-R1 虽然美观度最佳但功能实用性方面存在一定欠缺,而QwQ-32B 在该案例中的编程能力还有提升的空间。
综上所述,QwQ-Plus 相较于 QwQ-32B ,在稳定性方面略胜一筹,尤其是面对复杂的计算推理任务时;然而,就速度表现而言,QwQ-Plus 和 DeepSeek-R1 则稍逊于 QwQ-32B 。
在与 DeepSeek-R1 的性能对比方面,无论是 QwQ-Plus 还是 QwQ-32B,均表现出与之十分接近的水准,但若要说完全超越,仍存在一定的差距。不过综合比较,将 QwQ-32B 称为 DeepSeek-R1 的平价替代品,这一说法倒是合理的。
在302.AI上使用 QwQ-Plus 和 QwQ-32B 模型
302.AI的聊天机器人和API超市提供了按需付费无订阅的服务方式,企业和个人用户可按需灵活选用。
1、使用模型对话
依次点击使用机器人→聊天机器人→ 模型→搜索关键词“qwq”→ 按需选择→创建聊天机器人;
2、使用模型API
企业用户可以通过302.AI的API超市快速、便捷地调用模型,还能够根据特定项目需求进行定制化开发。
相关文档:使用API→API超市→语言大模型→国产模型/开源模型→查看文档;
QwQ-Plus 的API名称:qwq-plus
QwQ-32B 的API名称:qwq-32b
硅基流动部署的 QwQ-32B 的API名称:Qwen/QwQ-32B